在金融行业,为了保证系统的高可用性和容灾能力,采用两个机房作为主中心,一个机房作为备份中心的架构模式,简称为“两地三中心架构”。两地三中心架构广泛应用于金融行业中的核心业务系统,如支付结算、证券交易、贷款管理。本文介绍两地三中心的相关概念和运维操作。
使用限制
PolarDB-X两地三中心形态当前仅支持专有云DBStack 1.2.1版本及以上。
两地三中心架构和技术原理
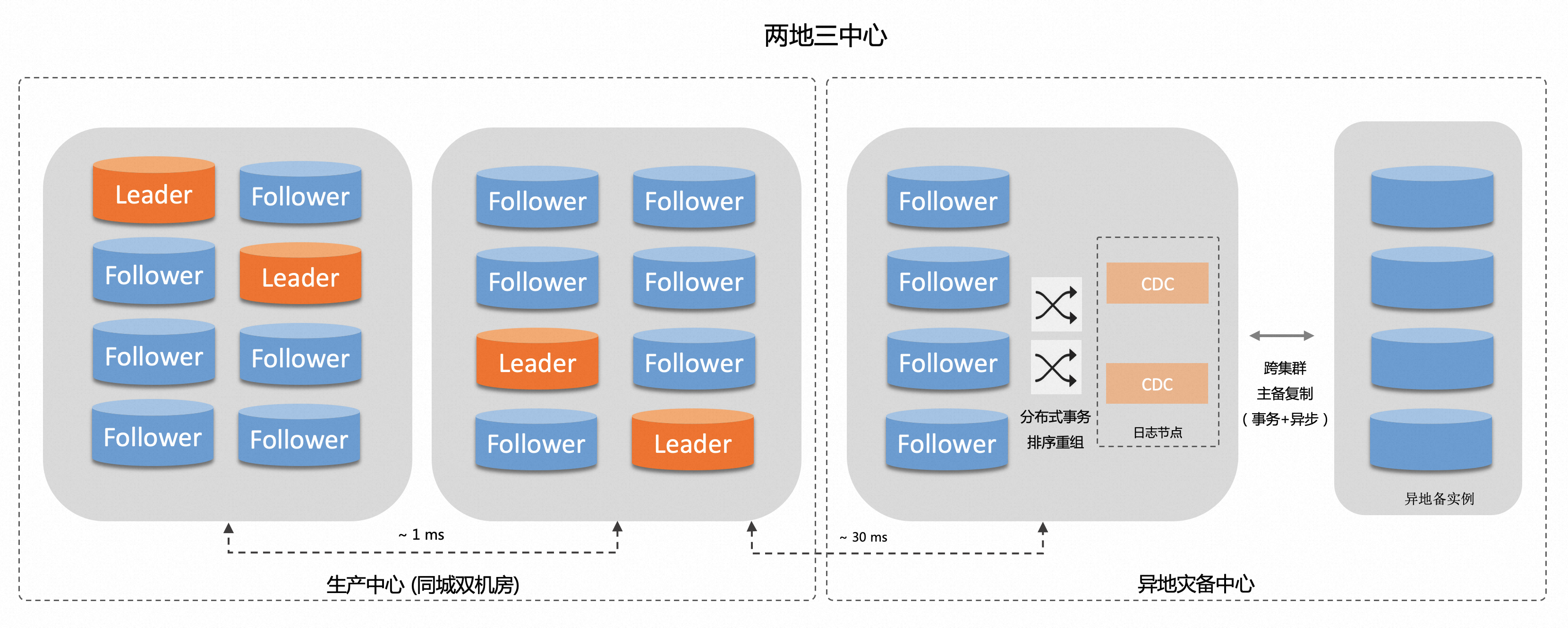
PolarDB-X基于多数派共识协议Paxos支持两地三中心5副本 + 主备集群的部署架构,满足跨域高可用下的RPO=0,需要细粒度支持不同级别的容灾。
容灾场景 | 细粒度场景 | 高可用容灾策略 |
单副本故障 | 主中心机房Leader副本 | 触发Leader重新选举,同机房副本优先(业务流量需要就近访问)。 |
主中心机房Follower副本 | 无影响。 | |
备份中心机房Follower副本 | 无影响。 | |
机房故障 | 主中心机房 | 剩余3副本(会出现跨地域的强同步),5副本动态降级为3副本。 |
备份中心机房 | 剩余主中心4副本,对多数派协议无影响。 | |
地域故障 | 主中心 |
|
备份中心 | 无影响。 |
基于容灾策略的需求,引申出跨地域高可用架构的设计:权重化选举、副本数动态调整、单副本强制启动 、异地备集群。
权重化选举
PolarDB-X在两地三中心设计中引入选举权重,对应的工作原理:
乐观权重机制:在Paxos多数派共识协议的选举策略中,那些更容易发起选举的节点倾向于成为Leader。为了优化这一点,通过引入权重概念,对不同节点设置了启动Leader选举的随机延时,从而保证那些拥有较高权重的节点能够优先发起Leader选举。
强制权重机制:当某一个新成为Leader的节点发现自己不是所有节点中权重最高的节点的时候(当所有节点权重一致的时候,任意节点都是权重最高的点,所以此判定不生效),不会立刻放开写入,而是继续等待一个选举超时的时间段(称为禅让阶段),在禅让阶段会每隔一个心跳时间(比如1~2秒),向其它节点发送一次心跳探测。在选举时间段结束以后,如果收到其他权重比自己大的节点回包,即向回包节点中权重最大的节点发起一次Leader转移,确保高权重的节点成为Leader。
PolarDB-X两地三中心副本的选举权重配置:
机房 | 副本 | 选举权重 |
中心机房 1 | Leader | 9 |
Follower | 7 | |
中心机房 2 | Follower | 5 |
Follower | 3 | |
备份中心 | Follower | 1 |
当中心机房1的Leader副本出现故障,触发Leader选举,同机房下的Follower副本选举权重为7,优先会成为Leader,满足同机房优先的策略。
副本数动态调整
在两地三中心中,5副本多数派的复制组需要>=3个副本完成同步响应,默认情况下主中心的4副本会因为网络延迟的优势,优先在同城完成多数派的同步响应,多数派协议的延迟基本在1ms左右。但出现中心机房级别的故障后仅剩余3副本,会导致必须等待备份中心的副本也同步响应,从而导致多数派协议的延迟增加30ms(例如,常见的金融行业中主中心和备份中心的网络延迟在30ms左右)。
常见的副本数调整场景:
5副本降级为3副本,引入
downgrade_follower指令将Follower角色降级Learner角色,动态修改两个副本的角色3副本升级为5副本,引入
upgrade_learner指令将Learner角色升级为Follower角色,需要确保Learner异步复制日志追平。1副本升级为3副本,引入
add_follower指令动态新增节点,新节点会先成为Learner角色,追平日志之后自动转成Follower角色。
单副本强制启动
两地三中心中,当中心地域完全故障时,常见的多数派共识协议会因为剩余1个副本无法满足多数派,导致备份中心的副本无法承担数据服务。
PolarDB-X支持单副本强制启动的能力,引入force_single_mode指令,强制单节点服务并剔除所有Follower。另外,等中心机房故障恢复后,通过副本数动态调整能力,再从1副本恢复为3副本、5副本,实现最终的数据服务的恢复。
异地备集群
金融行业容灾标准,针对异地容灾的RPO和RTO都有细粒度的要求,如下表所示:
容灾等级 | RTO(恢复时间目标) | RPO(恢复点目标) | 灾备部署运维能力 |
4级 | ⩽ 30分钟 | 0 | 同城灾备或异地灾备 |
5 级 | ⩽ 15分钟 | 0 | 异地容灾,异地至少单副本 |
6级 | ⩽ 1分钟 | 0 | 异地容灾,异地至少双副本 |
PolarDB-X为满足异地容灾 RTO 的要求,采用两地三中心 5 副本 + 主备集群提供异地备集群实例,当中心地域完全故障时,业务可以快速切流到异地备集群来实现故障恢复。
两地三中心主备集群相关的设计要点:
PolarDB-X的主集群,采用跨地域Paxos复制协议,需要>=3个副本完成同步响应,默认情况主中心的4副本会因为网络延迟的优势,优先在同城完成多数派的同步响应,而主集群的异地副本普遍是异步响应,所以主集群不会受到异地副本的网络延迟影响。
PolarDB-X的备集群,主要部署在异地,通过PolarDB-X的CDC日志节点组件,构建准实时的跨集群主备复制,虽然异地备集群会有一定的数据复制延迟,但需要确保分布式事务场景下的原子性复制,避免出现事务不一致的情况。
跨集群的主备复制,尤其在两地三中心场景(主集群的异地副本,不同Paxos复制组会因为网络延迟出现分布式事务复制进度之间有差异),需要在异地部署CDC日志节点进行分布式事务排序重组,提供分布式事务的原子性复制能力,确保跨集群主备复制不会出现事务只有一半提交的状态。通过原子性事务复制,在日常的容灾演练、以及真实故障场景下,都可以确保业务切流到异地备集群时事务数据的完整性。
常见的运维操作
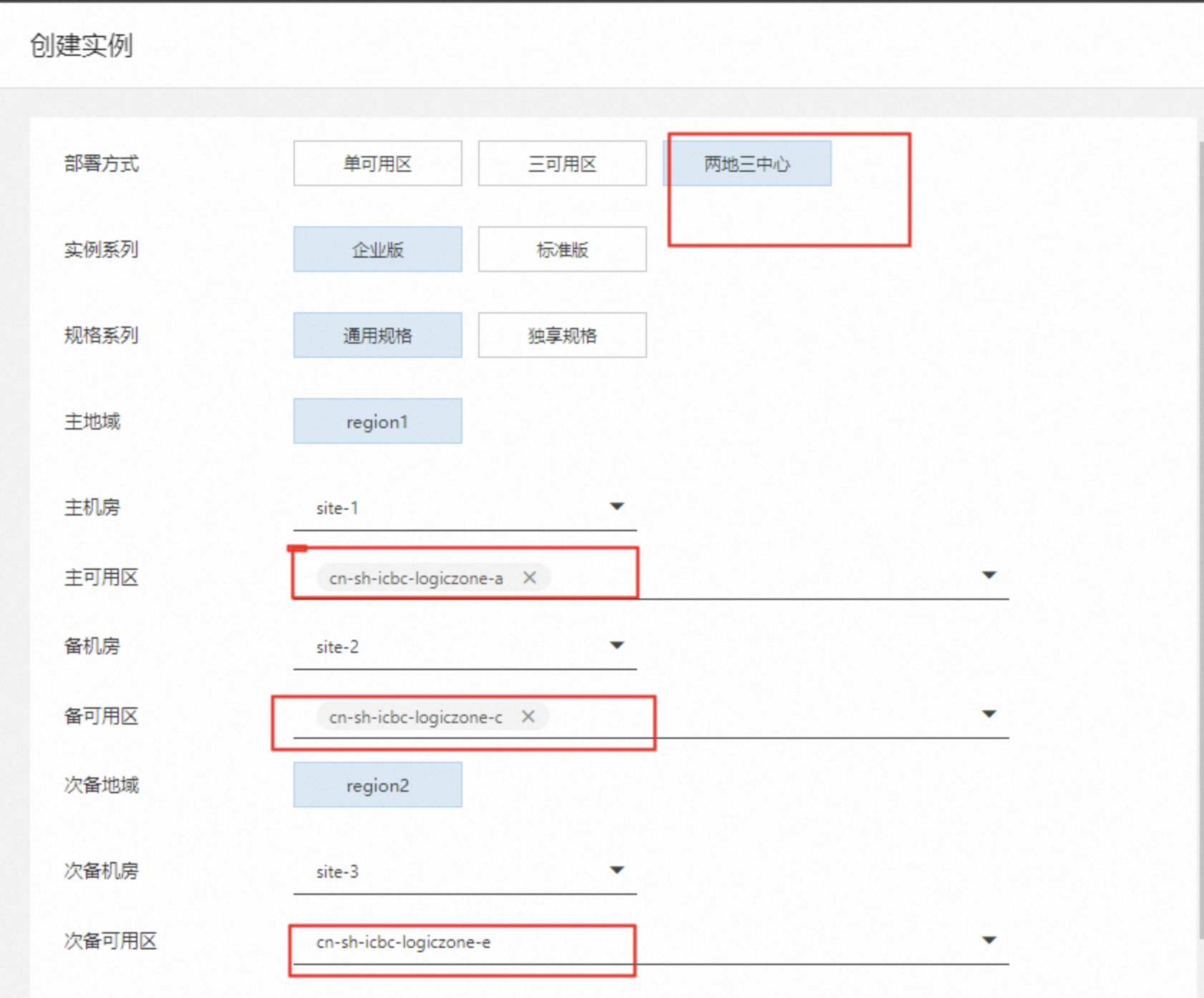
创建实例
在购买PolarDB-X实例时,部署方式可以选择两地三中心。
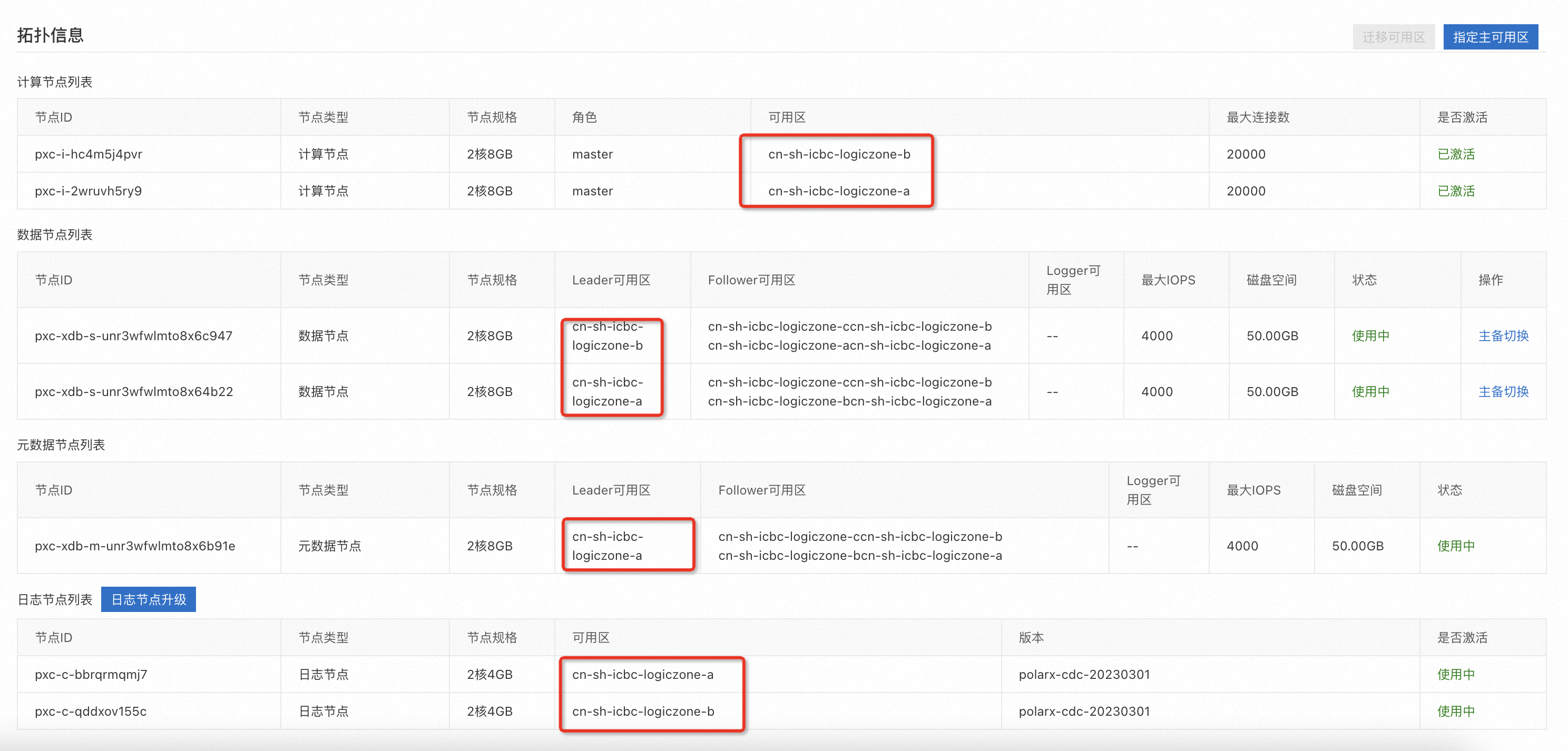
查看实例拓扑
在实例基本信息页面底部的拓扑信息区域,可以查看对应资源的可用区信息。
容灾切换
在页面左上角选择目标实例所在地域。
在实例列表页,单击PolarDB-X 2.0页签。
找到目标实例,单击实例ID。
在基本信息页面底部的拓扑信息区域,单击右侧的指定主可用区。
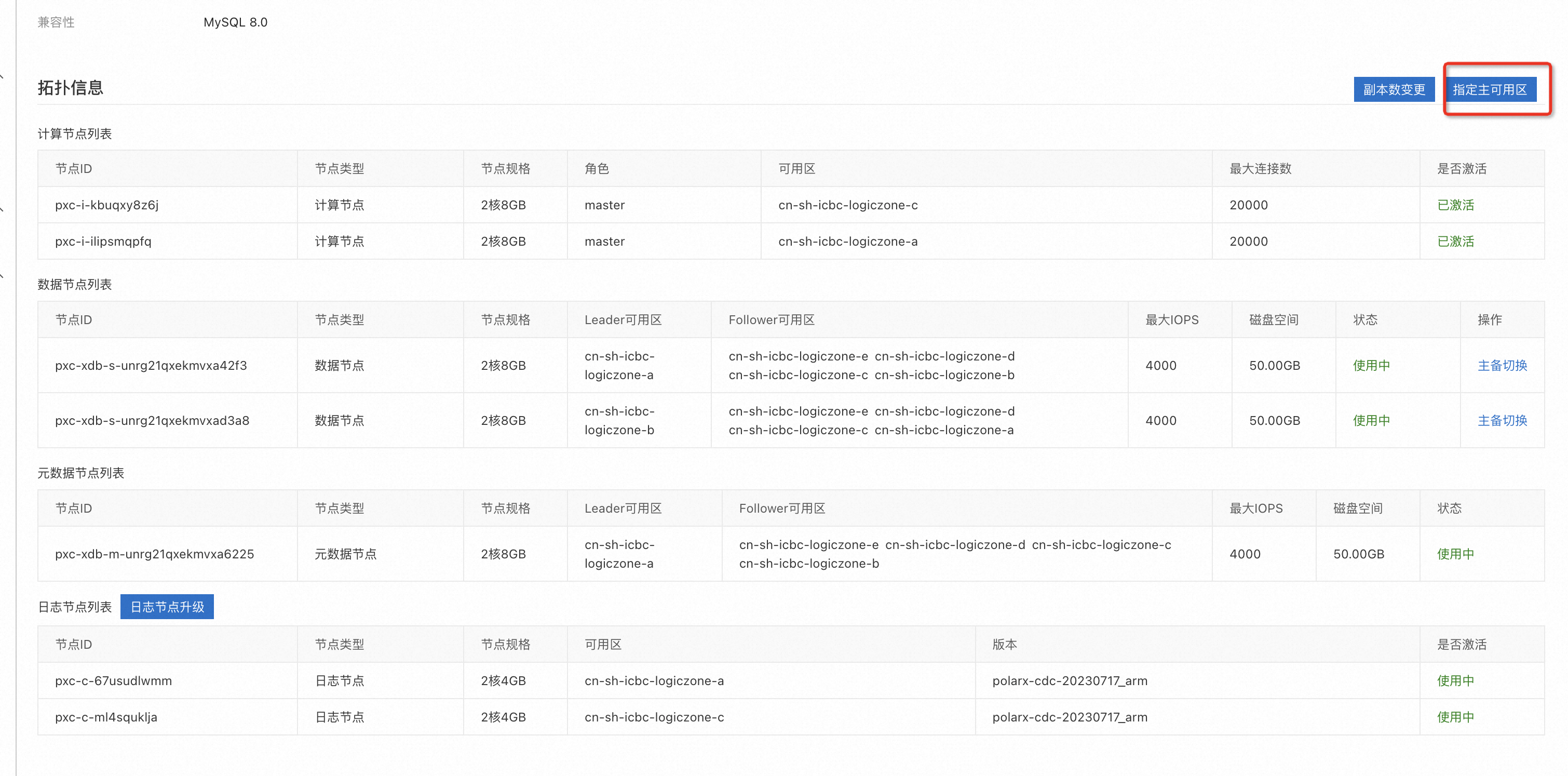
在弹出的指定主可用区对话框,选择机房、主可用区、切换模式。
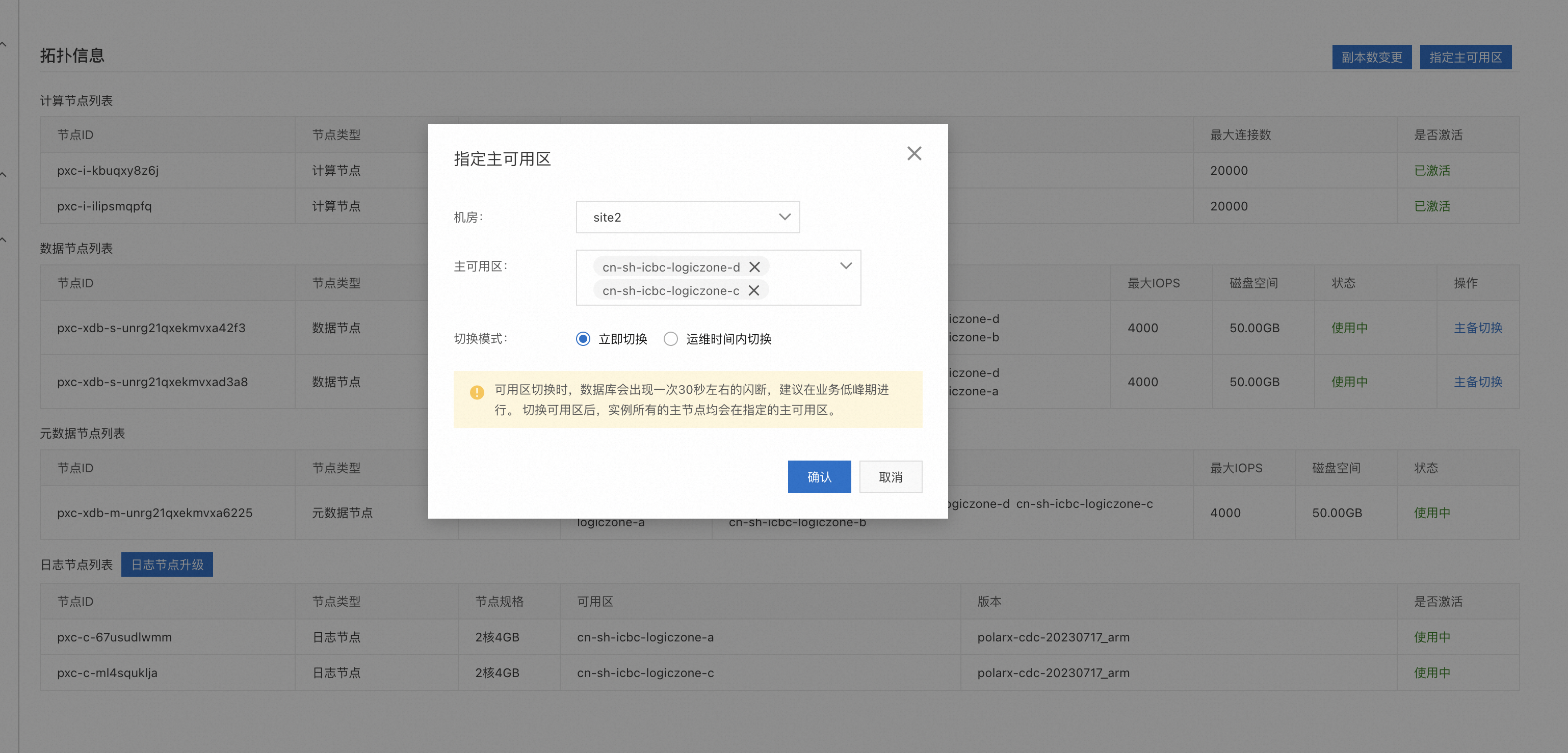
单击确认。