分散在不同服务器上的业务日志或系统日志,难以统一检索、监控和分析。使用LoongCollector(Logtail)采集器,可将 ECS 实例、自建 IDC 或其他云厂商主机上的文本日志实时、增量地采集到 日志服务,以实现日志的集中化管理与分析。如需采集全量日志,可以通过导入历史日志文件实现。
适用范围
支持的操作系统与架构:
LoongCollector 当前仅支持 Linux 系统;Windows 主机请使用 Logtail。新接入场景建议优先选用 LoongCollector。
LoongCollector 是阿里云日志服务推出的新一代日志采集 Agent,是 Logtail 的升级版。用户在使用时,只需安装LoongCollector或Logtail其中之一,无需重复安装。
计算资源要求:
CPU:最少预留0.4 Core。
内存:最少需要 300 MB。
使用率建议:为保证稳定运行,建议LoongCollector(Logtail)的实际资源使用率低于限制值的 80%。实际使用量与采集速率、监控目录和文件数量、发送阻塞程度等因素相关。
权限要求:
若使用 RAM 用户操作,需授予
AliyunLogFullAccess和AliyunECSFullAccess权限。如需精细化授权,请参考附录:自定义权限策略。
采集配置创建流程
准备工作:创建Project和LogStore,Project是资源管理单元,用于隔离不同业务日志,而LogStore用于存储日志。
配置机器组(安装LoongCollector):根据服务器类型,安装LoongCollector,并将其加入到机器组。使用机器组统一管理采集节点,对服务器进行配置分发与状态管理。
查询与分析配置:系统默认开启全文索引,支持关键词搜索。建议启用字段索引,以便对结构化字段进行精确查询和分析,提升检索效率。
准备工作
在采集日志前,需规划并创建用于管理与存储日志的Project和LogStore。若已有可用资源,可跳过此步骤,直接进入配置机器组(安装LoongCollector)。
创建Project
创建LogStore
单击Project名称,进入目标Project。
在左侧导航栏,选择
 ,单击+。
,单击+。在创建LogStore页面,完成以下核心配置:
LogStore名称:设置一个在Project内唯一的名称,该名称创建后不可修改。
LogStore类型:根据规格对比选择标准型或查询型。
计费模式:
按使用功能计费:按存储、索引、读写次数等各项资源独立计费。适合小规模或功能使用不确定的场景。
按写入数据量计费:仅按原始写入数据量计费,提供30天免费存储,以及免费的数据加工、投递等功能。适合存储周期接近30天或数据处理链路复杂的业务场景。
数据保存时间:设置日志的保留天数(1~3650天,3650为永久保存),默认为30天。
其他配置保持默认,单击确定。如需了解其他配置信息,请参考管理LogStore。
步骤一:配置机器组(安装LoongCollector)
在完成准备工作后,为不同类型的服务器安装LoongCollector并将其加入机器组。
以下安装步骤仅适用于日志源为阿里云ECS实例,且该实例与日志服务Project属于同一阿里云账号和相同地域的场景。
如果您的ECS实例与Project不在同一账号或地域,或者日志源为自建服务器,请参考LoongCollector 安装与配置进行操作。
配置步骤:
在
 日志库页面,单击目标LogStore名称前的
日志库页面,单击目标LogStore名称前的 展开。
展开。单击数据接入后的
 ,在快速数据接入弹框中,选择文本日志接入模板(如单行-文本日志),单击立即接入。
,在快速数据接入弹框中,选择文本日志接入模板(如单行-文本日志),单击立即接入。所有文本日志接入模板仅在解析插件上有所差异,其余配置流程一致,后续均可修改。
在机器组配置页面,配置如下参数:
使用场景:主机场景
安装环境:ECS
配置机器组:根据目标服务器的LoongCollector安装情况与机器组配置状态,选择对应操作:
已安装LoongCollector且已加入某个机器组,直接在源机器组列表中勾选,将其添加至应用机器组列表,无需重复创建。
未安装LoongCollector,单击创建机器组:
以下步骤将引导您完成LoongCollector的一键自动安装并创建机器组。
系统会自动列出与 Project 同地域的 ECS 实例,勾选需要采集日志的一台或多台实例。
单击安装并创建为机器组,系统将自动在所选ECS实例上安装LoongCollector。
配置机器组名称并单击确定。
说明如果安装失败或一直处于等待中,请检查ECS地域是否与Project相同。
如需将已安装LoongCollector的服务器加入已有机器组,请参考常见问题如何将服务器加入到已有机器组?
检查心跳状态:单击下一步,页面出现机器组心跳情况。查看心跳状态,若为OK表示机器组连接正常,单击下一步,进入Logtail配置页面。
若为FAIL,可能是初次建立心跳需要花费一些时间,请等待两分钟左右,再刷新心跳状态。若刷新后仍为FAIL,请参考机器组心跳连接为fail进一步排查。
步骤二:创建并配置日志采集规则
完成LoongCollector安装和机器组配置后,进入Logtail配置页面,定义日志采集和处理规则。
1. 全局与输入配置
定义采集配置的名称及日志采集的来源和范围。
全局配置:
配置名称:自定义采集配置名称,在其所属Project内必须唯一。创建成功后,无法修改。命名规则:
仅支持小写字母、数字、连字符(-)和下划线(_)。
必须以小写字母或者数字作为开头和结尾。
输入配置:
类型:文本日志采集。
文件路径:日志采集的路径。
Linux:以“/”开头,如
/data/mylogs/**/*.log,表示/data/mylogs目录下所有后缀名为.Log的文件。Windows:以盘符开头,如
C:\Program Files\Intel\**\*.Log。
最大目录监控深度:文件路径中通配符
**匹配的最大目录深度。默认为0,表示只监控本层目录。
2. 日志处理与结构化
通过配置日志处理规则,将原始非结构化日志转换为结构化、可检索的数据,提升日志查询与分析效率。建议在配置前先添加日志样例:
在Logtail配置页面的处理配置区域,单击添加日志样例,输入待采集的日志内容。系统将基于样例识别日志格式,辅助生成正则表达式和解析规则,降低配置难度。
场景一:多行日志处理(如Java堆栈日志)
由于Java异常堆栈、JSON等日志通常跨越多行,在默认采集模式下会被拆分为多条不完整的记录,导致上下文信息丢失;为此,可启用多行模式,通过配置行首正则表达式,将同一日志的连续多行内容合并为一条完整日志。
效果示例:
未经任何处理的原始日志 | 默认采集模式下,每行作为独立日志,堆栈信息被拆散,丢失上下文 | 开启多行模式,通过行首正则表达式识别完整日志,保留完整语义结构。 |
|
|
|


配置步骤:在Logtail配置页面的处理配置区域,开启多行模式:
类型:选择自定义或多行JSON。
自定义:原始日志的格式不固定,需配置行首正则表达式,来标识每条日志的起始行。
行首正则表达式:支持自动生成或手动输入,正则表达式需要能够匹配完整的一行数据,如上述示例中匹配的正则表达式为
\[\d+-\d+-\w+:\d+:\d+,\d+]\s\[\w+]\s.*。自动生成:单击自动生成正则表达式,然后在日志样例文本框中,选择需提取的日志内容,单击生成正则。
手动输入:单击手动输入正则表达式,输入完成后,单击验证。
多行JSON:当原始日志均为标准JSON格式时,日志服务会自动处理单条JSON日志内部的换行。
切分失败处理方式:
丢弃:如果一段文本无法匹配行首规则,则直接丢弃。
保留单行:将无法匹配的文本按原始的单行模式进行切分和保留。
场景二:结构化日志
当原始日志为非结构化或半结构化文本(如 Nginx 访问日志、应用输出日志)时,直接进行查询和分析往往效率低下。日志服务提供多种数据解析插件,能够自动将不同格式的原始日志转换为结构化数据,为后续的分析、监控和告警提供坚实的数据基础。
效果示例:
未经任何处理的原始日志 | 结构化解析后的日志 |
| |
配置步骤:在Logtail配置页面的处理配置区域
添加解析插件:单击添加处理插件,根据实际格式配置正则解析、分隔符解析、JSON 解析等插件。此处以采集NGINX日志为例,选择。
NGINX日志配置:将 Nginx 服务器配置文件(nginx.conf)中的
log_format定义完整地复制并粘贴到此文本框中。示例:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$request_time $request_length ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent"';重要此处的格式定义必须与服务器上生成日志的格式完全一致,否则将导致日志解析失败。
通用配置参数说明:以下参数在多种数据解析插件中都会出现,其功能和用法是统一的。
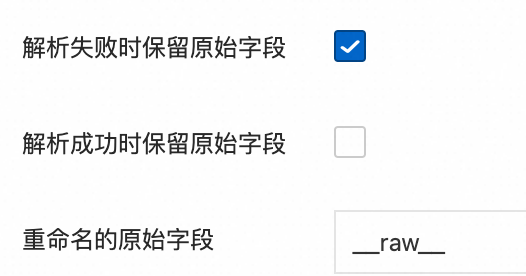
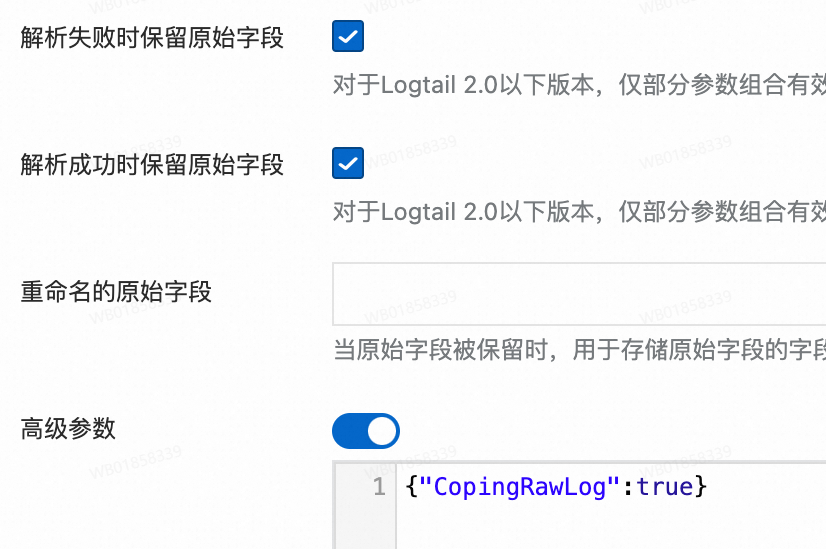
原始字段:指定要解析的源字段名。默认为
content,即采集到的整条日志内容。解析失败时保留原始字段:推荐开启。当日志无法被插件成功解析时(例如格式不匹配),此选项能确保原始日志内容不会丢失,而是被完整保留在指定的原始字段中。
解析成功时保留原始字段:选中后,即使日志解析成功,原始日志内容也会被保留。
3. 日志过滤
在日志采集过程中,大量低价值或无关日志(如 DEBUG/INFO 级别日志)的无差别收集,不仅造成存储资源浪费、增加成本,还影响查询效率并带来数据泄露风险。为此,可通过精细化过滤策略实现高效、安全的日志采集。
通过内容过滤降低成本
基于日志内容的字段过滤(如仅采集 level 为 WARNING 或 ERROR 的日志)。
效果示例:
未经任何处理的原始日志 | 只采集 |
| |
配置步骤:在Logtail配置页面的处理配置区域
单击添加处理插件,选择:
字段名:过滤的日志字段。
字段值:用于过滤的正则表达式,仅支持全文匹配,不支持关键词部分匹配。
通过黑名单控制采集范围
通过黑名单机制排除指定目录或文件,避免无关或敏感日志被上传。
配置步骤:在Logtail配置页面的区域,启用采集黑名单,并单击添加。
支持完整匹配和通配符匹配目录和文件名,通配符只支持星号(*)和半角问号(?)。
文件路径黑名单:需要忽略的文件路径,示例:
/home/admin/private*.log:在采集时忽略/home/admin/目录下所有以private开头,以.log结尾的文件。/home/admin/private*/*_inner.log:在采集时忽略/home/admin/目录下以private开头的目录内,以_inner.log结尾的文件。
文件黑名单:配置采集时需要忽略的文件名,示例:
app_inner.log:在采集时忽略所有名为app_inner.log的文件。
目录黑名单:目录路径不能以正斜线(/)结尾,示例:
/home/admin/dir1/:目录黑名单不会生效。/home/admin/dir*:在采集时忽略/home/admin/目录下所有以dir开头的子目录下的文件。/home/admin/*/dir:在采集时忽略/home/admin/目录下二级目录名为dir的子目录下的所有文件。例如/home/admin/a/dir目录下的文件被忽略,/home/admin/a/b/dir目录下的文件被采集。
4. 日志分类
当多个应用或实例的日志格式相同但路径不同时(如 /apps/app-A/run.log 和 /apps/app-B/run.log),采集日志难以区分来源。通过配置日志主题(Topic),对来自不同应用、服务或路径的日志进行逻辑区分,实现统一存储下的高效归类与精准查询。
配置步骤::选择Topic生成方式,支持如下三种类型:
机器组Topic:采集配置应用于多个机器组时,LoongCollector 会自动使用服务器所属的机器组名称作为
__topic__字段上传。适用于按主机划分日志场景。自定义:格式为
customized://<自定义主题名>,例如customized://app-login。适用于固定业务标识的静态主题场景。文件路径提取:从日志文件的完整路径中提取关键信息,动态标记日志来源。适用于多用户/应用共用相同日志文件名但路径不同的情况。当多个用户或服务将日志写入不同顶级目录,但下级路径和文件名一致时,仅靠文件名无法区分来源,例如:
/data/logs ├── userA │ └── serviceA │ └── service.log ├── userB │ └── serviceA │ └── service.log └── userC └── serviceA └── service.log此时您可以配置文件路径提取,并使用正则表达式从完整路径中提取关键信息,将匹配结果作为日志主题(Topic)上传至LogStore。
文件路径提取规则:基于正则表达式的捕获组
在配置正则表达式时,系统根据捕获组的数量和命名方式自动决定输出字段格式,规则如下:
文件路径的正则表达式中,需要对正斜线(/)进行转义。
捕获组类型
适用场景
生成字段
正则示例
匹配路径示例
生成字段示例
单捕获组(仅一个
(.*?))仅需一个维度区分来源(如用户名、环境)
生成
__topic__字段\/logs\/(.*?)\/app\.log/logs/userA/app.log__topic__:userA多捕获组-非命名(多个
(.*?))需要多个维度区分来源但无需语义标签
生成tag字段
__tag__:__topic_{i}__,其中{i}为捕获组的序号\/logs\/(.*?)\/(.*?)\/app\.log/logs/userA/svcA/app.log__tag__:__topic_1__userA;__tag__:__topic_2__svcA多捕获组-命名(使用
(?P<name>.*?)需要多个维度区分来源且希望字段含义清晰、便于查询与分析
生成tag字段
__tag__:{name}\/logs\/(?P<user>.*?)\/(?P<service>.*?)\/app\.log/logs/userA/svcA/app.log__tag__:user:userA;__tag__:service:svcA
步骤三:查询与分析配置
在完成日志处理与插件配置后,单击下一步,进入查询分析配置页面:
配置完成后,单击下一步,完成整个采集流程的设置。
步骤四:验证与故障排查
配置完成后,应用到机器组并保存。等待片刻后,按以下清单进行验证。
验证清单
确认日志文件有新增内容:LoongCollector只采集增量日志。执行
tail -f /path/to/your/log/file,并触发业务操作,确保有新的日志正在写入。检查LoongCollector状态:
sudo /etc/init.d/loongcollectord status。检查机器组心跳:前往
 资源 > 机器组页面,单击目标机器组名称,在区域,查看心跳状态。
资源 > 机器组页面,单击目标机器组名称,在区域,查看心跳状态。如果心跳为OK,则表示机器组与日志服务 Project 连接正常。
如果心跳为FAIL:参考机器组心跳连接为fail进行排查。
查询日志:进入目标 LogStore 的查询分析页面,单击查询/分析(默认时间范围为最近15分钟),观察是否有新日志流入。
常见问题排查
机器组心跳连接为fail
检查用户标识:如果您的服务器类型不是ECS,或ECS和Project属于不同阿里云账号,请检查指定目录下是否存在正确的用户标识,如不存在请参考如下命令手动创建。
Linux:执行
cd /etc/ilogtail/users/ && touch <uid>命令,创建用户标识文件。Windows:进入
C:\LogtailData\users\目录,创建一个名为<uid>的空文件。
检查机器组标识:如果您在创建机器组时使用了用户自定义标识,请检查指定目录下是否存在
user_defined_id文件,如果存在请检查该文件中的内容是否与机器组配置的自定义标识一致。Linux:
# 配置用户自定义标识,如目录不存在请手动创建 echo "user-defined-1" > /etc/ilogtail/user_defined_idWindows:在
C:\LogtailData目录下新建user_defined_id文件,并写入用户自定义标识。(如目录不存在,请手动创建)
如果用户标识和机器组标识均配置无误,请参考LoongCollector(Logtail)机器组问题排查思路进一步排查。
日志采集无数据
检查是否有增量日志:配置LoongCollector(Logtail)采集后,如果待采集的日志文件没有新增日志,则LoongCollector(Logtail)不会采集该文件。
检查机器组心跳状态:前往
 资源 > 机器组页面,单击目标机器组名称,在区域,查看心跳状态。
资源 > 机器组页面,单击目标机器组名称,在区域,查看心跳状态。如果心跳为OK,则表示机器组与日志服务 Project 连接正常。
如果心跳为FAIL:参考机器组心跳连接为fail进行排查。
确认LoongCollector(Logtail)采集配置是否已应用到机器组:即使LoongCollector(Logtail)采集配置已创建,但如果未将其应用到机器组,日志仍无法被采集。
前往
 资源 > 机器组页面,单击目标机器组名称,进入机器组配置页面。
资源 > 机器组页面,单击目标机器组名称,进入机器组配置页面。在页面中查看管理配置,左侧展示全部Logtail配置,右侧展示已生效Logtail配置。如果目标LoongCollector(Logtail)采集配置已移动到右侧生效区域,则表示该配置已成功应用到目标机器组。
如果目标LoongCollector(Logtail)采集配置未移动到右侧生效区域,请单击修改,在左侧全部Logtail配置列表中勾选目标LoongCollector(Logtail)配置名称,单击
 移动到右侧生效区域,完成后单击保存。
移动到右侧生效区域,完成后单击保存。
采集日志报错或格式错误
排查思路:这种情况说明网络连接和基础配置正常,问题主要出在日志内容与解析规则不匹配。您需要查看具体的错误信息来定位问题:
在Logtail配置页面,单击采集异常的LoongCollector(Logtail)配置名称,在日志采集错误页签下,单击时间选择设置查询时间。
在区域,查看错误日志的告警类型,并根据采集数据常见错误类型查询对应的解决办法。
配额与限制
限制项 | 限制说明 |
单条日志长度 | 默认限制为512 KB。您可通过启动参数max_read_buffer_size进行调整,最大不能超过8 MB。具体操作,请参见Logtail网络类型,启动参数与配置文件。 多行日志按行首正则表达式划分后,每条日志大小限制仍为512 KB。如果日志超过512 KB,会被强制拆分为多条进行采集。例如:单条日志大小为1025 KB,则第一次处理512 KB,第二次处理512 KB,第三次处理1 KB,最终采集结果为多条不完整的日志。 |
文件编码 | 支持UTF-8或GBK编码的日志文件,建议使用UTF-8编码获得更好的处理性能。 警告 如果日志文件为其它编码格式则会出现乱码、数据丢失等问题。 |
日志文件轮转 | 日志轮转队列大小默认为20。您可通过启动参数logreader_max_rotate_queue_size进行调整。具体操作,请参见Logtail网络类型,启动参数与配置文件。 支持设置采集路径为 重要 同一个Logtail实例中请勿混用两种形式,否则可能导致同一文件匹配多个Logtail采集配置,出现重复采集。 如果未处理完成的文件超过20个,将导致新生成的日志丢失。此类情况,请优先排查LogStore Shard写入Quota是否超限,并调整Logtail并发水平。具体操作,请Logtail网络类型,启动参数与配置文件。 更多信息,请参见相关技术文章。 |
日志解析阻塞时采集行为 | 日志解析阻塞时,Logtail会保持该日志文件描述符为打开状态,避免阻塞期间文件被删除,导致日志丢失。 如果解析阻塞期间出现多次日志文件轮转,Logtail会将文件放入轮转队列。 |
正则表达式 | 支持Perl兼容正则表达式。 |
JSON | 完全支持标准JSON(RFC7159、ECMA-404)。不支持非标准JSON,例如 |
文件打开行为 | Logtail会保持被采集的文件和轮转队列中待采集的文件处于打开状态,以保证采集数据完整性。出现以下情况,会关闭文件。
如果无论文件是否采集完成或仍有日志写入文件,您都希望文件在删除后的可控时间内释放文件句柄,则您可通过启动参数force_release_deleted_file_fd_timeout设置超时时间。具体操作,请参见Logtail网络类型,启动参数与配置文件。 |
首次日志采集行为 | Logtail只采集增量的日志文件。首次发现文件被修改后,如果文件大小超过1 MB(容器标准输出为512 KB),则从最后1 MB处开始采集,否则从开始位置采集。 您可通过Logtail采集配置中的tail_size_kb参数调整新文件首次采集的大小。具体操作,请参见Logtail配置(旧版)。 如果下发Logtail采集配置后,日志文件一直无修改,则Logtail不会采集该文件。如果需要采集历史文件,请参见导入历史日志文件。 |
文件发生覆盖的行为 | Logtail采用inode+文件中前1024字节的Hash识别文件。文件被覆盖后,如果inode或文件前1024字节Hash发生变化,则文件会作为新文件从头开始采集,否则不会被采集。 |
文件发生移动的行为 | 文件发生移动后,如果匹配Logtail采集配置,且该Logtail采集配置之前从未匹配过该文件,则移动后的文档将被当成新文件从头开始采集,否则不会被采集。 |
文件采集历史 | Logtail会在内存中保留文件采集历史进度,保证文件发生变化后仅采集增量部分,超过保留范围的日志如果发生写入,会导致重复采集。
|
非标准文本日志 | 对于日志中包含 |
计费说明
安装 LoongCollector 或 Logtail本身不收费。
日志写入、存储、索引、查询、加工、投递等环节将根据 LogStore 计费模式产生费用。
如果在安装或配置中使用了全球加速功能,通过加速网络传输的数据会产生额外的流量费用。
常见问题(FAQ)
如何将ECS服务器的日志传输到另一个阿里云账号的Project?
如果您尚未安装LoongCollector,请参考安装配置选择合适的跨账号场景进行安装;
如果您已安装了LoongCollector,请参考如下步骤配置用户标识,用于标识这台服务器有权限被日志服务Project所属账号访问、采集日志。
只有在采集非本账号ECS、自建IDC、其他云厂商服务器日志时需要配置用户标识。
复制日志服务所属的主账号ID:鼠标悬浮在右上角用户头像上,在弹出的标签页中查看并复制账号ID。
登录需要采集日志的服务器,创建阿里云账号ID文件配置用户标识:
touch /etc/ilogtail/users/{阿里云账号ID} # 如果/etc/ilogtail/users目录不存在,请手动创建目录。用户标识配置文件只需配置文件名,无需配置文件后缀。
如何将ECS服务器的日志传输到同账号不同地域的Project?
如果您尚未安装LoongCollector,请参考安装配置选择合适的跨地域场景进行安装;
如果已安装LoongCollector,则需要修改LoongCollector配置。
执行
sudo /etc/init.d/ilogtaild stop命令,停止LoongCollector。修改LoongCollector启动配置文件
ilogtail_config.json,根据您的网络需求从以下两种方式中选择一种进行修改:配置文件路径:
/usr/local/ilogtail/ilogtail_config.json方式一:使用公网传输
参考RegionID,将配置文件中的地域替换为日志服务所在的地域,需要修改的字段包括:
primary_regionconfig_servers中的地域部分data_servers中的region和endpoint_list地域部分
方式二:使用传输加速
将data_server_list参数中的endpoint一行替换为
log-global.aliyuncs.com。文件路径,请参见Logtail网络类型,启动参数与配置文件。
执行
sudo /etc/init.d/ilogtaild start命令,启动LoongCollector。
如何将服务器加入到已有机器组?
当您已有配置好的机器组,希望将新的服务器(如新部署的 ECS 或自建服务器)加入其中并继承其采集配置时,可通过以下步骤完成绑定。
操作前提:
已存在一个配置完成的机器组。
新服务器已安装 LoongCollector。
操作步骤:
查看目标机器组标识:
在目标Project页面,单击左侧导航栏
 。
。进入机器组页面,单击目标机器组名称。
在机器组配置页面,查看机器组标识。
根据标识类型执行对应操作:
说明同一机器组中不允许同时存在Linux服务器、Windows服务器,请勿在Linux和Windows服务器上配置相同的用户自定义标识。一个服务器可配置多个用户自定义标识,标识之间以换行符分隔。
类型一:机器组标识为IP地址
在服务器上,执行如下命令打开
app_info.json文件,查看ip值。cat /usr/local/ilogtail/app_info.json在目标机器组配置页面,单击修改,填写服务器的IP地址,多个IP之间使用换行符分隔。
配置完成后,单击保存,并确认心跳状态。心跳为OK后,服务器将自动应用机器组的采集配置。
若心跳状态为FAIL,请参考常见问题机器组心跳连接为fail进一步排查。
类型二:机器组标识为用户自定义标识
根据操作系统,向指定文件写入与目标机器组一致的用户自定义标识字符串:
若目录不存在需手动创建。文件路径和名称由日志服务固定,不可自定义。
Linux:向
/etc/ilogtail/user_defined_id文件写入自定义字符串 。Windows:向
C:\LogtailData\user_defined_id写入自定义字符串。
如何导入其他Project的采集配置?
在完成准备工作、机器组配置的基础上,您可将已有 Project 中的采集配置快速导入到当前 LogStore,避免重复配置,提升效率。
操作步骤:
如何获取服务器的IP地址,作为机器组标识?
在已安装LoongCollector(Logtail)的服务器上,打开/usr/local/ilogtail/app_info.json文件,查看ip值。
Logtail自动获取的服务器IP地址记录在app_info.json文件的ip字段中,如下所示。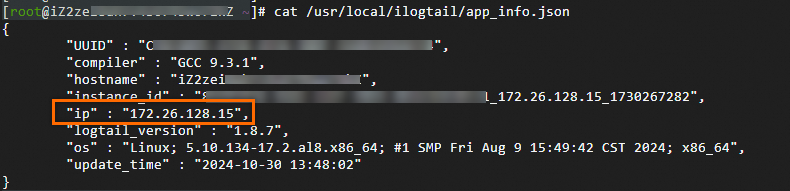
存在多台服务器时,请手动输入对应的IP地址,IP地址之间需使用换行符分隔。
同一机器组中不允许同时存在Linux和Windows服务器。请勿将Windows和Linux服务器IP添加到同一机器组中。
如何让同一个日志文件被多个采集配置同时采集?
默认情况下,日志服务为了避免数据重复,限制一个文本日志文件只能被一个Logtail配置采集。若需实现同一日志文件被多个采集配置同时采集,需要手动开启允许文件多次采集功能。
操作步骤:
采集多份时,文件读取的IO、计算资源和网络IO都会线性增加。
登录日志服务控制台,进入目标Project。
在左侧导航栏选择
 日志库,找到目标LogStore。
日志库,找到目标LogStore。单击其名称前的
 展开LogStore。
展开LogStore。单击Logtail配置,在配置列表中,找到目标Logtail配置,单击操作列的管理Logtail配置。
在Logtail配置页面,单击编辑:
,开启允许文件多次采集。
配置完成后,单击保存。
为什么最后一段日志延迟很久才上报?有时还会被截断?
原因分析:日志被截断通常发生在日志文件末尾缺少换行符,或多行日志(如异常堆栈)尚未完整写入时。由于采集器无法判断日志是否已结束,可能导致最后一段内容被提前切分或延迟上报。不同版本的LoongCollector(Logtail)处理机制有差异:
1.8 之前版本:
如果最后一行日志没有换行符(回车),或者一个多行日志段落未结束,采集器会一直等待下一次写入触发输出。这可能导致最后一条日志长时间滞留不发送,直到新日志写入。1.8 及之后版本:
引入超时刷新机制,避免日志卡住。当检测到未完成的日志行时,系统启动计时器,超时后自动提交当前内容,确保日志最终能被采集。默认超时时间:60 秒(保证大多数场景下的完整性)
您可根据实际需求调整该值,但不建议设为 0,否则可能导致日志截断或丢失部分内容。
解决方案:
您可以适当延长等待时间,确保完整日志写入后再被采集:
登录日志服务控制台,进入目标Project。
在左侧导航栏选择
日志库,找到目标LogStore。单击其名称前的
展开LogStore。单击Logtail配置,在配置列表中,找到目标Logtail配置,单击操作列的管理Logtail配置。
在Logtail配置页面,单击编辑:
:添加以下JSON配置自定义超时时间
{ "FlushTimeoutSecs": 1 }默认值:由启动参数
default_reader_flush_timeout决定(通常为几秒)。单位:秒。
建议值:≥1 秒,不建议设为 0,否则可能导致日志截断或丢失部分内容。
配置完成后,单击保存。
为什么LoongCollector(Logtail)在运行过程中会从内网域名切换到公网?能否自动切回?
LoongCollector(Logtail)运行过程中,若检测到内网域名通信异常(如网络不通、连接超时等),为保障日志采集的连续性和可靠性,系统会自动切换至公网域名进行数据发送,避免日志堆积或丢失。
LoongCollector:内网恢复后,自动切回内网。
Logtail:不会自动切回,需手动重启才能恢复内网通信。
附录:原生解析插件详解
在Logtail配置页面的处理配置区域,可以通过添加处理插件,对原始日志进行结构化处理。如需为已有采集配置添加处理插件,可以参考如下步骤:
在左侧导航栏选择
 日志库,找到目标LogStore。
日志库,找到目标LogStore。单击其名称前的
 展开LogStore。
展开LogStore。单击Logtail配置,在配置列表中,找到目标Logtail配置,单击操作列的管理Logtail配置。
在Logtail配置页面,单击编辑。
此处仅介绍常用处理插件,覆盖常见日志处理场景,如需更多功能,请参考拓展处理插件。
插件组合使用规则(适用于 LoongCollector / Logtail 2.0 及以上版本):
原生处理插件与拓展处理插件均可独立使用,也支持按需组合使用。
推荐优先选用原生处理插件,因其具备更优的性能和更高的稳定性。
当原生功能无法满足业务需求时,可在已配置的原生处理插件之后,追加配置拓展处理插件以实现补充处理。
顺序约束:
所有插件按照配置顺序组成处理链,依次执行。需要注意:所有原生处理插件必须先于任何拓展处理插件,添加任意拓展处理插件后,将无法继续添加原生处理插件。
正则解析
通过正则表达式提取日志字段,并将日志解析为键值对形式,每个字段都可以被独立查询和分析。
效果示例:
未经任何处理的原始日志 | 使用正则解析插件 |
| |
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
正则表达式:用于匹配日志,支持自动生成或手动输入:
自动生成:
单击自动生成正则表达式。
在日志样例中划选需要提取的日志内容。
单击生成正则。

手动输入:根据日志格式手动输入正则表达式。
配置完成后,单击验证,测试正则表达式是否能够正确解析日志内容。
日志提取字段:为提取的日志内容(Value),设置对应的字段名(Key)。
其他参数请参考场景二:结构化日志中的通用配置参数说明。
分隔符解析
通过分隔符将日志内容结构化,解析为多个键值对形式,支持单字符分隔符和多字符分隔符。
效果示例:
未经任何处理的原始日志 | 按指定字符 |
| |
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
分隔符:指定用于切分日志内容的字符。
示例:对于CSV格式文件,选择自定义,输入半角逗号(,)。
引用符:当某个字段值中包含分隔符时,需要指定引用符包裹该字段,避免错误切割。
日志提取字段:按分隔顺序依次为每一列设置对应的字段名称(Key)。规则要求如下:
字段名只能包含:字母、数字、下划线(_)。
必须以字母或下划线(_)开头。
最大长度:128字节。
其他参数请参考场景二:结构化日志中的通用配置参数说明。
标准JSON解析
将Object类型的JSON日志结构化,解析为键值对形式。
效果示例:
未经任何处理的原始日志 | 标准JSON键值自动提取 |
| |
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
原始字段:默认值为content(此字段用于存放待解析的原始日志内容)。
其他参数请参考场景二:结构化日志中的通用配置参数说明。
嵌套JSON解析
通过指定展开深度,将嵌套的JSON日志解析为键值对形式。
效果示例:
未经任何处理的原始日志 | 展开深度:0,并使用展开深度作为前缀 | 展开深度:1,并使用展开深度作为前缀 |
| | |
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
原始字段:需要展开的原始字段名,例如
content。JSON展开深度:JSON对象的展开层级。0表示完全展开(默认值),1表示当前层级,以此类推。
JSON展开连接符:JSON展开时字段名的连接符,默认为下划线 _。
JSON展开字段前缀:指定JSON展开后字段名的前缀。
展开数组:开启此项可将数组展开为带索引的键值对。
示例:
{"k":["a","b"]}展开为{"k[0]":"a","k[1]":"b"}。如果需要对展开后的字段进行重命名(例如,将 prefix_s_key_k1 改为 new_field_name),可以后续再添加一个重命名字段插件来完成映射。
其他参数请参考场景二:结构化日志中的通用配置参数说明。
JSON数组解析
使用json_extract函数,从JSON数组中提取JSON对象。
效果示例:
未经任何处理的原始日志 | 提取JSON数组结构 |
| |
配置步骤:在Logtail配置页面的处理配置区域,将处理模式切换为SPL,配置SPL语句,使用 json_extract函数从JSON数组中提取JSON对象。
示例:从日志字段 content 中提取 JSON 数组中的元素,并将结果分别存储在新字段 json1和 json2 中。
* | extend json1 = json_extract(content, '$[0]'), json2 = json_extract(content, '$[1]')Apache日志解析
根据Apache日志配置文件中的定义将日志内容结构化,解析为多个键值对形式。
效果示例:
未经任何处理的原始日志 | Apache通用日志格式 |
| |
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
日志格式:combined。
APACHE配置字段:系统会根据日志格式自动填充配置。
重要请务必核对自动填充的内容,确保与服务器上 Apache 配置文件(通常位于/etc/apache2/apache2.conf)中定义的 LogFormat 完全一致。
其他参数请参考场景二:结构化日志中的通用配置参数说明。
IIS日志解析
根据IIS日志格式定义将日志内容结构化,解析为多个键值对形式。
对比示例:
原始日志 | 微软IIS服务器专用格式适配 |
| |
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
日志格式:选择您的IIS服务器日志采用的日志格式。
IIS:Microsoft IIS日志文件格式。
NCSA:NCSA公用日志文件格式。
W3C:W3C扩展日志文件格式。
IIS配置字段:选择IIS或NCSA时,日志服务已默认设置了IIS配置字段,选择W3C时,设置为您的IIS配置文件中
logExtFileFlags参数中的内容。例如:logExtFileFlags="Date, Time, ClientIP, UserName, SiteName, ComputerName, ServerIP, Method, UriStem, UriQuery, HttpStatus, Win32Status, BytesSent, BytesRecv, TimeTaken, ServerPort, UserAgent, Cookie, Referer, ProtocolVersion, Host, HttpSubStatus"其他参数请参考场景二:结构化日志中的通用配置参数说明。
数据脱敏
对日志中的敏感数据进行脱敏处理。
效果示例:
未经任何处理的原始日志 | 脱敏结果 |
| |
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
时间解析
对日志中的时间字段进行解析,并将解析结果设置为日志的__time__字段。
效果示例:
未经任何处理的原始日志 | 时间解析 |
|
|
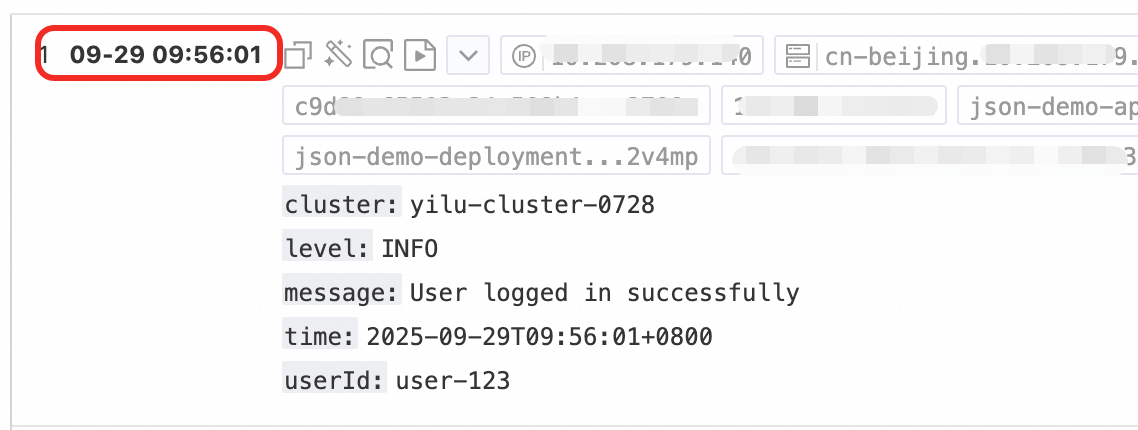
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
原始字段:解析日志前,用于存放日志内容的原始字段。
时间格式:根据日志中的时间内容设置对应的时间格式。
时区:选择日志时间字段所在的时区。默认使用机器时区,即LoongCollector(Logtail)进程所在环境的时区。
附录:权限策略参考
阿里云主账号登录:默认拥有全部权限,可直接操作。
RAM账号登录:需要主账号授权相应权限策略。
自定义权限策略(精细化控制)
当系统策略无法满足最小权限原则时,可通过创建自定义权限策略实现精细化授权。以下为权限策略示例,包含的权限有:
查看Project:查看Project列表,查看指定Project详情。
管理日志库 (LogStore): 在Project下创建新的日志库,或修改、删除已有的日志库。
管理采集配置: 创建、删除和修改采集配置。
查看日志: 查询和分析指定Project下指定日志库中的数据。
替换${regionName}${uid}、${projectName}、${logstoreName}为实际的地域名称,主账号id,目标Project和LogStore。
权限 | 对应操作 | 资源 |
只读Project |
|
|
获取指定Project |
|
|
管理LogStore |
|
|
管理LoongCollector(Logtail)数据接入 |
|
|
查询快速查询 |
|
|
查询仪表盘 |
|
|
查询指定日志库日志 |
|
|
操作ECS的权限 |
|
|
操作OOS的权限(可选) 仅在日志服务与ECS实例同账号同地域通过OOS自动化安装LoongCollector(Logtail)时需要。 |
|
|
系统权限策略
若使用系统预定义策略,建议添加以下权限:
AliyunLogFullAccess:管理日志服务的权限。AliyunECSFullAccess:管理ECS的权限。(可选)
AliyunOOSFullAccess:当通过 OOS 一键安装LoongCollector(Logtail)时需要。
更多信息
处理配置参数介绍
配置项 | 说明 |
日志样例 | 待采集日志的样例,请务必使用实际场景的日志。日志样例可协助您配置日志处理相关参数,降低配置难度。支持添加多条样例,总长度不超过1500个字符。 |
多行模式 |
|
处理模式 | 处理插件组合,包括原生处理插件和拓展处理插件。有关处理插件的更多信息,请参见处理插件概述。 重要 处理插件的使用限制,请以控制台页面的提示为准。
|