
什么是关系模型?
关系模型简介
Quick BI关系模型是一套用于多表关联与分析的数据建模体系,旨在解决传统物理建模中效率低、准确性不足、分析灵活性差等问题,适用于复杂业务场景下的多维数据分析需求。
在关系模型中,您无需关注数据细节,无需指定明确的关联方式,只需要将有关系的表统一放置在画布中,并配置关联键,即可轻松完成建模。
在大力提高建模效率的同时,关系模型的数据正确性也可以得到有力保障。Quick BI会根据查询时用到的具体字段,以及关系的配置,灵活调整查询SQL,保证数据准确性。具体处理逻辑可参考关系模型如何工作?
关系模型核心价值
背景及痛点问题
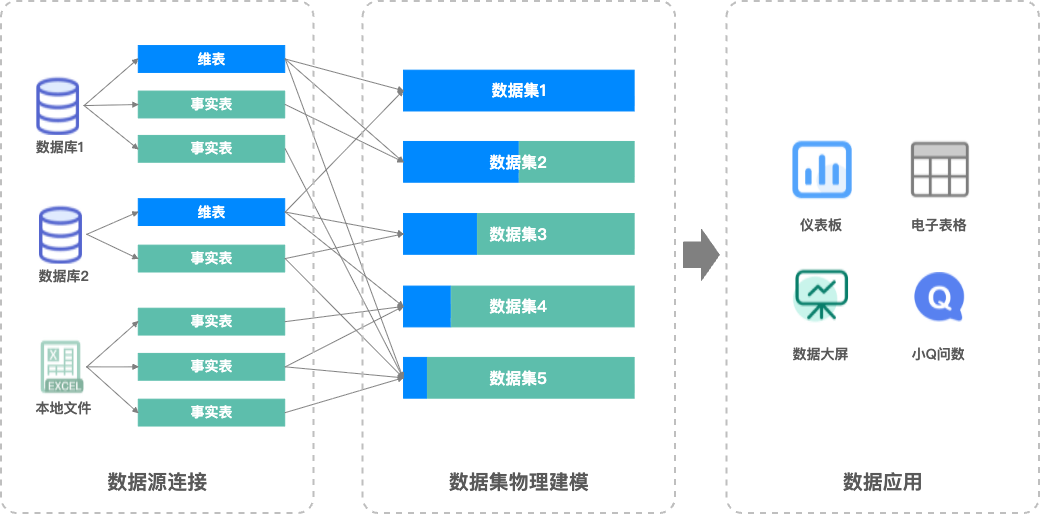
在Quick BI之前的数据集建模中,表与表之间的关联方式是普通的物理关联,即Left Join、Full Join等,关联完成后将会形成一张完整大宽表。由于普通物理关联可能存在数据膨胀的问题,为保证数据正确性,通常需要用户提前对数据情况有清晰的掌控,包括数据完整性、唯一性等。有时甚至需要对数据源表进行预处理,来避免数据膨胀的出现(如:对数据提前进行聚合)。综上,物理建模往往存在比较高的门槛和操作成本,也容易因数据膨胀导致数据错误。
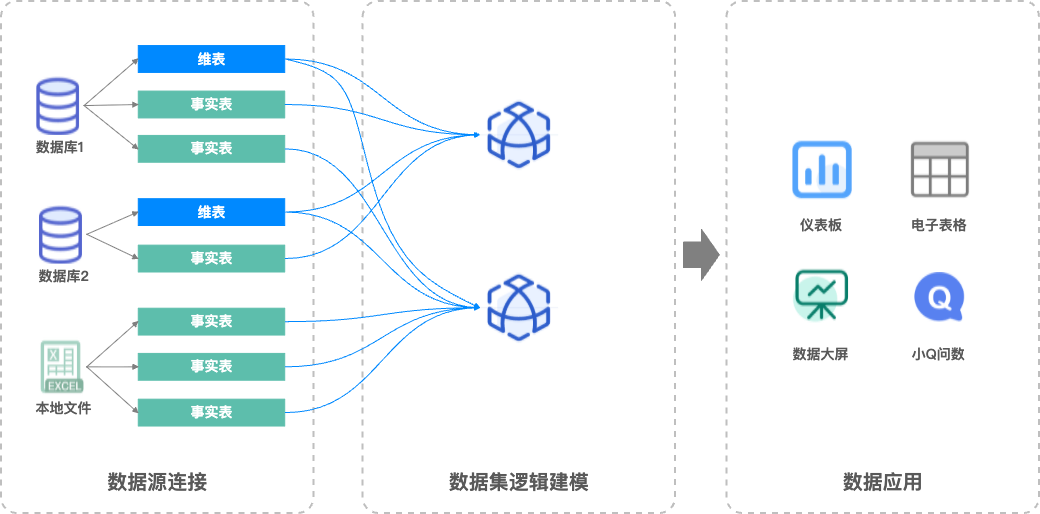
为此,Quick BI推出了全新的“关系模型”,在“物理建模”的基础上引入了“关系建模”的能力。关系模型可以极大地提高用户在处理复杂数据模型时的效率和灵活性。
关系模型价值
数据建模更简单:无需关注关联方式,只需要指定关联字段即可完成数据建模,关系模型将自动处理以保证数据完整性。
解决数据膨胀问题:当数据粒度无法匹配时,无需在建模时进行数据预处理,关系模型可自动解决数据膨胀问题,保证数据计算的正确性。
模型可支撑更多分析场景,无需进行多次建模:关系模型的可复用性强,无需根据独立的分析场景分别建模,可有效减少建模的数量,便于后续的维护和管理。
更多内容可参考:关系模型的优势。
物理模型和关系模型对比
物理模型 | 关系模型 |
|
|
存在问题:
| 解决方案:
|
关键概念
事实表和维表
事实表(Fact Table)和维表(Dimension Table)是数据建模中常用的术语,用于描述两种不同类型的表格。
事实表:存储可被量化的业务指标,包含了与业务过程相关的事实(Facts)数据。比如在线教育平台中的课程完成人数、测验平均分、学习时长等。
维表:存储描述性属性,包含了与业务过程相关的维度(Dimensions)数据。比如课程类型、学员年级、教师姓名、学习日期等。
事实表和维表之间通过某些共同的字段建立关联关系,这样可以在查询和分析数据时将维度和指标进行关联,实现多维分析。
举例说明
事实表
订单表
订单ID | 日期 | 产品ID | 数量 | 金额 |
1 | 2025-12-01 | A | 1 | 50 |
2 | 2025-12-01 | A | 2 | 100 |
3 | 2025-12-01 | B | 3 | 60 |
4 | 2025-12-02 | C | 1 | 10 |
库存记录
日期 | 产品ID | 库存数量 |
2025-12-01 | A | 10 |
2025-12-01 | B | 20 |
2025-12-01 | C | 5 |
2025-12-02 | C | 4 |
维度表
产品ID | 产品名称 | 类别 | 品牌 |
A | 清风牌面巾纸(一箱) | 生活用品 | 清风 |
B | 晨光文件夹(一套) | 文具用品 | 晨光 |
C | 上好佳鲜虾片(大包) | 食品 | 上好佳 |
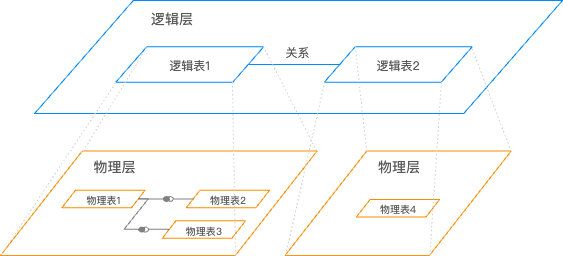
数据建模的层
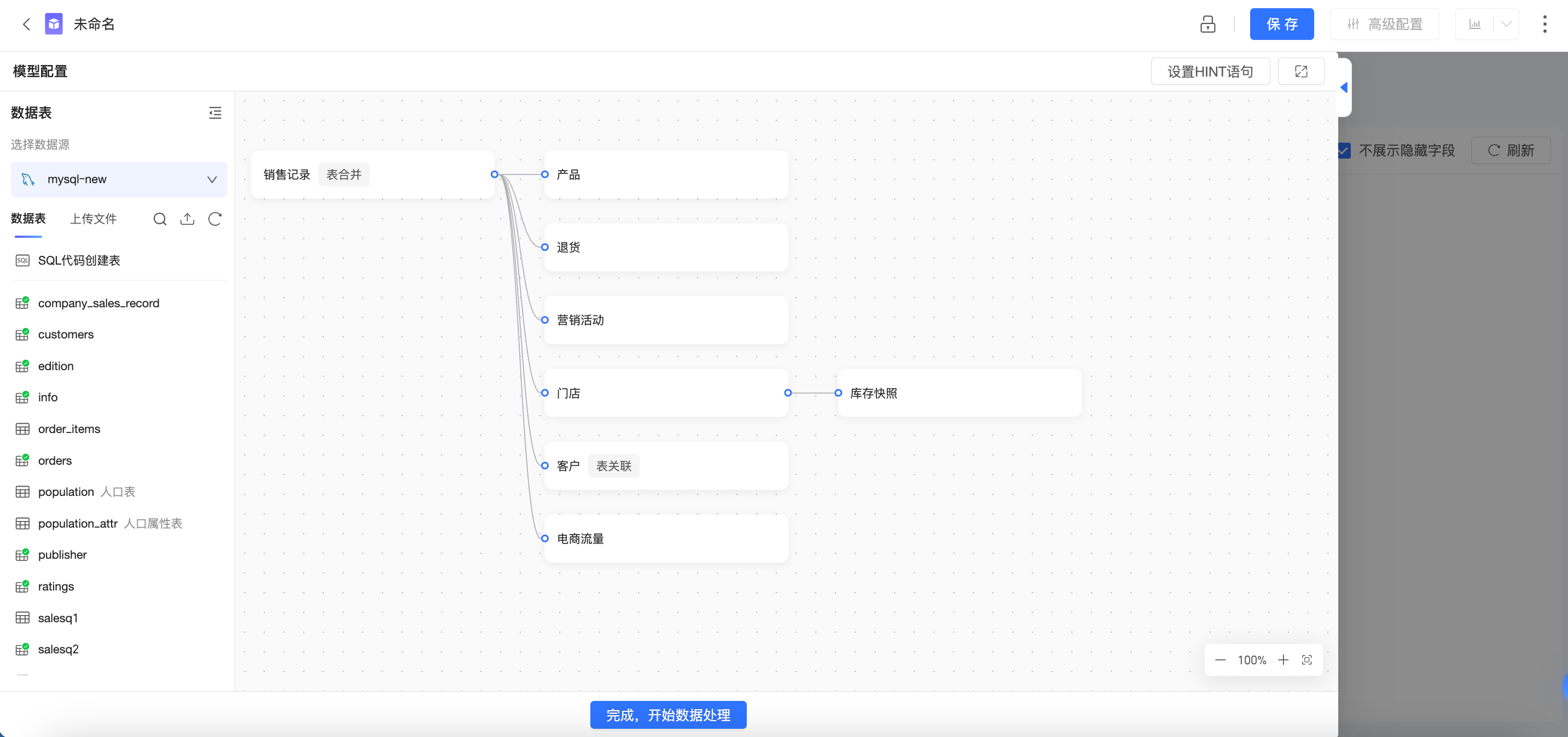
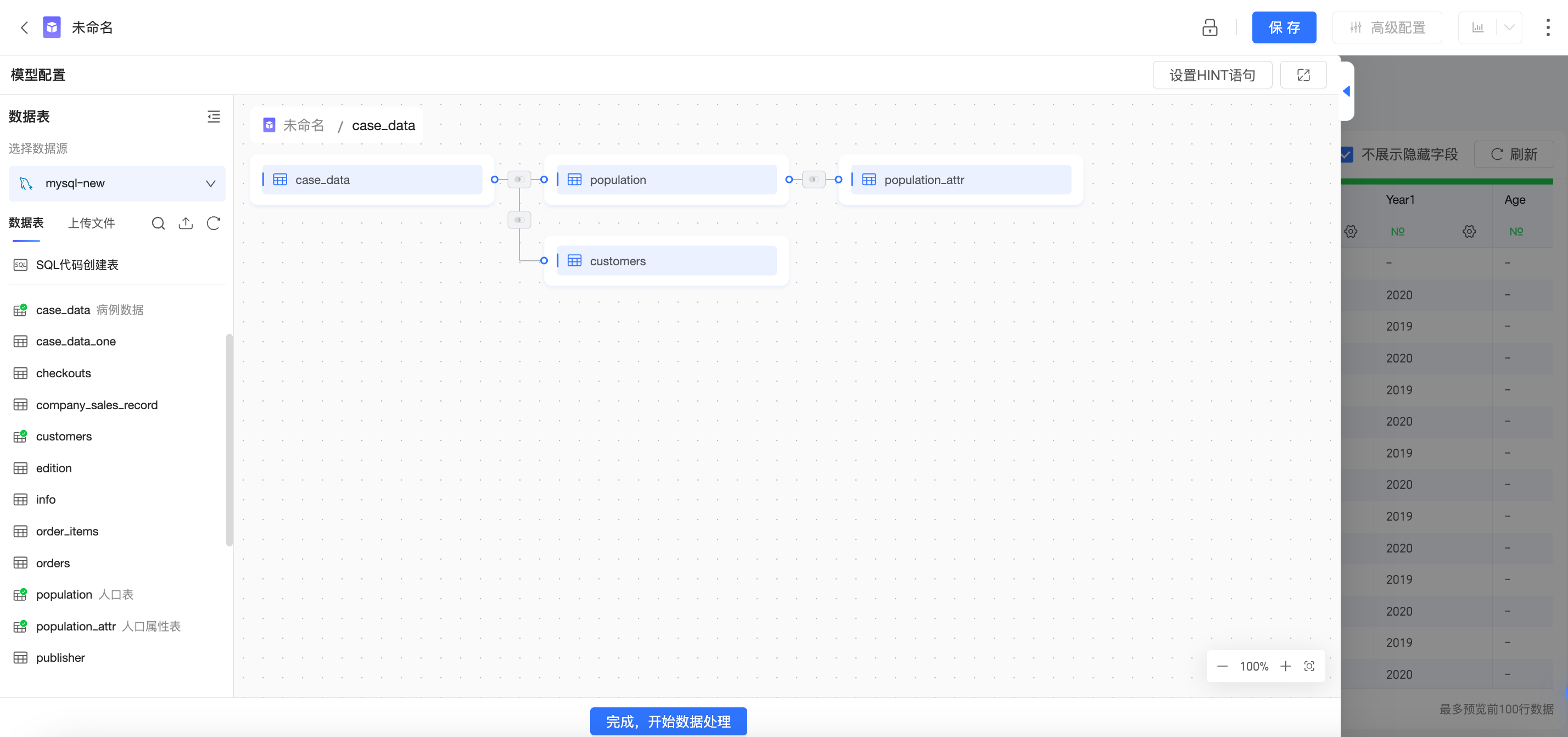
您在Quick BI中创建的每个数据集都有一个数据模型,可以将数据模型简单理解为一个数据表的关系图,告知Quick BI应该如何查询数据库表中的数据。
逻辑层和物理层
Quick BI的数据模型有2层:
逻辑层:
进入数据集的数据建模画布中,首先看到的是逻辑层,通常情况下,您只需要在逻辑层进行建模即可。
使用关系(关系线)来定义逻辑层中不同节点之间的关系,每个节点为一个逻辑表(每个逻辑表可以由单独的表、单独的自定义SQL构成,也可以是由多个表、自定义SQL进行物理关联、物理合并后的宽表构成)。
逻辑层的建模将构造出完整的数据模型。
物理层:
从逻辑层中任意一个逻辑表,可进入该逻辑表的物理画布中,也就是物理层。
物理层使用传统的物理关联、物理合并来定义多张物理表之间的关系,每一个节点是一张数据库表,或一段自定义SQL。
物理层的建模将形成一张固定的大宽表,并形成逻辑层中的一个逻辑节点。
逻辑层 | 物理层 |
关系线 | 维恩图 |
|
|
逻辑层和物理层之间的关系
逻辑层中,每个逻辑表之间通过“关系”进行建模,最终形成的是“关系模型”。逻辑层建模时不需要为关系指定具体的关联方式,最终也不会形成一张固定的大宽表。
每个逻辑表都对应一个单独的“物理建模”,您可以通过双击逻辑表,或者从右侧![]() 图标→“进入物理画布”进入物理层。物理层中,每个物理表之间可通过“关联”或“合并”进行建模,需要指定具体的关联方式,最终会形成一张完整的大宽表。
图标→“进入物理画布”进入物理层。物理层中,每个物理表之间可通过“关联”或“合并”进行建模,需要指定具体的关联方式,最终会形成一张完整的大宽表。
逻辑层中的每个逻辑表,在物理层中都有对应的物理建模(单表或多表的物理建模)。
在之前的Quick BI版本中,数据模型仅有一个物理层;在V6.1及更高版本中,数据模型具有逻辑层和物理层,也就是新增了“关系模型”的能力。
关联关系和数据匹配度
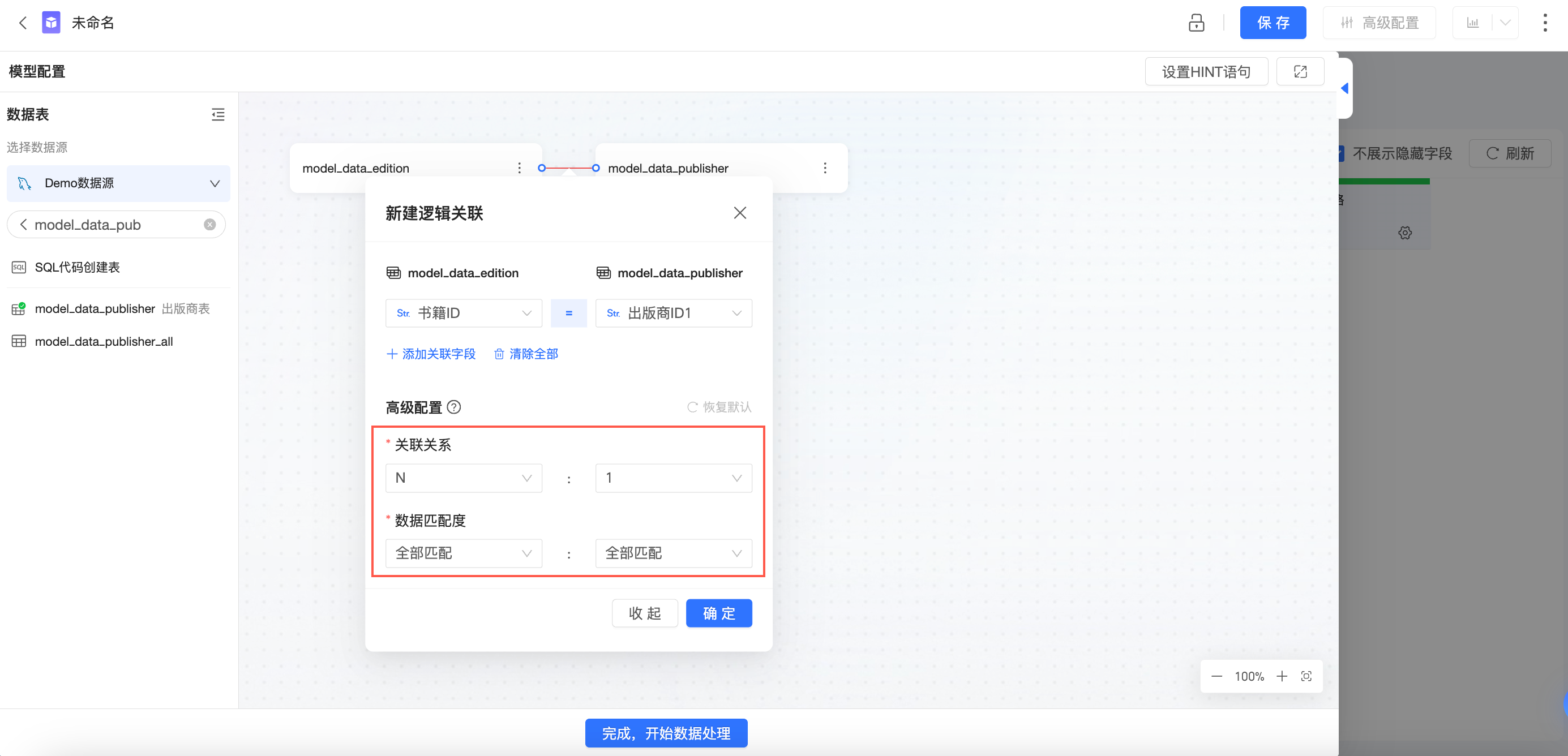
在配置关系时,点击“更多选项”,可配置数据的“关联关系”和“数据匹配度”。Quick BI会根据您的配置选择最合适的关联方式进行查询。若您能选择准确的配置,Quick BI在查询时将具有更好的性能。
当您不了解数据的具体分布,或者对“关联关系”、“数据匹配度”的概念不熟悉时,请不要修改默认配置,否则有可能会导致数据膨胀、数据丢失等错误。
只有当您对数据分布有清晰的把控,并且确定未来也不会有所变动时,您可以通过调整“关联关系”、“数据匹配度”的配置来优化关系模型的查询性能。
关联关系
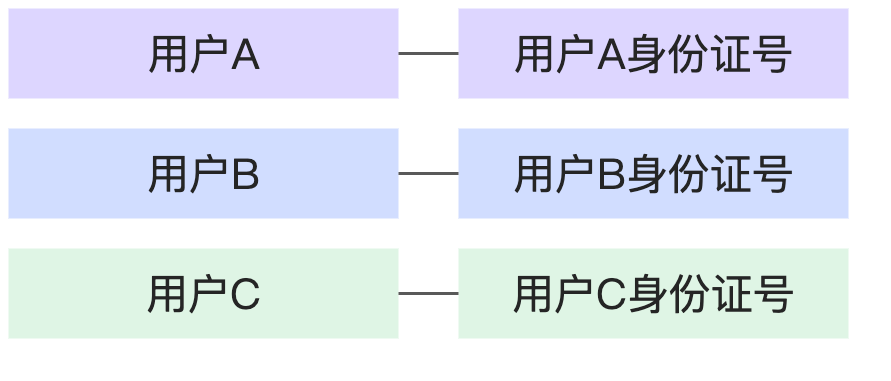
关联关系表示1个表中的关联键字段值是否是唯一的,以及2个表中的关联键值是否能唯一对应
1:字段值唯一
N:字段值不唯一
关联关系 | 举例 | 示意图 |
1:1 | 每个人都只有1个身份证号,每个身份证号也仅对应1个人。 |
|
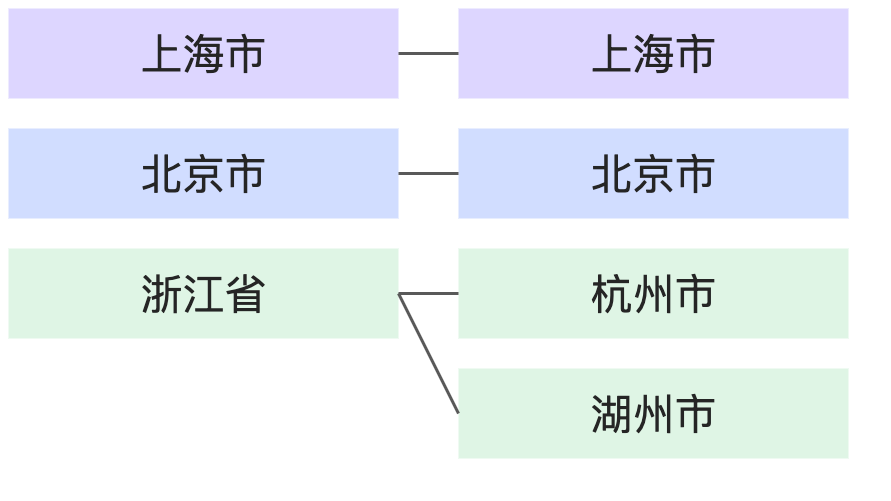
1:N | 每个省份对应N个城市,但每个城市只对应1个省份。 |
|
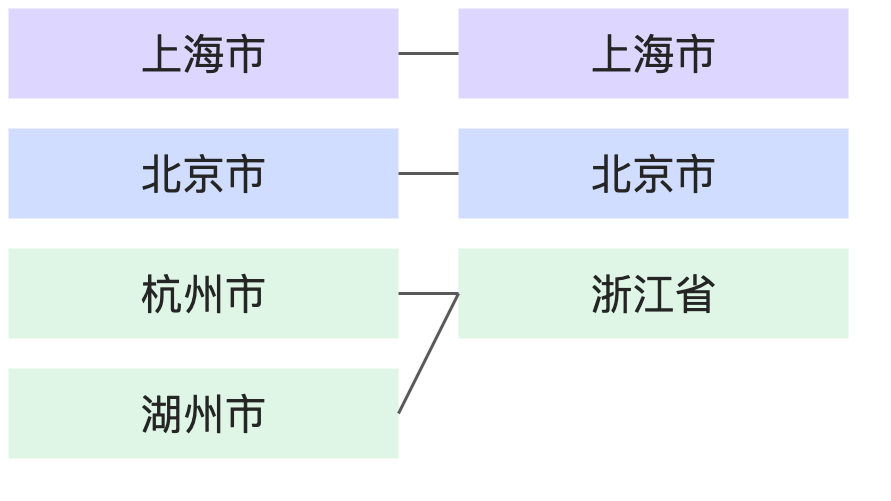
N:1 |
| |
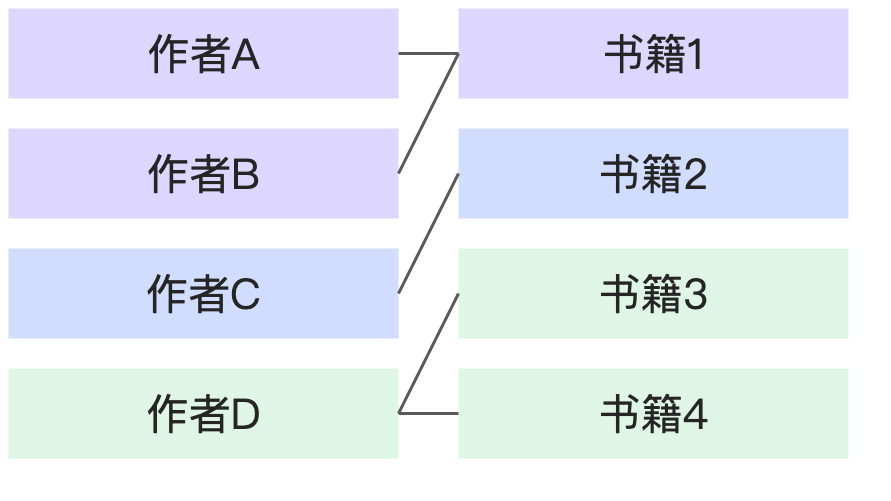
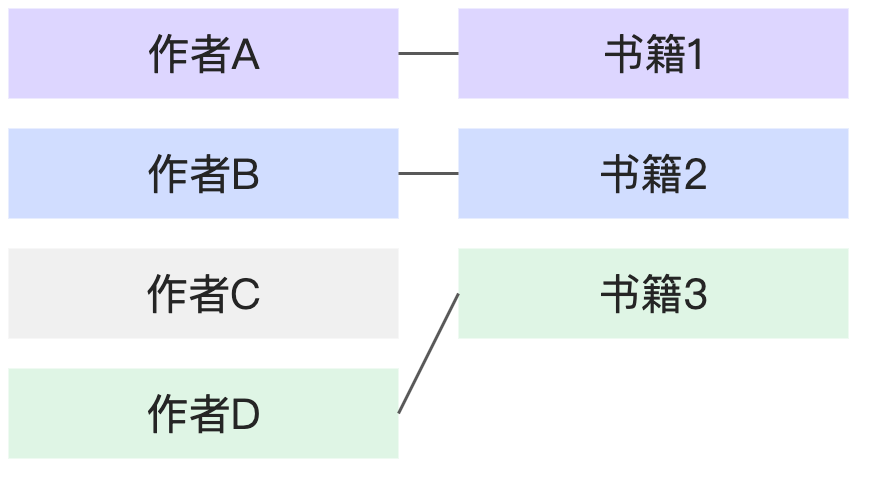
N:N | 1本书对应多个作者,1个作者也对应多本书。 |
|
数据匹配度
数据匹配度表示1个表中的关联键值是否能完整匹配到另一张表中,即:用于描述数据是否完整
部分匹配:存在字段值无法与另一张表匹配
完全匹配:所有字段值都能与另一张表匹配
数据匹配度 | 举例 | 示意图 |
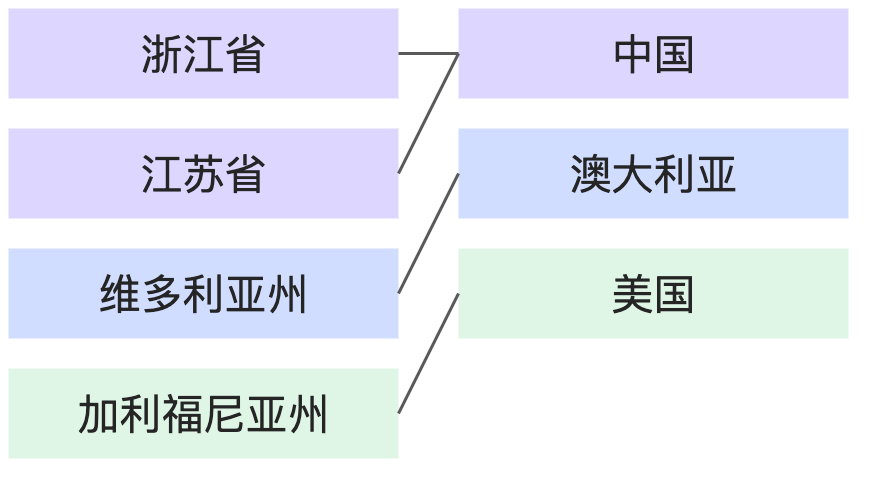
全部匹配:全部匹配 | 每个国家都有对应的省份,每个省份也都有对应的国家。 |
|
部分匹配:全部匹配 | 每本书都有对应的作者,但有的作者可能没有对应的书(还未发表作品)。 |
|
全部匹配:部分匹配 | ||
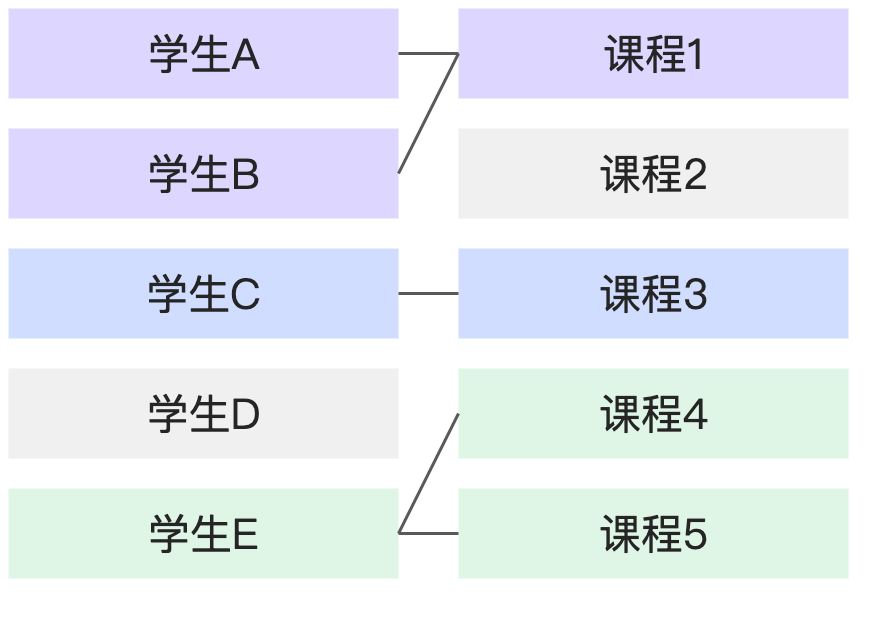
部分匹配:部分匹配 | 有的学生没有对应的课程(还未选课),有的课程也没有对应的学生(无人选课)。 |
|
关系模型适用场景
关系模型适用场景
场景一:业务用户简单数据建模
当用户对于SQL、数据库了解程度较浅时,推荐使用关系模型进行建模。
关系模型的配置比物理建模更简单,只需要指定两表之间的关联键(无需修改“高级配置”,建议直接使用默认值)。并且关系模型可以有效避免数据膨胀,无需业务用户关注数据完整性、唯一性等问题,有效降低建模门槛,提高建模准确性。
举例说明
HR部门为鼓励公司员工积极参与培训、课程等活动,制定了积分机制,可通过参加活动获取积分,积分可用来兑换礼品。数据库底层有2张表,分别为:
积分获取表:日期、员工ID、所在部门、参与活动名称、获取积分
积分兑换表:日期、员工ID、所在部门、兑换礼品名称、消耗积分
积分获取表和积分兑换表存在以下数据关系:
积分获取表 - 积分兑换表 | ||
关联关系 | N:N | 小王可以参与多个活动获取积分,也可以多次兑换礼品;在2张表中,“员工ID”都是不唯一的。 |
数据匹配度 | 部分:全部 | 小王获取了积分,但从未兑换礼品,因此“积分获取表”里有小王,“积分兑换表”里没有; 若某个员工从未获取过积分,自然也无法兑换礼品,因此不会出现“积分兑换表”有,但“积分获取表”里没有的情况。 |
当前,HR需要进行自助分析,查看每个员工的剩余积分有多少。很自然地,HR直接通过“员工ID”字段将2张表进行了物理关联。但由于“员工ID”字段在2张表中都不唯一,直接关联会出现数据膨胀的问题。物理建模的正确做法是将2张表分别按照“员工ID”聚合,再进行关联,但这需要一定的数据预处理能力。
如果HR直接使用“关系模型”进行建模,则可以直接使用“员工ID”进行关联,在实际计算中,Quick BI会自动进行数据的聚合处理,保证数据的正确性。
更多计算细节可参考:关系模型如何工作?
场景二:多分析场景下,关系模型提升数据集可复用性
当底层数据表数量相对较多时,IT用户可以直接将所有有关系的表拖入逻辑画布中,构造一份完整的关系模型。业务用户在使用时,只需要选择需要的字段即可。通过这种方式,可以有效避免IT针对不同分析场景构造不同关联大宽表,导致数据集数量堆积,难以维护和管理的问题。
在该场景下,建议IT用户根据数据特性,对“关联关系”、“数据匹配度”进行准确调整,从而提升数据查询的性能,降低复杂建模对性能造成的影响。
举例说明
还是以HR部门的积分获取、积分兑换场景举例:
积分获取表:日期、员工ID、所在部门、参与活动名称、获取积分
积分兑换表:日期、员工ID、所在部门、兑换礼品名称、消耗积分
与上一个例子不同的是,该公司要求中心化的IT团队为所有分析师准备好数据集,因此HR同学向IT提出以下3个场景的数据需求;若IT同学通过物理建模的方式构造数据集,则必须为3个场景准备3个数据集。
场景 | 具体分析描述 | 物理建模处理 |
场景1 | 分析每场活动的参与人数、积分获得情况 | 积分获取表(单表建模) |
场景2 | 分析每种礼品的兑换人数、兑换次数等 | 积分兑换表(单表建模) |
场景3 | 分析每个员工的剩余积分,展示剩余积分排行榜 | 积分获取表和积分兑换表,分别根据“员工ID”聚合后,再进行关联 |
由于“积分获取表”和“积分兑换表”的数据粒度不一致,直接进行物理关联会导致数据膨胀,无法保证数据正确性。但是在根据“员工ID”字段聚合后,又会丢失“参与活动名称”、“兑换礼品名称”等信息,无法实现“场景1”、“场景2”的分析。因此,在使用物理建模时,IT必须为HR准备3份数据集,以完成3个场景的分析。
但如果IT使用的是关系模型,则直接准备1份数据集即可,Quick BI会根据具体分析的字段自动选择合适的计算方式,以保证数据的正确性。
场景 | 具体分析描述 | 关系建模处理 | 拖入字段 | 关系模型处理 |
场景1 | 分析每场活动的参与人数、积分获得情况 | 关联键:员工ID N:N 部分:全部 | 维度:参与活动名称 度量:员工ID(去重计数)、获取积分(求和) | 单表查询 |
场景2 | 分析每种礼品的兑换人数、兑换次数等 | 维度:兑换礼品名称 度量:员工ID(去重计数)、消耗积分(求和) | 单表查询 | |
场景3 | 分析每个员工的剩余积分,展示剩余积分排行榜 | 维度:员工ID 度量:SUM(获取积分) - SUM(消耗积分) | 聚合后关联 |
更多计算细节可参考:关系模型如何工作?
关系模型使用限制
性能限制
关系模型为避免数据膨胀,会对查询SQL进行特殊的处理,这会使SQL更加复杂。相比于传统的物理关联,关系模型产生的查询SQL会有更多的子查询和嵌套层数,一定程度上将会降低查询性能。并且,性能的表现与数据量和模型复杂程度有较大关系,随着数据量变大以及模型复杂度变高,关系模型与物理模型之间的性能差距也会更加明显。
若您对数据分布情况十分了解,可通过优化“关联关系”和“数据匹配度”来优化查询性能。一般情况下,各个配置的性能表现如下:
关联关系:1:1 > 1:N = N:1 > N:N
数据匹配度:全部:全部 > 全部:部分 = 部分:全部 > 部分:部分
当您不了解数据的具体分布,或者对“关联关系”、“数据匹配度”的概念不熟悉时,请不要修改默认配置,否则有可能会导致数据膨胀、数据丢失等错误。
只有当您对数据分布有清晰的把控,并且确定未来也不会有所变动时,您可以通过调整“关联关系”、“数据匹配度”的配置来优化关系模型的查询性能。
尽管如此,若您具有较好的数据处理能力,并且对查询性能要求非常高时,我们仍然建议您继续使用传统的物理建模方式,从而避免因关系模型复杂逻辑引入的额外计算。
数据量限制
当度量来自于多个逻辑表时,QBI将以逻辑表为单位分别进行查询计算,之后再将多个结果关联,取得最终的结果。为保障查询效率和Quick BI整体服务的稳定性,每次查询将有1万行的数据量限制。具体细节可参考关系模型如何工作?
此处的1万行限制可以简单理解为:聚合后的数据限制1万行。比如:关联字段为“区域”,查询维度为“产品类型”,则在对逻辑表进行查询时,会按照“区域”和“产品类型”字段进行聚合,聚合后的结果取前1万行。
受关系模型计算复杂度的影响,无法通过分页的方式取到1万行之后的数据。若您需要执行更加“明细”粒度的数据查询,或者您的查询维度枚举值过多时,关系模型的处理可能会导致数据不完整。该场景下,我们建议您继续使用传统的物理关联进行建模。
功能限制
关系模型推出之后,数据集底层的处理和计算将有非常大的改造和优化,以下能力将无法兼容老版本:
资源包不支持将高版本数据集导入到低版本中,否则将报错。建议您先将目标环境升级到V6.1及之后版本,再进行资源包的导入。
旧版数据集详情查询接口“QueryDatasetDetailInfo”将无法继续兼容关系模型数据集,建议您切换为新版接口:QueryDatasetInfo
Quick BI在V6.1推出关系模型初版,以下功能仅支持单逻辑表数据集,对于多逻辑表数据集的支持将在后续版本中逐步补充:
数据准备
复杂过滤条件不允许选择来自于多个逻辑表的字段,以下功能点将受到限制:
行级权限:包括条件组合授权、用户标签关联授权
仪表板 - 复合查询控件
监控告警 - 告警规则
抽取加速限制:当查询涉及的逻辑表数量超过3个时,系统将不使用加速引擎,而是直接通过直连方式执行查询。