本文介绍了PolarDB PostgreSQL版(兼容Oracle)的业务低谷期垃圾回收功能的使用方法以及示例等内容。
前提条件
支持的PolarDB PostgreSQL版(兼容Oracle)的版本如下:
Oracle语法兼容 2.0(内核小版本2.0.14.12.24.0及以上)
背景信息
PolarDB PostgreSQL版(兼容Oracle)与原生PostgreSQL一样会在后台启动自动清理(autovacuum)进程去执行垃圾回收操作,它带来的收益包括但不限于:
回收老旧版本的数据以减少磁盘空间占用。
更新统计信息以确保查询优化器能够选择最优执行计划。
防止事务ID回卷,从而有效降低集群不可用的风险。
这些垃圾回收操作比较消耗硬件资源,为了避免过于频繁地执行自动清理,原生PostgreSQL为其设置了一些触发条件(详情请参见自动清理参数配置),只有满足这些条件时才会启动清理进程。 由于触发条件与数据变更行数和数据库年龄相关,越是在业务的高峰期,数据变更往往越多,事务ID消耗速度越快,自动清理的触发频率就越高,导致了如下问题:
资源使用过高问题:在业务高峰期间自动清理进程频繁执行垃圾回收并占用大量CPU和I/O,与业务读写请求争抢硬件资源,影响数据库的读写性能。在下图的示例中,自动清理进程在白天业务高峰期间的CPU使用率和I/O吞吐量在所有进程中排名第一。
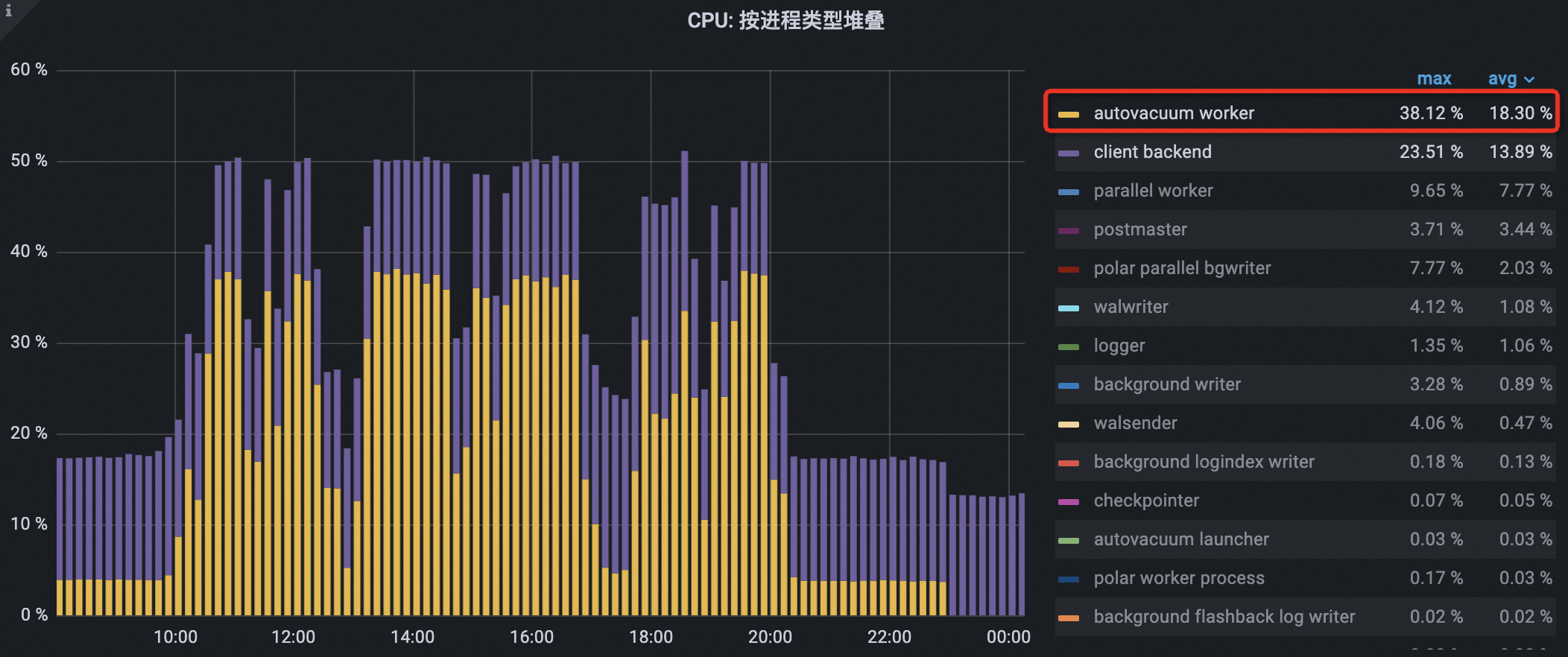
锁表阻塞读写问题:自动清理进程在回收空页的过程中需要短暂持有排它锁并阻塞单张表上的业务请求,虽然阻塞时间一般不长,但是在业务高峰期间即使很短暂的阻塞也无法接受。
计划缓存失效问题:自动清理进程收集统计信息并导致原有的执行计划缓存(Plan Cache)失效,新的查询需要重新生成执行计划,可能发生业务高峰期间有多个连接并行生成执行计划的情况,影响多个连接的业务请求响应时间。
说明PolarDB PostgreSQL版(兼容Oracle)的全局执行计划缓存功能可以一定程度减少此类问题的影响。
以上问题的核心在于原生PostgreSQL没有业务低谷期的概念,而现实场景下的业务通常有明显的高峰期和低谷期。PolarDB PostgreSQL版(兼容Oracle)允许配置一个业务低谷期间的时间窗口,利用业务低谷期的闲置硬件资源进行积极和充分的垃圾回收,从而降低业务高峰期间的自动清理频次,将更多的硬件资源留给业务读写请求,优化读写性能。
预期收益
业务低谷期内的垃圾回收预期可以缓解上文提到的各种问题,此外由于业务低谷期内的清理策略相比于原生PostgreSQL的自动清理更为积极,因此还可能有一些额外的收益。总的来说有如下收益:
资源使用率优化:业务低谷期内已经进行了垃圾回收,导致业务高峰期内的自动清理概率大幅下降,资源使用率也相应下降。
数据库年龄优化:业务低谷期内回收更多事务ID,防止事务ID回卷造成的数据库不可用问题。
统计信息&慢SQL优化:收集更多表的统计信息,帮助优化器选择更为准确的查询计划,减少统计信息过期导致的慢SQL。
锁表问题优化:业务高峰期内自动清理操作锁表导致阻塞业务读写的问题发生概率降低。
计划缓存失效问题优化:业务高峰期内自动清理操作导致计划缓存失效的问题发生概率降低。
使用方法
配置业务低谷期信息
创建插件。
在postgres数据库和所有需要执行垃圾回收的数据库上都需要创建
polar_advisor插件。CREATE EXTENSION IF NOT EXISTS polar_advisor;对于已经安装
polar_advisor插件的PolarDB集群,可通过以下命令升级:ALTER EXTENSION polar_advisor UPDATE;时间窗口设置。
执行如下命令设置业务低谷期时间段。
-- 在postgres数据库执行 SELECT polar_advisor.set_advisor_window(start_time, end_time);start_time:表示窗口开始时间。
end_time:表示窗口结束时间。
窗口默认会当天生效,之后每天都会自动在窗口时间段内执行垃圾回收操作。
说明仅在postgres数据库中配置的窗口时间会生效,在其他数据库上设置窗口时间无效。
窗口时间中的时区偏移量必须与PolarDB集群的时区设置保持一致,否则窗口时间无法生效。
将北京时间(东八区,+08时区)的每天晚上23点到第二天凌晨2点这个时间段作为业务低谷期,该集群每天都会在这个时间段内执行垃圾回收操作,示例如下:
SELECT polar_advisor.set_advisor_window(start_time => '23:00:00+08', end_time => '02:00:00+08');时间窗口查看。
执行如下命令查看设置的业务低谷期信息。
-- 在 postgres 数据库执行 -- 查看业务低谷期详情 SELECT * FROM polar_advisor.get_advisor_window(); -- 查看业务低谷期时间长度,单位为秒 SELECT polar_advisor.get_advisor_window_length(); -- 查看当前时间是否在窗口时间内 SELECT now(), * FROM polar_advisor.is_in_advisor_window(); -- 查看当前时间距离下一次窗口开始时间的时长,单位为秒 SELECT * FROM polar_advisor.get_secs_to_advisor_window_start(); -- 查看当前时间距离下一次窗口结束时间的时长,单位为秒 SELECT * FROM polar_advisor.get_secs_to_advisor_window_end();示例如下:
-- 查看业务低谷期详情 postgres=# SELECT * FROM polar_advisor.get_advisor_window(); start_time | end_time | enabled | last_error_time | last_error_detail | others -------------+-------------+---------+-----------------+-------------------+-------- 23:00:00+08 | 02:00:00+08 | t | | | (1 row) -- 查看业务低谷期时间长度 postgres=# SELECT polar_advisor.get_advisor_window_length() / 3600.0 AS "窗口长度/h"; 窗口长度/h -------------------- 3.0000000000000000 (1 row) -- 查看当前时间是否在窗口时间内 postgres=# SELECT now(), * FROM polar_advisor.is_in_advisor_window(); now | is_in_advisor_window -------------------------------+---------------------- 2024-04-01 07:40:37.733911+00 | f (1 row) -- 查看当前时间距离下一次窗口开始时间的时长 postgres=# SELECT * FROM polar_advisor.get_secs_to_advisor_window_start(); secs_to_window_start | time_now | window_start | window_end ----------------------+--------------------+--------------+------------- 26362.265179 | 07:40:37.734821+00 | 15:00:00+00 | 18:00:00+00 (1 row) -- 查看当前时间距离下一次窗口结束时间的时长 postgres=# SELECT * FROM polar_advisor.get_secs_to_advisor_window_end(); secs_to_window_end | time_now | window_start | window_end --------------------+--------------------+--------------+------------- 36561.870337 | 07:40:38.129663+00 | 15:00:00+00 | 18:00:00+00 (1 row)关闭/开启窗口。
设置窗口后,窗口默认开启,会在每天的窗口时间内执行垃圾回收。如果某一天的业务低谷期内不希望集群执行垃圾回收(例如需要手动执行其他运维操作,担心与垃圾回收冲突),则可以执行以下命令来关闭业务低谷期,等到运维工作结束以后再调用函数重新开启窗口。
-- 在 postgres 数据库执行 -- 关闭业务低谷期垃圾回收 SELECT polar_advisor.disable_advisor_window(); -- 开启业务低谷期垃圾回收 SELECT polar_advisor.enable_advisor_window(); -- 查看窗口是否已开启 SELECT polar_advisor.is_advisor_window_enabled();示例如下:
-- 窗口已开启 postgres=# SELECT polar_advisor.is_advisor_window_enabled(); is_advisor_window_enabled --------------------------- t (1 row) -- 关闭窗口 postgres=# SELECT polar_advisor.disable_advisor_window(); disable_advisor_window ------------------------ (1 row) -- 窗口已关闭 postgres=# SELECT polar_advisor.is_advisor_window_enabled(); is_advisor_window_enabled --------------------------- f (1 row) -- 重新开启窗口 postgres=# SELECT polar_advisor.enable_advisor_window(); enable_advisor_window ----------------------- (1 row) -- 窗口已开启 postgres=# SELECT polar_advisor.is_advisor_window_enabled(); is_advisor_window_enabled --------------------------- t (1 row)
其他配置
设置黑名单。
如果配置了业务低谷期,默认情况下数据库会自行决定在窗口期内对哪些表执行垃圾回收操作,任何一张表都有可能被执行。如果希望某张表不要被选中,则可以通过以下命令将该表加入到黑名单中。
-- 在具体的业务数据库中执行 -- 将表加入VACUUM & ANALYZE黑名单 SELECT polar_advisor.add_relation_to_vacuum_analyze_blacklist(schema_name, relation_name); -- 验证表是否在VACUUM & ANALYZE黑名单中 SELECT polar_advisor.is_relation_in_vacuum_analyze_blacklist(schema_name, relation_name); -- 获取VACUUM & ANALYZE黑名单 SELECT * FROM polar_advisor.get_vacuum_analyze_blacklist();示例如下:
-- 将 public.t1 表加入黑名单 postgres=# SELECT polar_advisor.add_relation_to_vacuum_analyze_blacklist('public', 't1'); add_relation_to_vacuum_analyze_blacklist --------------------------- t (1 row) -- 查看该表是否在黑名单中 postgres=# SELECT polar_advisor.is_relation_in_vacuum_analyze_blacklist('public', 't1'); is_relation_in_vacuum_analyze_blacklist -------------------------- t (1 row) -- 获取完整的黑名单列表,查看该表是否在黑名单中 postgres=# SELECT * FROM polar_advisor.get_vacuum_analyze_blacklist(); schema_name | relation_name | action_type -------------+---------------+---------------- public | t1 | VACUUM ANALYZE (1 row)设置活跃连接数阈值。
为了避免业务低谷期内的垃圾回收操作影响正常业务,系统会自动检测业务低谷期间的活跃连接数,超出阈值时将自动取消垃圾回收操作的执行,您可以手动调整该阈值以适应您的业务特性(阈值默认为5~10,具体与集群的CPU核数有关)。
-- 在 postgres 数据库执行 -- 获取业务低谷期可以接受的连接数阈值,实际的活跃连接数高于该值就不会执行垃圾回收 SELECT polar_advisor.get_active_user_conn_num_limit(); -- 在业务低谷期内执行 SQL,获取业务低谷期的实际活跃连接数(或者通过 PolarDB 控制台->性能监控->高级监控->标准试图->会话连接->active_session查看) SELECT COUNT(*) FROM pg_catalog.pg_stat_activity sa JOIN pg_catalog.pg_user u ON sa.usename = u.usename WHERE sa.state = 'active' AND sa.backend_type = 'client backend' AND NOT u.usesuper; -- 人为设置活跃连接数阈值,将覆盖系统默认的阈值 SELECT polar_advisor.set_active_user_conn_num_limit(active_user_conn_limit); -- 取消设置活跃连接数阈值,将恢复使用系统默认的阈值 SELECT polar_advisor.unset_active_user_conn_num_limit();示例如下:
-- 获取实例默认活跃连接数阈值,该实例阈值为5(不同实例的阈值可能不同,具体与CPU核数有关) postgres=# SELECT polar_advisor.get_active_user_conn_num_limit(); NOTICE: get active user conn limit by CPU cores number get_active_user_conn_num_limit -------------------------------- 5 (1 row) -- 获取当前实际活跃连接数,结果为8,大于上面获取的阈值5,因此系统会认为活跃连接数较多,不能在业务低谷期时间内执行垃圾回收 postgres=# SELECT COUNT(*) FROM pg_catalog.pg_stat_activity sa JOIN pg_catalog.pg_user u ON sa.usename = u.usename postgres-# WHERE sa.state = 'active' AND sa.backend_type = 'client backend' AND NOT u.usesuper; count ------- 8 (1 row) -- 将活跃连接数阈值设为10,大于实际的活跃连接数8,系统会认为实际的活跃连接数8没有超过阈值10,可以执行垃圾回收 postgres=# SELECT polar_advisor.set_active_user_conn_num_limit(10); set_active_user_conn_num_limit -------------------------------- (1 row) -- 查看活跃连接数阈值,显示为10,就是上一步手动设置的值 postgres=# SELECT polar_advisor.get_active_user_conn_num_limit(); NOTICE: get active user conn limit from table get_active_user_conn_num_limit -------------------------------- 10 (1 row) -- 取消设置活跃连接数阈值 postgres=# SELECT polar_advisor.unset_active_user_conn_num_limit(); unset_active_user_conn_num_limit ---------------------------------- (1 row) -- 取消设置以后,活跃连接数阈值恢复到默认值5 postgres=# SELECT polar_advisor.get_active_user_conn_num_limit(); NOTICE: get active user conn limit by CPU cores number get_active_user_conn_num_limit -------------------------------- 5 (1 row)
查看结果
业务低谷期内执行的垃圾回收操作的结果和收益都记录在postgres数据库的日志表中,保留最近90天的数据。
表结构
polar_advisor.db_level_advisor_log表保存了数据库级别的每一轮垃圾回收操作的各项信息。
CREATE TABLE polar_advisor.db_level_advisor_log (
id BIGSERIAL PRIMARY KEY,
exec_id BIGINT,
start_time TIMESTAMP WITH TIME ZONE,
end_time TIMESTAMP WITH TIME ZONE,
db_name NAME,
event_type VARCHAR(100),
total_relation BIGINT,
acted_relation BIGINT,
age_before BIGINT,
age_after BIGINT,
others JSONB
);参数说明:
参数名称 | 说明 |
id | 表示表的主键,自动递增。 |
exec_id | 表示执行的轮次,通常每天运行一轮,一轮可以操作多个数据库,所以当天的多条记录的 |
start_time | 表示操作开始的时间。 |
end_time | 表示操作结束的时间。 |
db_name | 表示操作的数据库名称。 |
event_type | 表示操作类型,当前仅支持 |
total_relation | 表示表中可以被操作的表和索引数量。 |
acted_relation | 表示实际操作的表和索引数量。 |
age_before | 表示操作前的数据库年龄。 |
age_after | 表示操作后的数据库年龄。 |
others | 包含较多扩展的统计数据:
|
polar_advisor.advisor_log表保存了表/索引级别的每一次垃圾回收操作的详细信息,polar_advisor.db_level_advisor_log表中的一条记录对应polar_advisor.advisor_log表的多条记录。
CREATE TABLE polar_advisor.advisor_log (
id BIGSERIAL PRIMARY KEY,
exec_id BIGINT,
start_time TIMESTAMP WITH TIME ZONE,
end_time TIMESTAMP WITH TIME ZONE,
db_name NAME,
schema_name NAME,
relation_name NAME,
event_type VARCHAR(100),
sql_cmd TEXT,
detail TEXT,
tuples_deleted BIGINT,
tuples_dead_now BIGINT,
tuples_now BIGINT,
pages_scanned BIGINT,
pages_pinned BIGINT,
pages_frozen_now BIGINT,
pages_truncated BIGINT,
pages_now BIGINT,
idx_tuples_deleted BIGINT,
idx_tuples_now BIGINT,
idx_pages_now BIGINT,
idx_pages_deleted BIGINT,
idx_pages_reusable BIGINT,
size_before BIGINT,
size_now BIGINT,
age_decreased BIGINT,
others JSONB
);参数说明:
参数名称 | 说明 |
id | 表示表的主键,自动递增。 |
exec_id | 表示执行的轮次,通常每天运行一轮,一轮可以操作多个数据库,所以当天的多条记录的 |
start_time | 表示操作开始的时间。 |
end_time | 表示操作结束的时间。 |
db_name | 表示操作的数据库名称。 |
schema_name | 表示操作的数据库模式名称。 |
relation_name | 表示操作的数据库表/索引名称。 |
event_type | 表示操作类型,当前仅支持 |
sql_cmd | 表示具体执行的操作命令,例如 |
detail | 表示操作的结果详情,例如 |
tuples_deleted | 表示本次操作中表回收的死元组数量。 |
tuples_dead_now | 表示本次操作后表中遗留的死元组数量。 |
tuples_now | 表示本次操作后表的活元组数量。 |
pages_scanned | 表示本次操作中扫描的页数。 |
pages_pinned | 表示本次操作中因为缓存被引用而无法删除的页数。 |
pages_frozen_now | 表示本次操作后被冻结的页数。 |
pages_truncated | 表示本次操作中删除/截断的空页数。 |
pages_now | 表示本次操作后表的页数。 |
idx_tuples_deleted | 表示本次操作中回收的索引死元组数量。 |
idx_tuples_now | 表示本次操作后索引的活元组数量。 |
idx_pages_now | 表示本次操作后索引的页数。 |
idx_pages_deleted | 表示本次操作中删除的索引页数。 |
idx_pages_reusable | 表示本次操作中重新利用的索引页数。 |
size_before | 表示本次操作前的表/索引大小。 |
size_after | 表示本次操作后的表/索引大小。 |
age_decreased | 表示本次操作前后的表年龄下降大小。 |
others | 表示扩展的统计数据。 |
统计数据
查看近期每一轮垃圾回收记录的开始时间、结束时间、操作的表/索引数量,示例如下:
-- 在 postgres 数据库执行 SELECT COUNT(*) AS "表/索引数量", MIN(start_time) AS "开始时间", MAX(end_time) AS "结束时间", exec_id AS "轮次" FROM polar_advisor.advisor_log GROUP BY exec_id ORDER BY exec_id DESC;结果显示如下,可以看到最近3轮执行垃圾回收的表数量都在4390左右,执行时间都在凌晨1-4点。
表/索引数量 | 开始时间 | 结束时间 | 轮次 -------------+--------------------------------+--------------------------------+------ 4391 | 2024-09-23 01:00:09.413901 +08 | 2024-09-23 03:25:39.029702 +08 | 139 4393 | 2024-09-22 01:03:07.365759 +08 | 2024-09-22 03:37:45.227067 +08 | 138 4393 | 2024-09-21 01:03:08.094989 +08 | 2024-09-21 03:45:20.280011 +08 | 137查看近期每天内执行垃圾回收的表/索引数量,按日期统计,示例如下:
-- 在 postgres 数据库执行 SELECT start_time::pg_catalog.date AS "时间", count(*) AS "表/索引数量" FROM polar_advisor.advisor_log GROUP BY start_time::pg_catalog.date ORDER BY start_time::pg_catalog.date DESC, count(*) DESC;结果显示如下,可以看到最近3天内每一天执行垃圾回收的表数量都在4390左右。
时间 | 表/索引数量 ------------+------------- 2024-09-23 | 4391 2024-09-22 | 4393 2024-09-21 | 4393查看最近执行垃圾回收的表/索引数量,按日期和数据库统计,示例如下:
-- 在 postgres 数据库执行 SELECT start_time::pg_catalog.date AS "时间", count(*) AS "表/索引数量" FROM polar_advisor.advisor_log GROUP BY start_time::pg_catalog.date ORDER BY start_time::pg_catalog.date DESC, count(*) DESC;结果显示如下,可以看到最近3天对postgres、db_123、db_12345、db_123456789这些数据库执行过垃圾回收,每个数据库执行了几十个到几百个表/索引不等。
时间 | DB | 表/索引数量 -------------+----------------+------------- 2024-03-05 | db_123456789 | 697 2024-03-05 | db_123 | 277 2024-03-04 | db_123456789 | 695 2024-03-04 | db_123 | 267 2024-03-04 | db_12345 | 174 2024-03-03 | postgres | 65 (6 rows)
详细数据
查看近期执行垃圾回收的数据库的收益信息,示例如下:
-- 在 postgres 数据库执行 SELECT id, start_time AS "开始时间", end_time AS "结束时间", db_name AS "数据库", event_type AS "操作类型", total_relation AS "数据库总表数量", acted_relation AS "操作的表数量", CASE WHEN others->>'cluster_age_before' IS NOT NULL AND others->>'cluster_age_after' IS NOT NULL THEN (others->>'cluster_age_before')::BIGINT - (others->>'cluster_age_after')::BIGINT ELSE NULL END AS "年龄下降", CASE WHEN others->>'db_size_before' IS NOT NULL AND others->>'db_size_after' IS NOT NULL THEN (others->>'db_size_before')::BIGINT - (others->>'db_size_after')::BIGINT ELSE NULL END AS "存储空间下降" FROM polar_advisor.db_level_advisor_log ORDER BY id DESC;结果显示如下,可以看到最近三次执行的操作都是
VACUUM。id | 开始时间 | 结束时间 | 数据库 | 操作类型 | 数据库总表数量 | 操作的表数量 | 年龄下降 | 存储空间下降 ---------+-------------------------------+-------------------------------+----------------+----------+----------------+--------------+----------+-------------- 1184 | 2024-03-05 00:44:26.776894+08 | 2024-03-05 00:45:56.396519+08 | db_12345 | VACUUM | 174 | 164 | 694 | 0 1183 | 2024-03-05 00:43:30.243505+08 | 2024-03-05 00:44:26.695602+08 | db_123456789 | VACUUM | 100 | 90 | 396 | 0 1182 | 2024-03-05 00:41:47.70952+08 | 2024-03-05 00:43:30.172527+08 | db_12345 | VACUUM | 163 | 153 | 701 | 0 (3 rows)查看近期执行垃圾回收的表的收益信息,示例如下:
-- 在 postgres 数据库执行 SELECT start_time AS "开始时间", end_time AS "结束时间", db_name AS "数据库", schema_name AS "模式", relation_name AS "表/索引", event_type AS "操作类型", tuples_deleted AS "回收死元组数", pages_scanned AS "扫描页数",pages_truncated AS "回收页数", idx_tuples_deleted AS "回收索引死元组数", idx_pages_deleted AS "回收索引页数", age_decreased AS "表年龄下降" FROM polar_advisor.advisor_log ORDER BY id DESC;结果显示如下,可以看到最近三次操作回收的死元组数量、回收的页数、表年龄下降等信息。
开始时间 | 结束时间 | 数据库 | 模式 | 表/索引 | 操作类型 | 回收死元组数 | 扫描页数 | 回收页数 | 回收索引死元组数 | 回收索引页数 | 表年龄下降 -------------------------------+-------------------------------+----------+--------+--------+---------+------------+---------+---------+---------------+------------+------------ 2024-03-05 00:45:56.204254+08 | 2024-03-05 00:45:56.357263+08 | db_12345 | public | cccc | VACUUM | 0 | 33 | 0 | 0 | 0 | 1345944 2024-03-05 00:45:56.068499+08 | 2024-03-05 00:45:56.200036+08 | db_12345 | public | aaaa | VACUUM | 0 | 28 | 0 | 0 | 0 | 1345946 2024-03-05 00:45:55.945677+08 | 2024-03-05 00:45:56.065316+08 | db_12345 | public | bbbb | VACUUM | 0 | 0 | 0 | 0 | 0 | 1345947 (3 rows)查看数据库年龄下降最多的操作记录。
PolarDB PostgreSQL版(兼容Oracle)共有约21亿个可用的事务ID,通过数据库年龄来衡量已经消耗的事务ID数量,年龄达到21亿时将发生事务ID回卷,数据库将不可用,因此数据库年龄越小越好。
-- 在 postgres 数据库执行 -- 获取数据库实例年龄下降最大的记录对应的数据库和操作类型 SELECT id, exec_id AS "轮次", start_time AS "开始时间", end_time AS "结束时间", db_name AS "数据库", event_type AS "操作类型", CASE WHEN others->>'cluster_age_before' IS NOT NULL AND others->>'cluster_age_after' IS NOT NULL THEN (others->>'cluster_age_before')::BIGINT - (others->>'cluster_age_after')::BIGINT ELSE NULL END AS "年龄下降" FROM polar_advisor.db_level_advisor_log ORDER BY "年龄下降" DESC NULLS LAST; -- 根据上一步获取的轮次信息获取该轮操作中具体导致数据库年龄下降的详细记录 SELECT id, start_time AS "开始时间", end_time AS "结束时间", db_name AS "数据库", schema_name AS "模式", relation_name AS "表名", sql_cmd AS "命令", event_type AS "操作类型", age_decreased AS "年龄下降" FROM polar_advisor.advisor_log WHERE exec_id = 91 ORDER BY "年龄下降" DESC NULLS LAST; -- 获取当前数据库年龄(任何一个数据库皆可执行)(或者通过 PolarDB 控制台->性能监控->高级监控->标准试图->Vacuum->db_age 查看) SELECT MAX(pg_catalog.age(datfrozenxid)) AS "实例年龄" FROM pg_catalog.pg_database;结果显示如下:
-- 2024-02-22 这天对 aaaaaaaaaaaaa 这个数据库执行的 vacuum 操作让数据库年龄下降了 9275406,也就是接近一千万,执行轮次为 91 postgres=# SELECT id, exec_id AS "轮次", start_time AS "开始时间", end_time AS "结束时间", db_name AS "数据库", event_type AS "操作类型", CASE WHEN others->>'cluster_age_before' IS NOT NULL AND others->>'cluster_age_after' IS NOT NULL THEN (others->>'cluster_age_before')::BIGINT - (others->>'cluster_age_after')::BIGINT ELSE NULL END AS "年龄下降" FROM polar_advisor.db_level_advisor_log ORDER BY "年龄下降" DESC NULLS LAST; id | 轮次 | 开始时间 | 结束时间 | 数据库 | 操作类型 | 年龄下降 --------+------+-------------------------------+-------------------------------+---------------+----------+---------- 259 | 91 | 2024-02-22 00:00:18.847978+08 | 2024-02-22 00:14:18.785085+08 | aaaaaaaaaaaaa | VACUUM | 9275406 256 | 90 | 2024-02-21 00:00:39.607552+08 | 2024-02-21 00:00:42.054733+08 | bbbbbbbbbbbbb | VACUUM | 7905122 262 | 92 | 2024-02-23 00:00:05.999423+08 | 2024-02-23 00:00:08.411993+08 | postgres | VACUUM | 578308 -- 根据执行轮次 91 获取详细的 vacuum 记录,可以看到主要是一些 pg_catalog 系统表的 vacuum 操作使得数据库年龄下降 postgres=# SELECT id, start_time AS "开始时间", end_time AS "结束时间", db_name AS "数据库", schema_name AS "模式", relation_name AS "表名", event_type AS "操作类型", age_decreased AS "年龄下降" FROM polar_advisor.advisor_log WHERE exec_id = 91 ORDER BY "年龄下降" DESC NULLS LAST; id | 开始时间 | 结束时间 | 数据库 | 模式 | 表名 | 操作类型 | 年龄下降 ----------+-------------------------------+-------------------------------+-------+------------+--------------------+---------+---------- 43933 | 2024-02-22 00:00:19.070493+08 | 2024-02-22 00:00:19.090822+08 | abc | pg_catalog | pg_subscription | VACUUM | 27787409 43935 | 2024-02-22 00:00:19.116292+08 | 2024-02-22 00:00:19.13875+08 | abc | pg_catalog | pg_database | VACUUM | 27787408 43936 | 2024-02-22 00:00:19.140992+08 | 2024-02-22 00:00:19.171938+08 | abc | pg_catalog | pg_db_role_setting | VACUUM | 27787408 -- 当前实例年龄为两千多万,距离阈值 21 亿还有很远,非常安全 postgres=> SELECT MAX(pg_catalog.age(datfrozenxid)) AS "实例年龄" FROM pg_catalog.pg_database; 实例年龄 ---------- 20874380 (1 row)
优化效果示例
以下展示部分集群在配置业务低谷期以后的资源使用量和数据库年龄的优化效果。
锁表阻塞读写、计划缓存失效等问题的优化效果不太好通过图表的方式展示,因此不作展示。
并非所有集群都能取得示例中这么好的优化效果,实际效果与具体业务场景有关。导致提升效果不明显的原因有很多,例如有些集群全天业务都很繁忙且没有明显的业务低谷期,有些集群的业务低谷期则配置了一些任务来执行数据分析、数据导入、物化视图刷新等操作,没有太多闲置资源可供垃圾回收操作使用。
内存使用量优化效果
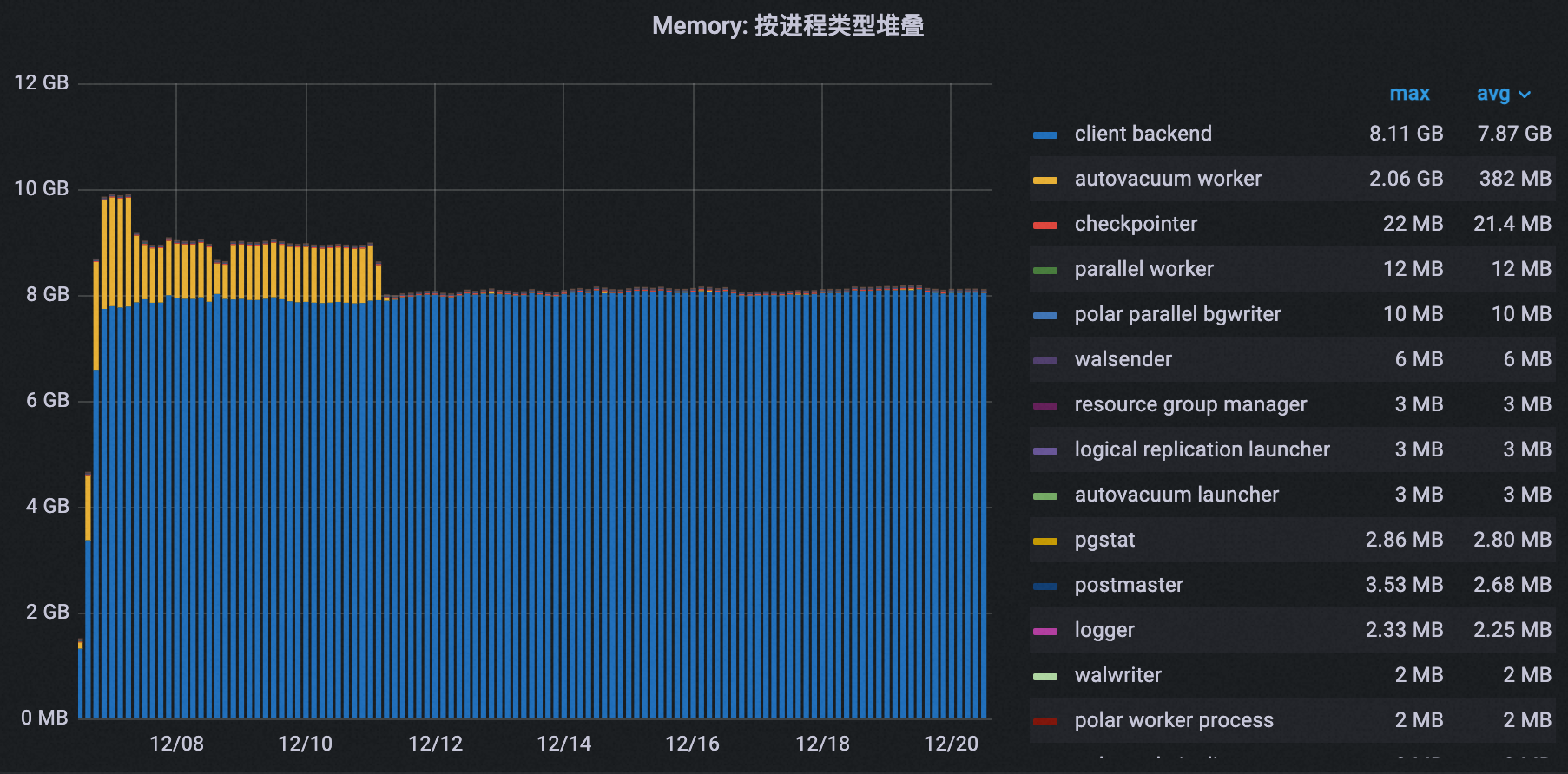
如下图所示,在配置业务低谷期垃圾回收之后,集群的自动清理进程内存使用量峰值从2.06 GB下降到37 MB,降幅达到98%。
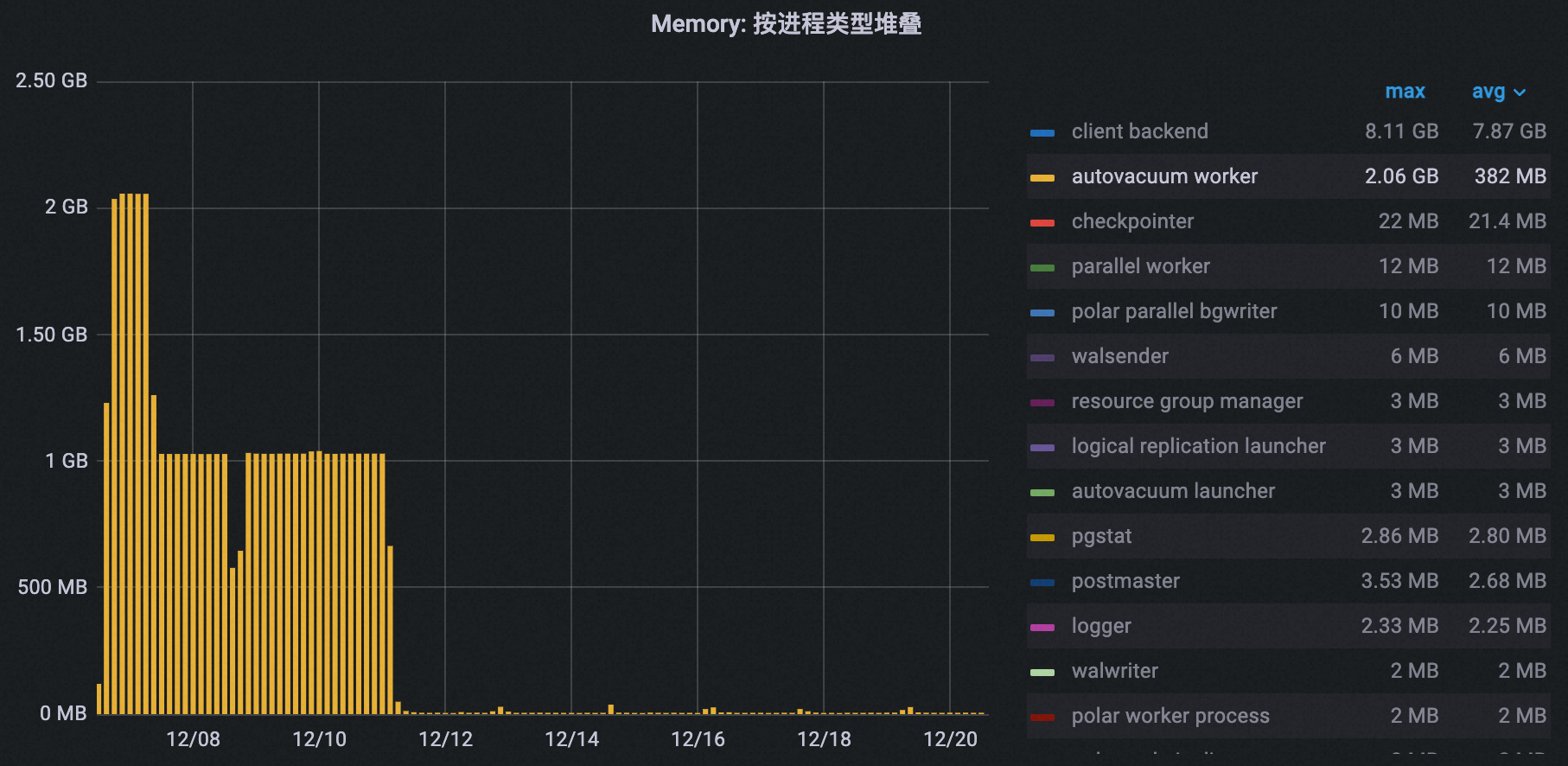
所有进程的总内存使用量峰值也随之从10 GB下降到8 GB,降幅20%。
I/O 使用量优化效果
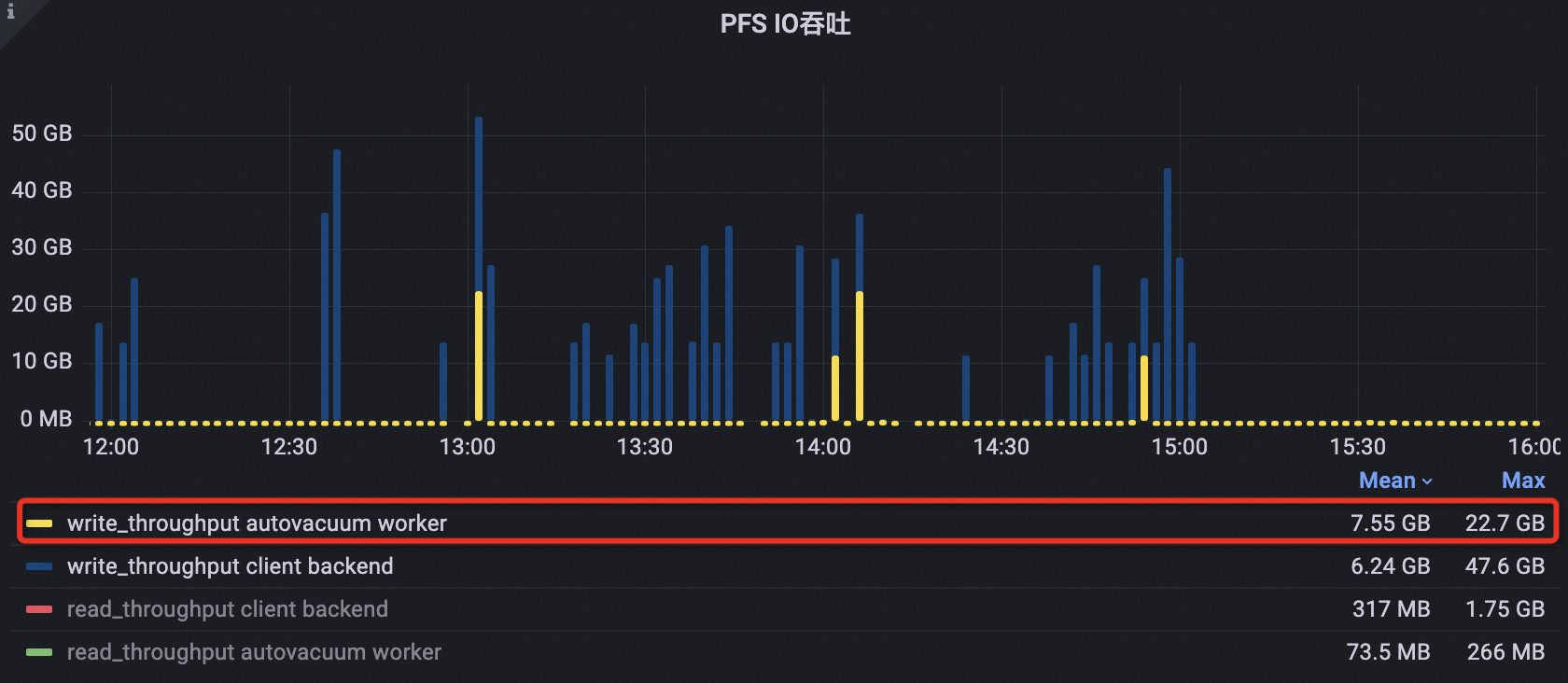
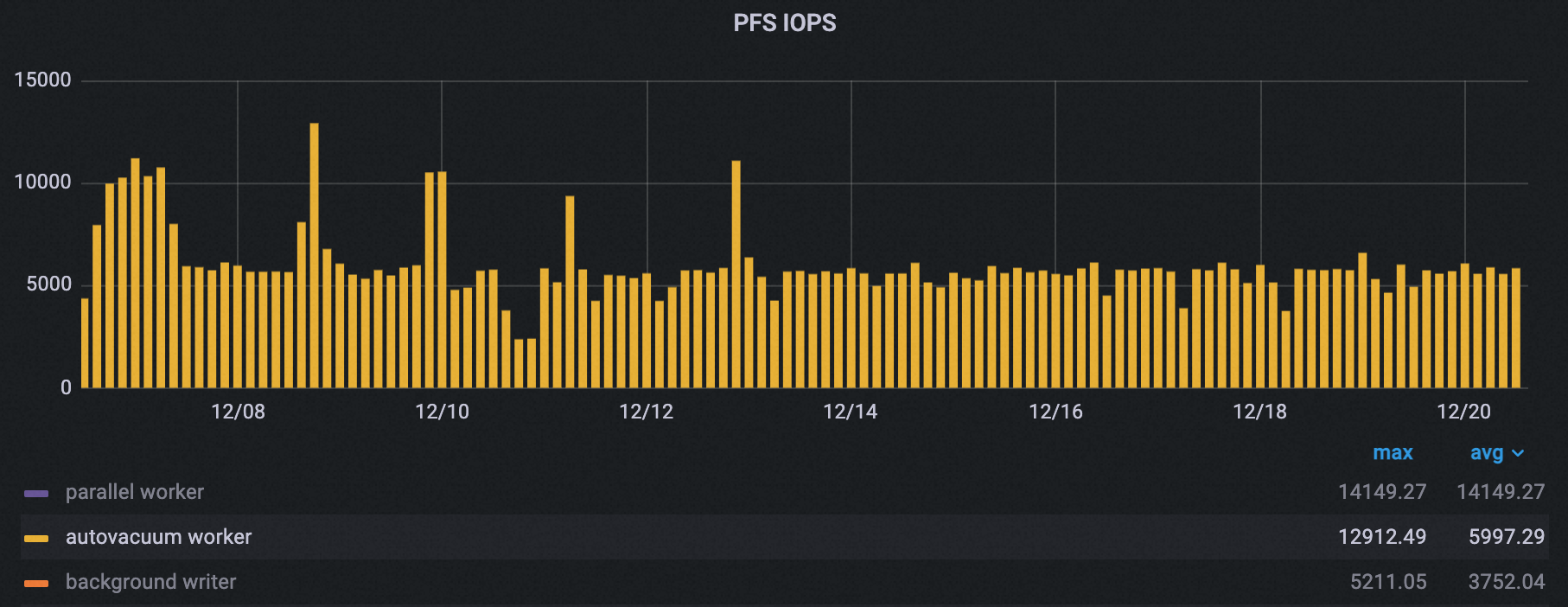
如下图所示,在配置业务低谷期信息之后,集群的自动清理进程PFS IOPS峰值明显降低,降幅约50%。
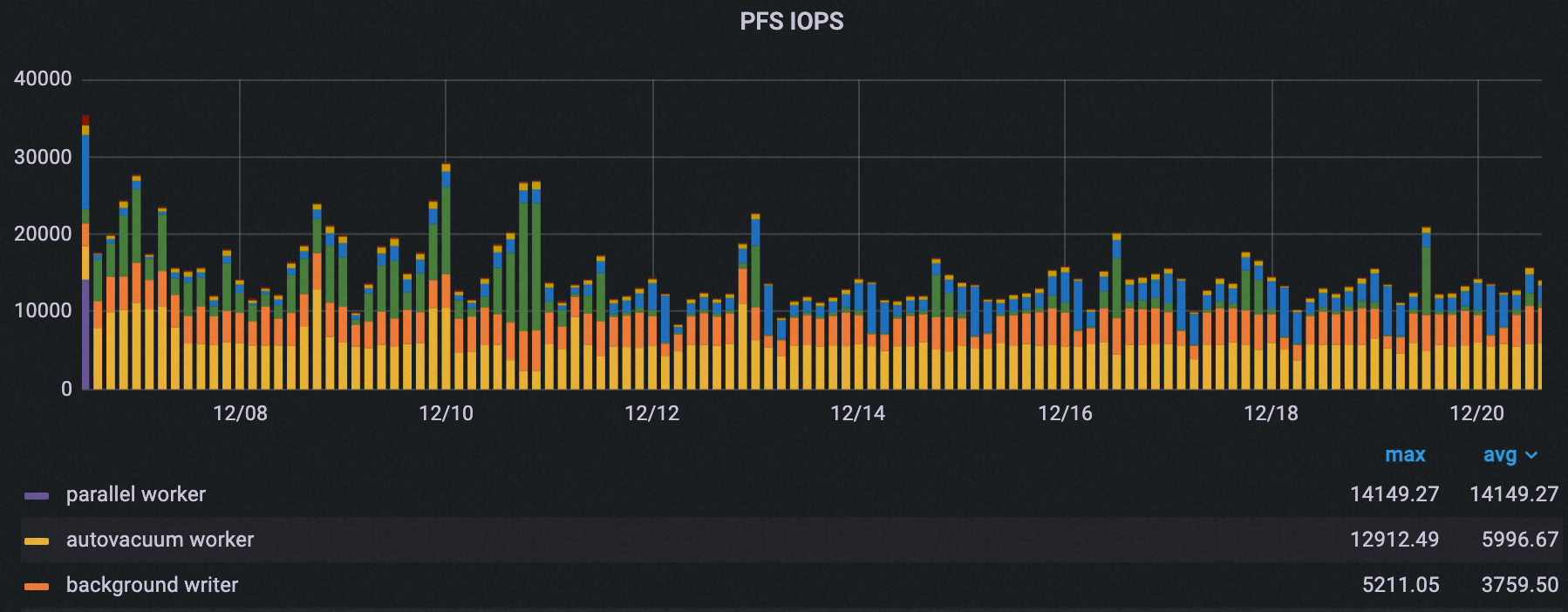
所有进程的总PFS IOPS峰值也从35000下降到21000左右,降幅约40%。
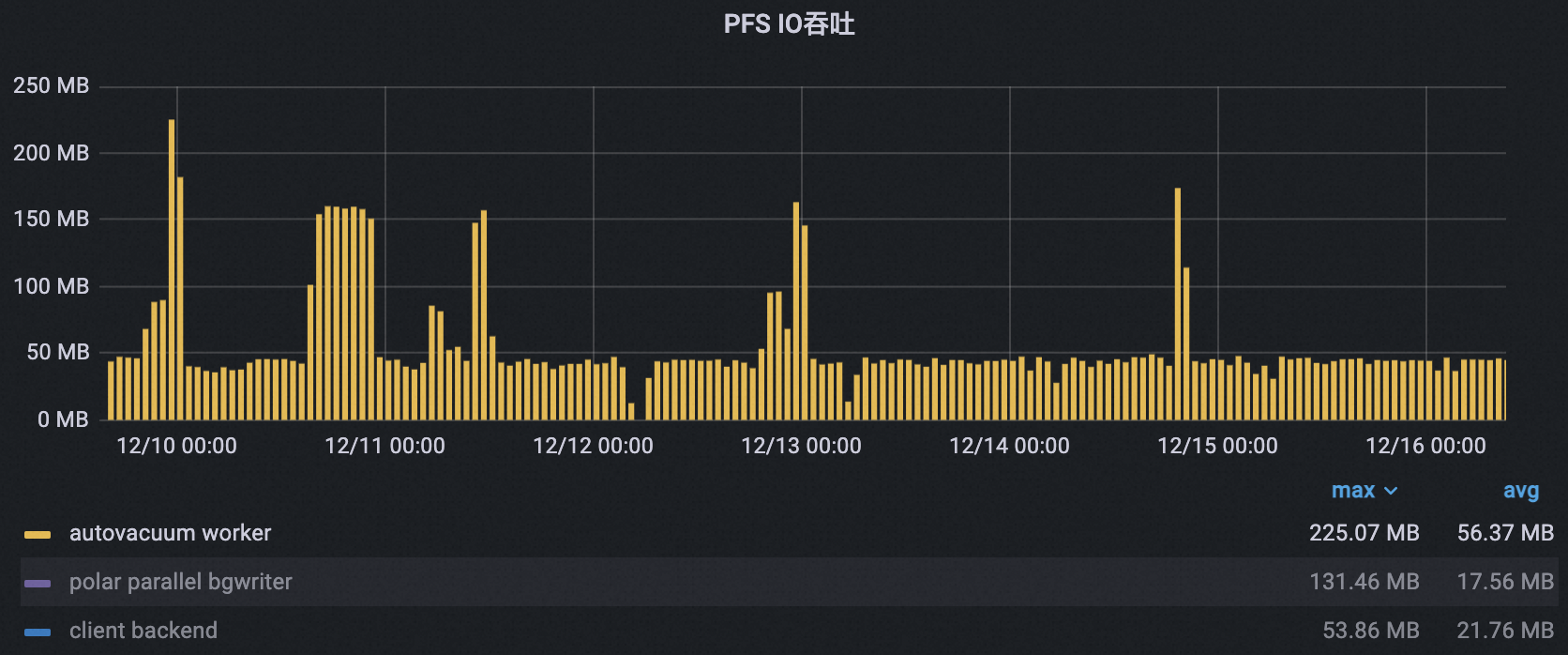
自动清理进程PFS I/O吞吐峰值从225 MB下降到173 MB,下降了23%,同时峰的宽度和数量也明显下降,吞吐平均值从65.5 MB降到42.5 MB,下降了35%。
CPU 使用量优化效果
如下图所示,在配置业务低谷期信息之后,集群的自动清理进程的CPU使用率逐渐降低,峰值降幅约50%。
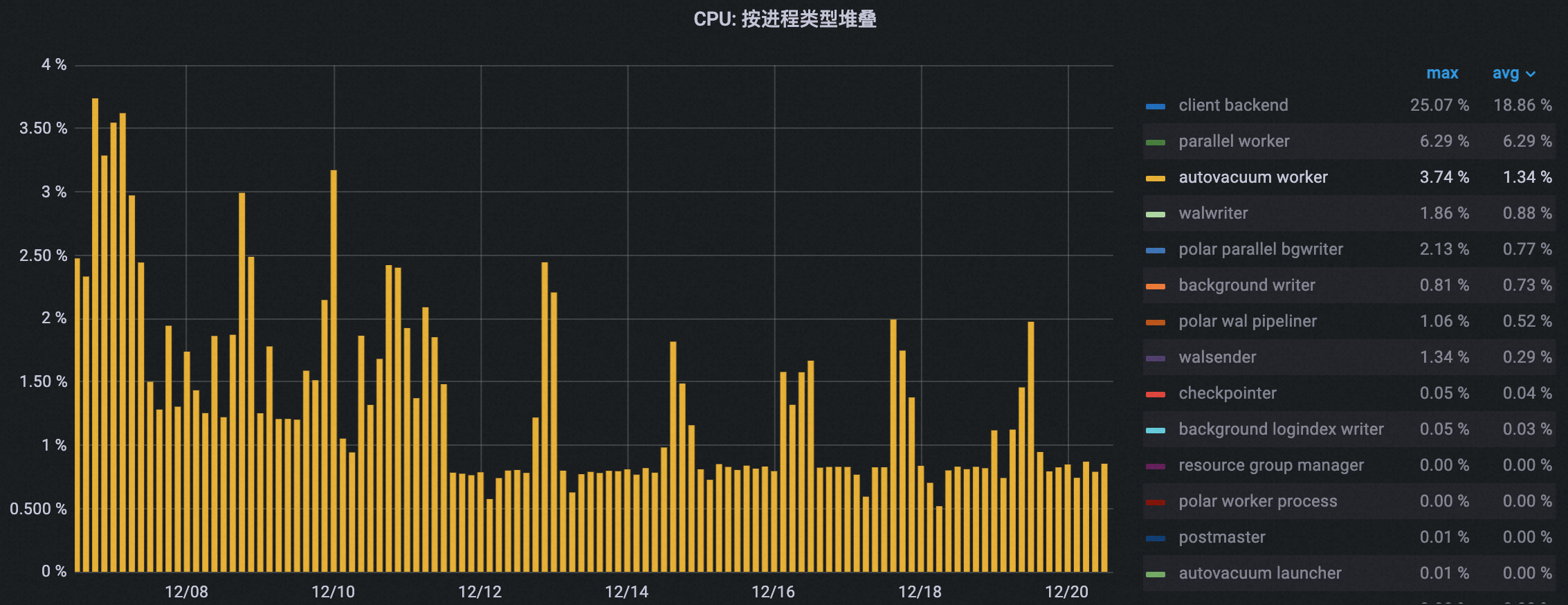
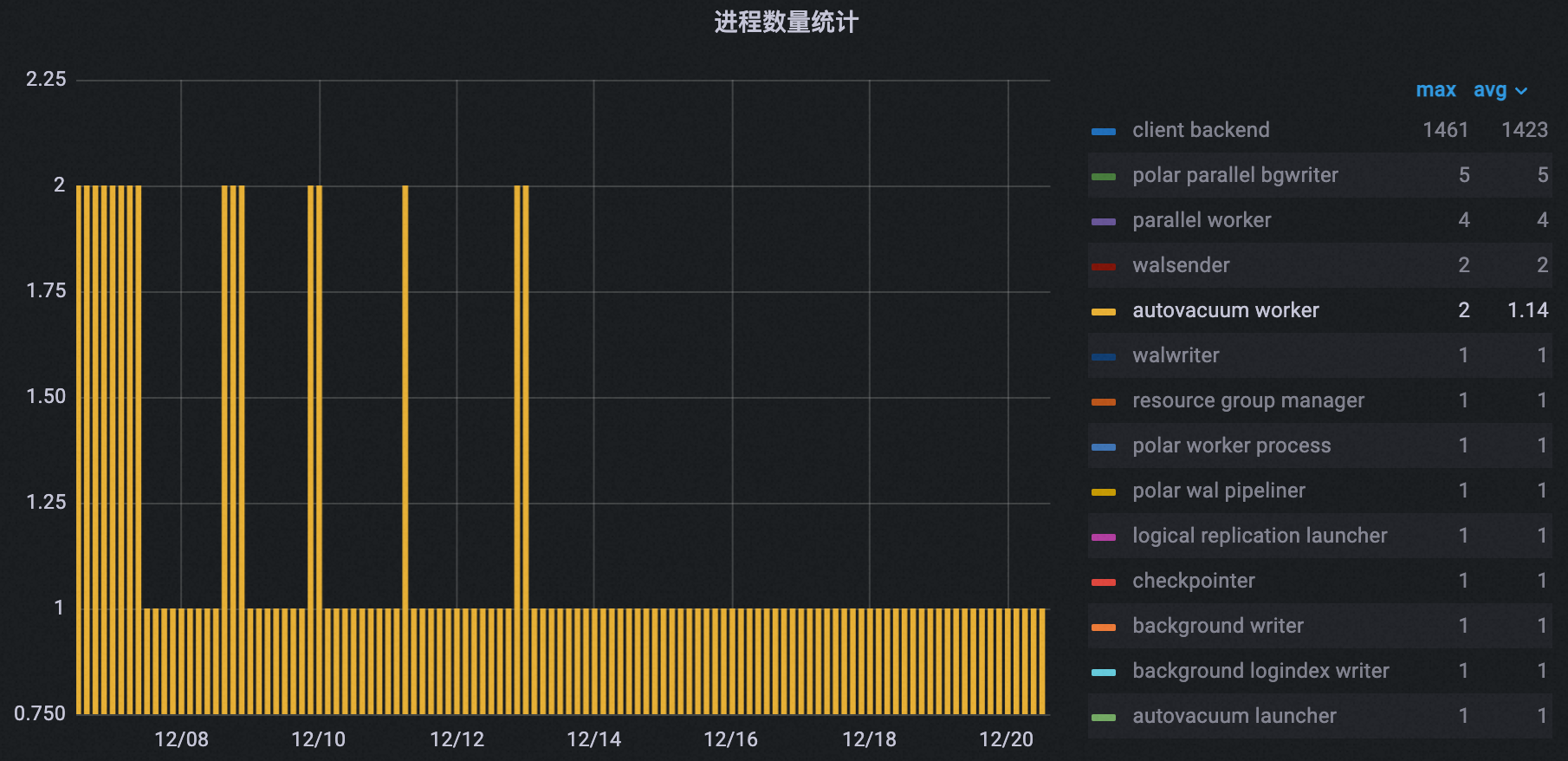
自动清理进程数优化效果
如下图所示,在配置业务低谷期信息之后,集群的自动清理进程数量从2降低到1。
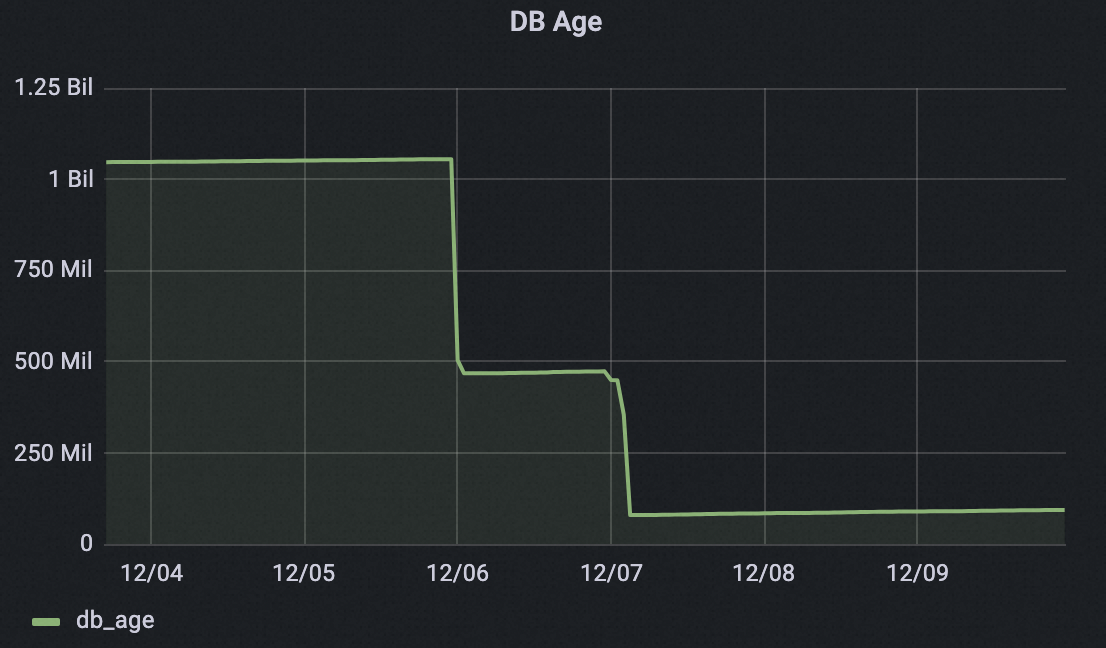
数据库年龄优化效果
如下图所示,集群在配置业务低谷期信息之后的两天内回收了超过10亿个事务ID,数据库年龄从10亿多下降到低于1亿,事务ID回卷风险大大降低。