
PolarDB新增支持连接保持功能,避免由于一些运维操作(如升级配置、主备切换或升级小版本等)或非运维操作故障(如节点所在服务器故障)导致的连接闪断或新建连接短暂失败的问题,进一步提高PolarDB的高可用性。
前提条件
PolarDB数据库代理(PolarProxy)版本需为2.4.7或以上。如何查看和升级当前数据库代理版本,请参见小版本升级。
集群版本需为PolarDB MySQL版5.6、5.7或8.0版本且产品系列为集群版。
仅访问默认集群地址或者自定义地址并且负载均衡策略配置为基于活跃请求数负载均衡的流量支持连接保持。
背景信息
PolarDB已通过高可用组件实现了主节点出现故障时快速进行主备切换,来提供高可用的集群服务。但此类切换过程会对应用程序服务造成影响,导致连接闪断、新建连接短暂失败等问题。引起应用程序服务短暂不可用的场景通常分为如下两种:
计划内(Switchover):即由数据库控制台或后台管控发起的各种运维操作,如升级配置、自动/手动主备切换或升级小版本等。
计划外(Failover):其他非运维操作引起的故障,比如主节点崩溃,节点所在的主机出现故障等。
通常的解决办法是重启应用程序或保证应用程序具备重连机制,但由于开发周期等原因,在开发设计应用程序的前期可能并未考虑到该问题,导致出现大量的非预期行为甚至应用程序的服务不可用。因此PolarDB新增支持连接保持功能,避免由于一些运维操作或非运维操作故障导致的应用程序服务短暂不可用问题,进一步提高PolarDB集群的高可用性。
实现原理
主节点切换
从连接建立的角度看,PolarDB中的一个会话(Session)包含了一个前端连接(即应用程序和Proxy的连接)和N个后端连接(即Proxy和后端N个数据库节点的连接)。开启连接保持功能后,当Proxy与旧主节点(即高可用切换前的主节点)连接断开时,Proxy与前端应用的连接保持不断(即应用程序看到的Session),同时Proxy会与新主节点(即高可用切换后的主节点)重新建立连接并且恢复之前的会话状态,以实现对应用程序端无感知的高可用切换。
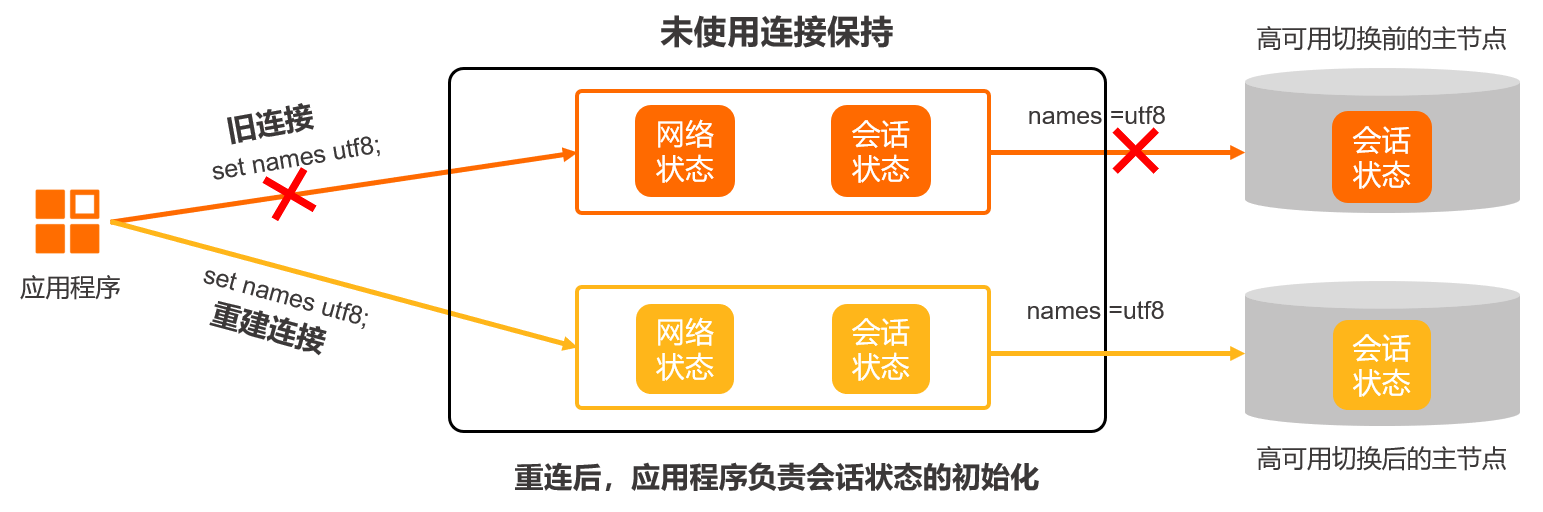
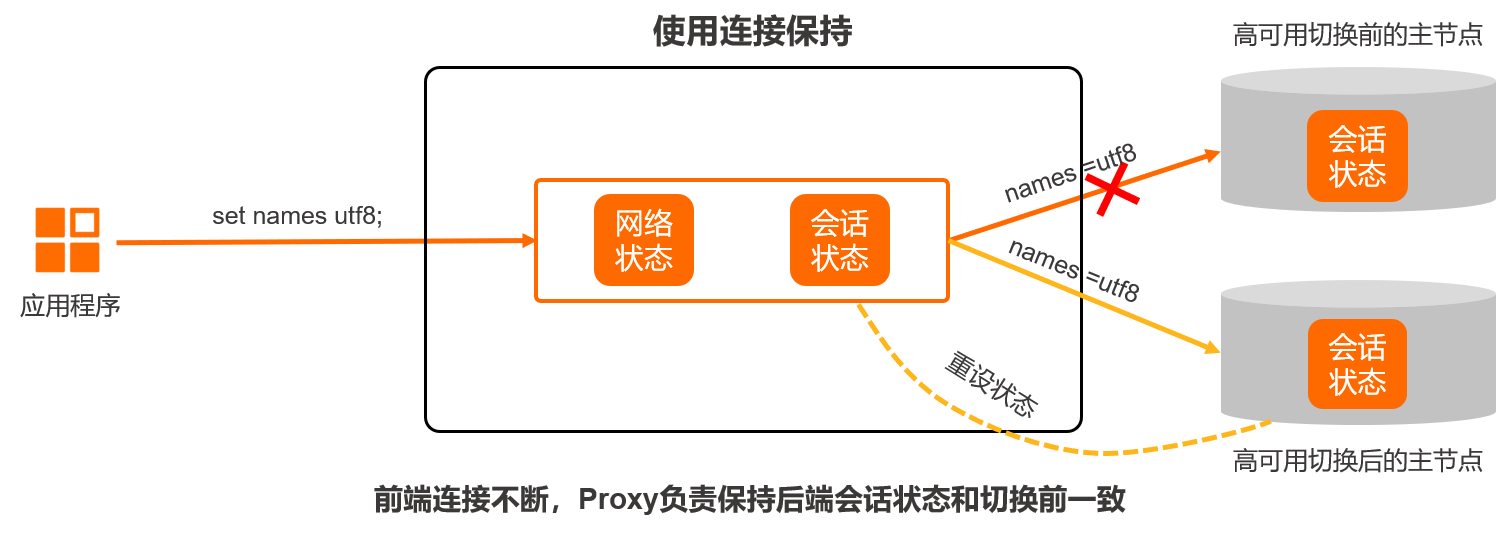
MySQL的连接(会话)通常包括系统变量、用户变量、临时表、字符集编码、事务状态和的Prepare语句状态信息。本文以字符集编码的状态信息为例介绍开启连接保持功能前后的会话状态。
假设应用程序和Proxy间建立了一个连接,并执行了set names utf8; 命令,此时names=utf8就是这个连接的一个状态。当Proxy在新旧主节点中进行切换时,需要保留这个状态,否则会出现字符集乱码问题。所以连接保持的核心在于保证连接切换前后的会话状态一致。
当Proxy将连接从旧主节点切换到新主节点的过程中,会存在短暂的新老数据库同时不可写不可读的时间(具体时长受数据库压力影响),所以在切换时,Proxy会暂时停止将应用程序的连接请求路由到后端数据库,并根据新主节点可读可写能力的恢复时间决定路由方向:
若新主节点在60秒内恢复了可写可读能力,Proxy会将请求路由到新主节点。
若新主节点的可读可写能力未能在60秒内恢复,Proxy会断开与应用程序间的连接,应用程序需重新发起连接请求(即此时与未使用连接保持功能时的行为一致)。
只读节点下线
只读节点下线,即从默认集群地址或自定义地址(并且是基于活跃请求数负载均衡策略)中摘除一个只读节点。如果当前摘除的只读节点上有正在执行的请求,并且这个请求的执行时间超过60秒(从代理收到只读节点要下线的时间开始算),这个请求对应的用户连接会闪断。其他不能保持连接的场景见注意事项中的内容;同时代理在收到下线只读节点请求时,所有的新连接和空闲新请求都不会再路由到该下线节点。
注意事项
连接保持功能无法保持如下场景中的连接:
当连接切换时,连接(会话)上存在临时表。
当连接切换时,Proxy正在从数据库接收结果报文但只接收了部分结果报文,比如执行SELECT语句后,需要从数据库接收一个包含100 MB数据的结果报文,但切换时数据库只传输了10 MB数据。
当连接切换时,连接(会话)上有正在执行中的事务(如
begin;insert into;)。使用cursor或者stmt_send_long_data,并且在切换时cursor或long_data还没有结束。
对于计划内(Switchover)发起的切换或下线节点,Proxy会保留最多60秒的冷静期。如果上述连接能够在60秒内变成空闲(比如正在执行的请求全部返回,或者事务结束等),Proxy也将会保持这些连接,从而提高连接保持的概率。
对于基于连接数负载均衡策略的地址,若删除该地址下的只读节点,当前只读节点上的连接都会闪断,与用户直连该只读节点的行为一致,即不支持连接保持。
性能测试
测试环境
测试用集群如下:
PolarDB MySQL版8.0版本集群(默认包含1个主节点和2个只读节点)。
节点规格为4核16 GB独享规格(polar.mysql.x4.large)。
测试工具:Sysbench。
测试数据如下:
20张表,其中每张表包含10000行记录数。
并发度为20。
测试方法
在不同运维场景下,测试PolarDB集群的连接保活率(即执行运维操作前后的连接保持比例)。
测试结果
在如下测试的运维场景中,PolarDB集群均能保持100%的连接保活率。
说明当前升级集群规格仅支持在未跳级升级规格(如从4核升级至8核)的场景下能够保持100%的连接保活率,如果是从4核升级到16核(或者更大规格),可能出现连接闪断。
若删除只读节点时触发了数据库代理节点收缩,将导致部分连接的闪断。
内核小版本升级的场景中仅包括数据库内核引擎的小版本升级,而不包含数据库代理的小版本升级,数据库代理的小版本升级会出现连接闪断。
运维场景
保活率
主备切换
100%
内核小版本升级
100%
升级集群规格
100%
增删节点
100%