为了使不熟悉SQL语言的用户能够方便地从数据库中进行数据分析,PolarDB for AI推出了自研的基于大语言模型的自然语言到SQL语言转义(Large Language Model based Natural Language to SQL,简称LLM-based NL2SQL)AI模型,作为内置模型供您使用。与传统的NL2SQL方法相比,LLM-based NL2SQL模型在语言理解能力上更为强大,所生成的SQL语句能够支持更多的函数,例如日期加减等。该模型甚至能够理解一些简单的映射关系,例如有效->isValid=1等。此外,经过适当调整后,还能够理解您的一些常用SQL搭配,例如在条件中默认选择datastatus=1等。
效果展示
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '筛选出2个请假次数最多的学生,按照学生的请假次数降序排列,显示学生的名字和请假次数。') WITH (basic_index_name='schema_index');输出:SELECT s.student_name, COUNT(sc.id) AS leave_count FROM students s JOIN student_courses sc ON s.id = sc.student_id WHERE sc.status = 0 GROUP BY s.student_name ORDER BY leave_count DESC LIMIT 2;
自然语言到SQL语言转义全流程
为了帮助您能高效实现NL2SQL的落地应用,我们将实施流程分为3个阶段:快速启动阶段、优化调优阶段、生产部署阶段。
快速启动阶段:本阶段旨在帮助用户从零基础快速搭建NL2SQL基础能力。
优化调优阶段:针对实际业务场景中的具体问题,我们将提供深度优化。
生产部署阶段:确保NL2SQL系统顺利投入生产环境。

前提条件
增加AI节点,并设置AI节点的连接数据库账号:开启PolarDB for AI功能
说明若您在购买集群时已添加AI节点,则可以直接为AI节点设置连接数据库的账号。
AI节点的连接数据库账号需具有读写权限,以确保能够顺利读取和写入目标数据库。
使用集群地址连接PolarDB集群:登录PolarDB for AI
重要使用命令行连接集群时,需增加
-c选项。在使用DMS体验和使用PolarDB for AI功能时,DMS默认使用PolarDB集群的主地址进行连接,无法将SQL语句路由至AI节点。因此,您需要手动将连接地址修改为集群地址。
注意事项
提问方式:在提出的问题中,应明确表达出限制条件及相关的实体值。同时,应尽量将条件前置,然后列出需寻找的列值对应的实体,最后提供可能的列名。示例如下:
SELECT '超过1个房间的“房子”或“公寓”的属性名称是什么?'其中,超过1个房间是条件,房子和公寓是列值对应的实体,属性名称是可能的列名。
查询结果准确率:LLM-based NL2SQL是一个基于大语言模型的AI模型,其效果与诸多因素有关。为了使查询结果不脱离预期,总结了下列可能会影响整体准确率的几个因素:
表和列注释的丰富程度:每张表及表中的列都添加注释,会提高查询的准确率。
用户问题与表中列注释的匹配程度:用户问题中的关键词和列注释保持一致,语义上越接近,查询效果越好。
生成的SQL语句长度:SQL语句中涉及的列越少、条件越简单,查询会越准确。
SQL语句中的逻辑复杂程度:SQL语句中涉及的高级语法越少,查询越准确。
使用说明
规范数据表
NL2SQL的前提是需要模型能够理解表的含义,包括列名代表的意思。因此,在使用LLM-based NL2SQL前,需要为常用的数据表以及表中的列添加注释。
表注释
表注释能够帮助LLM-based NL2SQL模型更好地理解表的基础信息,从而能更好地定位SQL语句中涉及的表。注释应简洁明了地概述表的主要内容。如订单、库存等,且尽量控制在10个字以内,避免引入过多的解释。
列注释
列注释通常由常用的名词或短语构成,例如订单编号、日期、店铺名称等,这些内容能够精确体现列名所表达的含义。同时,您可以在列注释中添加列的样例数据或映射关系。例如,对于列名为
isValid,注释可以为是否有效。0:否。1:是。。
若原有注释无法修改,您可以使用进阶功能中的自定义表列注释能力调整相关注释。具体信息,请参见进阶使用-自定义表列注释。
数据准备
您可以根据实际业务场景准备相应的测试数据。本文采用的测试数据集为:测试数据集.sql。
构建检索索引表
为了提取数据表中的数据,需要构建数据表的检索索引表,支持自定义表名(需符合数据库规范)。本文以
schema_index为例,构建检索索引表的SQL语句如下:/*polar4ai*/CREATE TABLE schema_index(id integer, table_name varchar, table_comment text_ik_max_word, table_ddl text_ik_max_word, column_names text_ik_max_word, column_comments text_ik_max_word, sample_values text_ik_max_word, vecs vector_768, ext text_ik_max_word, PRIMARY KEY (id));说明检索索引表不会直接展示于数据库中。如需查看相关信息,请使用SQL语句
/*polar4ai*/SHOW TABLES;进行查询。如果需要删除检索索引表,以
schema_index为例,可以执行此SQL语句/*polar4ai*/DROP TABLE IF EXISTS schema_index;。
将数据表中的信息导入检索索引表
在执行以下SQL语句后,PolarDB for AI默认会对当前数据库下的所有表执行转向量操作,并对列值进行取样。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='schema') INTO schema_index;参数说明
_polar4ai_text2vec为文本转向量化模型。INTO后需要填写之前创建的检索索引表名,该名称为步骤1:构建检索索引表的表名。WITH()内支持配置多个参数,以便对相关行为进行设置:参数
必填
说明
mode
是
数据写入模式。固定为async,表示为异步模式。
resource
是
资源类型。固定为schema,表示对数据表信息进行向量化。
tables_included
否
设置转向量的表。
默认为
'',表示对所有的表执行转向量操作。设置时,多个表名之间需要使用英文逗号分隔,并拼接为字符串。to_sample
否
设置是否对列值进行取样。对列值进行取样会使得导入检索索引表的任务时间变长,但在表的列数较少(小于15列)时能提高生成的SQL的质量。取值范围如下:
0(默认):不对列值取样
1:对列值取样
columns_excluded
否
设置不参与LLM-based NL2SQL操作的列。
默认为
'',表示所有参与转向量的表中的所有列均参与后续LLM-based NL2SQL操作。设置时,需要将所选表中不参与后续LLM-based NL2SQL操作的列按照table_name1.column_name1,table_name1.column_name2,table_name2.column_name1的格式拼接为字符串。示例:以下SQL语句表示对当前数据库中的
graph_info表、image_info表以及text_info表执行转向量操作,并对列值进行取样。同时,graph_info表中的time列和text_info表中的ext列不参与后续的LLM-based NL2SQL操作。/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='schema', tables_included='graph_info,image_info,text_info', to_sample=1, columns_excluded='graph_info.time,text_info.ext') INTO schema_index;
查看任务状态
执行完上述导入检索索引表的语句后,将返回该任务的
task_id,例如bce632ea-97e9-11ee-bdd2-492f4dfe0918。您可以通过以下命令查看导入状态,当返回值显示为finish时,表示任务已完成。/*polar4ai*/SHOW TASK `bce632ea-97e9-11ee-bdd2-492f4dfe0918`;您可以执行以下SQL语句来查看检索索引信息:
/*polar4ai*/SELECT * FROM schema_index;
在线使用LLM-based NL2SQL
语法说明
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '<question>') WITH (basic_index_name='<basic_index_name>');参数说明
<question>后是需要输入待转换为SQL语句的问题。以下为您展示一些推荐的问句样例:本示例场景
其他场景
按照老师名字的字母升序排列,显示老师的名字和安排他们教的课程名称。
筛选出10个请假次数最多的学生,按照学生的请假次数降序排列,显示学生的名字和请假次数。
查询2023年10月1日至2023年10月3日期间开课的课程名称和上课地点。
统计每个学生选修的课程数量超过2门的学生姓名和课程数量,按课程数量降序排列。
筛选出学生住址包含“北京市”或“上海市”的学生姓名和电话号码。
进行过两次或更多次治疗的专家的ID、角色和名字是什么?
被养最多数量狗的品种名称是什么?
哪一位主人为他或她的狗支付了最多的治疗费?列出主人的ID和姓氏。
告诉我花在他或她的狗身上最多治疗费的主人的ID和姓氏。
总花费最少的治疗类型的描述是什么?
WITH()内支持配置多个参数,以便对相关行为进行设置:参数名称
必填
说明
basic_index_name
是
当前数据库内检索索引表名。
to_optimize
否
是否进行SQL优化。取值范围:
0(默认):不优化。
1:执行SQL优化操作,PolarDB for AI将会对生成的SQL语句进一步加工成更优化的SQL。
basic_index_top
否
召回表的最相近个数。取值范围:[1,10]。
默认值为3,表示对当前问题只选出最优的3张表。通常设置为1即可。
如果涉及到多张表,可以将该值设置为4或更大,以扩大召回,提高效果。
basic_index_threshold
否
召回表判断是否相近时所使用的阈值。取值范围:(0,1]。
默认值为0.1,表示当数据库表向量匹配超过0.1时才会被选中。
示例
显示特定内容,并按照指定顺序进行排序。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '按照老师名字的字母升序排列,显示老师的名字和安排他们教的课程名称。') WITH (basic_index_name='schema_index');SELECT t.teacher_name, c.course_name FROM teachers t JOIN courses c ON t.id = c.teacher_id ORDER BY t.teacher_name ASC;根据指定条件进行搜索,展示符合条件的内容,并按照指定顺序进行排序。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '筛选出2个请假次数最多的学生,按照学生的请假次数降序排列,显示学生的名字和请假次数。') WITH (basic_index_name='schema_index');SELECT s.student_name, COUNT(sc.id) AS leave_count FROM students s JOIN student_courses sc ON s.id = sc.student_id WHERE sc.status = 0 GROUP BY s.student_name ORDER BY leave_count DESC LIMIT 2;
进阶使用
PolarDB for AI为您提供四种进阶使用方法。若您遇到以下问题时,可参考相应的进阶使用说明以解决相关问题。
配置问题模板:通过配置通用的问题模板,使模型能够基于特定知识生成SQL语句。
构建配置表:对问题进行前置处理或对生成SQL语句进行后置处理。
自定义表列注释:如果原表或列的注释无法进行修改,可以为该表及相关列添加新的注释,以覆盖原表中的注释内容。
宽表支持:当表中列数过多或出现
Please use column index to avoid oversize table information.错误时,可以通过构建列索引表来使模型支持宽表。
配置问题模板
问题模板是为特定领域知识而制定的,能够帮助模型更好地理解当前问题。您可以配置一些通用的问题模板,通过引入特定知识来指导模型,使得模型能按特定的知识来生成SQL语句。
使用说明
创建问题模板表
问题模板表的名称必须以
polar4ai_nl2sql_pattern开头,且表结构必须包含下述建表语句中的五个列。DROP TABLE IF EXISTS `polar4ai_nl2sql_pattern`; CREATE TABLE `polar4ai_nl2sql_pattern` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `pattern_question` text COMMENT '模板问题', `pattern_description` text COMMENT '模板描述', `pattern_sql` text COMMENT '模板SQL', `pattern_params` text COMMENT '模板参数', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;问题模板列说明
列名
说明
模板问题
带参数的问题,作为输入提供给LLM-based NL2SQL模型。
在模板问题中,需要按照
#{XXX}格式来写入参数。模板描述
对模板问题进行提炼,并将一些实体作为参数,例如日期、年份、机构等。这些实体通常对应于表中的特定列。
在模板描述中,需要按照
【XXX】格式来写入参数,并且需要与模板问题中的参数顺序保持一致。模板SQL
与模板问题相对应的正确SQL语句。该SQL语句中需将模板问题中的参数作为变量进行处理。
说明模板问题与模板SQL中的参数可不相同,但需具备关联关系。例如,参数应具有相同的前缀,并且参数值之间存在一一映射关系。以
#{category}和#{categoryCode}为例,当category的参数值为普通商标、特殊商标和集体商标时,相应的categoryCode值分别为0、1和2。详细说明,请参见下述示例。模板参数
模板参数为一个JSON字符串,其结构由
table_name、param_info和explanation三个参数组成,具体参数如下:table_name
string:模板SQL中的表名。param_info
array:模板SQL中的参数说明。param_name
string:参数名称。value
array:参数的取值样例。说明如果参数对应的是有限的枚举值,则尽量在value中将所有的值列出来。
如果只是样例值,可以列出2~4个值。
如果存在相互对应的参数,则需要通过数组索引来映射。以
#{category}和#{categoryCode}为例,category中的普通商标对应categoryCode中的1,特殊商标对应categoryCode中的2。详细说明,请参见下述示例。
explanation
string:补充说明。通常是对生成SQL语句的一些要求。比如,输出哪些信息或者对字段的一些说明。
说明当不需要填写模板参数时,您可以将模板参数值设置为以下任意一种形式:
NULL
空字符串
空的list字符串[]
示例
模板问题
模板描述
模板SQL
模板参数
查询课程名称为#{courseName}授课状态为#{status}的课程
【课程名称】【授课状态】的课程有哪些?
SELECT course_name, course_time, course_location FROM courses WHERE course_name=#{courseName} AND status=#{statusCode}[{"table_name":"courses","param_info":[{"param_name":"#{courseName}","value":["数学","物理","化学","英语","历史","地理","生物","计算机科学","艺术","音乐","体育","编程","文学","心理学","哲学","经济学","社会学","物理学实验","化学实验","生物学实验"]},{"param_name": "#{status}", "value": ["未开课","授课中"]},{"param_name": "#{statusCode}","value": [0,1]}], "explanation": "输出课程名称course_name、课程时间course_time、课程地点course_location。注:status为常量映射类型。变量映射字段:statusCode。"}]
查询年份为#{issueDate}年项目状态为#{projectStat}状态计划发布的国家标准有哪些?
【年份】【项目状态】计划发布的国家标准有哪些?
SELECT DISTINCT planNum, projectCnName, projectStat FROM sy_cd_me_buss_std_gjbzjh WHERE `planNum` IS NOT NULL AND `dataStatus` != 3 AND `isValid` = 1 AND projectStat=#{projectStat} AND DATE_FORMAT(`issueDate`, '%Y')=#{issueDate}[{"table_name":"sy_cd_me_buss_std_gjbzjh","param_info":[{"param_name":"#{issueDate}","value":[2009,2010,2011,2012]},{"param_name":"#{projectStat}","value":["正在征求意见","已发布","正在审查"]}],"explanation":"输出标准名称projectCnName、计划号、项目状态"}]
查询商标类型为#{category}国际分类为#{intCls}类型的商标有哪些?
【商标类型】【国际分类】的商标有哪些?
SELECT DISTINCT tmName, regNo, status FROM sy_cd_me_buss_ip_tdmk_new WHERE dataStatus!=3 AND isValid = 1 AND category=#{categoryCode} AND intCls=#{intClsCode}[{"table_name":"sy_cd_me_buss_ip_tdmk_new","param_info":[{"param_name":"#{intCls}","value":["化学原料","颜料油漆","日化用品","燃料油脂","医药"]},{"param_name":"#{category}","value":["普通商标","特殊商标","集体商标"]},{"param_name":"#{intClsCode}","value":[1,2,3,4,5]},{"param_name":"#{categoryCode}","value":[0,1,2]}],"explanation":"输出商标名称tmName、regNo申请号/注册号、status商标状态。注:category为常量映射类型。变量映射字段:categoryCode。intCls为常量映射类型。变量映射字段:intClsCode。"}]
以本文示例场景为例,创建上述表格中第一条模板问题。执行SQL如下:
INSERT INTO `polar4ai_nl2sql_pattern` (`pattern_question`,`pattern_description`,`pattern_sql`,`pattern_params`) VALUES ('查询课程名称为#{courseName}授课状态为#{status}的课程','【课程名称】【授课状态】的课程有哪些?','SELECT course_name, course_time, course_location FROM courses WHERE course_name=#{courseName} AND status=#{statusCode}','[{"table_name":"courses","param_info":[{"param_name":"#{courseName}","value":["数学","物理","化学","英语","历史","地理","生物","计算机科学","艺术","音乐","体育","编程","文学","心理学","哲学","经济学","社会学","物理学实验","化学实验","生物学实验"]},{"param_name": "#{status}", "value": ["未开课","授课中"]},{"param_name": "#{statusCode}","value": [0,1]}], "explanation": "输出课程名称course_name、课程时间course_time、课程地点course_location。注:status为常量映射类型。变量映射字段:statusCode。"}]');创建问题模板索引表
支持自定义索引表名(需符合数据库规范)。本文以
pattern_index为例,创建问题模板索引表的SQL语句如下:/*polar4ai*/CREATE TABLE pattern_index(id integer, pattern_question text_ik_max_word, pattern_description text_ik_max_word, pattern_sql text_ik_max_word, pattern_params text_ik_max_word, pattern_tables text_ik_max_word, vecs vector_768, PRIMARY KEY (id));说明问题模板索引表不会直接展示于数据库中。如需查看相关信息,请使用SQL语句
/*polar4ai*/SHOW TABLES;进行查询。如果需要删除问题模板索引表,以
pattern_index为例,可以执行此SQL语句/*polar4ai*/DROP TABLE IF EXISTS pattern_index;。
将问题模板表中信息导入索引表
说明问题模板表中的信息不得为空。在执行导入索引表的SQL语句之前,您需至少添加一条记录。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='pattern') INTO pattern_index;参数说明
_polar4ai_text2vec为文本转向量化模型。INTO后需要填写之前创建的问题模板索引表名,该名称为步骤2:创建问题模板索引表的表名。WITH()内支持配置多个参数,以便对相关行为进行设置:参数
必填
说明
mode
是
数据写入模式。固定为async,表示为异步模式。
resource
是
资源类型。固定为pattern,表示对问题模板信息进行向量化。
pattern_table_name
否
设置转向量的问题模板表的表名,该名称为步骤1:创建问题模板表中的表名。
默认为
polar4ai_nl2sql_pattern,表示对polar4ai_nl2sql_pattern表执行转向量操作。设置时,需填写以polar4ai_nl2sql_pattern开头的问题模板表的表名。若您希望为不同场景或业务维护不同的问题模板索引表,可以在创建问题模板索引表时指定不同的表名。例如,为用户相关场景创建
polar4ai_nl2sql_pattern_user表,随后在第二步创建问题模板索引时,将索引名设定为pattern_index_user。在将信息导入索引表时,使用如下SQL语句:/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='pattern', pattern_table_name='polar4ai_nl2sql_pattern_user') INTO pattern_index_user;
查看任务状态
执行完上述导入索引表的语句后,将返回该任务的
task_id,例如bce632ea-97e9-11ee-bdd2-492f4dfe0918。您可以通过以下命令查看导入状态,/*polar4ai*/SHOW TASK `bce632ea-97e9-11ee-bdd2-492f4dfe0918`;当返回值显示为
finish时,表示任务已完成。问题模板信息可被模型引用。您可以执行以下SQL语句来查看问题模板索引信息:/*polar4ai*/SELECT * FROM pattern_index;说明如果
polar4ai_nl2sql_pattern表中的数据发生了变更,则需要重新执行步骤3:将问题模板信息导入索引表。在线使用问题模板
您可以执行以下SQL语句来在线使用LLM-based NL2SQL和问题模板:
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '查询课程名称为数学,授课状态为授课中的课程') WITH (basic_index_name='schema_index', pattern_index_name='pattern_index');SELECT course_name, course_time, course_location FROM courses WHERE course_name='数学' AND status=1;参数说明
SELECT后需要输入待转换为SQL语句的问题。
basic_index_name为当前数据库检索索引表名称。pattern_index_name为问题模板索引表名称。WITH()内支持配置多个参数,以便对相关行为进行设置(其他参数说明请参见在线使用LLM-based NL2SQL):参数名称
参数描述
取值范围
pattern_index_top
召回问题模板的最相近个数。
取值范围:[1,10]。
默认值为2,表示对当前问题模板只选出最优的2条模板。
pattern_index_threshold
召回问题模板是否相近时所使用的阈值。
取值范围:(0,1]。
默认值为0.85,表示当问题模板向量匹配超过0.85时才会被选中。
构建配置表
若您希望对问题进行前置处理,或对最终生成的SQL进行后置处理,可以通过配置表进行相应配置。
适用场景
场景一:对问题中的确定性词语进行替换,如人名、行业用语、商品名替换等。
例如:对于所有涉及
张三的问题,将张三替换为ZS001。在此情况下,对于问题张三上个月的销售额是多少?和张三今年的总销售额是多少?,在最终调用大模型之前,可以通过配置表将其全部预处理为ZS001上个月的销售额是多少?和ZS001今年的总销售额是多少?。场景二:对包含特定词语的问题补充额外信息。
例如,对于所有涉及
总销售额的问题,应补充总销售额的计算公式:总销售额 = SUM(销售额)。在最终调用大型模型之前,可以通过配置表添加此类信息,当问题满足相应条件时进行补充。场景三:对特定表或列的值进行映射替换。
例如:对所有最终涉及
student_courses表的SQL,将其中的status = '请假'替换为status = 0,以作为一种列值映射的兜底措施。
语法说明
构建配置表的SQL语句如下,表名polar4ai_nl2sql_llm_config固定不可变。
DROP TABLE IF EXISTS `polar4ai_nl2sql_llm_config`;
CREATE TABLE `polar4ai_nl2sql_llm_config` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`is_functional` int(11) NOT NULL DEFAULT '1' COMMENT '是否生效',
`text_condition` text COMMENT '文本条件',
`query_function` text COMMENT '查询处理',
`formula_function` text COMMENT '公式信息',
`sql_condition` text COMMENT 'SQL条件',
`sql_function` text COMMENT 'SQL处理',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;当polar4ai_nl2sql_llm_config表中的数据发生变更时,您无需进行任何操作,变更的数据将立即生效。
参数说明
列名 | 说明 | 取值范围 | 示例 |
is_functional | 表示该行配置是否生效。 当配置表存在时,默认每次进行NL2SQL时均采用。若存在不希望采用又暂时不想删除的配置项,可将is_functional置为0。使该配置行不生效。 |
|
|
text_condition | 前置处理:对问题进行文本条件判断。 如果判断为匹配,则使用query_function和formula_function两列进行处理,反之则不使用。 |
| 若text_condition为 例如:
|
query_function | 前置处理:对问题进行处理。 当text_condition判断为匹配时使用。 |
| 若query_function为 例如:
|
formula_function | 前置处理:在问题中补充与具体业务/概念相关的计算公式信息或其他信息。 当text_condition判断为匹配时使用。 | - | 若formula_function为 |
sql_condition | 后置处理:对模型生成的SQL进行条件判断。 如果判断为匹配,则使用sql_function对SQL进行处理,反之则不使用。 |
| 若sql_condition= 例如:
|
sql_function | 后置处理:对SQL进行处理,可用于对业务逻辑中的值映射进行强制处理。 当sql_condition判断为匹配时使用。 |
| 若sql_function= |
示例
is_functional | text_condition | query_function | formula_function | sql_condition | sql_function |
1 |
|
| |||
1 |
| ||||
1 |
|
|
未添加配置表前,执行以下SQL语句:
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '筛选出2个请假次数最多的学生,按照学生的请假次数降序排列,显示学生的名字和请假次数。') WITH (basic_index_name='schema_index');SELECT s.student_name, COUNT(sc.id) AS leave_count FROM students s JOIN student_courses sc ON s.id = sc.student_id WHERE sc.status = 0 GROUP BY s.student_name ORDER BY leave_count DESC LIMIT 2;按照语法说明构建配置表。
添加配置记录。如果表
students或表student_courses在SQL中,且表courses不在SQL中时,将status = 0替换成status = 10。INSERT INTO `polar4ai_nl2sql_llm_config` (`is_functional`,`sql_condition`,`sql_function`) VALUES (1,'students||student_courses&&!!courses','{"replace":{"status = 0":"status = 10"}}');执行步骤1的SQL语句。可以看出生成的SQL语句已将
status的值进行了替换。/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '筛选出2个请假次数最多的学生,按照学生的请假次数降序排列,显示学生的名字和请假次数。') WITH (basic_index_name='schema_index');SELECT s.student_name, COUNT(sc.id) AS leave_count FROM students s JOIN student_courses sc ON s.id = sc.student_id WHERE sc.status = 10 GROUP BY s.student_name ORDER BY leave_count DESC LIMIT 2;
自定义表列注释
若您在规范数据表的过程中发现原有数据表或列的注释无法修改,您可在polar4ai_nl2sql_table_extra_info表中为该表及相关列添加新的注释。在使用LLM-based NL2SQL时,该表中的注释将覆盖原表中的注释内容。
语法说明
创建自定义表列注释表的SQL语句如下,表名polar4ai_nl2sql_table_extra_info固定不可变。
DROP TABLE IF EXISTS `polar4ai_nl2sql_table_extra_info`;
CREATE TABLE `polar4ai_nl2sql_table_extra_info` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`table_name` text COMMENT '表名称',
`table_comment` text COMMENT '表说明',
`column_name` text COMMENT '列名称',
`column_comment` text COMMENT '列说明',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;当polar4ai_nl2sql_table_extra_info表中的数据发生变更时,需重新执行步骤:将数据表中的信息导入检索索引表,才可使polar4ai_nl2sql_table_extra_info表中变更的数据生效。
示例
创建自定义表列注释表。
对
student_courses表中status列的注释进行修改。此处,为status列新增了一个选项说明:2-缺勤。INSERT INTO `polar4ai_nl2sql_table_extra_info` (`table_name`,`table_comment`,`column_name`,`column_comment`) VALUES ('student_courses','课程学生信息表','status','学生状态 0-请假,1-正常,2-缺勤。');重新执行步骤:将数据表中的信息导入检索索引表。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, SELECT '') WITH (mode='async', resource='schema') INTO schema_index;查看任务状态。
执行完上述导入检索索引表的语句后,将返回该任务的
task_id,例如bce632ea-97e9-11ee-bdd2-492f4dfe0918。您可以通过以下命令查看导入状态,当taskStatus显示为finish时,表示任务已完成。/*polar4ai*/SHOW TASK `bce632ea-97e9-11ee-bdd2-492f4dfe0918`;在线使用LLM-based NL2SQL。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '筛选出2个缺勤次数最多的学生,按照学生的缺勤次数降序排列,显示学生的名字和缺勤次数。') WITH (basic_index_name='schema_index');SELECT s.student_name, COUNT(sc.id) AS absence_count FROM student_courses sc JOIN students s ON sc.student_id = s.id WHERE sc.status = 2 GROUP BY s.student_name ORDER BY absence_count DESC LIMIT 2;从上述输出结果中可以看出,LLM-based NL2SQL模型已经将缺勤对应为
student_courses表中status列的列值2。
宽表支持
若数据表中存在列数较多的宽表,或在使用LLM-based NL2SQL过程中收到Please use column index to avoid oversize table information.的错误消息时,可以使用以下流程以支持宽表。
在线使用LLM-based NL2SQL时,WITH()中的basic_index_name和pattern_index_name均可使用相同的column_index_name。与schema或pattern不同,这里仅为信息精简。
对于绝大多数请求而言,column_index_name参数不会造成影响,仅在触发长度限制的NL2SQL请求中,需要通过column_index_name对表信息进行精简。这可能导致一定程度的准确度损失,但有效避免了因提示(Prompt)过长而引发LLM-based NL2SQL模型错误的问题。
构建列索引表。
支持自定义列索引表名(需符合数据库规范),但该表名不得与当前数据库中已存在的表名相同。此外,一个数据库中只需存在一张列索引表即可。建表语句如下:
/*polar4ai*/CREATE TABLE column_index(id integer, table_name varchar, table_comment text_ik_max_word, column_name text_ik_max_word, column_comment text_ik_max_word, is_primary integer, is_foreign integer, vecs vector_768, ext text_ik_max_word, PRIMARY KEY (id));说明列索引表不会直接展示于数据库中。如需查看相关信息,请使用SQL语句
/*polar4ai*/SHOW TABLES;进行查询。如果需要删除列索引表,以
column_index为例,可以执行此SQL语句/*polar4ai*/DROP TABLE IF EXISTS column_index;。
将数据表中的信息以列为粒度导入列索引表。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_text2vec, select '') WITH (mode='async', resource='column') into column_index;查看任务状态。
执行完上述导入列索引表的语句后,将返回该任务的
task_id,例如bce632ea-97e9-11ee-bdd2-492f4dfe0918。您可以通过以下命令查看导入状态,当taskStatus显示为finish时,表示任务已完成。/*polar4ai*/SHOW TASK `bce632ea-97e9-11ee-bdd2-492f4dfe0918`;在线使用LLM-based NL2SQL宽表。
/*polar4ai*/SELECT * FROM PREDICT (MODEL _polar4ai_nl2sql, SELECT '按照老师名字的字母升序排列,显示老师的名字和安排他们教的课程名称。') WITH (basic_index_name='schema_index', column_index_name='column_index');
常见问题
使用DMS执行SQL时,报错:语法有误
若您在DMS体验或使用PolarDB for AI功能时,执行AI SQL(即SQL语句前添加/*polar4ai*/的SQL)出现以下错误:You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'xxx' at line xxx,请检查DMS的连接地址是否为PolarDB集群的集群地址。
PolarDB for AI功能需在AI节点上执行,而DMS默认使用PolarDB集群的主地址进行连接。因此,您需要按照以下流程修改DMS的连接地址。
通过DMS连接集群后,在左侧导航栏的列表中,选择目标集群,单击右键选择编辑实例。
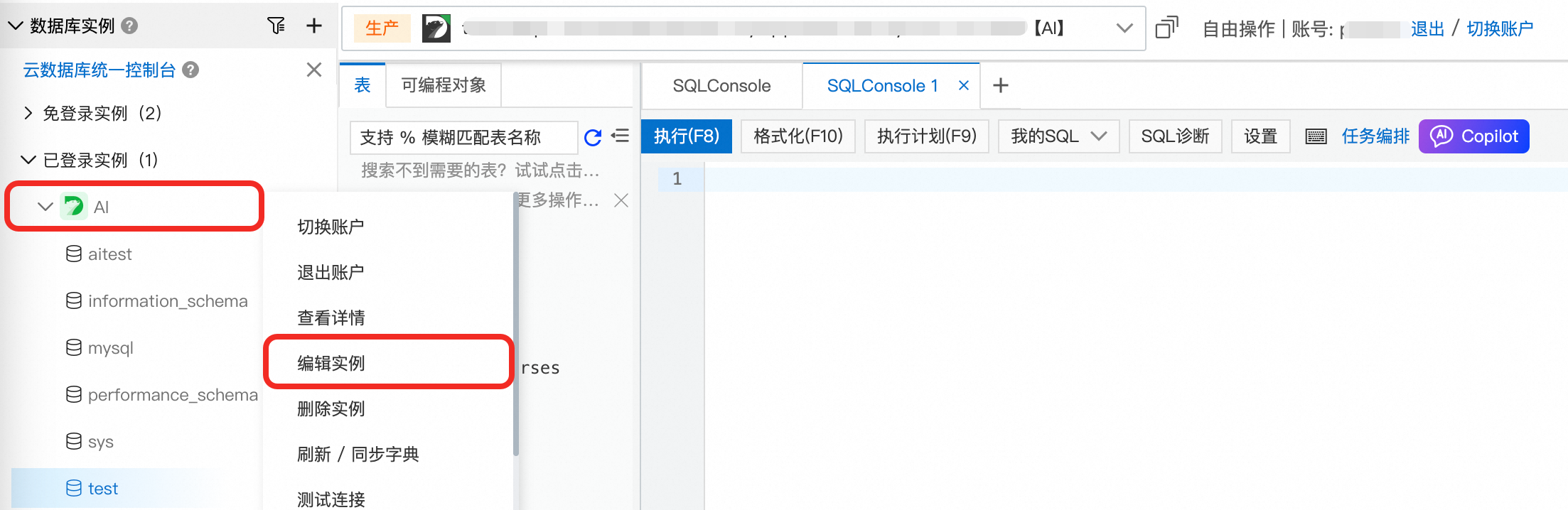
在编辑实例弹窗中,将修改为连接串地址,并填入集群的集群地址。单击保存。

由于原SQL窗口使用的是主地址连接集群,因此在修改连接串地址后,请关闭原SQL窗口,并重新打开一个新的SQL窗口执行SQL。