
客户推荐语录
PolarDB PostgreSQL版的存储具备弹性扩容的能力,最大可支持500 TB存储空间。它的大表优化和弹性跨机并行查询(ePQ),成功解决了社区PostgreSQL针对大表的查询和并发更新慢的问题。在小鹏汽车的智能辅助驾驶业务上,实现了每日TB级大数据表的7000万行更新和大数据表秒级分析查询。
——小鹏汽车 SRE 负责人
客户介绍

关于小鹏汽车
小鹏汽车是中国领先的智能电动汽车公司,致力于为对技术充满热情的消费者设计、开发、制造和营销智能电动汽车。公司的核心使命是通过科技驱动智能电动汽车的变革,引领未来的出行方式。为了提升客户的驾驶体验,小鹏汽车投入了大量资源自主研发全栈式智能辅助驾驶技术、车载智能操作系统,以及涵盖动力总成和电子电气架构的车辆核心系统。
业务场景
智能辅助驾驶是小鹏汽车的重点技术方向,每天有海量的图片、视频数据采集上传。有海量的数据存储在对象存储中,同时还需要在关系数据库中针对每个文件生成一条“目录”,以便批量地查找和管理文件,记录文件的位置、属性、指标等。这就导致了这个“目录”要覆盖到全量的数据文件,即数据库的超大单表,并且随着指标的变化要经常进行表的全量数据更新。
客户痛点
小鹏汽车原先使用的数据库是社区PostgreSQL,随着智能辅助驾驶业务的快速增长,系统面临数据处理的三重挑战:
大表查询慢
面对海量数据,单机并行处理能力已经达到极限,无法应对TB级大表的查询,小鹏汽车的智能辅助驾驶分析业务承受前所未有的压力。小鹏汽车数据中心最庞大的数据表体量已攀升至7 TB,而超过TB级别的数据表数量更是多达四张。当大表的分析查询时间达到数十分钟甚至数小时时,这一数据处理瓶颈已成为制约智能辅助驾驶业务的关键难题,迫切需要一种新的技术解决方案来破解。
大表频繁更新
在小鹏汽车的标注业务中,面临着一个日益严峻的问题:TB级大数据表每天的更新量高达7000万行。这一庞大的数据流量引发了一系列的问题,尤其是在TB级大表更新过程中,过多的文件校验作业导致了文件系统的IOPS达到极限,进而导致了系统性能的急剧下降。最终,这种过载使得单行数据更新耗时达到分钟级,进而触发数据库雪崩,对公司的业务运营构成了直接的威胁。
存储空间快速增长
数据库总容量飙升至30 TB并且以每月2 TB的惊人速度持续增长。社区版的PostgreSQL数据库面临着一个严峻挑战:它无法实现自动化的扩容。这样迅猛增加的存储需求正急剧逼近系统的极限,成为了一个亟待解决的难题。
产品方案
随着数据量越来越大,社区版PostgreSQL遇到性能瓶颈,数据处理链路产生堆积,尤其是数据批量更新更是成为卡点,影响智能辅助驾驶研发效率。针对现状和PostgreSQL生态兼容性考虑推荐客户测试PolarDB PostgreSQL版,在兼容现有业务代码的同时,解决单机数据库的性能瓶颈,提高研发效率:

ePQ加速TB级大表分析查询
ePQ是Elastic Parallel Query(弹性并行查询)的缩写。PolarDB PostgreSQL版通过ePQ优化器,生成能够被多个计算节点并行执行的执行计划。ePQ的执行引擎将在多个计算节点上协调执行该计划,同时利用多个节点的CPU、内存、I/O带宽来扫描和计算数据。PolarDB PostgreSQL版ePQ 的架构示意图如下所示:
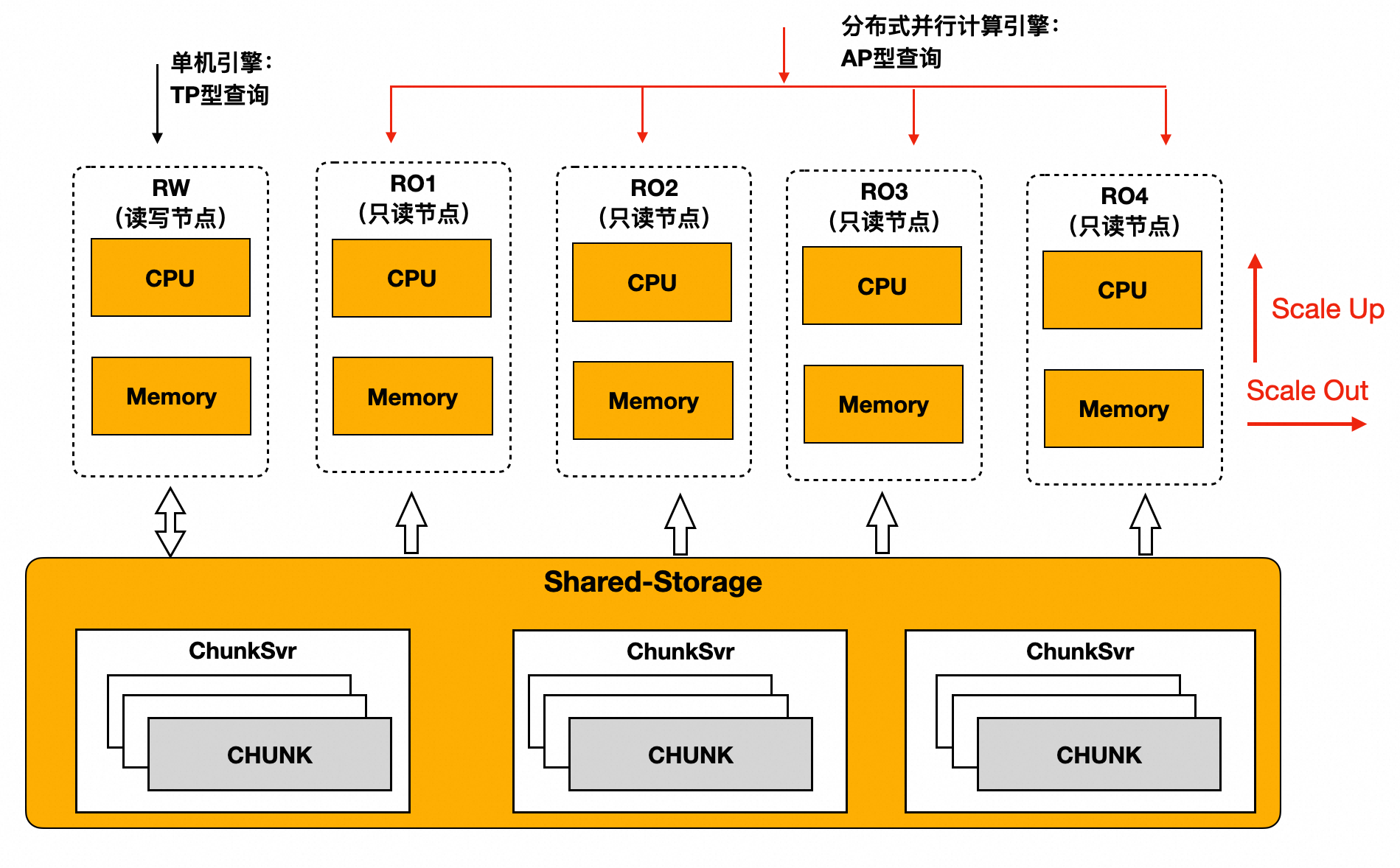
基于此架构,PolarDB PostgreSQL版的ePQ相较于社区PostgreSQL有如下优势:
优异的分析查询性能:1 TB TPC-H测试平均提升23倍性能,性能可随并行度、节点数线性提升。
业务完全透明:无须修改任何业务代码,仅需在控制台打开
polar_enable_px开关即可使用ePQ。一体化存储:TP/AP共享一套存储数据,减少存储成本。TP高压力写入下,AP引擎提供毫秒级数据新鲜度。
大表优化解决大表频繁更新问题
客户业务问题
在小鹏汽车的场景下,单表的大小达到TB级别,最大可达到7 TB。业务侧采用短连接 + 高并发(> 400)更新的方式来访问TB级大表。在这种情况下,大表的文件访问操作(例如open/lseek)会将整个数据库的IOPS打满,IO时延飙升,触发数据库雪崩。
原因分析
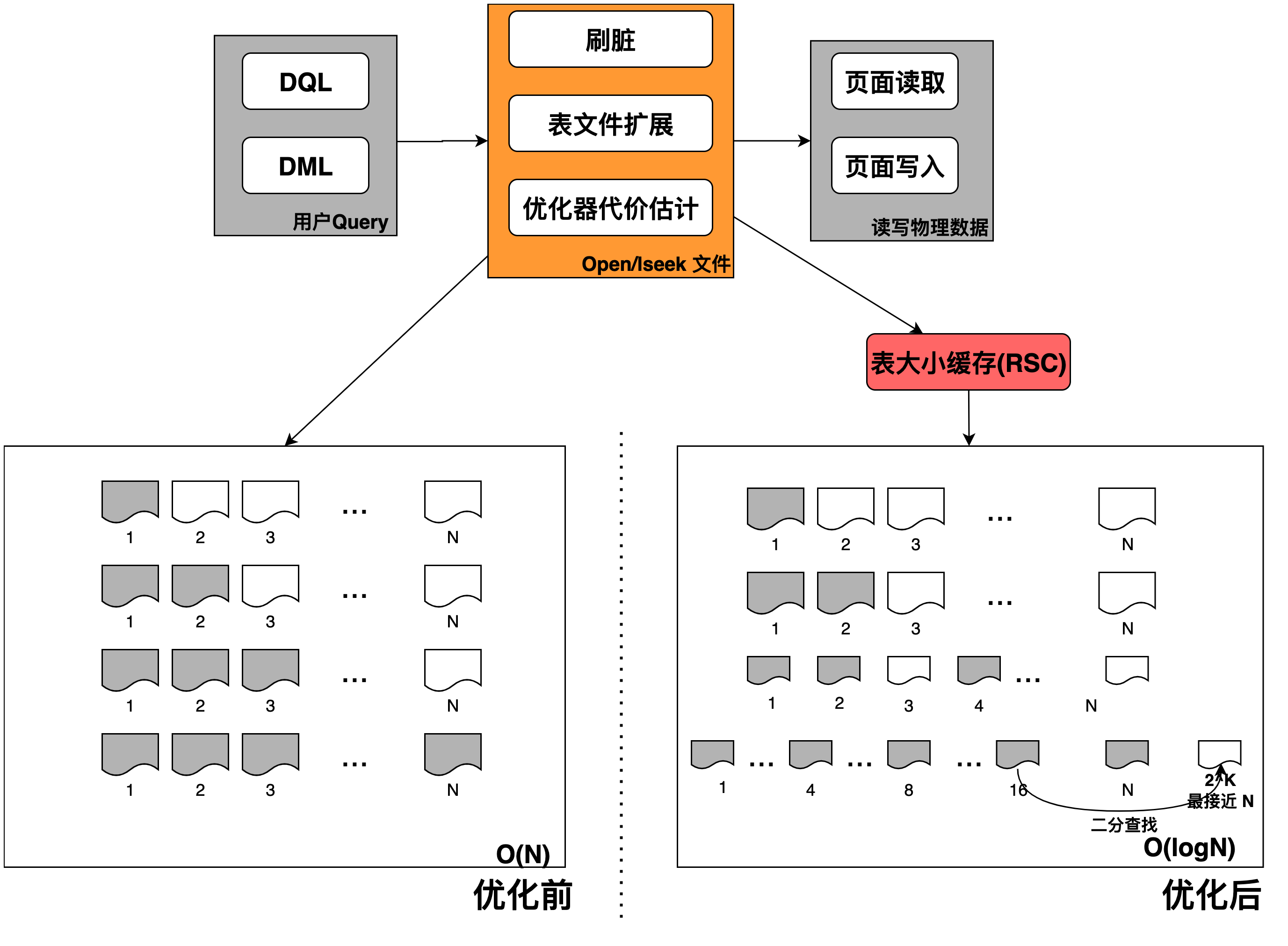
在社区PostgreSQL中,每张表的文件都是以Segment为单位来进行存储,每个Segment大小为1 GB。在如下三个场景需要使用open/lseek文件访问操作来获取文件大小:
刷脏操作:在脏页写入情况下,需要定位每一个脏页需要写入的具体位置。这个时候,需要打开写入页面前所有的segment文件,通过lseek获取所有 segment文件大小并求和,最终,check脏页写入位置正确。
DML引发的表扩展:在Insert/Update过程中,如果找不到空闲页面,会进行表扩展。表扩展的时候需要获取当前表的大小用来定位表扩展后的位置,获取当前表大小需要逐个open/lseek segment文件。
优化器进行代价估计:优化器在对普通表进行代价估计时,需要获取表大小用来判断采用seqscan还是indexscan。获取当前表大小需要逐个open/lseek segment文件。
小鹏汽车智能辅助驾驶场景下, 7TB的大表意味着7000个Segment文件,每次对大表进行刷脏或者表扩展的时候,单次文件写入操作会被放大成7000 个 Segment 文件长度校验。同时业务侧还是采用短连接 + 高并发的方式访问大表,意味着文件句柄无法缓存,只能采用文件操作(open/lseek)来访问 Segment 文件长度,最终大表的海量文件访问将整个数据库的IOPS打满,IO时延飙升,触发数据库雪崩。
解决办法
PolarDB PostgreSQL版用如下三个方法解决了大表写入问题:
二分查找获取表大小:在文件扩展或者优化器代价估计。社区PostgreSQL获取表文件大小,需要逐个获取每个 segment 大小,复杂度为 O(N);PolarDB PostgreSQL版优化过后,按2的倍数依次打开 segment 文件(例如0、1、2、4、16、32....),直至文件不存在,锁定文件大小区间,例如
[64,128)。然后在[64,128)二分查找segment N存在并且N+1不存在,最终文件的大小锁定为(N-1)*segment_size + 第 N 个 segment 大小(segment_size为 1GB)。经过优化后,表文件大小获取的复杂度由O(N)降低至O(logN)。减少冗余文件校验:社区PostgreSQL在刷脏写入一个页面的时候,需要逐个打开之前所有 Segment 文件计算页面写入位置信息,检查页面写入位置信息正确。PolarDB PostgreSQL版优化过后,在保证数据正确性的基础上,减少冗余的文件校验,仅获取
SegN-1和SegN两个文件大小。表大小缓存(Relation Size Cache):PolarDB PostgreSQL版设计的表大小缓存,会在优化器进行代价估计的时候优先采用缓存,而不是通过IO获取文件大小。
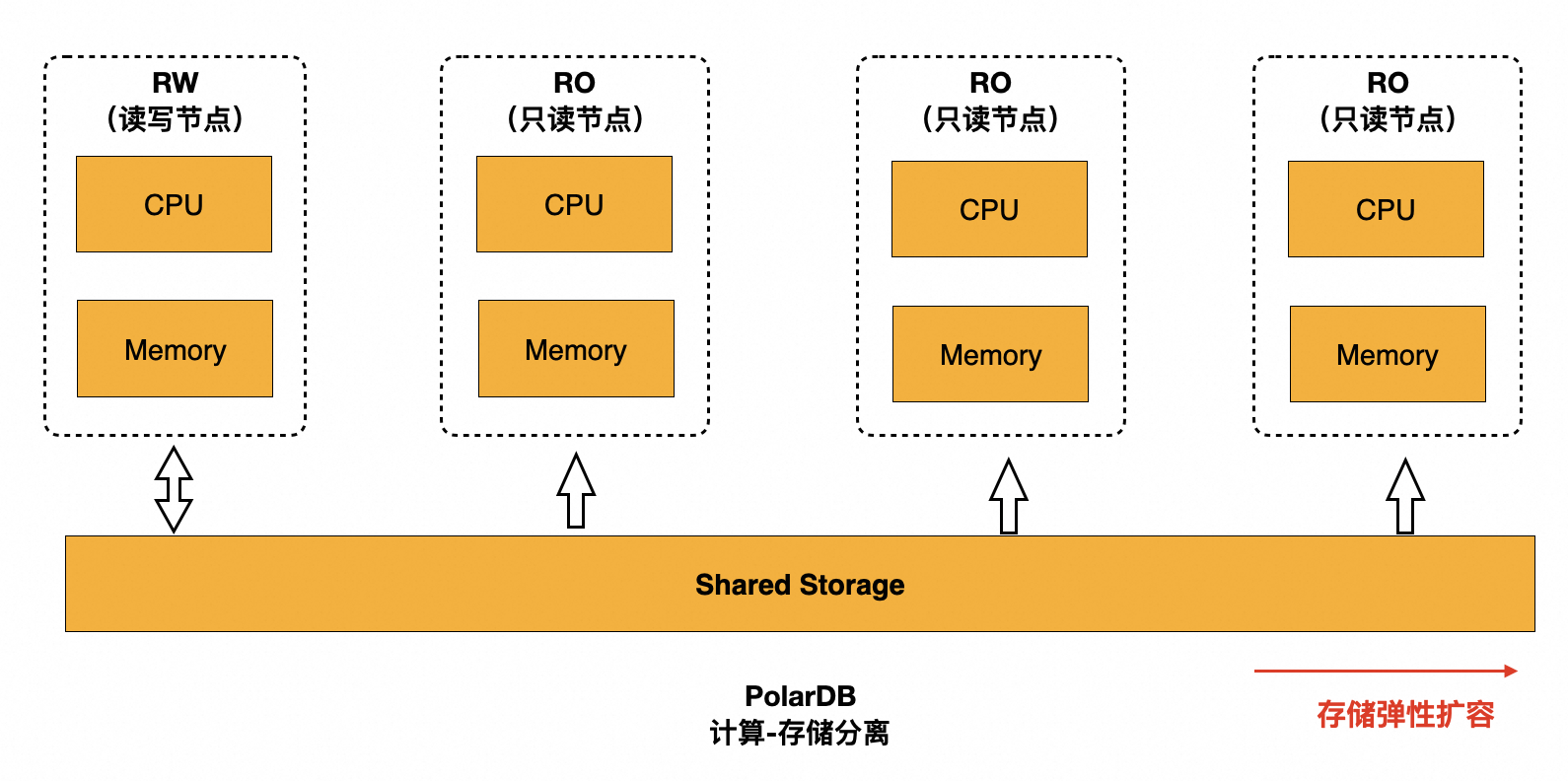
存算分离实现弹性扩容
客户业务问题
小鹏汽车的PolarDB PostgreSQL版实例数据量达到30 TB,并且以平均每月2 TB的速度在增长。基于ECS自建的PostgreSQL数据库已无法应对数据增长的需要。
解决办法
PolarDB PostgreSQL版基于存储计算分离的架构,PolarStore存储集群可独立扩展,支持弹性扩容,存储按量进行计费,最大支持500 TB存储,PolarStore存储集群的读写带宽稳定在1.6 GB/s 以上。大容量 + 高带宽确保PolarDB PostgreSQL版的IO和存储空间不成为瓶颈。
客户价值
大表分析查询速度提升3.6倍
以数据统计业务为例,大表(这里简称为xxx)的表大小为7.6 TB,通过如下语句查询:
select count(1) as cnt from xxx where create_time>='2024-03-19 01:00:00' and create_time<'2024-03-19 02:00:00';未使用ePQ查询,采用原生单机并行查询,并行度为6,执行时间为66 秒。

采用ePQ 2个RO节点,24并发查询,执行时间可降低至18 秒。

采用ePQ跨机并行查询相较于单机并行查询速度可提升3.6倍,能达到查询性能随并行度线性提升。再增加只读节点,查询速度仍可继续提升。
数据等待事件降低至几乎为0
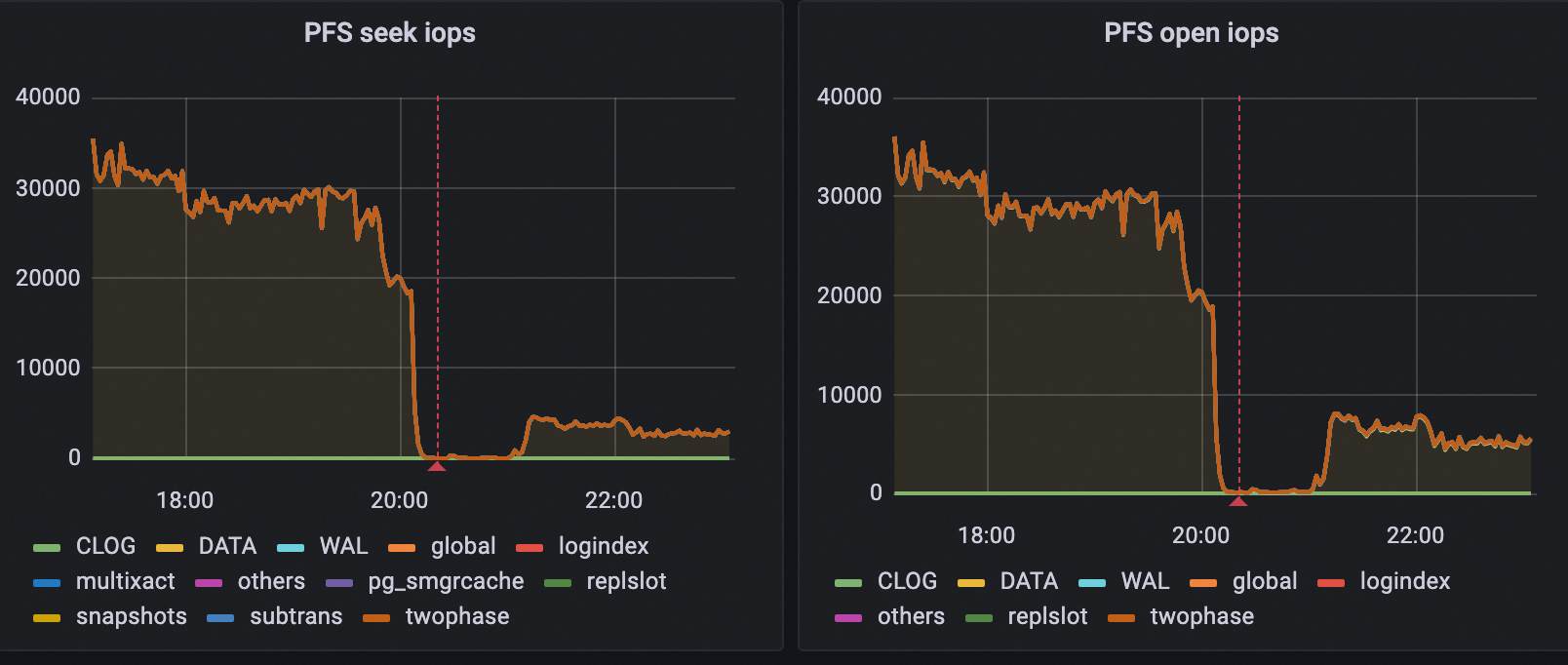
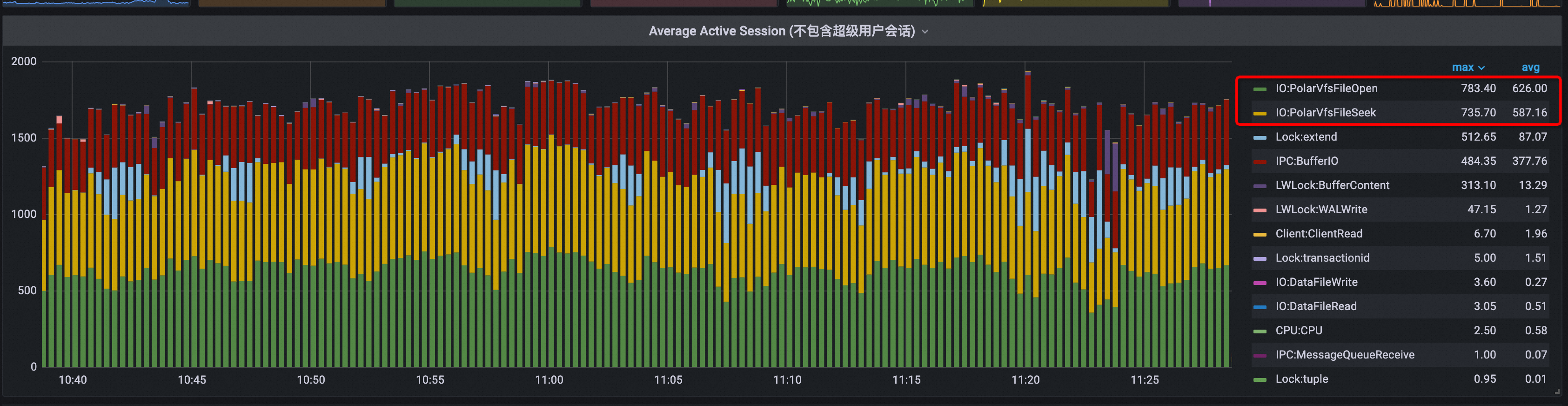
下图展示了文件系统seek和open iops的变化,红线左侧是优化前的表现,红线右侧是优化后的表现。
优化前:整体的open/seek iops达到30000 ~ 40000。
优化后:整体的open/seek iops达到5000左右,减少80%的iops数量。
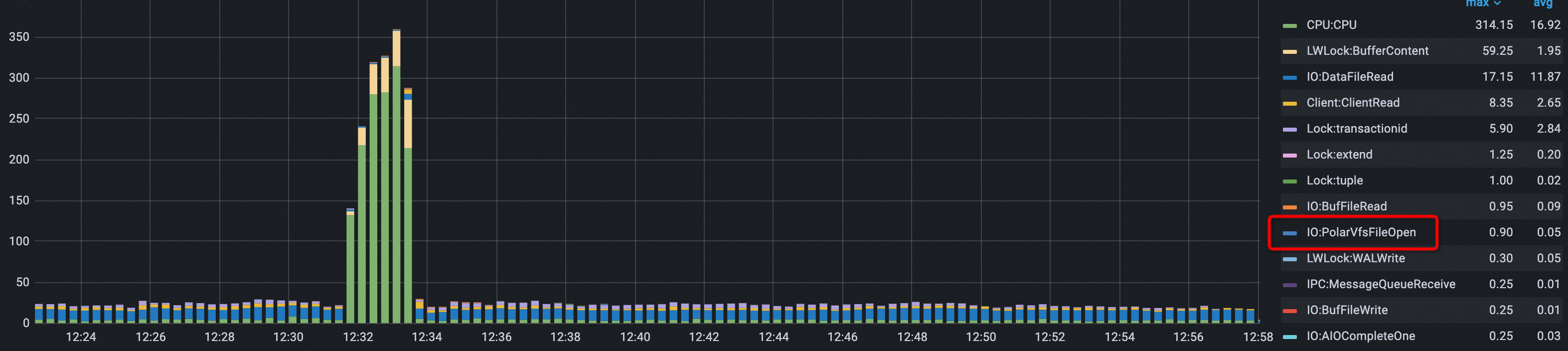
如下图所示,图中的每一项表示数据库在运行过程中的等待事件总量。由原来平均600+的FileOpen/FileSeek等待事件,优化到后面几乎没有FileOpen/FileSeek等待事件(<1)。
优化前:
优化后:
存算分离实现弹性扩容
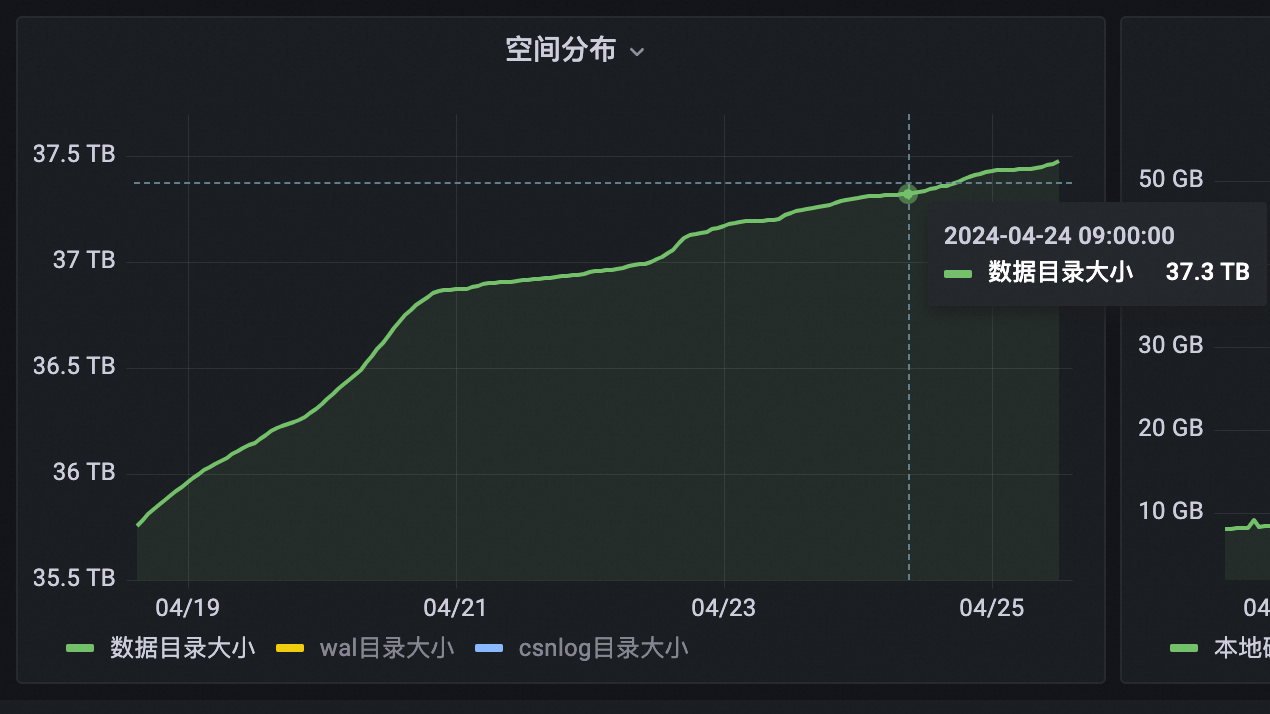
下图展示了小鹏客户的总数据量和7天内数据增长量。总数据量达到37 TB 级别,数据增长量峰值达到每7天1.5 TB,平均以每月2 TB的速度增长。但PolarDB PostgreSQL版的存储空间不会成为瓶颈。
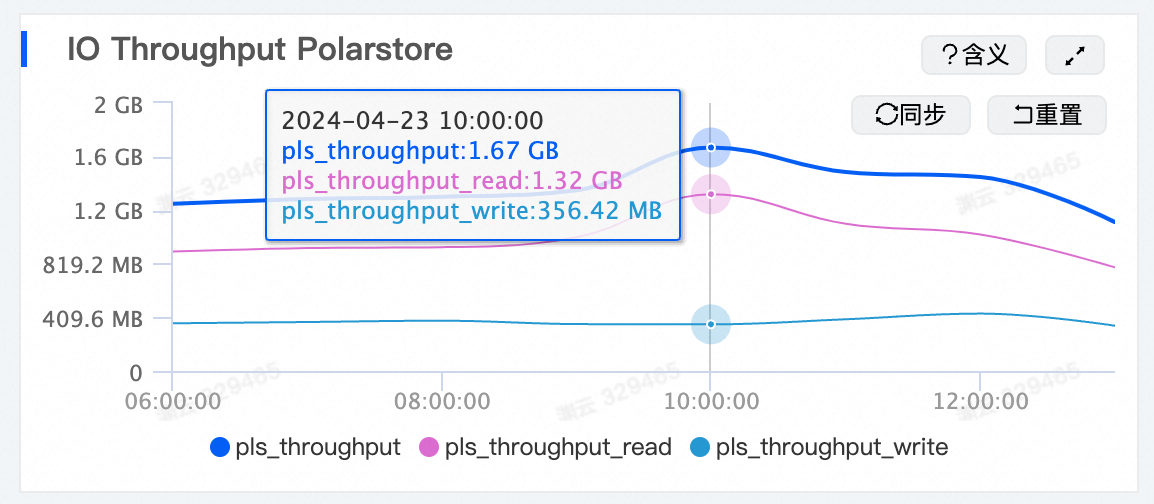
下图展示了小鹏汽车智能辅助驾驶业务在业务高峰期的IO读写带宽,稳定在1.6 GB/s 以上。PolarDB PostgreSQL版的高读写带宽确保智能辅助驾驶业务在高峰期正常运行。
总结
PolarDB PostgreSQL版的自动弹性扩容、大表优化和弹性跨机并行查询已经成为小鹏汽车智能辅助驾驶业务应对TB级别大表标注、分析查询的"利器"。同时,PolarDB PostgreSQL版针对大表的高性能解决方案也可以更好地满足类似汽车领域内智能辅助驾驶业务的数据库访问需求:
支持TB级别大表的秒级分析查询。
支持TB级别大表每日7000万的频繁标注更新。
提供500 TB的存储空间、存储弹性自动扩容、按量付费方式。
所有大表优化对业务完全透明,无需业务修改,省去开发和运维负担。