
本文介绍了PolarDB-X处理SQL的基本原理及执行计划的概念。
分布式数据库架构相对单机数据库有差异,所以在单机数据库调优方法的基础上分布式数据库又有着自身的特点。PolarDB-X可以基于统计信息、执行计划、并发策略和执行之后反馈的运行时长等信息,找出导致SQL执行慢的原因,进行针对性调优。
一条慢查询可能和物理SQL执行快慢、并发度数量、执行计划和索引选择是否合适都有关系。所以在分布式数据库中,SQL调优的成本一般会比单机数据库高。
基本原理
PolarDB-X是一款计算存储分离的分布式数据库产品。当一条查询SQL发往PolarDB-X计算节点(CN)时(此SQL又称为逻辑SQL),PolarDB-X会将其分成可下推和不可下推的两部分,可下推的部分也被称为物理SQL。不可下推的SQL在CN上执行,可下推的SQL在DN上执行。
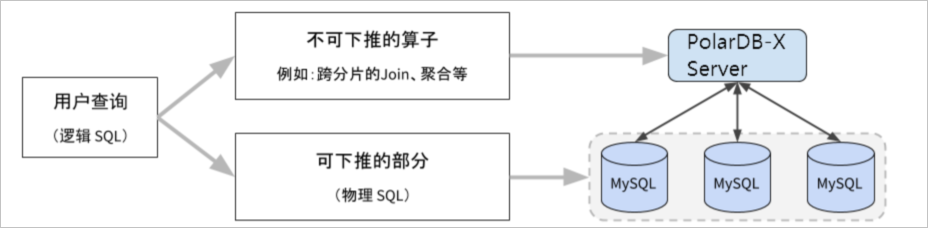
PolarDB-X按照以下原则进行SQL优化:
尽可能将逻辑SQL下推到DN上执行,除了可以避免CN和DN间数据网络交互以外,还可以充分利用多分片并发执行的能力,利用各个DN资源加速查询。
对于无法下推的部分包含的物理算子,查询优化器会选择最优的方式来执行,例如选择合适的物理算子,选择合适的并行度策略以及使用MPP执行。
说明并行度指查询过程中数据并行执行的最大数目,对于CN来说就是利用多核能力多线程计算,对DN来说就是同时执行多个下推物理SQL的并行数。
PolarDB-X的索引一般分为局部索引和全局索引,局部索引是指单个DN节点的索引(MySQL索引),全局索引是指构建在多个DN上的分布式索引。选择合适的索引,可以极大提高PolarDB-X的检索速度。
执行计划介绍
一条SQL进入到PolarDB-X分布式数据库后,经过解析优化,会生成一个可运行的执行计划。该执行计划是按照执行过程中算子的依赖关系组成。一般通过执行计划树,可以窥探SQL在数据库内部是如何高效运行的。示例如下:
示例1
执行以下命令:
EXPLAIN select count(*) from lineitem group by L_LINESTATUS;返回执行计划信息如下:
| HashAgg(group="L_LINESTATUS", count(*)="SUM(count(*))") | | Exchange(distribution=hash[0], collation=[]) | | LogicalView(tables="[000000-000003].lineitem_[00-15]", shardCount=16, sql="SELECT `L_LINESTATUS`, COUNT(*) AS `count(*)` FROM `lineitem` AS `lineitem` GROUP BY `L_LINESTATUS`")由于group by的列和表lineitem分区键不对齐,group by不能完全下推给DN执行。所以group by会拆分成两阶段,将partition agg下推给DN,先做部分聚合;然后在CN层将数据做重分布式,再做一次最终的聚合,输出结果。
LogicalView:由于有16个分片,会生成多个下推物理SQL,每条物理SQL携带了group by部分,做预聚合。
Exchange:汇总LogicalView返回的数据,按照L_LINESTATUS字段做重分布式,输出给下游算子。
HashAgg:接受多路输入,做最终的聚合。
示例2
执行以下命令:
EXPLAIN select * from lineitem, orders where L_ORDERKEY= O_ORDERKEY;返回执行计划如下:
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | HashJoin(condition="O_ORDERKEY = L_ORDERKEY", type="inner") | | Exchange(distribution=hash[0], collation=[]) | | LogicalView(tables="[000000-000003].lineitem_[00-15]", shardCount=16, sql="SELECT `L_ORDERKEY`, `L_PARTKEY`, `L_SUPPKEY`, `L_LINENUMBER`, `L_QUANTITY`, `L_EXTENDEDPRICE`, `L_DISCOUNT`, `L_TAX`, `L_RETURNFLAG`, `L_LINESTATUS`, `L_SHIPDATE`, `L_COMMITDATE`, `L_RECEIPTDATE`, `L_SHIPINSTRUCT`, `L_SHIPMODE`, `L_COMMENT` FROM `lineitem` AS `lineitem`") | | Exchange(distribution=hash[0], collation=[]) | | LogicalView(tables="[000000-000003].orders_[00-15]", shardCount=16, sql="SELECT `O_ORDERKEY`, `O_CUSTKEY`, `O_ORDERSTATUS`, `O_TOTALPRICE`, `O_ORDERDATE`, `O_ORDERPRIORITY`, `O_CLERK`, `O_SHIPPRIORITY`, `O_COMMENT` FROM `orders` AS `orders`")示例2是典型的两张表做关联(join),由于两表分区键没对齐,所有join没有下推,整个执行过程是将两个表数据都扫描出来,在CN层做关联计算。
LogicalView:扫描表数据。
Exchange:汇总LogicalView返回的数据,分布按照关联条件的列做重分布式,输出给下游Join算子。
HashJoin:接受两边输入,通过构建HashTable的方式来计算关联结果。
示例3
执行以下命令:
EXPLAIN select * from lineitem, orders where L_LINENUMBER= O_ORDERKEY;返回执行计划信息如下:
| Gather(concurrent=true) | | LogicalView(tables="[000000-000003].lineitem_[00-15],orders_[00-15]", shardCount=16, sql="SELECT `lineitem`.`L_ORDERKEY`, `lineitem`.`L_PARTKEY`, `lineitem`.`L_SUPPKEY`, `lineitem`.`L_LINENUMBER`, `lineitem`.`L_QUANTITY`, `lineitem`.`L_EXTENDEDPRICE`, `lineitem`.`L_DISCOUNT`, `lineitem`.`L_TAX`, `lineitem`.`L_RETURNFLAG`, `lineitem`.`L_LINESTATUS`, `lineitem`.`L_SHIPDATE`, `lineitem`.`L_COMMITDATE`, `lineitem`.`L_RECEIPTDATE`, `lineitem`.`L_SHIPINSTRUCT`, `lineitem`.`L_SHIPMODE`, `lineitem`.`L_COMMENT`, `orders`.`O_ORDERKEY`, `orders`.`O_CUSTKEY`, `orders`.`O_ORDERSTATUS`, `orders`.`O_TOTALPRICE`, `orders`.`O_ORDERDATE`, `orders`.`O_ORDERPRIORITY`, `orders`.`O_CLERK`, `orders`.`O_SHIPPRIORITY`, `orders`.`O_COMMENT` FROM `lineitem` AS `lineitem` INNER JOIN `orders` AS `orders` ON (`lineitem`.`L_LINENUMBER` = `orders`.`O_ORDERKEY`)") |示例3也是典型的两张表做关联,由于两表分区键对齐,所有join下推到各个分片的DN来执行,上层的CN节点只需要通过Gather算子将DN返回的结果汇总输出。
示例4
执行以下命令:
EXPLAIN select * from gsi_dml_unique_multi_index_base where integer_test=1;返回执行计划信息如下:
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Project(pk="pk", integer_test="integer_test", varchar_test="varchar_test", char_test="char_test", blob_test="blob_test", tinyint_test="tinyint_test", tinyint_1bit_test="tinyint_1bit_test", smallint_test="smallint_test", mediumint_test="mediumint_test", bit_test="bit_test", bigint_test="bigint_test", float_test="float_test", double_test="double_test", decimal_test="decimal_test", date_test="date_test", time_test="time_test", datetime_test="datetime_test", timestamp_test="timestamp_test", year_test="year_test", mediumtext_test="mediumtext_test") | | BKAJoin(condition="pk = pk", type="inner") | | IndexScan(tables="DRDS_POLARX1_QATEST_APP_000000_GROUP.gsi_dml_unique_multi_index_index1_a0ol_01", sql="SELECT `pk`, `integer_test`, `varchar_test`, `char_test`, `bit_test`, `bigint_test`, `double_test`, `date_test` FROM `gsi_dml_unique_multi_index_index1` AS `gsi_dml_unique_multi_index_index1` WHERE (`integer_test` = ?)") | | Gather(concurrent=true) | | LogicalView(tables="[000000-000003].gsi_dml_unique_multi_index_base_[00-15]", shardCount=16, sql="SELECT `pk`, `blob_test`, `tinyint_test`, `tinyint_1bit_test`, `smallint_test`, `mediumint_test`, `float_test`, `decimal_test`, `time_test`, `datetime_test`, `timestamp_test`, `year_test`, `mediumtext_test` FROM `gsi_dml_unique_multi_index_base` AS `gsi_dml_unique_multi_index_base` WHERE ((`integer_test` = ?) AND (`pk` IN (...)))") | | HitCache:true本示例中,SQL本身只是带有谓词的简单查询,结果从执行计划看是两表做关联(BKAJoin)。主要是gsi_dml_unique_multi_index_base在列上integer_test有全局二级索引,命中索引可以减少扫描代价,但这个索引并不是覆盖索引,所以需要有回表操作。
IndexScan:根据integer_test=1扫描出索引表gsi_dml_unique_multi_index_index1_a0ol_01数据。
BKAJoin:收集IndexScan的结果,通过该算子和主表gsi_dml_unique_multi_index_base做回表关联,获取其他列值。
说明通常情况下,通过查询执行计划,可以查看到是否命中了全局二级索引等信息。但是对于下推部分的SQL,还可以通过explain execute指令,获取物理SQL在DN上的执行情况,比如是否命中了DN的局部索引。