
在创建分析存储的映射关系后,您可以使用SQL查询与分析时序数据。本文介绍分析存储SQL查询样例。
样例场景
某厂商有100000台设备,每台设备每两分钟会生成一组CPU监控数据。为了方便管理和分析设备状态,厂商会将采集的设备监控数据接入到云端进行存储来降低业务成本,同时通过分析设备状态来监控设备运行情况。
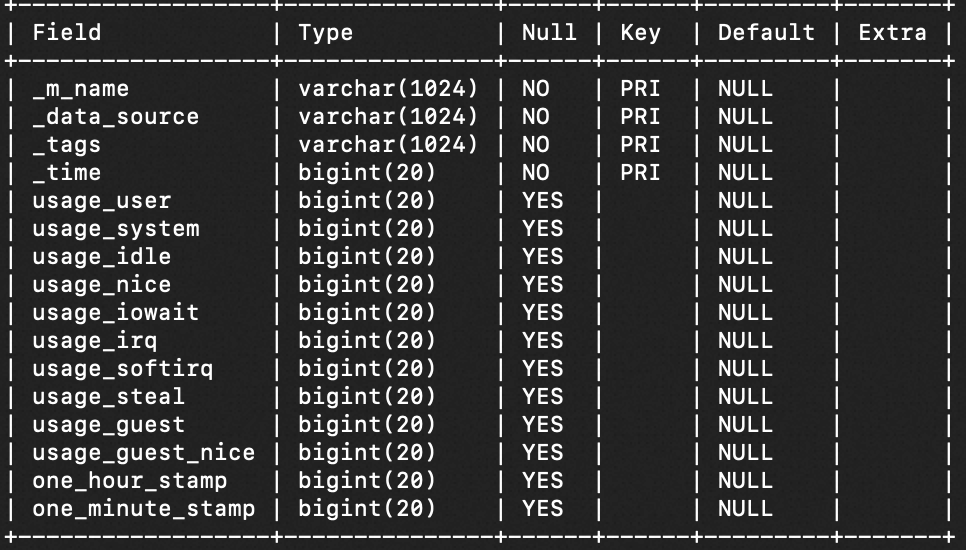
在该样例场景中,您可以通过SQL查询功能来快速查询与分析时序数据。假如设备的监控数据存储在表格存储时序表device中,时序表的映射关系为`device::cpu`,schema如下图所示。
步骤一:创建分析存储的映射关系
通过CREATE TABLE语句创建多值模型映射关系。更多信息,请参见时序表的SQL映射关系。
语法
_m_name、_data_source、_tags和_time字段为固定配置,保留相应内容即可,无需修改。
CREATE TABLE table_name (
`_m_name` VARCHAR(1024),
`_data_source` VARCHAR(1024),
`_tags` VARCHAR(1024),
`_time` BIGINT(20),
`column_name ` data_type,
......
`user_column_namen ` data_type,
PRIMARY KEY(`_m_name`,`_data_source`,`_tags`,`_time`))ENGINE=AnalyticalStore参数
参数 | 说明 |
table_name | 表名,用于唯一标识一张表。格式为 |
column_name | 列名。SQL中的列名必须和原始表中的列名等效,例如原始表中列名为Aa,在SQL中列名必须使用Aa、AA、aA或者aa中的一个。 |
data_type | 列的数据类型,包含BIGINT、DOUBLE、BOOL等多种数据类型。 SQL中列的数据类型必须和原始表中列的数据类型相匹配。关于数据类型映射的更多信息,请参见SQL数据类型映射。 |
ENGINE | 使用映射表查询数据时的执行引擎。
|
示例
创建device时序表的多值模型映射关系`device::cpu`。
CREATE TABLE `device::cpu`
(`_m_name` VARCHAR(1024),
`_data_source` VARCHAR(1024),
`_tags` VARCHAR(1024),
`_time` BIGINT(20),
`usage_user` BIGINT(20),
`usage_system` BIGINT(20),
`usage_idle` BIGINT(20),
`usage_nice` BIGINT(20),
`usage_iowait` BIGINT(20),
`usage_irq` BIGINT(20),
`usage_softirq` BIGINT(20),
`usage_steal` BIGINT(20),
`usage_guest` BIGINT(20),
`usage_guest_nice` BIGINT(20),
`one_hour_stamp` BIGINT(20),
`one_minute_stamp` BIGINT(20),
PRIMARY KEY(`_m_name`,`_data_source`,`_tags`,`_time`)) ENGINE=AnalyticStore;步骤二:使用SQL查询数据
创建映射关系后,使用SELECT语句查询表中的数据。时序分析存储写入数据存在同步延迟,查询最近数据进行计算时可能会存在部分数据未同步的情况。
语法
SELECT语句中子句的执行优先级为WHERE子句 > GROUP BY分组查询 > ORDER BY排序 > LIMIT和OFFSET。
SELECT
select_expr [, select_expr] ...
[FROM table_references]
[WHERE where_condition]
[GROUP BY groupby_condition]
[ORDER BY order_condition]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]参数
参数 | 是否必选 | 说明 |
select_expr | 是 | 列名或者列表达式,格式为 通过列表达式指定需要查询的列。使用规则如下: |
table_references | 是 | 目标时序表映射关系名称。 |
where_condition | 否 | WHERE子句,可配合不同条件实现相应功能。配合关系运算符查询符合指定条件的数据,格式为 使用规则如下: |
groupby_condition | 否 | GROUP BY分组查询,可配合时序函数使用。 使用规则如下:
|
order_condition | 否 | ORDER BY排序,格式为
|
row_count | 否 | 本次查询需要返回的最大行数。 |
offset | 否 | 本次查询的数据偏移量,默认偏移量为0。 |
示例
示例一:查询所有设备在
2023-01-05 05:14:00到2023-01-07 09:14:00时间段内每天的最大usage_irq和最大usage_softirq。重要unix_timestamp_micros("2023-01-05 05:14:00.000000")中时间的时区为系统时区(中国为UTC+8北京时间)。SELECT time_bin(_time,"1day"), max(usage_irq),max(usage_softirq) FROM `device::cpu` WHERE _time > unix_timestamp_micros("2023-01-05 05:14:00.000000") AND _time < unix_timestamp_micros("2023-01-07 09:14:00.000000") GROUP BY 1 ORDER BY 1;示例二:查询在host_50625且cpu架构为x64的设备所有时间平均usage_nice。
SELECT avg(usage_nice) FROM `device::cpu` WHERE _data_source = "host_50625" AND tag_value_at(_tags,"arch") = "x64";示例三:查询所有设备在
2023-01-05 05:14:00到2023-01-07 09:14:00时间段内数据行数以及平均usage_user和平均usage_system。SELECT count(*),avg(usage_idle),avg(usage_system) FROM `device::cpu` WHERE _time > unix_timestamp_micros("2023-01-05 05:14:00.000000") AND _time < unix_timestamp_micros("2023-01-07 09:14:00.000000");示例四:将cpu数据每周分组,对每组数据按照每小时再分组,计算每个分组中usage_user的标准差。
SELECT week(from_unixtime_micros(_time)) as week,time_bin(_time,"1h"), stddev(usage_user) FROM `device::cpu` GROUP BY 1,2 ORDER BY 1,2;示例五:查询在host_50625的所有设备在
2023-01-05 05:14:00到2023-01-07 09:14:00时间段内每两小时最后时刻(lastpoint)的usage_user,usage_system以及usage_nice。SELECT time_bin(_time,"2h"), max_by(usage_user,_time), max_by(usage_system,_time),max_by(usage_nice,_time) FROM `device::cpu` WHERE _time > unix_timestamp_micros("2023-01-05 05:14:00.000000") AND _time < unix_timestamp_micros("2023-01-07 09:14:00.000000") AND _data_source = 'host_50625' GROUP BY 1 ORDER BY 1;示例六:输出usage_user为100时在
2023-01-05 05:14:00到2023-01-07 09:14:00时间段内的时间数据、月份名称、星期名称、小时、分钟、秒以及微秒。SELECT from_unixtime_micros(_time) as time, monthname(from_unixtime_micros(_time)) as monthname, dayname(from_unixtime_micros(_time)) as dayname, hour(from_unixtime_micros(_time)) as hour, minute(from_unixtime_micros(_time)) as minute, second(from_unixtime_micros(_time)) as second, microsecond(from_unixtime_micros(_time)) as microsecond FROM `device::cpu` WHERE _time > unix_timestamp_micros("2023-01-05 05:14:00.000000") AND _time < unix_timestamp_micros("2023-01-07 09:14:00.000000") AND usage_user = 100 LIMIT 100;