数据集管理主要是管理要进行质检的文本/语音数据集。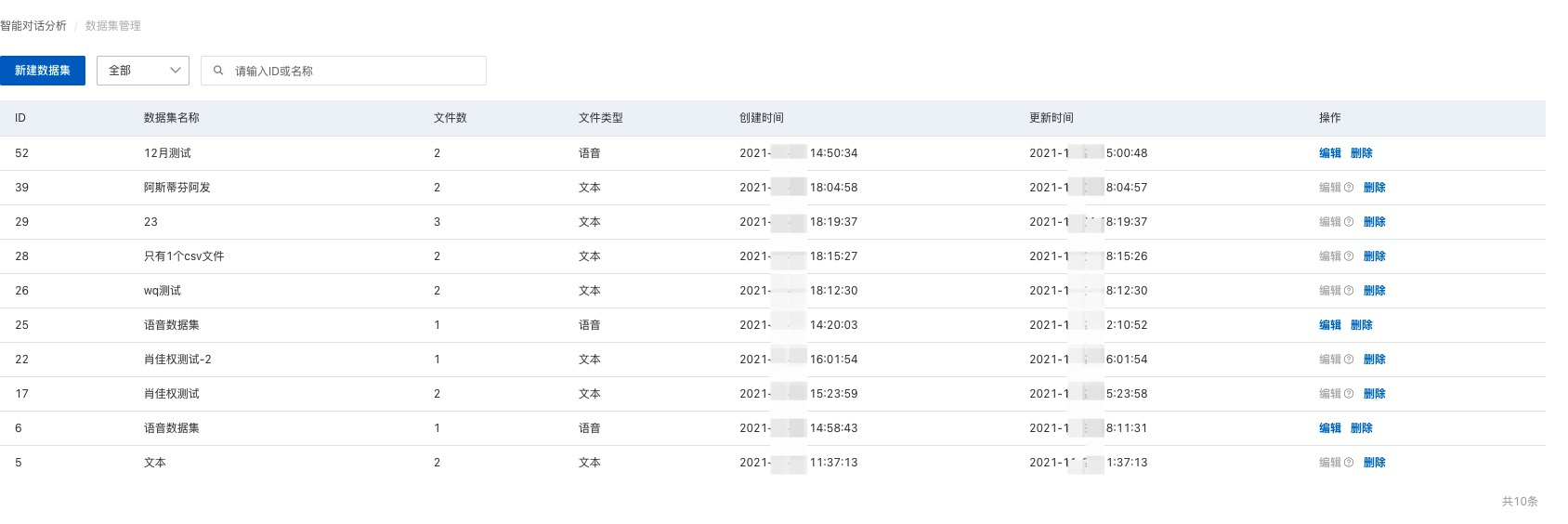
新建数据集
点击数据集列表左上方的 新建数据集 按钮即可呼出弹出窗上传数据集。
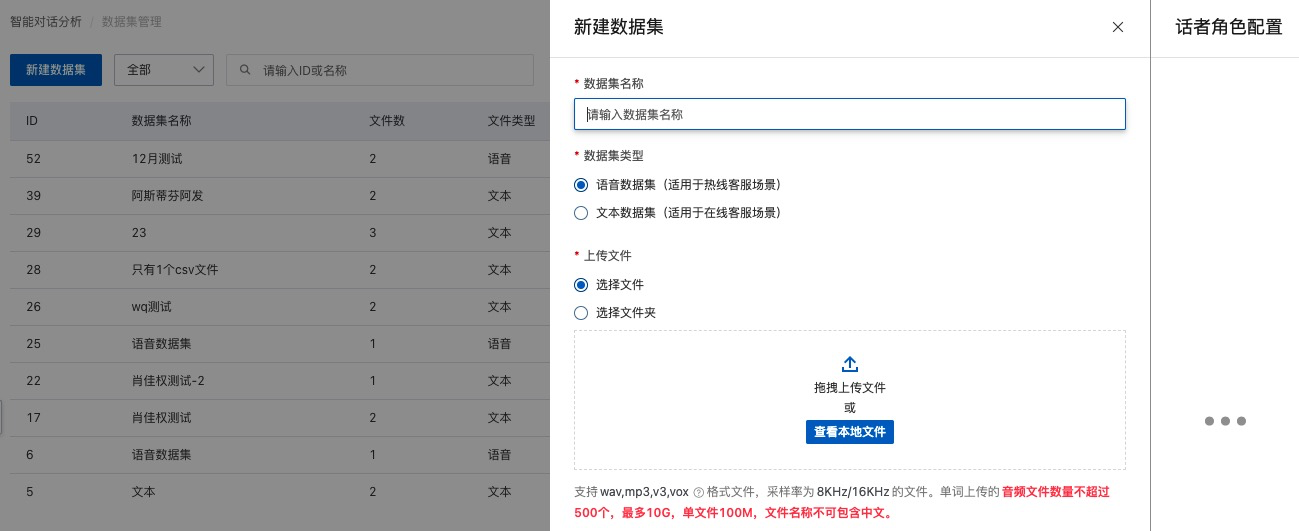
数据集名称:表示当前创建的数据集名称
数据集类型:系统默认支持语音和文本两种数据集,分别适用于热线客服场景和在线客服场景的质检。
上传文件:上传文件也分为选择文件和选择文件夹,分别对应单文件上传和批量上传。
注:
语音数据集仅支持wav,mp3,v3,vox格式文件上传,要求单次上传的音频文件数量不超过500个,最多10G,单文件100M,文件名称不可包含中文。同时对于某些不符合标准的音频,上传时会做自动转码处理,比如将采样率转为8000Hz。
文本数据集仅支持csv格式文件上传,要求每次上传的对话文件数量不超过10000个。
上传完毕后点击页面底部的 下一步 按钮,开始进行话者角色配置。
话者角色配置
系统会随机选取一个文件,如果是语音文件需要点击页面中的 开始音频转写 按钮,对该文件进行语音转文字,转写完毕后,需要根据对话文本进行话者角色配置。由于录音文件分为单轨录音和双轨录音,话者角色配置方式有所不同,下面会分别说明。
语音转文本时,系统会自动将录音分为两个对话角色,但是出于一些客观因素系统无法准确识别哪个角色为客服,所以需要您根据文本内容来手工设置,选出哪一方为客服,则另一方即为客户。准确的进行话者角色配置非常重要,因为我们进行质检分析时所用的规则,很多时候都有检测范围的限制(即一个规则只检测客服或者客户),如果话者角色配置是错误的,那么将对质检结果的准确性产生极大影响。
单轨录音的话者角色配置
单轨录音的话者角色配置,音频转写完成后,一侧为客户,一侧为客服;角色的判断方式:
根据关键词判断客服人员:根据实际业务场景,填写一个或多个客服开场时常说的关键词,匹配上这些关键词时,则认为当前角色为客服,另一侧即为客户;
选择合适的角色判断方式,点击 验证 按钮,对话框中的文本会发生变化,请您自行判断是否正确,如不正确,可以对关键词进行调整;对话者角色配置完毕后,点击页面底部的 完成创建 即可,此时该数据集内的所有文件,都将使用相同的角色判断方式。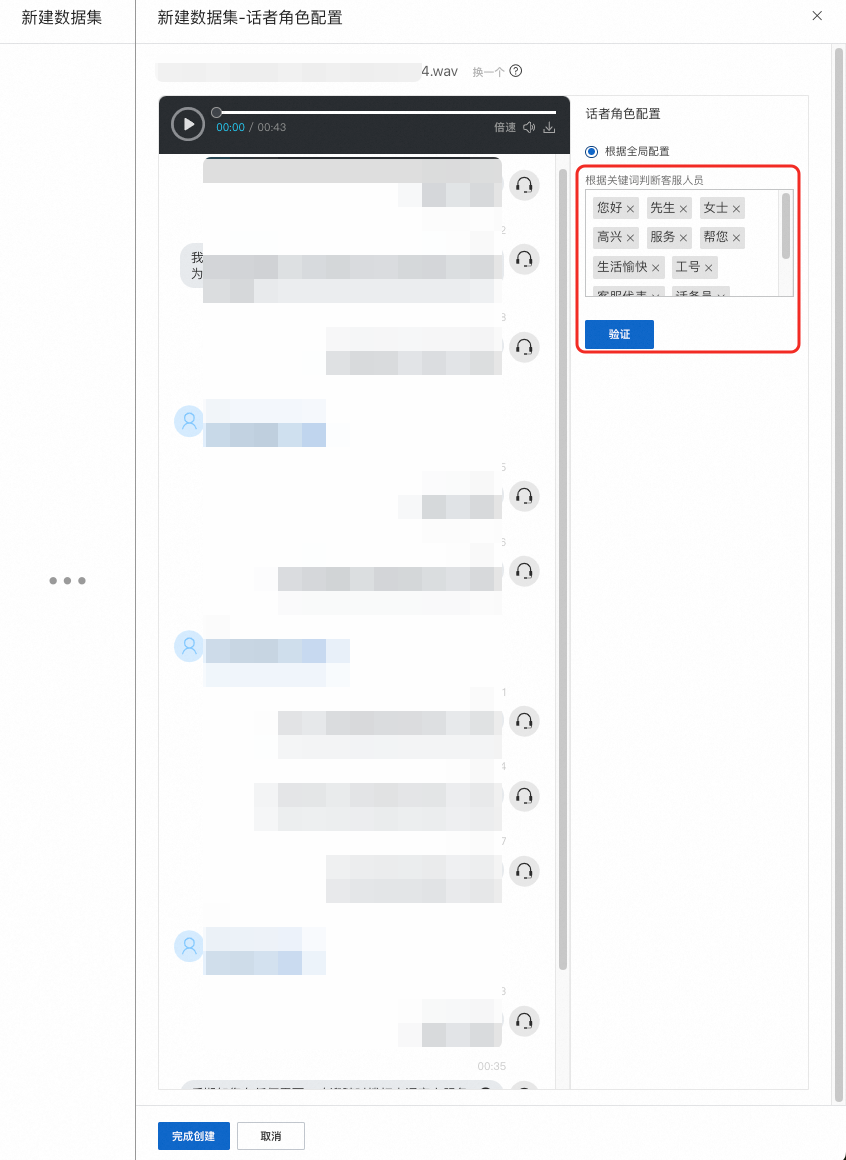
需要强调的是,单轨录音的话者角色分离无法保证100%正确,建议您将呼叫中心生成的录音文件设置为 双轨录音,这样客户一个轨,客服一个轨,可以从根源上避免出现话者角色分离错误的情况。
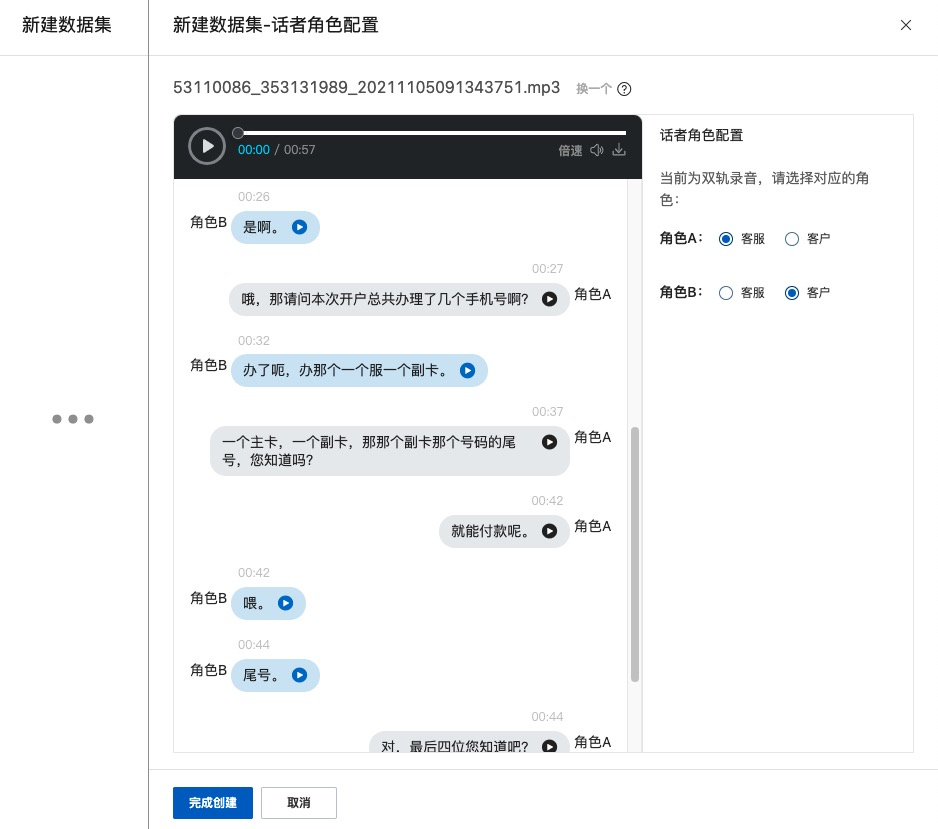
双轨录音的话者角色配置
选择无误后,点击页面底部的 完成创建 即可,此时该数据集内的所有文件,都将使用相同的角色判断方式。角色的判断方式分为两种:
根据全局关键词判断客服人员:根据实际业务场景,填写一个或多个客服开场时常说的关键词,匹配上这些关键词时,则认为当前角色为客服,另一侧即为客户;
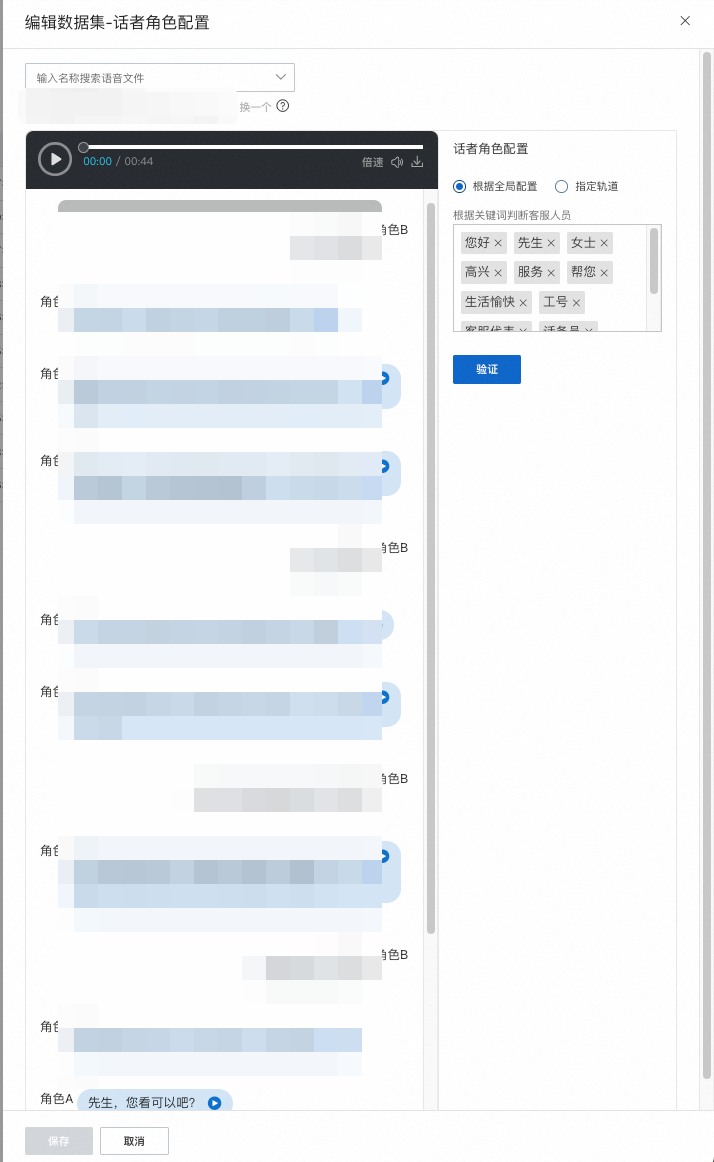
根据指定轨道来判断:根据对话文本,选择角色A的正确角色,角色B的角色会自动变化,