本文介绍什么是健康检查、以及健康检查的推荐配置和参数详解。
背景信息
K8s中的健康检查主要分为两种:
Liveness:存活检测,负责判断容器是否需要重启。
Readiness:就绪检测,负责判断容器是否需要承接流量。
核心参数:
检查方式:TCP/HTTP/CMD。
延迟时间:容器启动后,多久开始检测。
检查周期:决定检查的频率,灵敏度相关。
超时时间:检查的超时等待时间。
成功阈值:探针在失败后,被视为成功的最小连续成功数。Liveness必须设置为1。
失败阈值:判定总体失败的连续失败数。
推荐配置(快速设置版)
参数 | 说明 |
Liveness | 使用TCP方式,延迟时间尽量贴近应用启动时间,成功阈值为1,失败阈值为3。 |
Readiness | 使用HTTP方式,延迟时间需大于应用启动时间,成功阈值为1,失败阈值为1。 |
超时时间 | 通常采用默认1秒即可,如果访问的接口预期内大于1秒,则适当延长。 |
检查周期 | 通常用于控制探测的灵敏度,理论上如果高频率的检查不会对业务有实质影响,则检查周期越短越好。但是,如果Liveness的检查周期太短,可能会让业务容器更容易重启。 因此,可以根据计算公式(节点最大可容忍故障时间/3),来确定Liveness的检查周期。例如,单个故障实例最大可容忍30秒内不重启,则检查周期设置为10秒。因此,Readiness检查周期可设置为1秒,Liveness检查周期根据实际情况设置,如果没有特殊需求,可保持默认的30秒。 |
参数详解(进阶版)
延迟时间
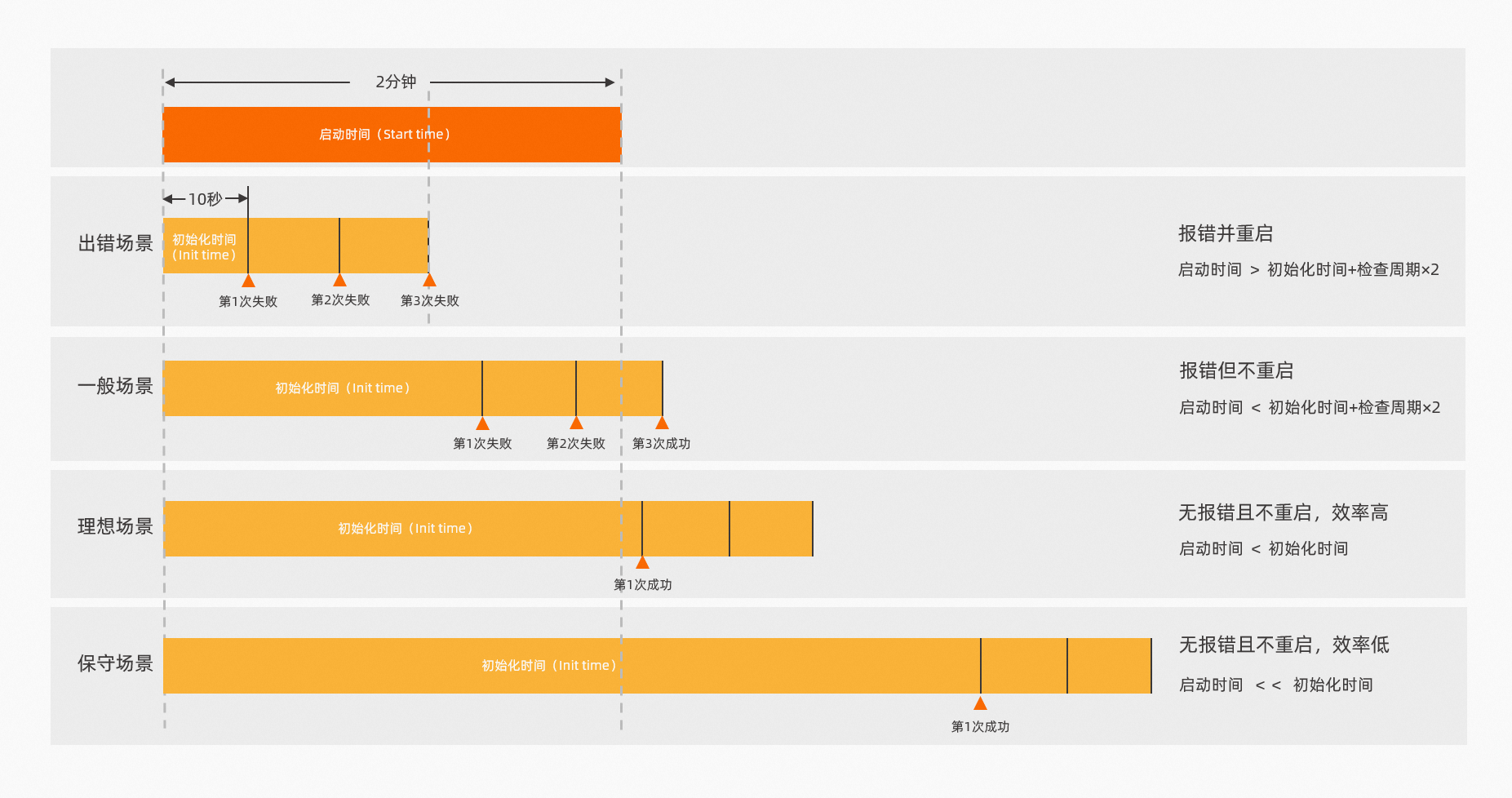
对于Livness的配置,需要重点理解参数“延迟时间”,其作用是帮助健康检查探针在合适的时候去探测业务容器的状态。如果Livness健康检查在不合适的时候去探测(延迟时间过短),会导致不断重启这一严重后果。
例如,一个Java应用启动可能需要耗时2分钟,如果全部按照默认配置,即延迟时间为10秒,检查周期为30秒,失败阈值为3,该应用将永远不可能启动成功。因为在上述设置中,Livness探针的三次健康检查全部是在应用启动完毕之前完成的,而应用启动完毕之前进行健康探测,持续失败就是预期中的结果。所以,该应用必然会不断重启。
因此,当初次部署应用时,如果无法确定应用的启动时间,可以尽量将延迟时间调长一点(例如5分钟),等应用成功启动后,再根据业务日志确定大致的启动耗时来修正延迟时间。需要注意的是,延迟时间过长也存在弊端,因为可能会让整个发布时间过长。
TCP与HTTP方式的选择
Liveness另一个容易踩坑的点是检查方式,用户需要为Readiness与Liveness配置不同的检查方式。但是,许多用户为了省事,将Readiness与Liveness设置成相同的检查,其实这是非常危险的行为。因为Liveness与Readiness是两种完全不同的探针,有着完全不同的作用。有时候业务由于流量拥塞导致不可用,只需摘除当前实例的流量,无需重启容器。当前请求被正常处理完成后,就可以重新负载流量并接收请求。但是,如果此时重启容器,可能会产生以下影响:
当前已有请求无法被顺利处理。
由于当前实例重启,可能会导致更长的时间无法负载流量,甚至出现雪崩。
例如,对于Java应用,Spring Boot框架提供了内置的健康检查。该健康检查会检测多个组件的情况,例如与Redis、Nacos等组件连接与心跳是否正常,并判断是否需要重启应用。由于网络抖动以及相关组件服务的可用性无法完全确定,这类异常无法成为当前应用是否需要重启的判断依据。
因此,为了减少因下游链路的抖动造成预期外的实例重启,必须区分Liveness与Readiness。如果不方便单独实现一个接口来检查应用自身的情况,可以通过Liveness采用TCP、Readiness采用HTTP的方式探测。重启这一操作需要谨慎对待,因此检测容错率更高的TCP方式更适合Liveness。HTTP方式的检测更容易反映业务的真实处理情况,更适合Readiness这一处理流量的检测。
例如一个端口可以通过TCP建立连接,但是不一定能够通过HTTP请求返回预期返回码(200)。
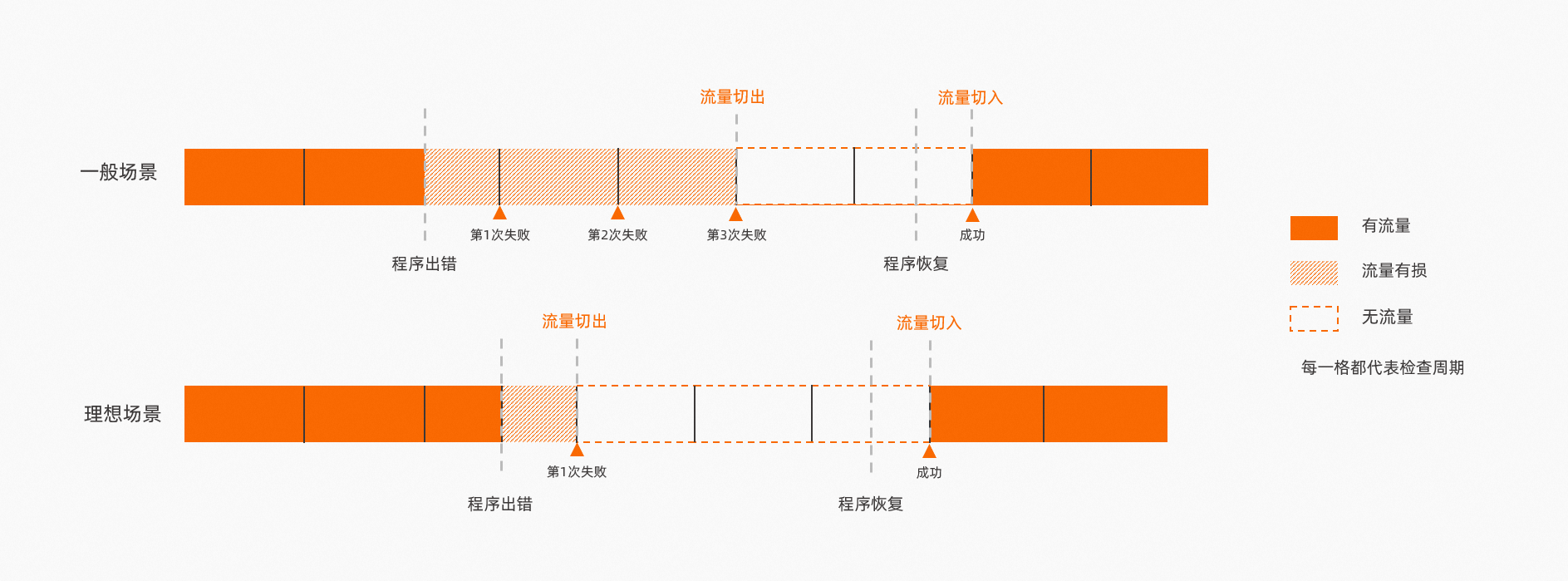
失败阈值与成功阈值
对于Liveness而言,其实只有一个动作,即失败重启。因此,成功阈值固定为1,且不可修改(由于成功没有显式动作,所以成功阈值大于1也没有意义)。而失败阈值默认为3,即连续失败三次,会认为真正失败,并开始重启容器。
对于Readiness而言,其实有两种动作,成功则接入流量,失败则切出流量。因此,为保证可用性,成功阈值与失败阈值都推荐设置为1,即当出现检测失败时立即切出流量,从而尽可能短时间内避免流量有损,而当检测成功(即应用已经做好接收流量的准备)后立即切入流量。但是,快速切流可能导致剩余实例平均网络负载进一步增加,因此建议配合指标弹性一起使用。
此处流量特指使用SLB接入流量的SAE应用,而微服务内部调用的流量控制属于另一套体系。