
表格存储向量检索(KnnVectorQuery)使用数值向量进行近似最近邻查询,可以在大规模数据集中找到最相似的数据项。向量检索功能适用于检索增强生成(RAG)、推荐系统、相似性检测、自然语言处理与语义搜索等场景。
应用场景
向量检索适用于推荐系统、图像与视频检索、自然语言处理与语义搜索等场景。
检索增强生成(RAG)
RAG是一种将检索能力和大模型能力结合在一起的AI框架,通过检索能力增强大模型输出结果的准确性,尤其是在私域数据或者专业数据领域可以大幅提升大模型输出结果的准确性。当前广泛应用于知识库场景。
推荐系统
在电商、社交媒体、视频流媒体等平台中,用户行为、偏好、内容特征等内容可以编码为向量进行存储,然后通过向量检索快速找到与用户兴趣相匹配的产品、文章或视频,实现个性化推荐,提升用户满意度和留存率。
相似性检测(图像、视频和语音等)
在图像,视频、语音、声纹和人脸识别等领域中,可以将这些非结构化的数据转换为向量表示,然后通过向量检索快速找到最相似的目标。例如,在电商平台中,用户上传一张图片后,系统能迅速找出具有类似样式、颜色或图案的商品图片。
自然语言处理与语义搜索
在NLP领域,将文本转换为向量表示(例如Word2Vec、BERT嵌入等),然后通过向量检索理解查询语句的语义,并找出语义上最相关的文档、新闻、问答等内容,提升搜索结果的相关性和用户体验。
知识图谱与智能问答
知识图谱节点和关系可以表示为向量,通过向量检索能够加速实体链接、关系推理以及智能问答系统的响应速度,使系统能够更准确地理解和回答复杂的问题。
产品核心优势
低成本
核心引擎采用优化后的DiskAnn技术,相较于HNSW算法,无需加载所有索引数据到内存,只需不到10%的内存即可达到HNSW图算法的高召回率和高性能,使整体成本显著低于同类型系统。
简单易用
向量检索作为多元索引的一个子功能,也具备Serverless特性,用户无需搭建部署系统,只需通过表格存储控制台创建实例即可开始使用。
使用过程中支持按量付费,无需关心水位和扩容,系统在存储和计算上均支持水平扩展。向量检索最大可以支持千亿规模,非向量检索最大可以支持十万亿规模。
向量检索时内部引擎使用查询优化器自动选择最佳算法和执行路径,无需进行众多参数的调优即可达到高召回率和高性能,大幅降低使用门槛,有效缩短业务研发周期。
支持通过SQL、多种SDK(Java、Golang、Python和Node.js等语言)和开源框架(LangChain、LangChain4J和LlamaIndex)等方式使用向量检索。
功能概述
向量检索(KnnVectorQuery)使用数值向量进行近似最近邻查询,可以在大规模数据集中找到最相似的数据项。
向量检索继承了多元索引的所有特性,无需部署搭建系统,即开即用,按量付费。支持多元索引的流式构建,数据写入表后近实时可查询;支持高吞吐的新增、更新和删除;查询性能和采用HNSW算法的系统相当。
使用KnnVectorQuery功能查询数据时,您可以需要指定要查询相似度的向量、要匹配的向量字段以及要查询的最邻近TopK个值,来获取向量字段中与要查询相似度的向量最相似的TopK个值。您还可以组合使用其他非向量检索的查询功能来过滤查询结果。
向量字段说明
使用KnnVectorQuery功能前,您需要在创建多元索引时配置向量字段并指定向量维度、向量数据类型和向量之间的距离度量算法。
向量字段在数据表中对应字段的数据类型必须为字符串类型,在多元索引中的数据类型必须为Float32数组字符串。向量字段的具体配置说明请参见下表。
配置项 | 说明 |
dimension | 向量维度,当前最大支持4096维。维度值必须和上游向量生成(embedded)系统产生的向量维度一致。 向量字段的数组长度与该字段的dimension参数配置相等,例如向量字段的值为 说明 当前仅支持稠密向量,多元索引中向量字段的数据维度必须和创建索引时Schema中设置的维度保持一致。如果过多或者过少都会导致该行数据构建索引失败。 |
dataType | 向量的数据类型。当前仅支持Float32,并且Float32不支持NaN和Infinite等极端值。 数据类型必须和上游向量生成(embedded)系统产生的向量数据类型保持一致。 说明 如果有其他数据类型的向量使用需求,请提交工单联系我们。 |
metricType | 向量之间的距离度量算法。取值范围包括欧氏距离(euclidean)、余弦相似度(cosine)、点积(dot_product)。 距离度量算法必须和上游向量生成(embedded)系统的建议算法保持一致。更多信息,请参见距离度量算法说明。 |
向量生成(embedded)系统的不同模型或者不同版本生成的向量属性不同,包括维度、数据类型和距离度量算法。向量检索系统中的向量字段的属性(维度、数据类型和距离度量算法)必须和向量生成(embedded)系统中生成的向量属性保持一致。关于向量生成的具体操作,请参见两种生成向量的方式。
距离度量算法说明
向量检索支持的距离度量算法包括欧氏距离(euclidean)、余弦相似度(cosine)、点积(dot_product)。具体说明请参见下表。评分公式的值越大表示两个向量的相似度越大。
MetricType | 评分公式 | 性能 | 说明 |
欧氏距离 (euclidean) | 较高 | 多维空间中两个向量之间的直线距离。出于性能考虑,表格存储中的欧氏距离算法未进行最后的平方根计算。欧氏距离的评分越大表示两个向量的相似度越大。 | |
点积 (dot_product) | 最高 | 维度相同的两个向量的对应坐标相乘,然后将结果相加。点积的评分越高表示两个向量的相似度越大。 重要 Float32向量必须在写入表前进行归一化(例如使用L2范数进行归一化),否则会出现查询效果差、构建向量索引慢、查询性能差等潜在问题。向量归一化示例请参见附录2:向量归一化示例。 | |
余弦相似度 (cosine) | 较低 | 向量空间中两个向量间夹角的余弦值。余弦相似度的评分越高表示两个向量的相似度越大。常用于文本数据的相似度计算。 由于0无法作为除数,无法完成余弦相似度的计算,因此Float32向量的平方和不允许为0。 重要 余弦相似度计算复杂,推荐您在写入数据到表之前进行向量的归一化,然后使用点积(dot_product)作为向量距离的度量算法。向量归一化示例请参见附录2:向量归一化示例。 |
注意事项
使用向量检索时,请注意如下事项:
向量字段类型的个数、维度等存在限制。更多信息,请参见多元索引使用限制。
由于多元索引服务端是多分区的,多元索引服务端的每个分区均会返回自身最邻近的TopK个值并在协调节点进行汇总,因此如果要使用Token翻页获取所有数据,则获取到的总行数与多元索引服务端的分区数有关。
目前支持使用向量检索功能的地域包括华东1(杭州)、华东2(上海)、华北1(青岛)、华北2(北京)、华北3(张家口)、华北6(乌兰察布)、华南1(深圳)、华南3(广州)、西南1(成都)、中国香港、日本(东京)、新加坡、马来西亚(吉隆坡)、印度尼西亚(雅加达)、菲律宾(马尼拉)、泰国(曼谷)、德国(法兰克福)、英国(伦敦)、美国(弗吉尼亚)、美国(硅谷)、华东1 金融云、华东2 金融云、华北2 阿里政务云1。
使用流程
计费说明
公测期间,使用向量索引不引入额外的向量索引专用计费项,当前按照已有模式进行计费。
使用VCU模式(原预留模式)时,使用多元索引查询数据会消耗VCU的计算资源。使用CU模式(原按量模式)时,使用多元索引查询数据会消耗读吞吐量。更多信息,请参见多元索引计量计费。
附录1:与BoolQuery组合使用说明
KnnVectorQuery可以和BoolQuery自由组合使用,不同的组合使用方式会有不同的效果,以下对两种常见的使用方式进行说明。此处以一个Filter命中数据量较少的场景为例进行介绍。
假设表中有1亿张图片,其中用户“a”总计有5万张图片,但是近7天内仅有50张图片,用户“a”希望以图搜图的方式找到7天内最相似的10张图片。由下表说明可知KnnVectorQuery的Filter内部使用BoolQuery的组合使用方式能满足用户“a”的查询需求。
组合使用方式 | 查询条件图示 | 说明 |
KnnVectorQuery的Filter内部使用BoolQuery |
| KnnVectorQuery命中的行数据为在满足BoolQuery条件下返回最相似的TopK个行数据,SearchRequest返回的结果为TopK行数中的前Size个。 在此示例中,KnnVectorQuery首先通过Filter筛选出该用户“a”在7天内的所有50张图片,然后再从这50张图片中找到最相似的10张图片返回给用户。 |
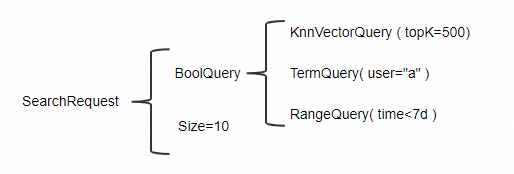
BoolQuery中使用KnnVectorQuery |
| BoolQuery的每一个子查询条件会首先进行查询,然后对所有子查询求交集。 在此示例中,KnnVectorQuery会返回表中1亿张图片中最相似的前TopK=500张图片,然后再按照顺序找出用户“a”在7天内的10张图片。但是由于所有图片的TopK=500张图片中不一定包含用户“a”近7天内所有的50张图片,因此该查询方式不一定能找到近7天内的10张图片,甚至找不到任何数据。 |

附录2:向量归一化示例
向量归一化的示例代码如下:
public static float[] l2normalize(float[] v, boolean throwOnZero) {
double squareSum = 0.0f;
int dim = v.length;
for (float x : v) {
squareSum += x * x;
}
if (squareSum == 0) {
if (throwOnZero) {
throw new IllegalArgumentException("can't normalize a zero-length vector");
} else {
return v;
}
}
double length = Math.sqrt(squareSum);
for (int i = 0; i < dim; i++) {
v[i] /= length;
}
return v;
}