
对于电商或SaaS等多租户业务场景,您可能需要为不同级别的租户(如VIP客户与普通客户)提供差异化的服务质量和资源保障。传统方案往往面临资源隔离不彻底、租户扩缩容操作复杂等挑战。PolarDB-X提供存储资源池功能,允许您将物理数据节点(DN)逻辑划分为不同的资源组。通过将数据库或表分区绑定到指定的资源池,您可以轻松实现租户间的物理资源隔离、灵活调整资源分配,从而有效保障核心业务的稳定性并简化运维管理。
功能简介
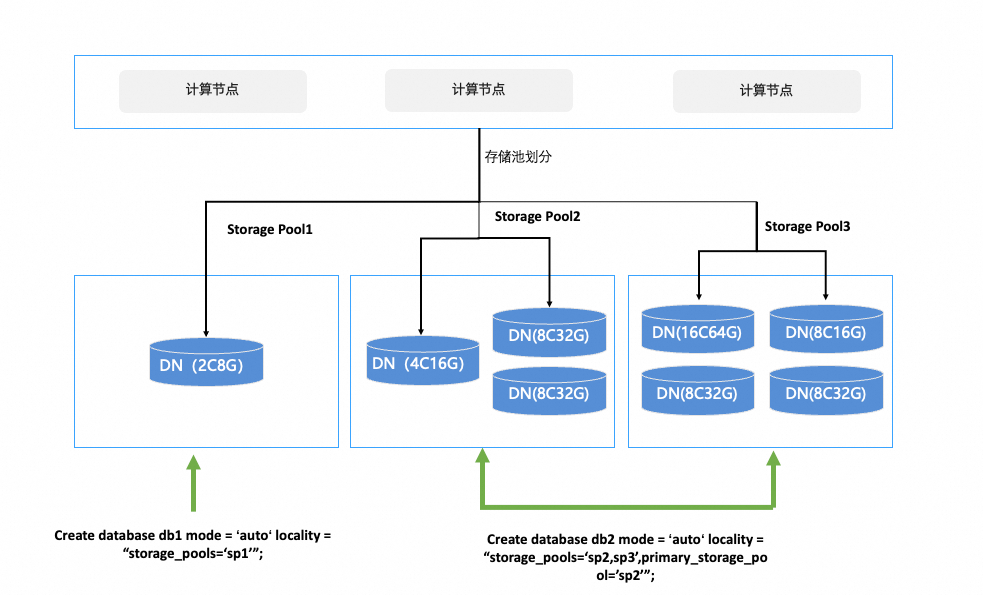
存储资源池(Storage Pool)是PolarDB-X提供的一种资源管理能力,它允许您将实例中的物理数据节点(DN)划分为若干个逻辑资源组。每个资源池由一个或多个DN组成,不同资源池之间DN互不重叠。
您可以将数据库、表或表分区等数据库对象与特定的资源池进行绑定,从而将这些对象的数据物理地隔离在指定的DN节点上。当资源池内的节点或数据库对象的绑定关系发生变更时,系统会自动触发数据迁移,以满足新的资源布局要求。
该功能主要用于实现多租户场景下的资源隔离、服务分级以及业务负载的精细化管理。
适用范围
实例内核版本需为
5.4.20-20250806及以上。逻辑库的分区模式(
MODE)需为auto模式。
使用说明
存储资源池
建议您使用PolarDB分布式版控制台中的数据节点管理功能来创建和管理存储资源池。以下关于存储资源池的相关SQL语句仅用于辅助理解其工作原理,不建议您在业务环境中直接执行。
查看存储资源池
在进行任何操作前,您首先需要了解当前实例已有的资源池及其状态。
系统默认资源池
一个PolarDB-X实例默认包含两个系统存储池:
_default:默认存储池。初始状态下,它包含实例中所有的活跃数据节点(DN)。如果您在创建数据库对象时未指定资源池,数据将默认存放在此池中。_recycle:回收存储池。它用于存放从其他资源池中移除、或尚未分配的空闲数据节点。这些节点是创建新资源池或为现有资源池扩容的来源。
查询方法
您可以通过查询information_schema.storage_pool_info视图来获取所有资源池的详细信息。
SELECT * FROM information_schema.storage_pool_info;输出示例
+------+----------+-----------------------------------------------------+-----------------+---------------------------+--------+---------------------+---------------------+
| ID | NAME | DN_ID_LIST | IDLE_DN_ID_LIST | UNDELETABLE_DN_ID | EXTRAS | GMT_CREATED | GMT_MODIFIED |
+------+----------+-----------------------------------------------------+-----------------+---------------------------+--------+---------------------+---------------------+
| 1 | _default | dn0,dn1,dn2,dn3,dn4,dn5,dn6,dn7,dn8,dn9 | | dn0 | NULL | 2024-04-15 19:46:05 | 2024-04-15 19:46:05 |
| 2 | _recycle | | | | NULL | 2024-04-15 19:46:05 | 2024-04-15 19:46:05 |
+------+----------+-----------------------------------------------------+-----------------+---------------------------+--------+---------------------+---------------------+变更存储资源池
您可以向现有资源池中添加节点(扩容),或从中移除节点(缩容)。移除节点后,存储池将自动变更为_recycle存储池。然而,您无法移除资源池中的UNDELETABLE_DN_ID。每个存储资源池必须至少包含一个DN节点,并且其中一个DN将被指定为UNDELETABLE DN。在资源池未被删除之前,该节点无法被移除。
缩容
从资源池移除节点。缩容时,节点上的数据会自动异步迁移。
-- 从资源池移除节点(节点上的数据会自动迁移)
ALTER STORAGE POOL <pool_name> DRAIN NODE "<dn_id_list>";示例
对_default存储池进行缩容,仅dn0保留在_default存储池中,其他节点均放入_recycle存储池中。
ALTER STORAGE POOL _default DRAIN NODE 'dn1,dn2,dn3,dn4,dn5,dn6,dn7,dn8,dn9';查看存储资源池,结果如下:
SELECT * FROM information_schema.storage_pool_info;
+------+----------+-----------------------------------------------------+-----------------+---------------------------+--------+---------------------+---------------------+
| ID | NAME | DN_ID_LIST | IDLE_DN_ID_LIST | UNDELETABLE_DN_ID | EXTRAS | GMT_CREATED | GMT_MODIFIED |
+------+----------+-----------------------------------------------------+-----------------+---------------------------+--------+---------------------+---------------------+
| 1 | _default | dn0 | | dn0 | NULL | 2024-04-15 19:46:05 | 2024-04-15 19:46:05 |
| 2 | _recycle | dn1,dn2,dn3,dn4,dn5,dn6,dn7,dn8,dn9 | | | NULL | 2024-04-15 19:46:05 | 2024-04-15 19:46:05 |
+------+----------+-----------------------------------------------------+-----------------+---------------------------+--------+---------------------+---------------------+扩容
向资源池添加节点。
- 向资源池添加节点
ALTER STORAGE POOL <pool_name> APPEND NODE "<dn_id_list>";新增的节点不得包含任何数据库对象。
不同资源池的DN之间不能互相交叉。
同一存储资源池内部允许包含不同规格的DN节点。
示例
对_default存储池扩容,将dn1节点放回_default存储池。
ALTER STORAGE POOL _default APPEND NODE 'dn1';查看存储资源池,结果如下:
SELECT * FROM information_schema.storage_pool_info;
+------+----------+-----------------------------------------------------+-----------------+---------------------------+--------+---------------------+---------------------+
| ID | NAME | DN_ID_LIST | IDLE_DN_ID_LIST | UNDELETABLE_DN_ID | EXTRAS | GMT_CREATED | GMT_MODIFIED |
+------+----------+-----------------------------------------------------+-----------------+---------------------------+--------+---------------------+---------------------+
| 1 | _default | dn0,dn1 | | dn0 | NULL | 2024-04-15 19:46:05 | 2024-04-15 19:46:05 |
| 2 | _recycle | dn2,dn3,dn4,dn5,dn6,dn7,dn8,dn9 | | | NULL | 2024-04-15 19:46:05 | 2024-04-15 19:46:05 |
+------+----------+-----------------------------------------------------+-----------------+---------------------------+--------+---------------------+---------------------+创建存储资源池
您可以将回收池(_recycle)中的空闲数据节点(DN)组合起来,创建一个新的自定义存储资源池。
CREATE STORAGE POOL <pool_name> DN_LIST = "<dn_id_1>,<dn_id_2>,..." UNDELETABLE_DN = "<dn_id>";参数说明
pool_name:自定义资源池的名称。DN_LIST:该资源池包含的数据节点ID列表,这些节点必须是空闲的。UNDELETABLE_DN:指定一个不可删除的节点,以保证资源池的最低可用性。
规则说明
每个存储资源池必须至少包含一个DN节点,并且其中一个DN将被指定为
UNDELETABLE DN。在资源池未被删除之前,该节点无法被移除。在创建存储资源池时,指定的DN上需不包含任何数据库对象。
不同资源池的DN之间不能互相交叉。
同一存储资源池内部允许包含不同规格的DN节点。
示例
-- 创建一个名为pool_1,包含dn4, dn5, dn6三个节点的资源池
CREATE STORAGE POOL pool_1 DN_LIST="dn4,dn5,dn6" UNDELETABLE_DN="dn4";
-- 创建一个名为pool_2,包含dn7一个节点的资源池
CREATE STORAGE POOL pool_2 DN_LIST="dn7" UNDELETABLE_DN="dn7";
-- 创建一个名为pool_3,包含dn8, dn9三个节点的资源池
CREATE STORAGE POOL pool_3 DN_LIST="dn8,dn9" UNDELETABLE_DN="dn8";关联存储资源池与数据库对象
定义关联关系
在创建数据库、表或分区时,可以通过LOCALITY子句指定其数据存放的资源池。允许指定多个存储资源池(storage_pools),并单独指定一个默认存储资源池列表(primary_storage_pool)。一个完整的存储池绑定声明如下:
CREATE DATABASE | TABLE ... LOCALITY = "storage_pools=<pool_list>;primary_storage_pool=<pool_name>";参数说明
storage_pools:允许该数据库对象使用的所有资源池列表。对于广播表,它会在该列表的所有资源池中创建副本。primary_storage_pool:默认使用的资源池。如果不显式为子对象(如表、分区)指定LOCALITY,它们将默认使用此主资源池。说明在显式为子对象(如表、分区)指定存储资源池时,需从属于其上一级对象,即数据库对象所具备的存储资源池(
storage_pools)。
示例
-- 创建一个数据库,其数据默认存放在pool_vip中
CREATE DATABASE db_test MODE = "auto" LOCALITY = "storage_pools=pool_1,pool_2,pool_3;primary_storage_pool=pool_1,pool_2";变更关联关系
对于数据库、表组或分区,允许直接变更其存储资源池。您可以修改其LOCALITY定义,以实现数据的在线迁移。
如果对对象关联的存储资源池进行追加,除了扩增广播表的节点范围外,不会进行其他操作。
如果对对象关联的存储资源池进行删减,则需消除该对象及其子对象在被删除资源池上所有对象的存储资源池定义,并进行迁移。
(库级别不支持此操作)如果完全清除对象关联的存储资源池,则等同于将该对象关联的资源池变更为默认资源池。
ALTER DATABASE | TABLE <object_name> [SET] LOCALITY = "...";此操作会触发后台的数据迁移任务,将数据从旧的资源池移动到新的资源池,整个过程对应用在线。
对于库级别的对象,无论如何变更关联的存储资源池,都不允许在
storage_pools列表中删除primary_storage_pool,也不允许变更已定义的primary_storage_pool,对于表组和分区则没有此限制。
示例
ALTER TABLE db_test LOCALITY = "storage_pools=pool_1;primary_storage_pool=pool_1";场景示例
场景一:库级租户
以一个电商平台(以下简称X公司)为例,其系统需要维护多个卖家的订单,其中包含有若干流水显著较高的大卖家和大部分小卖家,X公司对于大小卖家的资源划分要求如下:
大卖家需要使用单独的存储资源存储数据,确保在线流量稳定,同时需要提供单独的跑批数据分析能力。
小卖家需要共享一组存储资源,并且小卖家占用的资源需要尽可能在该组资源中保持均衡。
部分小卖家随着时间演进可能演变为大卖家,部分大卖家可能迁移到其他平台或者从其他平台迁入。
租户定义
X公司的需求可以通过库级资源隔离实现,然后按大卖家的需求,将已有的存储节点划分为若干存储池,对于小卖家的共享库,可直接建在默认存储池之上:
CREATE STORAGE POOL sp1 dn_list="dn4,dn5,dn6" undeletable_dn="dn4";
CREATE STORAGE POOL sp2 dn_list="dn7,dn8,dn9" undeletable_dn="dn7";
CREATE DATABASE orders_comm MODE = "auto"
LOCALITY= "storage_pools='_default'"; /* 小卖家共享_default存储池(dn1, dn2, dn3 */
CREATE DATABASE orders_seller1 MODE = "auto"
LOCALITY= "storage_pools='sp1'"; /* 大卖家1使用sp1存储池(dn4, dn5, dn6) */
CREATE DATABASE orders_seller2 MODE = "auto"
LOCALITY= "storage_pools='sp2'"; /* 大卖家2使用sp2存储池(dn7, dn8, dn9) */
...通过上述建库语句,应用可获得以下效果:
大卖家之间、大卖家与小卖家之间各自使用单独存储资源存储,存储资源完全隔离。
小卖家之间共享默认存储池的资源dn1~dn3。
大小卖家之间的建表语句可以完全独立,可以自行决定每个卖家的表结构定义以及存储资源。
资源均衡
小卖家的库内部可以使用Locality的单表打散模式全部建成单表,也可以建成分区表。当小卖家之间也存在数据分布的差异,需要在小卖家内部均衡资源分配时,只需直接调用存储池级别的资源均衡语句。
REBALANCE TENANT "_default" POLICY="data_balance";REBALANCE将会自动按照存储池内的对象属性定义均衡相应的单表和分区分布,与实例级别的扩缩容一样,该操作将自动满足资源约束,并且尽可能均衡所有单表和所有分区在dn1~dn3上的分布。
租户迁入及迁出
当平台迁入新的大卖家时,可在实例中加入新的存储节点(默认加入到_recycle存储池),然后使用该节点单独建立存储池,并新建大卖家相关的库使之独占新的存储池。
CREATE STORAGE POOL spn dn_list = "dn10,dn11,dn12" undeletable_dn="dn10";
/* 新定义存储池spn (dn10, dn11, dn12) */
CREATE DATABASE orders_sellern MODE = "auto"
LOCALITY="storage_pools='spn'";
/* 大卖家N使用spn存储池 */如果大卖家迁出,可删除相应库并且释放相应资源。
DROP DATABASE orders_sellern;
DELETE STORAGE POOL spn;/* 删除存储池,相应的节点将会自动进入_recycle存储池 */
ALTER STORAGE POOL _recycle DRAIN NODE "dn7, dn8, dn9"; /* 在集群中释放相应的节点 */在新增以及删除上述存储池和库时,已有的业务不会受到影响,对应用几乎是透明无感的。
场景二:分区级租户
对于场景一中X公司的需求,也可以通过分区级资源隔离实现,相比于库级租户,分区级租户可以提供完全一致的资源隔离能力,并且具备更多优势:
所有分区共享逻辑表的定义,加减列、加减索引等数据运维操作以及广播表的下推关系均由数据库自动维护。
通过分区分裂、分区合并等已有的分区管理能力,可以获得更加灵活的资源变更能力,如将部分租户升级到VIP服务、合并部分租户的资源等等。
租户定义
首先将存储节点划分为相应的存储池,然后使用全部存储池建立一个公共库。
CREATE DATABASE orders_db MODE = "auto"
LOCALITY = "storage_pools='_default,sp1,sp2,...',primary_storage_pool='_default'"
USE orders_db;
CREATE TABLE commodity(
commodity_id int,
commodity_name varchar(64)
) BROADCAST;
/*commodity作为一张广播表,将会在所有的存储池上建立分表,因此可与orders_sellers的任何一个分区进行join下推。*/
CREATE TABLE orders_sellers(
order_id int AUTO_INCREMENT primary key,
customer_id int,
commodity_id int,
country varchar(64),
seller_id int,
order_time datetime not null)
partition BY list(seller_id)
(
partition p1 VALUES IN (1, 2, 3, 4),
partition p2 VALUES IN (5, 6, 7, 8),
/*orders_seller的分区p1, p2默认会使用_default存储池中的节点进行存储,共享_default存储池中的资源。*/
...
partition pn VALUES IN (k) LOCALITY = "storage_pools='sp1'",
partition pn+1 VALUES IN (k+1, k+2) LOCALITY = "storage_pools='sp2'",
/*orders_seller的分区pn, pn+1会分别使用sp1, sp2存储池中的节点进行存储,分别独自占用相应存储节点的资源。*/
...
) LOCALITY = "storage_pools='_default,sp1,sp2,...'";库的定义中包含了全部存储池,但是同时定义了primary_storage_pool为_default存储池,因而orders_sellers中的分区默认会使用_default存储池作为存储节点列表,而广播表会自动分布在所有存储池节点上。
不同分区的定义包含不同的租户集合,并且可以自行指定分区的存储资源。
租户迁入和迁出
对于新增的小租户,可以直接添加分区,默认不迁移数据,只产生新分区。
ALTER TABLE orders_sellers ADD PARTITION
(PARTITION p3 values in (32, 33));对于新增的大租户,可向已有的存储节点中添加节点,并且加入到分区路由直接添加分区,同时指定其占用的存储池。
CREATE STORAGE POOL spn dn_list = "dn10,dn11,dn12" undeletable_dn="dn10";
/*向实例中新增了一个存储池spn.*/
ALTER DATABASE orders_db SET LOCALITY =
"storage_pools='_default,sp1,sp2,...,spn',primary_storage_pool='_default'"
/*向orders_db的存储池列表中添加spn, 这一修改将会自动触发广播表迁移到新的存储池节点之上。*/
ALTER TABLE orders_sellers ADD PARTITION
(PARTITION p4 values in (34) LOCALITY="storage_pools='spn');
/*在orders_sellers中新增一个租户分区,并且该分区分布在自定义的存储池spn上。*/同样,对于租户迁出,可直接删除相应分区并释放存储池资源。
ALTER TABLE orders_sellers DROP PARTITION p4;或者变更相应的分区定义,在分区内部删除小卖家。
ALTER TABLE orders_sellers MODIFY PARTITION p1 DROP VALUES (4, 5);对分区级租户而言,所有分区共享逻辑表的定义,因而数据模式变更可由数据库统一维护。上述分区变更语句均为online操作,仅影响实际操作涉及的分区,对其他分区的已有业务均无影响。
租户服务级别变更
当小卖家的服务级别需要升级为VIP级别时,可修改分区定义,将其单独分配到一个存储池上:
ALTER TABLE orders_sellers SPLIT PARTITION p2 INTO
(PARTITION p2 VALUES in (6, 7, 8) ,
PARTITION `pn+2` VALUES in (5) LOCALITY = "storage_pools='spn+3'");同样,可以根据对大卖家的服务级别进行降级。
ALTER TABLE orders_sellers MERGE PARTITION p1, pn TO p1 LOCALITY="";上述操作的效果将直接合并p1和pn分区的数据,并且新分区仍然存储于默认存储池之上。
在保留库级租户资源隔离的能力的基础上,分区级租户通过完善的分区管理接口提供了更加灵活的租户资源变更和控制能力。
资源均衡
当租户间在分区级别出现负载不均时,同样可以通过存储池级别的REBALANCE操作在公共存储池中进行负载均衡。
REBALANCE TENANT "_default" POLICY="data_balance";场景三:单机到分布式的迁移演进
以一个从单机关系型数据库到分布式数据库的迁移过程为例,在迁移初期,用户希望尽可能复用原有的使用模式,在享有分布式数据库scale out能力的同时,尽可能做到无痛改造;随着业务逐步发展,以表为单位逐步推动部分业务负载较大的单表进一步演进到分布式表,同时确保尽可能不影响已有业务的库表模型和资源占用。
通过存储池定义不同表的存储资源,即可实现单表与分布式表共存的集中分布式一体化使用模式,帮助用户平滑演进到分布式数据库。
建库建表
除少数具有广播表语义的表外,用户可使用单表打散模式在PolarDB-X中复用原有的单机建表语句,从而实现存量业务的一键迁移改造。
CREATE DATABASE orders_db MODE = "auto" DEFAULT_SINGLE=on
LOCALITY = "storage_pools='_default',primary_storage_pool='_default'";
use orders_db;
CREATE TABLE orders_region1(
order_id int AUTO_INCREMENT primary key,
customer_id int,
country varchar(64),
city int,
order_time datetime not null);
CREATE TABLE orders_region2(
order_id int AUTO_INCREMENT primary key,
customer_id int,
country varchar(64),
city int,
order_time datetime not null);
CREATE TABLE orders_region3(
order_id int AUTO_INCREMENT primary key,
customer_id int,
country varchar(64),
city int,
order_time datetime not null);
CREATE TABLE commodity(
commodity_id int,
commodity_name varchar(64)
) BROADCAST;上述建库和建表语句实现了两个效果:
所有应用单机建表语句的单表将会自动按照数据量和表的数量自动在_default存储池中均衡。
广播表将在_default存储池的所有节点上建立分表。
隔离部分单表
部分单表承载的数据量和访问量过大,可以在实例中添加新的存储节点,并将负载过大的单表单独隔离到新的节点上:
ALTER DATABASE orders_db set LOCALITY = "storage_pools='_default,sp1',primary_storage_pool='_default'";
/* 对数据库的变更将会自动处理广播表的分表扩张行为。 */
ALTER TABLE orders_region_single1 single LOCALITY = "storage_pools='sp1'";
/* 将业务负载较大的单表隔离到sp1存储池的节点上。*/分布式改造
随着业务演进,用户可将超出单个物理表负载限制的表改造为分布式表,并且指定其所使用的存储节点:
ALTER DATABASE orders_db set LOCALITY = "storage_pools='_default,sp1,sp2,sp3',primary_storage_pool='_default'";
ALTER TABLE orders_region_single2 partition by hash(order_id) partitions 16
LOCALITY = "storage_pools='sp2'";
/* orders_region_single2 使用存储池sp2 */
ALTER TABLE orders_region_single3 partition by hash(order_id) partitions 16
LOCALITY = "storage_pools='sp3'";
/* orders_region_single3 使用存储池sp3 */拆分变更允许用户以online执行的方式自定义目标表的分区方式和存储资源,从而做到表级别的业务模型改造,帮助用户无痛实现从单表到分布式表的演进。