
Ganos与PolarDB PostgreSQL版(兼容Oracle)联合打造了全空间数据多态(冷热)分层存储能力。多态(冷热)分层存储将对象存储OSS直接作为一种更为经济的数据库存储介质,能够与块存储联合使用。该方案支持将整库、单表甚至表内的某一字段存储在不同介质上,同时确保增删改查操作的全部透明性,并通过多级缓存机制保障性能的最小衰减。多态(冷热)分层存储是一种兼顾成本、性能与易用性的全空间数据管理方案,能够显著降低业务开发的复杂度及云资源使用成本。
关于多态(冷热)分层存储
业务背景
随着物理世界数字化的快速发展,各行业的数字化业务催生了对大规模全空间多模多态数据进行快速处理的需求。传统基于中间件的实现方式面临着空间计算性能的严峻挑战。为了进一步解决大规模全空间检索效率问题,推动空间业务全面在线,Ganos原生支持了全空间数据存储类型与海量的计算算子,以“空间计算全面下推”的方式极大程度提升查询计算速度。 在提升计算效率的同时,空间数据的大规模增长和空间对象的日益增大可能会带来愈发沉重的成本问题。此时,往往需要在成本与效率方面做出取舍,部分业务不得不重新迁回线下或者用离线任务的方式完成,业务开发不得不在多种存储介质中来回切换,运维与研发成本大幅度上升。因此,寻找一种兼顾效率、成本与易用性的全空间数据管理方案成为Ganos团队历时两年所重点解决的问题,两年中Ganos团队聚焦以下三个核心问题开展能力规划与建设:
如何拥有更为廉价的数据库存储介质(非外表方式),降低成本。
如何保障这类廉价存储的查询计算效率不会存在大规模衰减。
如何以更为透明的方式管理和使用多种存储介质。
Ganos团队发布了基于PolarDB PostgreSQL版Oracle语法兼容 2.0数据库构建的全空间数据多态(冷热)分层存储能力,将OSS对象存储直接作为一种更为廉价的数据库存储介质,可以与块存储联合使用。多态(冷热)分层存储能力支持将整个数据库、单个表乃至表内的特定字段存储于不同的介质上,同时确保增删改查操作的完全透明性,并通过多级缓存机制保障性能的最小衰减。多态(冷热)分层存储是一种多方兼顾的全空间数据管理方案,同时它一样也可以面向通用的数据库类型字段(BLOB、TEXT、JSON、JSONB、ANYARRAY等)使用。
功能简介
PolarDB PostgreSQL版Oracle语法兼容 2.0多态(冷热)分层存储是传统冷热分离存储功能的一个升级功能,在享受优良的读写性能的同时,又能将存储成本降低到极致。多态(冷热)分层存储支持根据数据的冷热程度进行分层存储。此外,它能够兼容OSS、MinIO、HDFS等多种对象存储介质。同时,它为大对象类型和全空间数据类型提供灵活多样的存储组合,简称为多态(冷热)分层存储。当前多态存储只支持OSS对象存储,更多使用说明请参见冷数据分层存储概述。
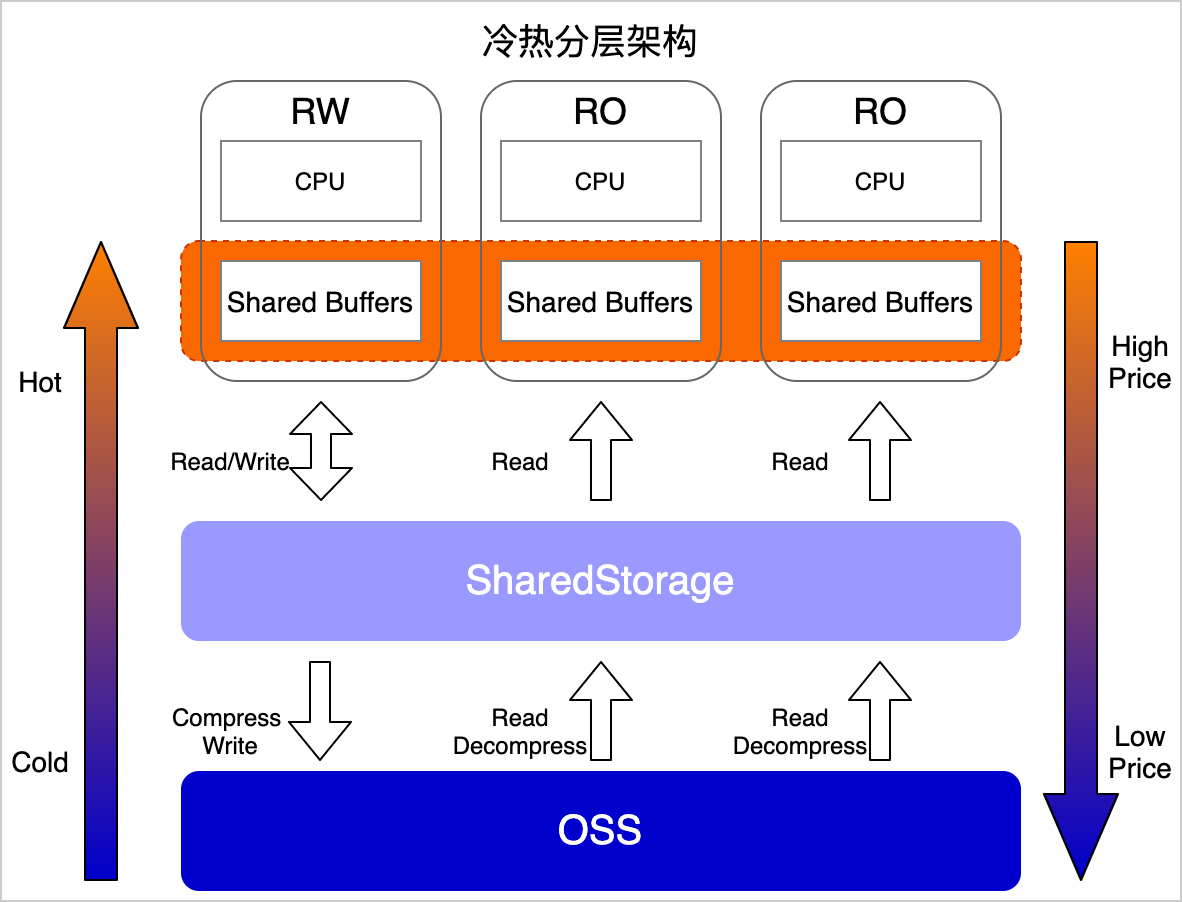
基于多态(冷热)分层存储功能,可以通过简便的SQL语句将过期数据、大对象数据及全空间数据等转存至OSS,实现弹性、低成本和高可靠性的数据管理。转存后,无需对SQL语句进行任何改动,且能够完全透明地执行增、删、改、查及表间联合等复杂分析操作。此外,当数据更新的访问频率增加时,也可以通过动态调整物化缓存,以达到与数据库云盘相同水平的访问性能。
技术优势
PolarDB PostgreSQL版Oracle语法兼容 2.0实现的多态(冷热)分层存储具有以下几方面的技术优势:
成本:支持数据压缩,平均压缩率50%,部分可达20%,使成本降为1/10甚至更低。
性能:物化缓存层加速冷存数据访问,性能衰减可控制在20%-80%。
易用:数据由冷到热分层存储,冷存后支持增删改查SQL完全透明。
可靠:借助OSS的高可靠性,冷数据在不增加存储的前提下支持快照,数据具备恢复还原的能力。
灵活:灵活的冷热分层存储模式,支持按表、按大字段、按子分区分别存储在OSS中。
成本维度
当今时代数据呈爆炸式增长,尤其是带有时间、空间等多维度的数据。随着时间的推移,积累的数据达到TB甚至PB级别,同时对于过往的数据或辅助性数据,其访问频率比较低,此时存储降本往往是核心诉求。在PolarDB PostgreSQL版(兼容Oracle)冷热分层存储架构中,先将冷数据按规则切成小块,再对切好的块数据进行压缩,最后写入OSS,达到通用数据压缩率20%-40%,时空数据压缩率60%-70%,平均压缩率50%的效果,相当于将存储于数据库云盘中的数据转存在OSS中同时数据体量再砍掉一半,最终达到存储成本降为1/10甚至更低的水平。在此结合PolarDB云盘的计费标准、OSS单位存储的成本,以及OSS中实现的压缩比例,以100 GB数据每月存储费对比:
云盘 | 多态(冷热)分层存储(onOSS) | |
存储计费标准 | PSL41.5元/GB/月 |
|
压缩率 | 0 | 50% |
最终费用 | 1.5*100 GB=150元 |
|
最终的存储费用不到原始的1/10。
性能维度
通常情况下,OSS访问延迟是数据库云盘访问延迟的上百倍,如果直接访问存储在OSS中的数据,其读写性能会有较大幅度降低。PolarDB PostgreSQL版Oracle语法兼容 2.0多态存储功能利用数据库云盘实现OSS数据的物化缓存层。根据数据块实际访问情况自动分层存储,读写操作可首先命中物化缓存,确保访问性能,整体更新和插入性能达共享盘90%,点查性能达共享盘80%,数据在物化缓存中的生命周期由访问频率决定,实现降低存储成本的同时拥有优良的访问性能。
易用性维度
PolarDB PostgreSQL版(兼容Oracle)实现的多态(冷热)分层存储是一种完全透明的冷热分层存储方案,使用起来比较简单。首先,数据转存至OSS后,支持数据的增、删、改、查操作,支持索引扫描以及联合查询等各种复杂操作,SQL完全透明,无需有任何的改动。其次,执行数据转存的操作也做到了简单易用,比如分区表可按自定义规则自动转存至OSS、基表与索引一键转存至OSS等。详细操作请参见最佳实践。
可靠性维度
OSS的持久性可达到99.9999999999%,可用性则为99.995%。同时,OSS具备本地冗余和同城冗余功能,从而确保数据在OSS上的可靠性。然而,这并不意味着已经存储在OSS中的数据可以完全不进行备份和恢复操作。对于存储在OSS中的数据库数据,虽然其更新和访问频率相对较低,但仍然支持业务场景中的重要查询分析和数据挖掘等功能。一旦发生误改或误删,必须能够迅速进行还原和恢复。PolarDB PostgreSQL版(兼容Oracle)多态(冷热)分层存储功能支持冷数据的备份恢复,基于Copy-On-Write机制的数据多版本管理,秒级快照,一次快照后,只有被更新的数据块会产生副本,无更新的数据块不产生副本,以极小的成本做到数据的真正可靠。
灵活性维度
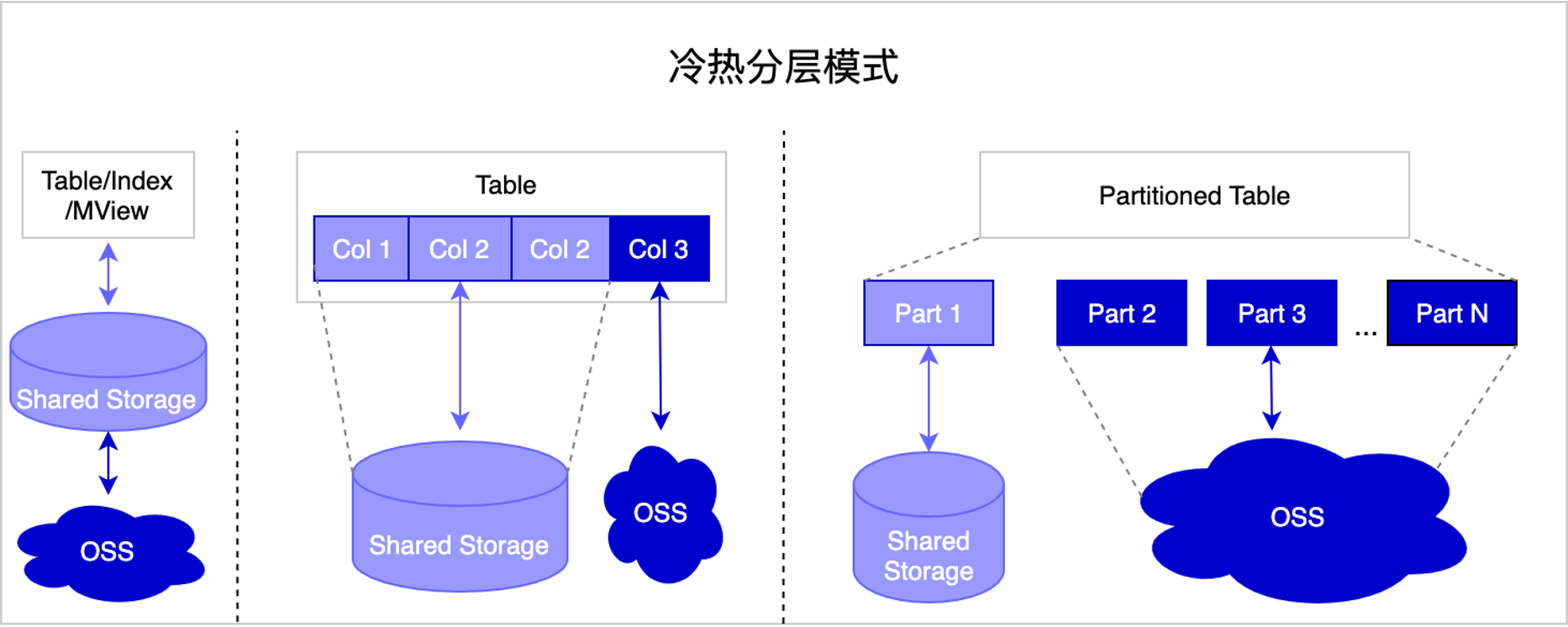
PolarDB PostgreSQL版(兼容Oracle)多态(冷热)分层存储功能支持冷热灵活搭配,具体支持以下几种搭配模式:
将整表数据存储在OSS中,索引存储在云盘中,降本后同时保证良好的访问性能。
将表中的大字段、辅助性字段独立存储在OSS中,其余字段存储在云盘中。
只将分区表中过期子分区存储在OSS中,热分区存储在云盘中,这是最经典的冷热分离模式。这里面还能衍生出好几种组合,比如冷分区数据与索引都存入OSS中,温分区数据存入OSS但索引保留在云盘中,而热分区全部在云盘,使得查询性能基本无衰减。
最佳实践
案例一:分区表过期子分区自动冷存
背景描述
轨迹数据采用分区表存储,并按月进行分区,随着时间的推移,三个月之前的轨迹数据访问频率大大降低(过期),为了降低存储成本,需要数据库自动将超过三个月的分区表进行冷存处理。
操作步骤
创建测试数据库,详细步骤请参见创建数据库,并执行如下语句准备测试数据。
--创建分区表 CREATE TABLE traj( tr_id serial, tr_lon float, tr_lat float, tr_time timestamp(6) )PARTITION BY RANGE (tr_time); CREATE TABLE traj_202301 PARTITION OF traj FOR VALUES FROM ('2023-01-01') TO ('2023-02-01'); CREATE TABLE traj_202302 PARTITION OF traj FOR VALUES FROM ('2023-02-01') TO ('2023-03-01'); CREATE TABLE traj_202303 PARTITION OF traj FOR VALUES FROM ('2023-03-01') TO ('2023-04-01'); CREATE TABLE traj_202304 PARTITION OF traj FOR VALUES FROM ('2023-04-01') TO ('2023-05-01'); --往分区表中写入测试数据 INSERT INTO traj(tr_lon,tr_lat,tr_time) values(112.35, 37.12, '2023-01-01'); INSERT INTO traj(tr_lon,tr_lat,tr_time) values(112.35, 37.12, '2023-02-01'); INSERT INTO traj(tr_lon,tr_lat,tr_time) values(112.35, 37.12, '2023-03-01'); INSERT INTO traj(tr_lon,tr_lat,tr_time) values(112.35, 37.12, '2023-04-01'); --创建分区表索引 CREATE INDEX traj_idx on traj(tr_id);在测试数据库中创建
polar_osfs_toolkit插件,用以支持使用工具类函数,包括主表与索引一键转存OSS、分区表一键转存OSS等。CREATE extension polar_osfs_toolkit;使用高权限账户连接到
postgres数据库中安装pg_cron插件,其他注意事项请参见pg_cron(定时任务)。---只有高权限账户连接到postgres数据库中执行该语句才可以创建pg_cron插件 CREATE EXTENSION pg_cron;设置定时执行任务。使用高权限账户连接到
postgres数据库为测试数据库创建一个名为task1的任务,任务为调用存储过程将超过分区3的历史分区表自动转入OSS存储,函数将返回任务ID:-- 每分钟执行 SELECT cron.schedule_in_database('task1', '* * * * *', 'select polar_alter_subpartition_to_oss(''traj'', 3);', 'db01');返回结果如下:
schedule_in_database ---------------------- 1查看执行结果及历史执行记录。
在测试数据库中使用psql工具查看分区表的存储位置:
\d+ traj_202301返回结果如下:
Table "public.traj_202301" Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description ---------+--------------------------------+-----------+----------+-------------------------------------+---------+-------------+--------------+------------- tr_id | integer | | not null | nextval('traj_tr_id_seq'::regclass) | plain | | | tr_lon | double precision | | | | plain | | | tr_lat | double precision | | | | plain | | | tr_time | timestamp(6) without time zone | | | | plain | | | Partition of: traj FOR VALUES FROM ('2023-01-01 00:00:00') TO ('2023-02-01 00:00:00') Partition constraint: ((tr_time IS NOT NULL) AND (tr_time >= '2023-01-01 00:00:00'::timestamp(6) without time zone) AND (tr_time < '2023-02-01 00:00:00'::timestamp(6) without time zone)) Replica Identity: FULL Tablespace: "oss" --已经存储在OSS Access method: heap可在
postgres数据库中查看定时任务历史执行记录。SELECT * FROM cron.job_run_details;
该实践实现按自定义规则自动将过期分区表转为冷存,冷存后的分区表不再占用云盘存储空间,大大降低存储成本,同时增删改查操作也完全透明。
案例二:单表大字段分层存储
背景描述
大字段包括BLOB、TEXT、JSON、JSONB、ANYARRAY以及时空引擎类型的字段,本案例旨在介绍如何将一张表中的大字段分离并独立存储于OSS中,同时实现访问的透明性,以达到通过按字段维度进行冷热数据分离以降低成本的目的。
操作步骤
创建包含大字段的表。当前以
TEXT类型为例,其余类型大字段使用方法类似。CREATE TABLE blob_table(id serial, val text);设置大字段存储位置。
ALTER TABLE blob_table ALTER COLUMN val SET (storage_type='oss');写入数据并查看存储。
写入数据,此时val字段完全存储在OSS中。
INSERT INTO blob_table(val) VALUES((SELECT string_agg(random()::text, ':') FROM generate_series(1, 100000)));查看val字段存储位置。
WITH tmp AS (SELECT 'pg_toast_'||b.oid||'_'||c.attnum AS tblname FROM pg_class b, pg_attribute c WHERE b.relname='blob_table' AND c.attrelid=b.oid AND c.attname='val') SELECT t.spcname AS storage_engine FROM pg_tablespace t, pg_class r, tmp m WHERE r.relname = m.tblname AND t.oid=r.reltablespace;返回结果如下:
storage_engine ---------------- oss (1 row)
只有在先调用
ALTER COLUMN的SQL语句设置大字段的存储位置之后写入的数据才会真正存储至OSS。对于已有的数据表,如果希望将某个大字段转存至OSS,可以先调用
ALTER COLUMN的SQL语句设置大字段的存储位置,然后执行VACUUM FULL,将数据重新写入。如果不执行VACUUM FULL,历史数据将继续保存在云盘中,而新写入的数据则将存储在OSS,该语句是否执行不影响对表数据的增删改查操作。需要注意的是,如果数据量较大,执行时间可能会较长,并且在执行过程中,该数据表将无法提供读写服务。
案例三:时空分析场景如何实现降本增效(高级进阶案例)
时空分析是指利用数据库的能力,对全空间、时空及时序场景中的数据进行数据挖掘、统计分析等功能。当前将以遥感影像的统计分析为例,介绍时空分析场景如何通过多态(冷热)分层存储功能降低存储成本,同时保持良好的分析效率。
本案例为高级进阶实践,您可以选择性地忽略中间处理步骤,直接关注最终的对比结果。
背景描述
遥感影像(栅格)数据在空间业务中的应用日益广泛。由于遥感数据的体量较大,并且通常涉及影像浏览与分析统计等多项业务,针对分析统计类的非实时业务,降低存储成本并提升易用性往往具有更大的吸引力。本案例将介绍如何利用经济实惠的OSS存储支持遥感影像的入库管理,并提供同样高效的统计分析功能。
操作步骤
数据准备。准备四幅landset遥感影像数据(您可自行准备此类数据)。

遥感影像数据入库。
创建测试数据库rastdb。
在测试数据库中安装ganos_raster插件,详细介绍请参见栅格模型。
CREATE EXTENSION ganos_raster CASCADE;导入影像数据。
CREATE TABLE raster_table (id integer, rast raster); INSERT INTO raster_table VALUES (1, ST_ImportFrom('rbt','/home/postgres/LC08_L1TP_113028_20190912_20190917_01_T1.TIF')); INSERT INTO raster_table VALUES (2, ST_ImportFrom('rbt','/home/postgres/LC08_L1TP_113029_20191030_20191114_01_T1.TIF')); INSERT INTO raster_table VALUES (3, ST_ImportFrom('rbt','/home/postgres/LC08_L1TP_114028_20191005_20191018_01_T1.TIF')); INSERT INTO raster_table VALUES (4, ST_ImportFrom('rbt','/home/postgres/LC08_L1TP_114029_20200905_20200917_01_T1.TIF'));
统计数据占用的存储空间。在Ganos中,Raster类型是一种元数据和块数据单独存储、统一管理的模式,基表中存储了影像的元数据,块表中存储了影像的块数据,为了方便统计块表中数据大小,这里需要手动创建存储过程:
CREATE OR REPLACE FUNCTION raster_data_internal_total_size( rast_table_name text, rast_column_name text) RETURNS int8 AS $$ DECLARE sql text; sql2 text; rec record; size int8; totalsize int8; tbloid Oid; BEGIN size := 0; totalsize := 0; --查询raster对象的块数据表 sql = format('select distinct(st_datalocation(%s)) as tblname from %s where st_rastermode(%s) = ''INTERNAL'';', rast_column_name, rast_table_name, rast_column_name); for rec in execute sql loop sql2 = format('select a.oid from pg_class a, pg_tablespace b where a.reltablespace = b.oid and b.spcname=''oss'' and a.relname=''%s'';', rec.tblname); execute sql2 into tbloid; if (tbloid > 0) then size := 0; else --统计每张数据表的大小 sql2 = format('select pg_total_relation_size(''%s'');',rec.tblname); execute sql2 into size; end if; totalsize := (totalsize + size); end loop; return totalsize; END; $$ LANGUAGE plpgsql;创建存储过程完成后,执行统计,结果表示目前影像数据占用的数据库存储空间在1.2 GB左右。
SELECT pg_size_pretty(raster_data_internal_total_size('raster_table','rast'));返回结果如下:
pg_size_pretty ---------------- 1319 MB (1 row)统计NDVI。数据存储在云盘。首先进行一次NDVI统计。在统计过程中,需要对多幅影像数据进行嵌套拼接(mosaic),利用拼接得到的完整影像进行NDVI计算,并统计所需时间,详细介绍请参见ST_MosaicFrom。
CREATE TABLE rast_mapalgebra_result(id integer, rast raster); INSERT INTO rast_mapalgebra_result SELECT 1, ST_MapAlgebra(ARRAY(SELECT st_mosaicfrom(ARRAY(SELECT rast FROM raster_table ORDER BY id), 'rbt_mosaic','','{"srid":4326,"cell_size":[0.005,0.005]')), '[{"expr":"([0,3] - [0,2])/([0,3] + [0,2])","nodata": true, "nodataValue":0}]', '{"chunktable":"rbt_algebra","celltype":"32bf"}');返回结果如下:
INSERT 0 1 Time: 39874.189 ms (00:39.874)影像块数据冷存处理。将遥感影像的块数据做冷存处理存入OSS,遥感影像的元数据依旧存储在云盘中,为了方便处理,需要创建存储过程:
CREATE OR REPLACE FUNCTION raster_data_alter_to_oss( rast_table_name text, rast_column_name text) RETURNS VOID AS $$ DECLARE sql text; sql2 text; rec record; BEGIN --查询raster对象的数据表 sql = format('select distinct(st_datalocation(%s)) as tblname from %s where st_rastermode(%s) = ''INTERNAL'';', rast_column_name, rast_table_name, rast_column_name); for rec in execute sql loop sql2 = format('alter table %s set tablespace oss;',rec.tblname); execute sql2; end loop; END; $$ LANGUAGE plpgsql;创建完存储过程后,执行冷存处理,冷存后再次统计块数据表占用的云盘存储空间:
SELECT raster_data_alter_to_oss('raster_table', 'rast'); --统计冷存后块数据在云盘占用的空间 SELECT pg_size_pretty(raster_data_internal_total_size('raster_table','rast'));返回结果显示共享盘统计的存储空间为0,说明此时块数据都已经存储在OSS中。
pg_size_pretty ---------------- 0 bytes (1 row)重新统计NDVI值。数据块存储在OSS中后,重新做一次NDVI统计计算:
INSERT INTO rast_mapalgebra_result select 2, ST_MapAlgebra(ARRAY(select st_mosaicfrom(ARRAY(SELECT rast FROM raster_table ORDER BY id), 'rbt_mosaic','','{"srid":4326,"cell_size":[0.005,0.005]')), '[{"expr":"([0,3] - [0,2])/([0,3] + [0,2])","nodata": true, "nodataValue":0}]', '{"chunktable":"rbt_algebra","celltype":"32bf"}');返回结果如下:
INSERT 0 1 Time: 69414.201 ms (01:09.414)
存储成本及性能表现对比。
对比项
云盘存储
OSS冷存
对比值
存储成本
1319 MB,按1.5 元/GB/月,费用为1.9元。
1319 MB,按0.238 美元/GB/月,费用为0.31美元。
1011.834 MB 按0.15 元/GB/月,费用为0.15元。
10:1
NDVI统计耗时
39s
69s
1:1.76
对比结果显示,使用OSS冷存的费用为共享盘的1/10以下,且计算性能降低控制在1倍以内。这一性价比在不追求实时性(RT)的统计分析场景中具有相当高的价值。
总结
目前,Ganos已成功支撑数十个行业领域的数千个应用场景。稳定性、成本效益、性能与易用性始终是Ganos长期追求的目标。全空间多态存储能力是Ganos在PolarDB PostgreSQL版(兼容Oracle)数据库上构建的内核级核心竞争力,能够为全空间数据管理提供真正兼顾成本、性能与易用性的解决方案,欢迎您开通体验。