
日志服务智能异常分析App提供模型训练和实时巡检功能,支持对日志、指标等数据进行自动化、智能化、自适应地模型训练和异常巡检。本文介绍智能巡检的背景信息、工作原理、功能特性、基本概念、调度与执行场景和使用建议。
自2025年7月15日(UTC+8)起,智能异常分析功能停止对新用户服务,存量用户可继续使用。
影响范围
本次下线涉及的核心功能模块包括智能巡检、文本分析和时序预测。
功能平移方案
上述下线功能均可以通过日志服务的机器学习语法、定时查询与分析(定时SQL)和仪表盘实现完整替代。
背景信息
基于时间的数据(例如日志、指标)日积月累后会积累大量的数据。例如,某个服务每天产生1000万条数据,则一年大约为36亿条数据。对于这些数据,使用固定巡检规则的人工巡检方式面临以下问题:
效率低:对于异常现场的定位,需要人工配置各种各样的规则去进行异常的捕获。
时效差:大部分时序数据具有时效性特征。故障、变更都会引起对应指标形态的变化,前一种规则条件下的异常可能在下一时刻是正常状态。
配置难:时序数据形态各异。有突刺变化、折点变化、周期变化等诸多形态,阈值范围也各有不同。对于复杂形态下的异常,规则往往难以配置。
效果差:数据流不断动态变化,业务形态日新月异,固定的规则方法很难在新的业态下起作用,从而产生大量的误报或者漏报。对于异常的程度,不同场景,不同用户,对其容忍的程度不同。在排查问题中,有效异常点捕捉的越多,有助于具体问题的排查;而在告警通知中,高危异常点越少,越有助于提升告警处理的效率。
针对以上问题,日志服务推出智能巡检功能,通过自研的人工智能算法,对指标、日志等流数据进行一站式整合、巡检与告警。使用智能巡检功能后,您只需要组织一下具体的监控项,算法模型就会自动为您完成异常检测、业态自适应、告警精细,让您从复杂繁琐的规则配置中解脱出来。
工作原理
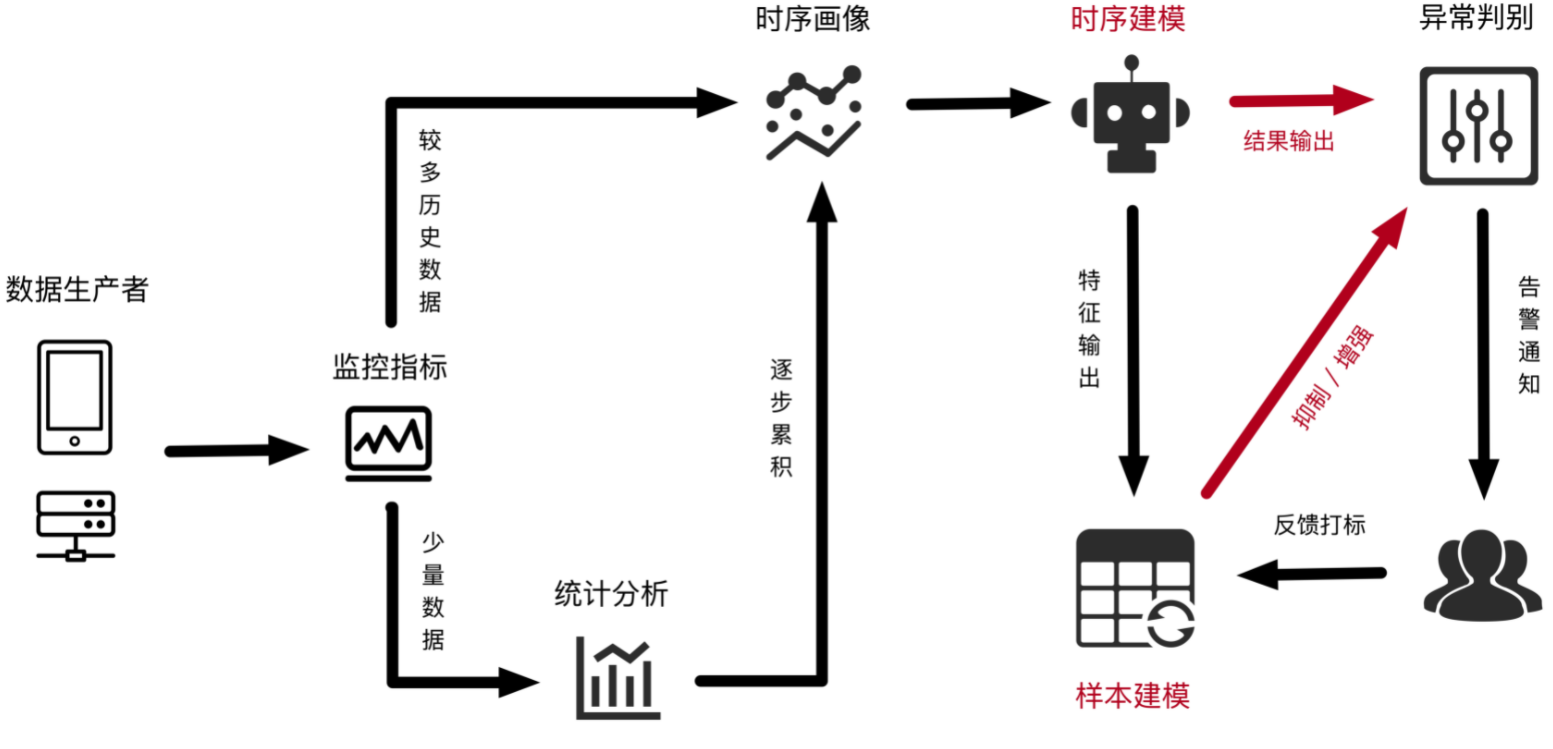
日志服务通过SQL方式构造、聚合监控指标,按照调度规则定时拉取数据输入模型,将巡检出来的结果按照事件标准写入目标日志库(internal-ml-log)中,并对异常发送告警通知。具体工作原理如下图所示。
功能特性
日志服务的智能巡检功能的特性如下表所示。
特性 | 说明 |
配置监控对象 | 设置SQL语句或查询分析语句,把日志数据转化成监控指标,发起任务 |
定时分析数据 | 根据需求设置具体的数据特征,配置实体项和指标项。巡检实例自动发现新的监控实体,定时拉取数据进行自动建模与智能分析。模型定时调度最高支持秒级拉取。 |
参数设置与模型效果预览 | 不同模型参数设置后支持效果预览,同时对指标时序曲线与异常分数曲线进行可视化。您可以轻松配置最适合当前数据特征的模型参数。 |
结果输出多渠道 | 巡检结果存储到目标LogStore中,通过告警通知将异常信息通知给您。 |
基本概念
日志服务的智能巡检功能涉及的基本概念如下表所示。
术语 | 说明 |
任务 | 一个巡检任务包括数据特征、模型参数、告警策略等信息。 |
实例 | 一个巡检任务按照任务配置生成执行实例。每一个实例针对任务配置定时拉取数据,运行算法模型,分发巡检结果。
|
实例ID | 执行实例的唯一标识。 |
创建时间 | 实例创建的时间。一般是按照您配置的任务规则生成,在补运行或追赶延迟时会立即生成实例。 |
执行时间 | 实例开始执行的时间。如果重试任务,则表示最后一次开始执行的时间。 |
结束时间 | 实例执行结束的时间。如果重试任务,则表示最后一次执行结束的时间。 |
执行状态 | 实例的执行状态。取值:
|
数据特征 | 数据特征包含以下配置:
|
算法配置 | 不同的算法有不同的配置项。各个算法的配置项说明请参见通过SQL聚合指标数据进行实时检测。 |
巡检事件 | 巡检事件包含以下配置:
|
调度与执行场景
巡检任务的调度与执行的主要场景如下表所示。
场景 | 说明 |
从某个历史时间点开始执行巡检任务 | 在当前时间点创建巡检任务后,按照任务规则对历史数据进行处理。算法模型会快速消费历史数据、进行模型训练,并逐渐追上当前时间。超过任务创建时间或者模型结束学习时间后,发出巡检事件。 |
修改调度配置 | 修改调度配置后,下一个实例按照新配置生成。算法模型会记忆当前消费的时间位置,进而对新来的数据继续巡检。 |
重试失败的实例 | 如果实例执行失败(例如权限不足、源库不存在、目标库不存在、配置不合法等),系统支持自动重试。若您的状态一直显示启动中,可能是配置失败。错误日志会发送到您的internal-etl-log下,您可以检查下配置并重新发起。调度执行完成后,系统会根据实际执行情况变更实例状态为成功或失败。 |
使用建议
建议您在使用智能巡检时,根据业务情况,明确具体的监控项,从而进行高效的数据转化与巡检。具体说明如下:
考虑数据上传LogStore的格式,明确字段的具体含义,确定观测时间间隔,从而完成巡检任务的快速配置。
掌握所监控对象的时序数据变化情况,了解其稳定性、周期性,对异常形态有初步预期,从而完成算法参数的合理配置。
按整时(例如整秒、整分钟、整小时)对齐巡检任务时间窗口,从而保证异常事件的告警及时性与多事件关联的准确性。
模型训练
您还可以使用模型训练功能加强对数据的异常学习,提升未来的异常预警准确率,模型训练主要具备以下优势。
直接使用实时巡检功能,准确率不及预期。通过模型训练任务,可提升异常检测的准确性。
通过实时巡检任务检测出来的异常和您所认为的异常之间存在GAP值时,建议您先通过模型训练任务来自适应检测所需要的异常类型。
基本流程
输入数据:写入模型训练服务所需要的数据,包含带标签的指标数据和不带标签的指标数据。这些数据统一存储在日志服务中,需要通过SQL查询来获取。其中,带标签的指标数据可以直接进入算法服务,不带标签的指标数据需要通过模拟异常注入方式,在获得标签后进入算法服务。
算法服务:主要包含特征工程和监督模型两部分。在算法服务中,每一个实体训练一个模型,即会使用实体ID标识对应的模型。
结果保存和可视化:模型训练任务完成后,系统会将所训练的模型进行云端保存,将数据集的验证结果、任务运行的事件等以日志形式保存到名为internal-ml-log的LogStore中。您还可以通过任务详情查看可视化结果。
创建预测任务:模型训练任务完成后,您将得到该任务中每个实体所训练的模型。接着您可以创建预测任务,通过预测任务对未来指标数据做实时的异常检测,以及日志服务打标工具,对结果进行打标,得到更多的标签数据,反复训练模型,提升准确率。
算法服务简介
算法服务主要包括如下三部分。
数据集:通过指定的时间范围构建数据集,分为训练集和验证集。
训练集的时间长度需大于12天,因为模型训练任务需要历史一周的数据做为特征工程的前提条件;验证集长度需大于3天,因为需要三天的数据给出验证报告,更好地说明模型的拟合程度、鲁棒性以及表现水平。
特征工程:包括同环比特征、平移特征、趋势特征、窗口特征、时间特征等。
集成模型:通过集成多个树模型来构建最终的模型。