
本文为您介绍如何使用LogStash将Elasticsearch或OpenSearch中的数据同步至PolarSearch。
准备工作
环境依赖:已准备一台可以同时访问源库和目标库网络的服务器用于运行LogStash。
权限要求:
源库:连接账号需具备待同步索引的
read和read_metadata权限。目标库:连接账号需具备
write、create_index等数据写入权限。
步骤一:准备LogStash环境
LogStash支持不同的源和目标,本文使用的目标库为PolarSearch,源库为Elasticsearch 7.10与PolarSearch。
下载并解压LogStash:请根据您的环境选择对应的安装包。本文以Linux x86_64环境8.8.2版本为例。
说明不同版本的LogStash在使用上略有差异但核心逻辑一致。
更多LogStash版本,请参见LogStash版本列表。
安装插件:
不同的源库与目标库需要安装不同的插件,请根据您的实际情况选择安装。插件仓库地址,请参见插件仓库。
源库插件:
若源库为Elasticsearch,则需要安装
input-elasticsearch插件。当前插件已经预安装,您可通过命令查看是否已经安装。# 进入 LogStash 根目录 cd /path/to/logstash-8.8.2 # 检查插件是否已经安装 ./bin/logstash-plugin list # 如果没有安装,则执行插件安装命令 ./bin/logstash-plugin install logstash-input-elasticsearch若源库为OpenSearch,则需要安装
input-opensearch插件。# 进入 LogStash 根目录 cd /path/to/logstash-8.8.2 # 执行插件安装命令 ./bin/logstash-plugin install logstash-input-opensearch
目标库插件:安装
output-opensearch插件,PolarSearch兼容OpenSearch接口,导入PolarSearch需安装output-opensearch插件。# 进入 LogStash 根目录 cd /path/to/logstash-8.8.2 # 执行插件安装命令 ./bin/logstash-plugin install logstash-output-opensearch
步骤二:创建同步配置文件
在LogStash根目录下创建synchronization.conf文件,并根据实际环境,参考以下模板填入配置。
相关参数说明
input源库中的index字段支持使用通配符*以同步多个索引。然而,不建议使用全通配逻辑*来复制所有索引,因为这可能会导致不必要的内部索引复制。input源库中的docinfo字段,可以获取原始索引名和文档ID。output目标库中index名字等可以通过记录的metadata读取,从而保持索引名等不变或在原有名字等元信息基础上进行定制。output目标库中可以增加stdout调试选项可输出调试信息。
更多信息,请参见同步Logstash事件至OpenSearch。
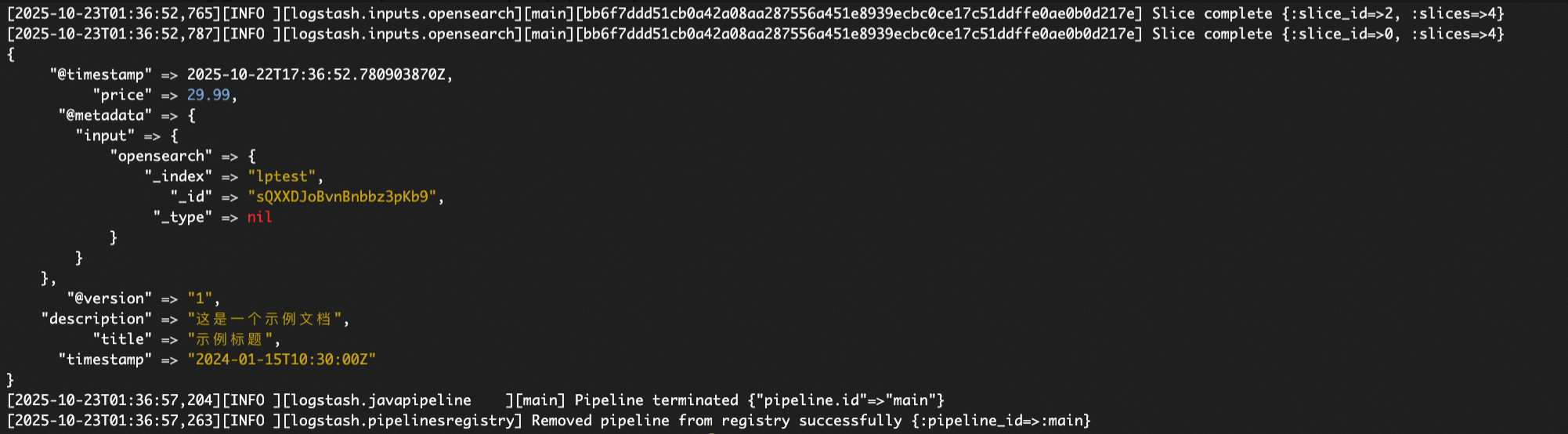
调试输出
如下图所示,通过该输出可以观察到记录的_index等metadata及其结构层次。例如,_index字段的结构层次表明其在output等后续流程中的提取逻辑为:[@metadata][input][opensearch][_index]。
不同input插件的metadata提取逻辑存在差异。
配置文件示例
# synchronization.conf
# 一个从 Elasticsearch/OpenSearch 向 PolarSearch 同步数据的完整配置示例。
input {
# 如果源集群是 Elasticsearch,请将 'opensearch' 替换为 'elasticsearch'。
# 两个插件的配置参数基本相同,但元数据路径可能存在差异。
opensearch {
# 【必填】源集群的连接地址,建议使用 HTTPS 协议。
hosts => ["https://source-cluster-endpoint:9200"]
# 【必填】源集群的认证凭据。
user => "your_source_user"
password => "your_source_password"
# 【必填】指定需要同步的索引,支持通配符。
# 为避免同步不必要的内部索引(如 .kibana),不建议使用 "*" 或 ".*"。
index => "your-business-logs-*"
# --- 安全配置 ---
# 如果源集群启用了 SSL/TLS,请设置为 true。
ssl => true
# 如果源集群使用自签名证书,取消注释并指定 CA 证书路径。
# cacert => "/path/to/source_ca.crt"
# --- 性能与元数据 ---
# 开启此选项以获取原始索引名和文档 ID。
docinfo => true
# 设置并发读取数,建议设置为源索引的主分片数量以最大化读取性能。
slices => 4
# 每次批量获取的文档数量。
size => 1000
# 滚动查询的存活时间,确保长任务不会因超时而中断。
scroll => "5m"
}
}
output {
opensearch {
# 【必填】目标 PolarSearch 集群的连接地址。
hosts => ["https://polarsearch-cluster-endpoint:9200"]
# 【必填】目标集群的认证凭据。
user => "your_target_user"
password => "your_target_password"
# --- 安全配置 ---
ssl => true
# 如果目标集群使用自签名证书,取消注释并指定 CA 证书路径。
# cacert => "/path/to/polarsearch_ca.crt"
# --- 索引与文档 ID ---
# 从元数据中动态读取并设置索引名,以保持与源端一致。
# 注意:元数据路径因 input 插件而异,需通过调试输出确认。
index => "%{[@metadata][input][opensearch][_index]}"
# 从元数据中读取并设置文档 ID,以保持文档的唯一性。
document_id => "%{[@metadata][input][opensearch][_id]}"
}
# --- 调试输出(可选) ---
# 在开发和测试阶段,取消此段注释可在控制台打印数据流信息。
# 正式同步时,注释掉此段以获得最佳性能。
# stdout {
# codec => rubydebug {
# metadata => true
# }
# }
}步骤三:执行同步与验证
启动任务:在LogStash根目录下执行以下命令启动同步任务。
# 启动同步任务,-f 参数指定配置文件 ./bin/logstash -f synchronization.conf对于大规模数据同步,建议使用
nohup将LogStash作为后台服务运行:nohup ./bin/logstash -f synchronization.conf &等待任务执行完成后,登录目标PolarSearch,检查索引和数据是否成功创建和写入。