
本文主要介绍了如何使用CloudLens for SLS对采集延迟问题进行分析和定位,并针对一些场景问题提供了告警语句的配置建议。
采集延迟场景
采集延迟是指本地实时日志在较长时间后才被发送至 SLS,可能导致监控延迟、数据不全,影响问题发现和统计告警。常见原因包括:
SLS服务端写入限流(Quota超限)。
网络质量问题,导致LoongCollector发送延迟(网络异常)。
数据产生速率过大,超过LoongCollector处理能力(计算资源不够)。
其他原因,如原始数据量非常大、LoongCollector频繁重启、使用了NAS类网络存储导致文件发现缓慢等。
通过CloudLens for SLS的LoongCollector文件采集监控,查看文件采集延迟概览报表,若存在采集延迟,会标出延迟的量。
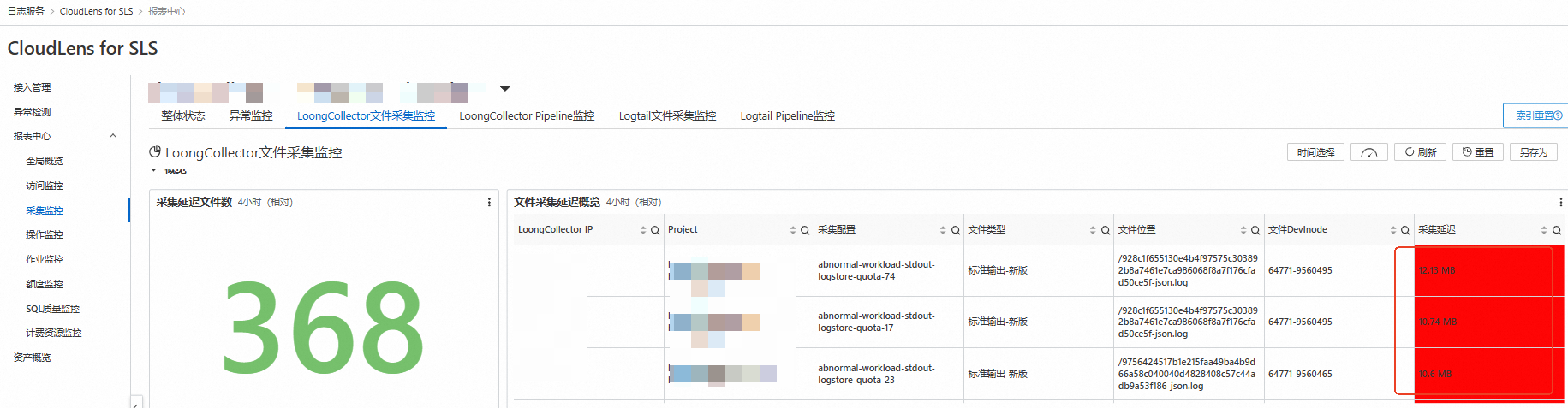
场景一:SLS服务端写入限流导致采集延迟
问题现象
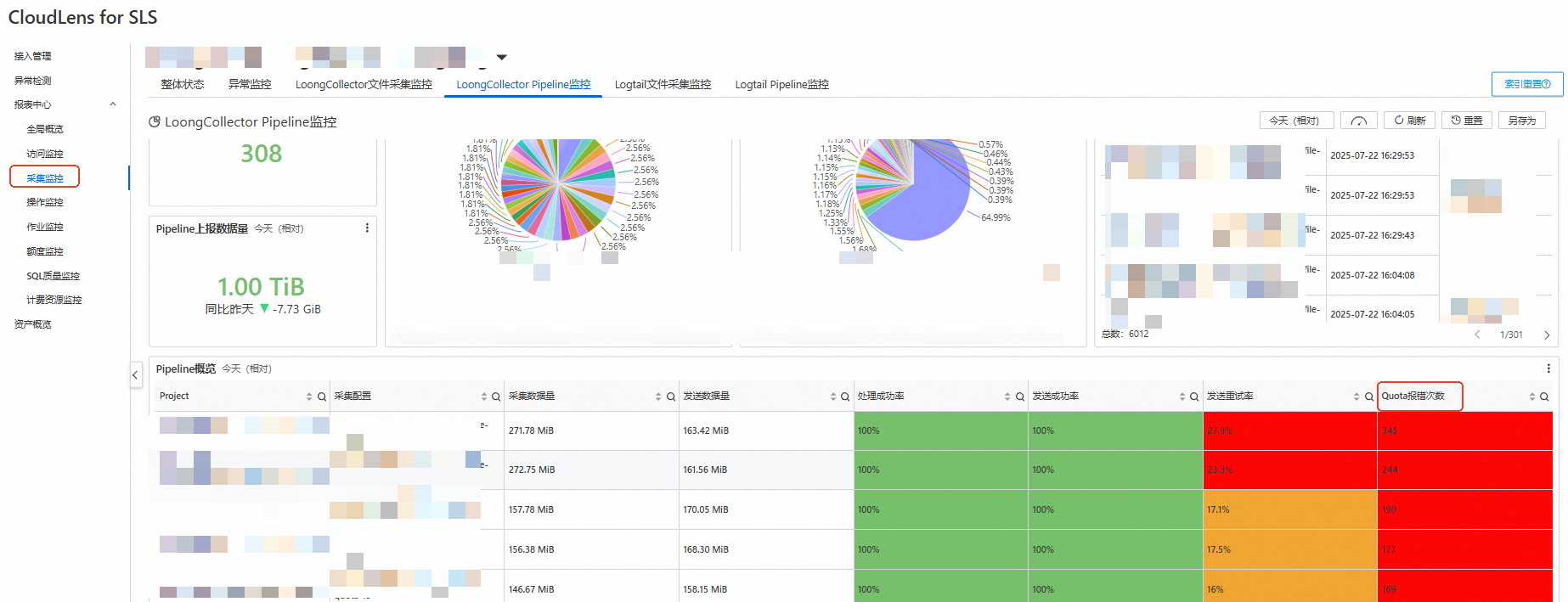
在CloudLens for SLS的LoongCollector Pipeline监控,查看Pipeline概览报表,最后一列为Quota报错次数,表示在查询时间范围内,LoongCollector写入SLS时因为超过服务端限制而失败的次数。
如果存在LoongCollector被限流的问题,Quota报错次数会显示出来,并标红高亮警示。
问题原因
日志服务包含Project、Logstore、Shard等资源概念,为保证云上多租户更可靠的QoS服务质量,每种资源会设置相关的资源流控及解决方案(即Quota),一旦超过资源流控限制,则会导致读写数据失败,请求异常等后果。
在LoongCollector采集数据场景,常见的Quota报错有两种:
WriteQuotaExceed:说明该Project在一定时间内,写入的数据总量或写入的次数过大,导致超过Quota限制的请求失败了。该报错发生并不一定是单个采集配置导致,而是多个采集配置、多个Logstore共同造成。
ShardWriteQuotaExceed:说明单个Logstore在一定时间内,写入的数据总量或次数过大,导致超过Quota限制的请求失败了。Logstore的写入能力由Shard决定,具体的说明请参见管理Shard。
LoongCollector采集的数据因Quota超限失败时,会不断重试直到发送成功,但是发送的数据总量不会超过Quota允许的范围,所以会导致积压的待重试的请求越来越多,每一次请求都需要等待很久才能上报成功,造成采集延迟。
Cloudlens for SLS中LoongCollector Pipeline监控下方的Pipeline发送状态详情,可以查看具体是Project写入超限,还是Logstore Shard写入超限。
解决方案
如果是Project写入Quota超限,参考管理Shard的管理资源配额,调整project写入流量上限和project写入次数上限两项参数,提交配额。
每次申请可以将当前配额提高50%左右。
如果是Logstore的shard写入超限,参考管理Shard的分裂Shard和自动分裂Shard,调整Logstore的Shard数。
每个Shard支持5MB/s或500次/s的数据写入、10MB/s或100次/s的数据读取。此限制非硬性限制,超出限制时,日志服务会尽可能提供服务,但是不保证服务质量。
可以通过语句
((__topic__: loongcollector_metric and category: pipeline and source_ip:* and labels.project: * and labels.logstore: *))| select "labels.project" as project, "labels.logstore" as logstore, round(sum(flusher_in_size_bytes)/1024.0/1024.0, 2) as output_size_bytes group by project, logstore order by output_size_bytes desc limit all在对应Project的运行日志Logstore中计算不同目标Logstore的原始数据写入量,取其中的最大值除以5并增加20%的缓冲,得到预期的Shard数。
告警配置建议
Quota超限是较为严重的问题,建议创建告警监控规则。
可以每10分钟检查一次自监控数据中是否存在quota报错的信息,并对出现报错的Project/Logstore进行对应处理,避免数据上报风险。
监控日志类型:运行日志
筛选条件:flusher_project_quota_error_total或flusher_shard_write_quota_error_total字段的值大于0,这两个字段分别对应Project Quota超限次数和Logstore shard Quota超限次数。
信息展示:展示一定时间段内出现Quota报错的Project(labels.project)、Logstore(labels.logstore)、采集配置(labels.pipeline_name)。
查询间隔:10分钟。告警使用的
__topic__为loongcollector_metric的自监控数据,上报间隔为10分钟一次。参考语句:
__topic__: loongcollector_metric and (flusher_project_quota_error_total>0 or flusher_shard_write_quota_error_total>0) | select "labels.project" as project, "labels.logstore" as logstore, split_part("labels.pipeline_name", '$', 2) as pipeline_name, sum(flusher_project_quota_error_total) as project_quota_error_total, sum(flusher_shard_write_quota_error_total) as shard_write_quota_error_total group by project, logstore, pipeline_name having project_quota_error_total>0 or shard_write_quota_error_total>0 order by pipeline_name limit all场景二:网络质量问题,导致LoongCollector发送延迟
问题现象
在CloudLens for SLS的LoongCollector Pipeline监控,拉到最下方的Pipeline发送状态详情,查看发送请求重试率,Project写入Quota超限次数和Logstore Shard写入超限次数都为0,则表示没有Quota相关的报错,发送请求重试率有数据,则表示重试率较高且说明网络质量存在问题,影响了数据及时上报,导致采集延迟。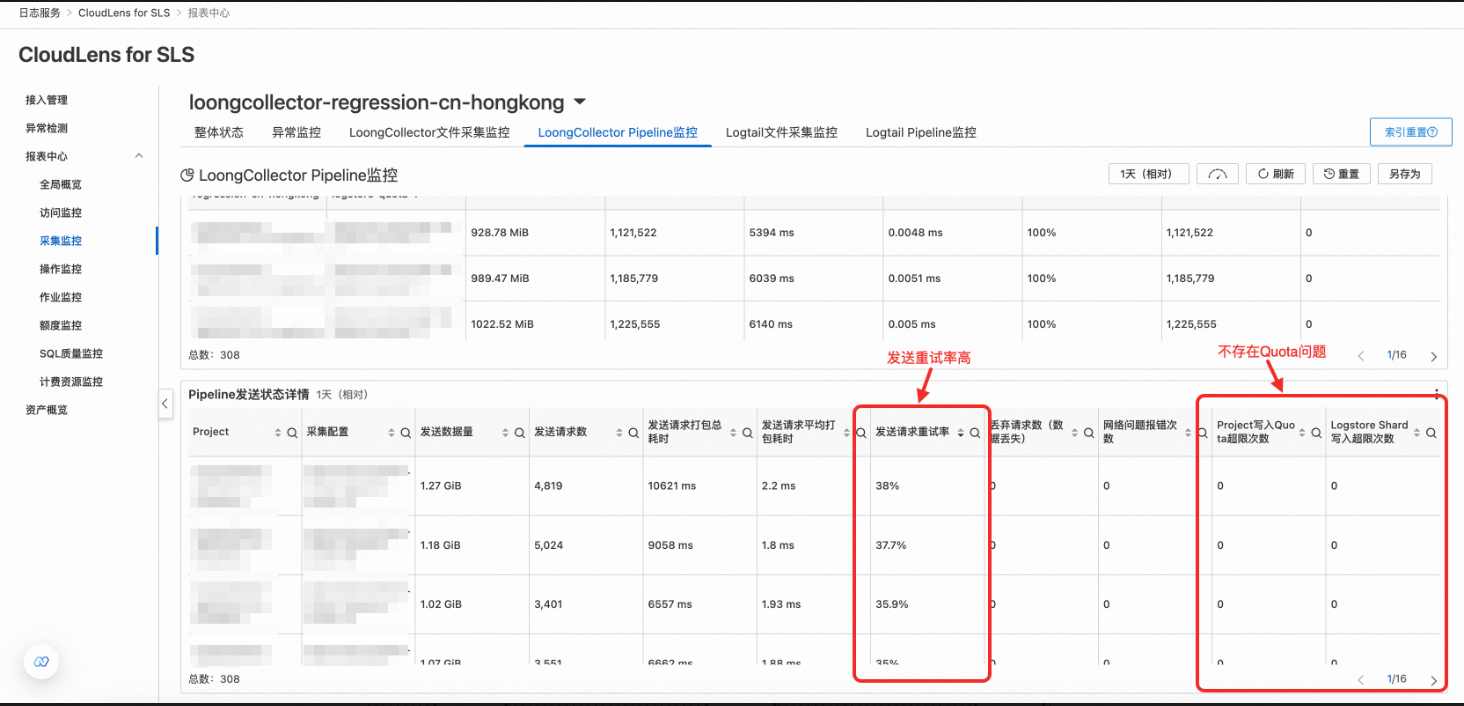
问题原因
LoongCollector内部,数据读取、处理、发送是一条流水线,从文件中读取数据后,依次将数据写入处理队列、发送队列。如果因网络质量不佳、数据量过大或其他原因,LoongCollector的发送能力受限,数据无法及时发送到SLS,则会导致SLS查询数据存在延时,还会导致发送队列数据堆积,进一步反压处理队列、读取线程,使采集延迟更高。

解决方案
告警配置建议
针对发送重试率报错配置告警。
监控日志类型:运行日志
筛选条件:筛选LoongCollector采集配置的指标。
信息展示:展示一定时间段内出现Quota报错的Project、Logstore、采集配置。
查询间隔:10分钟。指标的上报间隔为10分钟,如果10分钟内重试率较高,说明LoongCollector在此期间可能发生采集延迟。
参考语句:
((__topic__: loongcollector_metric and category: pipeline and source_ip:* and labels.pipeline_name:* and labels.project: *))| select "labels.project" as project, split_part("labels.pipeline_name", '$', 2) as pipeline_name, (sum(flusher_send_done_total)-sum(flusher_success_total))*1.0/(sum(flusher_send_done_total))as "发送重试率" group by project, pipeline_name having "发送重试率">0.1 and "发送重试率"<=1 order by "发送重试率" desc limit all 场景三:数据产生速率过大,超过LoongCollector处理能力
问题现象
首先需确认SLS服务端写入未超限,同时LoongCollector发送不存在瓶颈。
查看采集瓶颈
打开CloudLens for SLS的异常监控,查看采集异常监控中的全量错误信息,筛选告警类型
PROCESS_QUEUE_BUSY_ALARM,如果存在该告警且数量较多,则说明存在LoongCollector的处理性能瓶颈,导致了采集延迟。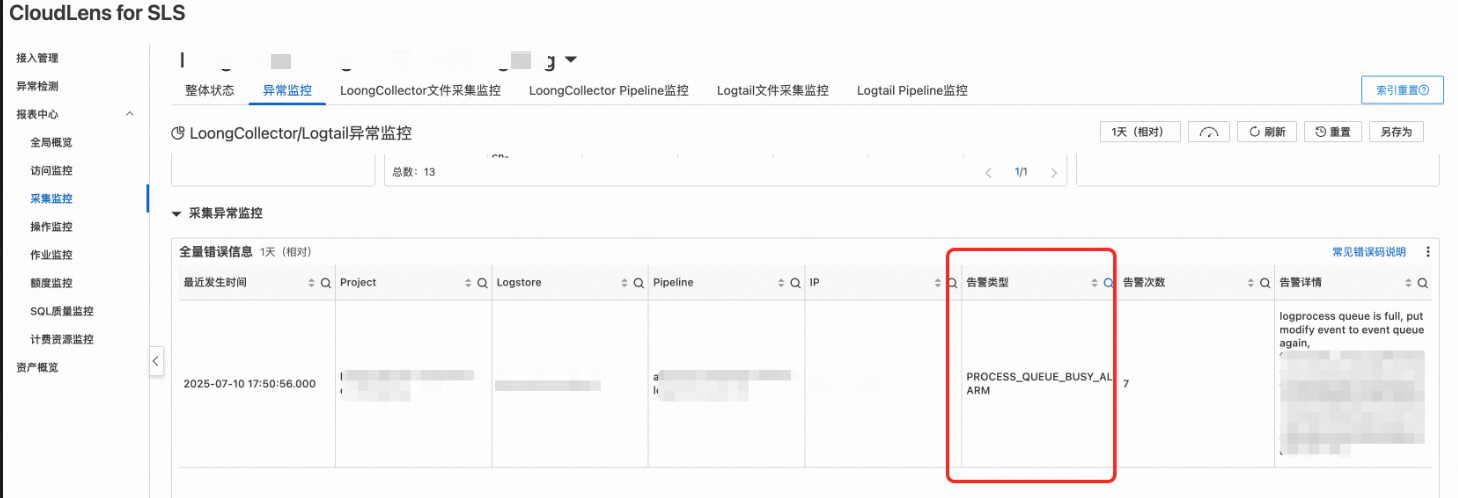
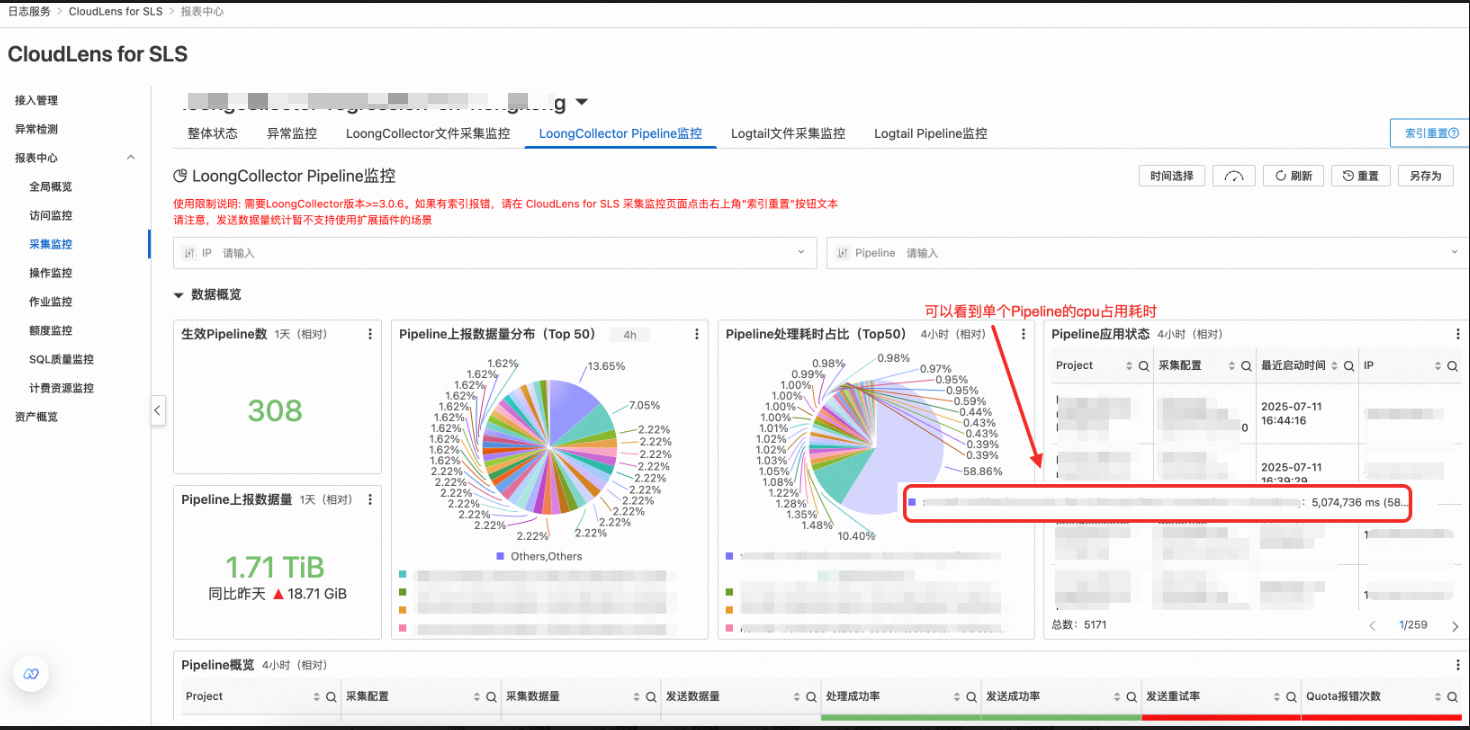
查看耗时较高的采集配置
在CloudLens for SLS的LoongCollector Pipeline监控,Pipeline处理耗时占比可以看到耗时较高的采集配置。
问题原因
LoongCollector有着优秀的采集性能(参见日志采集 Agent 性能大比拼——LoongCollector 性能深度测评),纯原生插件单线程处理速率可以超过100M/s。但是,如果采集配置中使用了扩展插件、使用了复杂正则、存在多个插件串联的情况,那么在数据量较大的时候,LoongCollector仍会达到性能瓶颈。此时,应该优先考虑将扩展插件替换为SPL插件或原生插件来提升处理性能。如果仍不能满足需求,则需要调整LoongCollector内部的处理线程数、cpu限制,来使LoongCollector更高效地处理数据。
解决方案
优先将扩展插件全部替换为使用Logtail SPL解析日志或原生插件,可以大幅提升处理性能。大部分常用的扩展插件,都有对应的原生插件,例如正则解析、json展开等,可以参见Logtail插件列表。
在尽可能将所有扩展插件替换为原生插件后,如果处理性能依旧不能满足需求,LoongCollector可以通过调大cpu使用限制、增加处理线程来加速数据的处理。可以参考设置启动参数修改LoongCollector的启动参数,可以着重调整
cpu_usage_limit和process_thread_count。
告警配置建议
针对PROCESS_QUEUE_BUSY_ALARM报错配置告警。需要注意,偶发的PROCESS_QUEUE_BUSY_ALARM可能是日志文件在某一瞬间写入了较多数据,并不会导致采集延迟,只有持续报错,才说明LoongCollector处理能力不足。
监控日志类型:运行日志
筛选条件:alarm_type为
PROCESS_QUEUE_BUSY_ALARM,表示处理队列满。信息展示:展示一定时间段内出现处理缓慢报错的Project、Logstore、采集配置。
查询间隔:5分钟。告警的间隔为30s,如果五分钟内报错超过5次,说明LoongCollector存在处理能力不足导致的采集延迟问题。
参考语句:
__topic__: logtail_alarm and alarm_type: PROCESS_QUEUE_BUSY_ALARM | SELECT project, logstore, split_part(config_name, '$', 2) as "采集配置", count(1) as cnt from log group by project, logstore, config_name having cnt >5 order by cnt desc limit all