
智能体(AI Agent)应用的核心挑战之一是其健忘的特性,无法记住历史交互、用户偏好或长期上下文。PolarDB记忆管理是为AI应用提供长时记忆(Long-term Memory)能力的托管服务,它通过将关键信息持久化存储在PolarDB集群中,并结合智能检索与动态上下文注入,让您的AI应用记住一切,从而构建更智能、更具个性化的用户体验。
若您在PolarDB记忆管理上有任何问题,可通过钉钉搜索群号入群咨询。您可以直接@群内专家,并附上您要咨询的问题。钉钉群号:34560007316。
工作原理
PolarDB记忆管理在您的PolarDB PostgreSQL版集群中创建一个隔离的Schema,用于存储和管理AI应用的记忆。当您的应用与用户交互时,它会将对话内容发送给记忆管理服务。服务内部通过大语言模型(LLM)自动完成信息提取、摘要和结构化,并将处理后的记忆存入PolarDB。在后续交互中,应用可随时从服务中检索相关记忆,并将其作为上下文注入到新的Prompt中,从而让大模型做出更精准、更具连续性的回应。
核心概念
记忆项目(Memory Project):一个独立的记忆管理单元,对应您的一项AI应用。在数据库层面,每个项目对应一个独立的
Schema,确保数据隔离。长时记忆(Long-term Memory):被持久化存储在PolarDB中的信息。它能够将知识在不同的阶段保存下来,它记录了:
事实记忆(Factual memory):用户偏好、账户详情和领域事实。
情景记忆(Episodic memory):对过去交互或已完成任务的总结。
语义记忆(Semantic memory):概念之间的关系,以便智能体后续能对它们进行推理。
智能体 (AI Agent):指代您开发的、集成了记忆管理能力的AI应用,例如智能客服或个人助手等。
适用范围
在使用PolarDB记忆管理前,请确认您的环境满足以下条件。本功能旨在帮助您快速判断是否适用,而非操作准备。
集群形态:集中式PolarDB PostgreSQL版集群,暂不支持PolarDB PostgreSQL分布式版集群。
数据库引擎:PostgreSQL 16。
计费说明
组件费用:PolarDB记忆管理收取资源组件费用,费用根据您选择的组件规格(CPU和内存)和购买时长计算。
存储费用:PolarDB记忆管理所产生的数据和文件等将存储在PolarDB PostgreSQL版集群存储空间。
模型费用:PolarDB记忆管理中所使用的模型(例如qwen3-max、text-embedding-v4或qwen3-rerank等)均为阿里云大模型服务平台百炼中的模型。详细计费规则,请参见模型调用计费。
流量与带宽:不收取费用。
准备集群环境
在创建记忆项目前,您需要先准备一个符合要求的PolarDB PostgreSQL版集群,并为其创建专用数据库。
准备集群:根据您实际业务需求,可使用已有集群或购买一个新的PostgreSQL 16版本集群。
创建高权限账号:准备一个高权限账号用于后续创建记忆管理。若您已有高权限账号,可忽略当前步骤。
创建数据库:创建一个逻辑数据库(Database),用于存放记忆项目的相关数据。
配置IP白名单:设置集群白名单,确保您的应用程序可以安全地连接到数据库。
快速体验
步骤一:创建记忆管理
前往PolarDB控制台,在左侧导航栏单击集群列表,找到符合适用范围的目标集群并进入集群详情页。单击左侧导航栏中的,并单击新建AI应用。
在购买页面中,请根据您的需求选择适合的配置:
配置项
说明
付费类型
包年包月:预付费模式。在创建应用时,您需选择固定规格的资源,并预先支付应用的费用。购买周期越长,所享受的折扣也越大。该模式一般适用于业务需求长期稳定的场景。
按量付费:后付费模式。在创建应用时,您需选择固定规格的资源,但无需提前支付应用的费用。该模式根据您实际使用的时长进行计费,一般适用于业务需求灵活的场景。
引擎
固定为PolarDB。
地域
选择应用所在的地理位置。
说明应用购买完成后,不支持更改地域。
应用需与PolarDB PostgreSQL版集群位于同一地域。因此,请选择与PolarDB PostgreSQL版集群相同的地域。
建议将应用与需要连接的ECS创建在同一地域,否则它们将无法通过内网(私网)实现互通,只能通过外网(公网)进行通信,这将无法充分发挥最佳性能。
架构
选择AI应用。
生态
自动填写为源PolarDB集群数据库生态,无需手动填写。
源 PolarDB 集群
选择需要创建应用的PolarDB集群。
版本
自动填写为源PolarDB集群数据库版本,无需手动填写。
AI应用
选择为记忆管理。
记忆引擎
选择为mem0。
组件集
一个AI应用可以包含多个资源组件,建议您选择至少2个组件以支持记忆管理的高可用性。
AI应用名
您可以填写自定义的应用名称。
说明不能以http://或者https://开头,且长度2~256个字符。
网络类型
固定为专有网络。
VPC网络
自动填写为源PolarDB集群的专有网络,无需手动填写。
可用区和交换机
配置VPC网络的交换机,建议选择与PolarDB PostgreSQL版集群的主可用区相同的交换机,以发挥最佳网络性能。
如果已有的交换机无法满足您的要求,您可以自行创建交换机。
项目名称
一个独立的记忆管理单元,对应您的一项AI应用。在数据库层面,每个项目对应一个独立的
Schema,确保数据隔离。数据库名
填写项目对应的数据库名称。
LLM模型
大语言模型,选择后不可修改。支持以下几种模型:
qwen3-max
qwen-plus
Embedding模型
文本转向量模型,选择后不可修改。支持qwen系列的以下版本:
text-embedding-v4
text-embedding-v3
ReRank模型
记忆ReRanker过程使用的模型,选择后不可修改。支持以下版本:
qwen3-rerank
gte-rerank-v2
数据库账号
填写PolarDB PostgreSQL版集群的高权限账号。
账号密码
填写高权限账号对应的密码。
安全组
配置应用的安全组。
购买数量
选择需要购买的应用数量。
说明每个PolarDB PostgreSQL版集群仅支持购买一个相同类型的AI应用。
仅付费类型为包年包月时,支持配置。
购买时长
选择应用的购买时长。
说明仅付费类型为包年包月时,支持配置。
自动续费
配置是否开启自动续费。为避免因忘记续费而导致业务中断,建议您开启自动续费。
说明仅付费类型为包年包月时,支持配置。
购买成功后,请返回集群的AI应用页面,即可查看新创建的应用。
说明系统需要3~5分钟创建应用,请耐心等待。

步骤二:获取连接地址与访问凭证
获取连接地:在AI应用列表页面,单击您的应用ID进入应用详情页,并在基本信息页签的拓扑图区域中查看私网地址。
说明公网地址需单独申请,请单击申请按钮以进行申请。
公网地址仅提供IP地址和端口,不提供域名。如您有相关需求,可自行绑定域名。
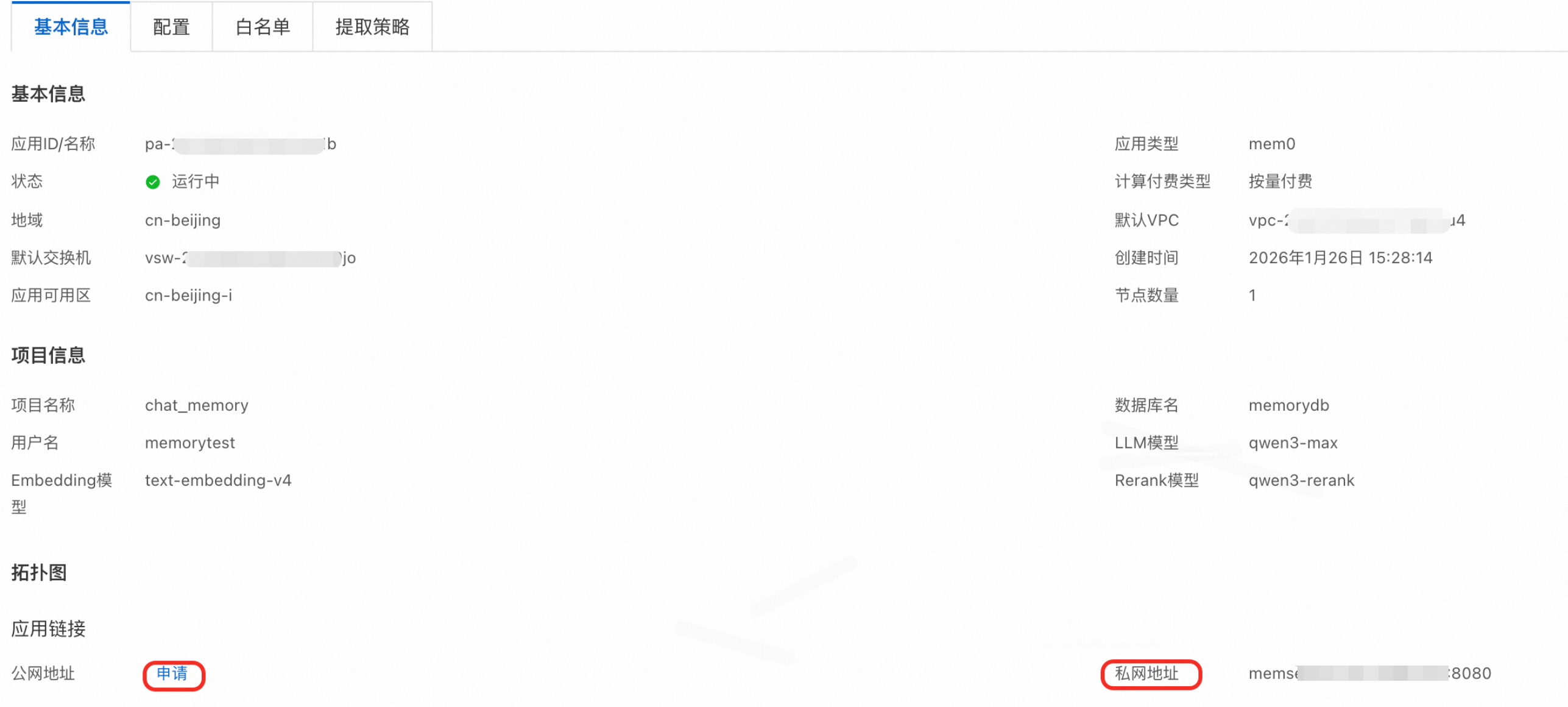
获取配置信息:在记忆库Mem0列表页面,单击您的应用ID/名称进入详情页,在配置页签中查看相关配置信息。

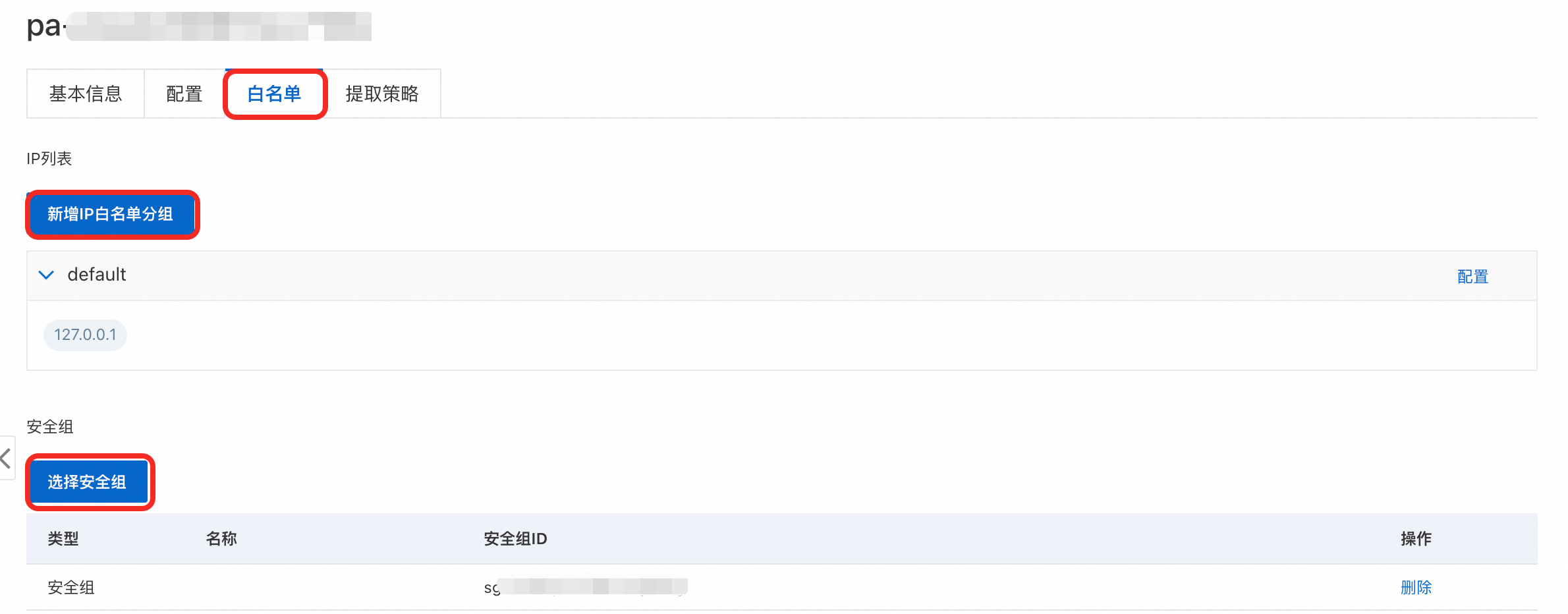
步骤三:配置白名单
在AI应用列表页面,单击您的应用ID进入应用详情页,并在白名单页签,新增IP白名单分组、选择安全组或配置已有白名单分组。
应用白名单与集群白名单相互独立,需进行单独配置。
如果您的ECS实例需要访问应用,可在ECS实例详情页面查看ECS实例的IP地址,并将其填写至IP白名单中。
如果您的ECS实例与应用位于同一VPC内,您可以填写ECS的私网IP地址或其所在VPC网段。
如果您的ECS实例与应用不在同一VPC内,您可填写ECS的公网IP地址,或添加ECS所在的安全组。
如果您本地的服务器、电脑或其他云服务器需要访问应用,请将其公网IP地址添加到IP白名单中。
步骤四:(可选)配置参数与自定义提取策略
参数说明
您可以在记忆管理的配置页签中调整以下参数以优化服务性能和效果。
修改部分参数会导致服务重启,请在业务低峰期操作。
secret.access.apikey:访问凭证。memserver.POLAR_GRAPH_EMBEDDING_THRESHOLD:在提取记忆时,判断是否需要新建图节点的阈值。当提取的记忆需要向已有图中增加关系时,需通过节点的向量相似度进行比较。若相似度大于设定阈值,则采用现有节点;若相似度小于阈值,则创建新的图节点。默认阈值设定为0.7。memserver.POLAR_GRAPH_MAXCONN:记忆服务的最大并发连接数。
自定义提取策略(Prompt)
记忆管理通过内置的Prompt模板(提取策略)来指导LLM如何从对话中提取和总结记忆。您可以自定义这些Prompt以适应特定的业务场景。
策略类型
当前仅支持会话摘要与语义记忆两种策略类型。
每种策略类型(如会话摘要)在同一时间只能启用一个策略。
操作说明
您可以在记忆管理的提取策略页签中进行管理这些策略。
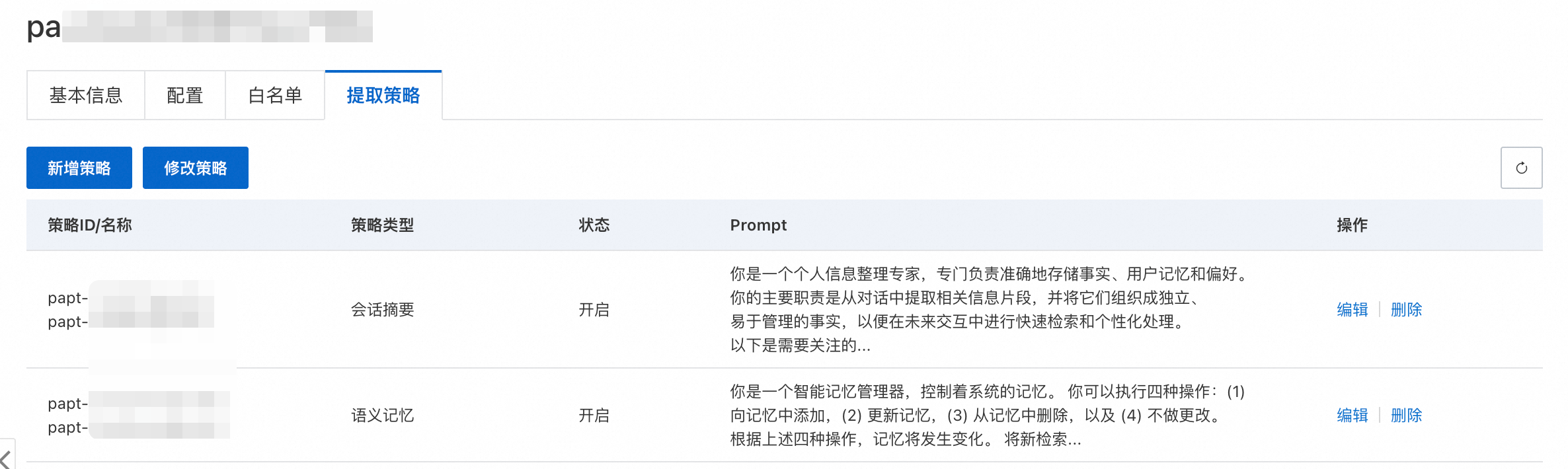
您可以编辑现有的策略进行微调,或新增策略后,通过修改策略按钮将其设为当前启用的策略。


步骤五:操作示例
添加记忆
curl -X POST http://my-endpoint:8080/v1/memories \
-H "Content-Type: application/json" \
-H "Authorization: Token <your-api-key>" \
-d '{
"messages": [
{
"role": "user",
"content": "我喜欢吃辣,特别是川菜。"
},
{
"role": "assistant",
"content": "好的,已经记下您的口味偏好。"
}
],
"user_id": "user_002",
"agent_id": "food-assistant",
"run_id": "user_002_run_id",
"metadata": {
"additionalProp1": {}
}
}'预期返回结果:
{
"results": [
{
"id": "32155c0a-xxxx-xxxx-xxxx-804e119bb965",
"event": "ADD",
"data": {
"memory": "喜欢吃辣"
}
},
{
"id": "9188deee-xxxx-xxxx-xxxx-3073ef826b42",
"event": "ADD",
"data": {
"memory": "特别喜欢川菜"
}
}
]
}搜索记忆
curl -X POST http://my-endpoint:8080/v2/memories/search \
-H "Content-Type: application/json" \
-H "Authorization: Token <your-api-key>" \
-d '{
"query": "我喜欢什么菜",
"agent_id": "food-assistant",
"filters": {
"user_id": "user_002",
"run_id": "user_002_run_id",
"additionalProp1": {}
}
}'预期返回结果:
{
"results": [
{
"id": "9188deee-xxxx-xxxx-xxxx-3073ef826b42",
"memory": "特别喜欢川菜",
"hash": "a826fbf3c3844024633e84d04875ee45",
"metadata": {
"additionalProp1": {
}
},
"score": 0.681654033365126,
"created_at": "2026-03-05T23:59:36.038217-08:00",
"updated_at": null,
"user_id": "user_002",
"agent_id": "food-assistant",
"run_id": "user_002_run_id"
},
{
"id": "32155c0a-xxxx-xxxx-xxxx-804e119bb965",
"memory": "喜欢吃辣",
"hash": "b2882aaf96654a9e16f45f363022010a",
"metadata": {
"additionalProp1": {
}
},
"score": 0.582298149788604,
"created_at": "2026-03-05T23:59:36.023417-08:00",
"updated_at": null,
"user_id": "user_002",
"agent_id": "food-assistant",
"run_id": "user_002_run_id"
}
]
}获取记忆
curl -X POST http://my-endpoint:8080/v2/memories \
-H "Content-Type: application/json" \
-H "Authorization: Token <your-api-key>" \
-d '{
"filters": {
"user_id": "user_002",
"run_id": "user_002_run_id",
"agent_id": "food-assistant"
}
}'预期返回结果:
{
"results": [
{
"id": "39b06e97-xxxx-xxx-xxxx-4223818bc04e",
"memory": "喜欢吃辣",
"hash": "b2882aaf96654a9e16f45f363022010a",
"metadata": {
"additionalProp1": {
}
},
"created_at": "2026-03-06T00:12:45.109789-08:00",
"updated_at": null,
"user_id": "user_002",
"agent_id": "food-assistant",
"run_id": "user_002_run_id"
},
{
"id": "482def46-xxxx-xxxx-xxxx-ff4886a1047c",
"memory": "特别喜欢川菜",
"hash": "a826fbf3c3844024633e84d04875ee45",
"metadata": {
"additionalProp1": {
}
},
"created_at": "2026-03-06T00:12:45.121585-08:00",
"updated_at": null,
"user_id": "user_002",
"agent_id": "food-assistant",
"run_id": "user_002_run_id"
}
]
}附录:API参考
PolarDB记忆管理基于开源框架mem0(V1.0.1)提供托管服务。您可以通过访问http://<your-endpoint>:8080/docs查看实时更新的API文档。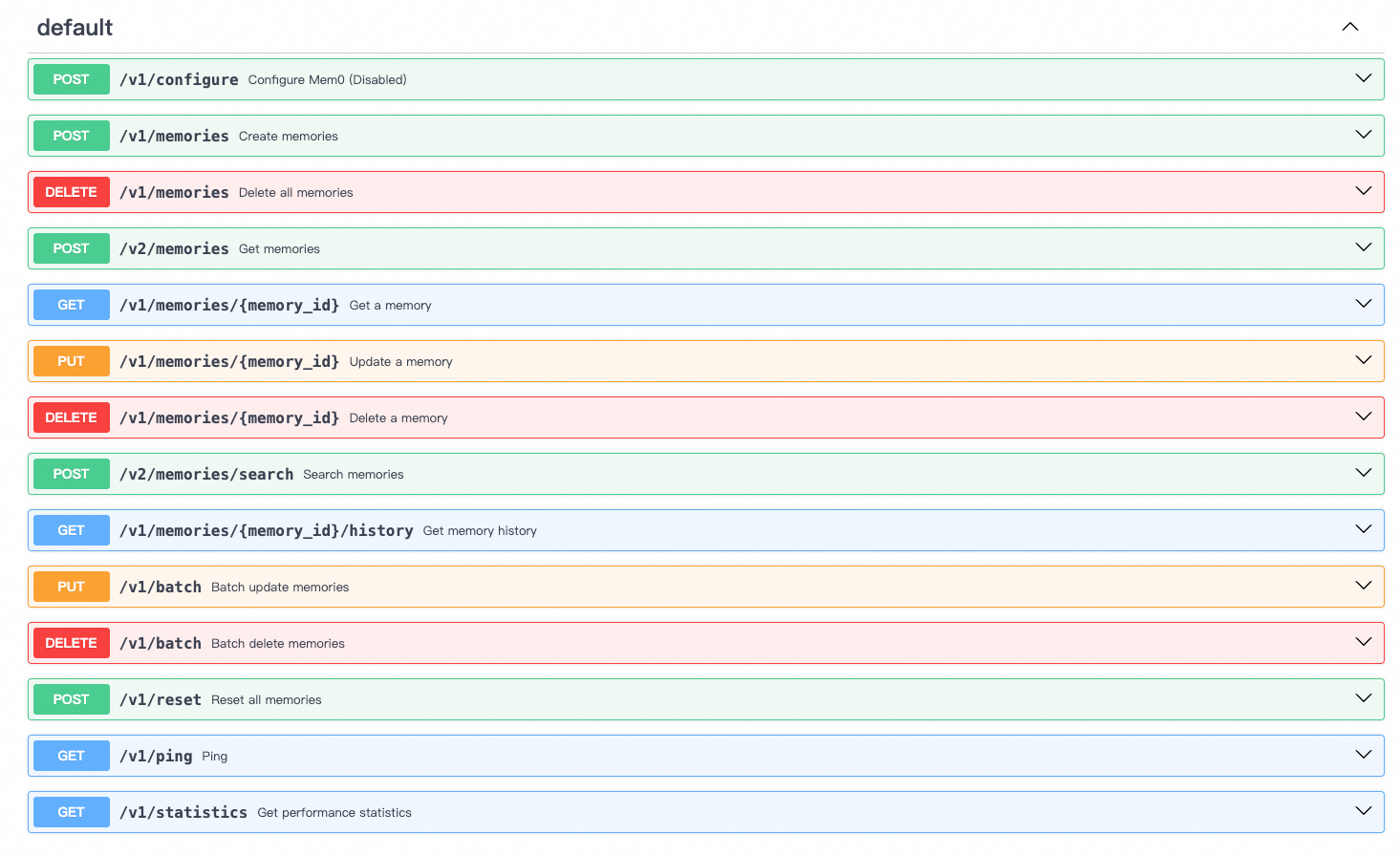
请求头
所有API请求都需要在HTTP Header中包含Authorization: Token <your-api-key>进行认证。
请求示例
此处仅列举部分API参考。
创建记忆(Create Memories)
存储新的记忆。服务会自动对messages内容进行分析,生成会话摘要和语义记忆。
请求地址:
POST /v1/memories请求体:
messages
array(必选)对话消息列表,遵循OpenAI格式。
curl
curl -X POST http://my-endpoint:8080/v1/memories \ -H "Content-Type: application/json" \ -H "Authorization: Token <your-api-key>" \ -d '{ "messages": [ { "role": "user", "content": "我喜欢吃辣,特别是川菜。" }, { "role": "assistant", "content": "好的,已经记下您的口味偏好。" } ], "user_id": "user_002", "agent_id": "food-assistant", "run_id": "user_002_run_id", "metadata": { "additionalProp1": {} } }'Python
import requests import json payload = { "messages": [ {"role": "user", "content": "我喜欢吃辣,特别是川菜。"}, {"role": "assistant", "content": "好的,已经记下您的口味偏好。"} ], "user_id": "user-002", "agent_id": "food-assistant", "run_id": "user_002_run_id" } response = requests.post( "http://<your-endpoint>:8080/v1/memories", headers={"Authorization": "Token <your-api-key>", "Content-Type": "application/json"}, data=json.dumps(payload) ) print(response.json())user_id
String(必选)用户的唯一标识符。
agent_id
String(可选)智能体的唯一标识符,用于在同一用户下隔离不同应用的记忆。
run_id
String(可选)单次执行或会话的唯一标识符。
metadata
Object(可选)附加的元数据,会与记忆一同存储。
搜索记忆(Search Memories)
根据查询字符串,搜索最相关的记忆。
请求地址:
POST /v2/memories/search请求体:
query
String(必选)用于搜索的查询文本,例如用户的新问题。
curl
curl -X POST http://my-endpoint:8080/v2/memories/search \ -H "Content-Type: application/json" \ -H "Authorization: Token <your-api-key>" \ -d '{ "query": "我喜欢什么菜", "agent_id": "food-assistant", "filters": { "user_id": "user_002", "run_id": "user_002_run_id", "additionalProp1": {} } }'Python
import requests import json payload = { "query": "我喜欢什么菜", "agent_id": "food-assistant", "filters": { "user_id": "user_002", "run_id": "user_002_run_id" } } response = requests.post( "http://<your-endpoint>:8080/v2/memories/search", headers={"Authorization": "Token <your-api-key>", "Content-Type": "application/json"}, data=json.dumps(payload) ) print(json.dumps(response.json(), indent=2, ensure_ascii=False))agent_id
String(可选)限定在指定智能体下搜索。
filters
String(必选)基于元数据的过滤条件。
获取记忆(Get Memories)
获取指定范围内的所有原始记忆。
请求地址:
POST /v2/memories请求体:
filters
String(必选)基于元数据的过滤条件。
curl
curl -X POST http://my-endpoint:8080/v2/memories \ -H "Content-Type: application/json" \ -H "Authorization: Token <your-api-key>" \ -d '{ "filters": { "user_id": "user_002", "run_id": "user_002_run_id", "agent_id": "food-assistant" } }'Python
import requests import json payload = { "filters": { "user_id": "user_002", "run_id": "user_002_run_id", "agent_id": "food-assistant", } } response = requests.post( "http://<your-endpoint>:8080/v2/memories", headers={"Authorization": "Token <your-api-key>", "Content-Type": "application/json"}, data=json.dumps(payload) ) print(json.dumps(response.json(), indent=2, ensure_ascii=False))
删除记忆(Delete Memories)
删除指定范围内的所有记忆。
请求地址:
DELETE /v1/memories请求体:
user_id
String(必选)用户的唯一标识符。
curl
curl -X DELETE 'http://<your-endpoint>:8080/v1/memories?user_id=user_002&agent_id=food-assistant' \ -H 'accept: application/json' \ -H 'Authorization: Token <your-api-key>'Python
import requests import json # 限制搜索范围 current_user_id = "user_002" current_agent_id = "food-assistant" # 准备API请求的URL和数据 api_url = f"http://<your-endpoint>:8080/v1/memories?user_id={current_user_id}&agent_id={current_agent_id}" response = requests.delete( api_url, headers={"Authorization": "Token <your-api-key>"}, ) print(json.dumps(response.json(), indent=2, ensure_ascii=False))agent_id
String(可选)如果提供,则仅删除该智能体的记忆。
run_id
String(可选)如果提供,则仅删除该会话的记忆。