本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
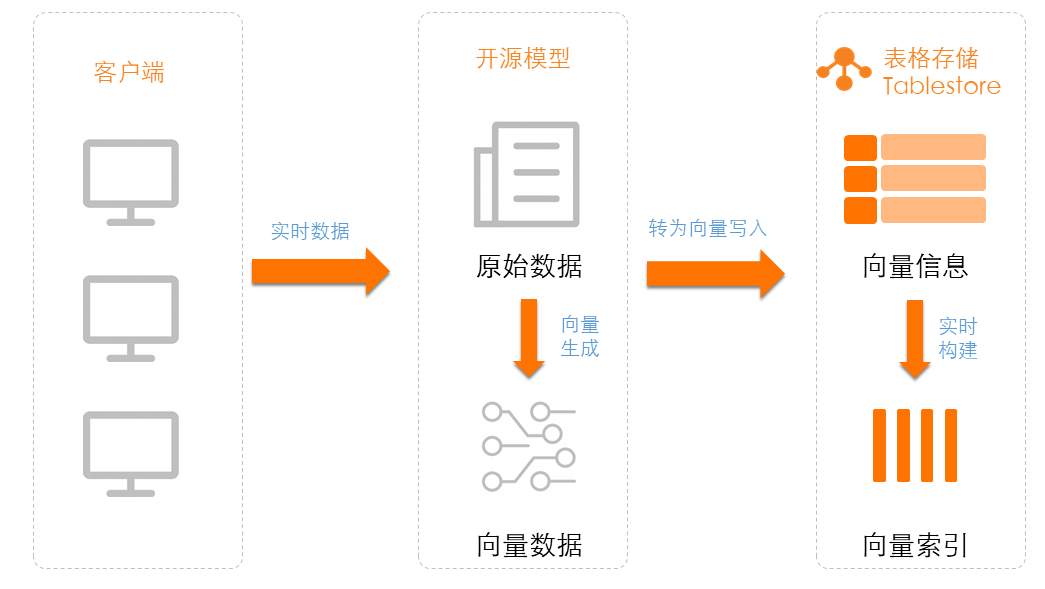
本文介绍如何将存储在 Tablestore 中的文本数据通过开源模型生成向量。
方案概览
ModelScope(魔搭社区)旨在打造下一代开源的模型即服务共享平台,为泛 AI 开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单。ModelScope 魔搭社区汇集行业领先的预训练模型,减少开发者的重复研发成本,提供更加绿色环保、开源开放的 AI 开发环境和模型服务。
使用免费开源模型将存储在 Tablestore 中的文本数据生成向量只需4步:
安装 Python SDK:使用开源模型生成向量和表格存储功能前,您需要安装表格存储 SDK 和开源模型 SDK。
选择与下载开源模型:ModelScope 魔搭社区提供了大量的文本向量 Embedding 模型,您可以通过模型库进行选择和下载使用。
生成向量并写入到表格存储:使用开源模型生成向量后,将向量数据写入到表格存储数据表中使用。
结果验证:使用表格存储的数据读取接口或者多元索引向量检索功能查询向量数据。
使用说明
开发语言:Python
Python版本:推荐使用 Python3.9 及以上版本。
测试环境:本文中示例已经过 CentOS 7 和 macOS 平台的环境验证。
注意事项
Tablestore 多元索引中向量类型的维度、类型、距离算法必须与开源模型中文本转向量模型的相应配置保持一致。例如开源模型damo/nlp_corom_sentence-embedding_chinese-tiny生成的向量类型为 256 维、Float32 类型和 euclidean 欧氏距离算法,在 Tablestore 创建多元索引时的向量类型也必须是 256 维、Float32 类型和 euclidean 欧氏距离算法。
前提条件
使用阿里云账号或者具有表格存储操作权限的 RAM 用户进行操作。
如果要使用 RAM 用户进行操作,您需要使用阿里云账号创建 RAM 用户并授予 RAM 用户访问表格存储(AliyunOTSFullAccess)的权限。具体操作,请参见为RAM用户授权。
已为阿里云账号或者 RAM 用户创建 AccessKey。具体操作,请参见创建AccessKey。
警告阿里云账号 AccessKey 泄露会威胁您所有资源的安全。建议您使用 RAM 用户 AccessKey 进行操作,可以有效降低 AccessKey 泄露的风险。
已获取表格存储实例的名称和服务地址。具体操作,请参见服务地址。
已将 AccessKey(包括 AccessKey ID 和 AccessKey Secret)、实例名称和实例的服务地址配置到环境变量中。
1. 安装 SDK
在命令行中执行 pip 命令安装表格存储 Python SDK 和 ModelScope 相关依赖。安装命令如下:
# 安装表格存储Python SDK。
pip install tablestore
# 安装ModelScope相关依赖。
pip install "modelscope[framework]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
pip install --use-pep517 "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
pip install torch torchvision torchaudio2. 选择与下载开源模型
2.1 选择开源模型
ModelScope 提供了大量的文本向量 Embedding 模型,您可以通过模型库进行选择。
下表列出了使用频率较高的模型,请根据业务需要进行选择。
如果 ModelScope 生成的向量没有归一化,则在 Tablestore 中可以选择欧式距离作为距离度量算法。
模型ID | 模型领域 | 向量维度 | 推荐距离度量算法 |
damo/nlp_corom_sentence-embedding_chinese-base | 中文-通用领域-base | 768 | 欧氏距离 |
damo/nlp_corom_sentence-embedding_english-base | 英文-通用领域-base | 768 | 欧氏距离 |
damo/nlp_corom_sentence-embedding_chinese-base-ecom | 中文-电商领域-base | 768 | 欧氏距离 |
damo/nlp_corom_sentence-embedding_chinese-base-medical | 中文-医疗领域-base | 768 | 欧氏距离 |
damo/nlp_corom_sentence-embedding_chinese-tiny | 中文-通用领域-tiny | 256 | 欧氏距离 |
damo/nlp_corom_sentence-embedding_english-tiny | 英文-通用领域-tiny | 256 | 欧氏距离 |
damo/nlp_corom_sentence-embedding_chinese-tiny-ecom | 中文-电商领域-tiny | 256 | 欧氏距离 |
damo/nlp_corom_sentence-embedding_chinese-tiny-medical | 中文-医疗领域-tiny | 256 | 欧氏距离 |
2.2 下载开源模型
确定要用的模型后,在命令行中执行 modelscope download --mode {模型 ID}下载所需模型。其中{模型 ID}请根据实际需要进行替换,此处以damo/nlp_corom_sentence-embedding_chinese-tiny模型为例介绍。命令示例如下:
modelscope download --mode damo/nlp_corom_sentence-embedding_chinese-tiny3. 生成向量并写入到表格存储
使用开源模型进行向量生成后,将向量写入到表格存储数据表中。您可以直接写入向量到表格存储中,也可以将表格存储中存量的数据生成向量再写入到表格存储中。
以下示例用于使用 Python SDK 创建表格存储的表和多元索引,然后使用开源模型生成维度为 256 的向量,并写入向量数据到表格存储。
import json
import os
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
from tablestore import OTSClient, TableMeta, TableOptions, ReservedThroughput, CapacityUnit, FieldSchema, FieldType, VectorDataType, VectorOptions, VectorMetricType, \
SearchIndexMeta, AnalyzerType, Row, INF_MIN, INF_MAX, Direction, OTSClientError, OTSServiceError, Condition, RowExistenceExpectation
# 选择合适的模型并填写模型ID
pipeline_se = pipeline(Tasks.sentence_embedding, model='damo/nlp_corom_sentence-embedding_chinese-tiny')
def text_to_vector_string(text: str) -> str:
inputs = {'source_sentence': [text]}
result = pipeline_se(input=inputs)
# 返回结果转成TableStore支持的格式:float32数组字符串,例如: [1, 5.1, 4.7, 0.08]
return json.dumps(result["text_embedding"].tolist()[0])
def create_table():
table_meta = TableMeta(table_name, [('PK_1', 'STRING')])
table_options = TableOptions()
reserved_throughput = ReservedThroughput(CapacityUnit(0, 0))
tablestore_client.create_table(table_meta, table_options, reserved_throughput)
def create_search_index():
index_meta = SearchIndexMeta([
# 支持文本匹配查询
FieldSchema('field_string', FieldType.KEYWORD, index=True, enable_sort_and_agg=True),
# 支持数字范围查询
FieldSchema('field_long', FieldType.LONG, index=True, enable_sort_and_agg=True),
# 全文检索字段
FieldSchema('field_text', FieldType.TEXT, index=True, analyzer=AnalyzerType.MAXWORD),
# 向量检索字段,使用欧氏距离作为度量,向量长度为 256
FieldSchema("field_vector", FieldType.VECTOR,
vector_options=VectorOptions(
data_type=VectorDataType.VD_FLOAT_32,
dimension=256,
metric_type=VectorMetricType.VM_EUCLIDEAN
)),
])
tablestore_client.create_search_index(table_name, index_name, index_meta)
def write_data_to_table():
for i in range(100):
pk = [('PK_1', str(i))]
text = "一段字符串,可用户全文检索。同时该字段生成Embedding向量,写入到下方field_vector字段中进行向量语义相似性查询"
vector = text_to_vector_string(text)
columns = [
('field_string', 'str-%d' % (i % 5)),
('field_long', i),
('field_text', text),
('field_vector', vector),
]
tablestore_client.put_row(table_name, Row(pk, columns))
def get_range_and_update_vector():
# 设置范围读的起始主键,INF_MIN是一个特殊最小值标志位
inclusive_start_primary_key = [('PK_1', INF_MIN)]
# 设置范围读的结束主键,INF_MAX是一个特殊最大值标志位
exclusive_end_primary_key = [('PK_1', INF_MAX)]
total = 0
try:
while True:
consumed, next_start_primary_key, row_list, next_token = tablestore_client.get_range(
table_name,
Direction.FORWARD,
inclusive_start_primary_key,
exclusive_end_primary_key,
["field_text", "想要返回的其它字段"],
5000,
max_version=1,
)
for row in row_list:
total += 1
# 获取读取到的"field_text"字段
text_field_content = row.attribute_columns[0][1]
# 根据"field_text"字段的内容重新生成向量
vector = text_to_vector_string(text_field_content)
update_of_attribute_columns = {
'PUT': [('field_vector', vector)],
}
update_row = Row(row.primary_key, update_of_attribute_columns)
condition = Condition(RowExistenceExpectation.IGNORE)
# 更新该行数据
tablestore_client.update_row(table_name, update_row, condition)
if next_start_primary_key is not None:
inclusive_start_primary_key = next_start_primary_key
else:
break
# 客户端异常,一般为参数错误或者网络异常。
except OTSClientError as e:
print('get row failed, http_status:%d, error_message:%s' % (e.get_http_status(), e.get_error_message()))
# 服务端异常,一般为参数错误或者流控错误。
except OTSServiceError as e:
print('get row failed, http_status:%d, error_code:%s, error_message:%s, request_id:%s' % (e.get_http_status(), e.get_error_code(), e.get_error_message(), e.get_request_id()))
print("一共处理数据:", total)
if __name__ == '__main__':
# 初始化 tablestore client
end_point = os.environ.get('end_point')
access_id = os.environ.get('access_key_id')
access_key_secret = os.environ.get('access_key_secret')
instance_name = os.environ.get('instance_name')
tablestore_client = OTSClient(end_point, access_id, access_key_secret, instance_name)
table_name = "python_demo_table_name"
index_name = "python_demo_index_name"
# 创建表
create_table()
# 创建索引
create_search_index()
# 方式1:直接写入向量数据到TableStore中
write_data_to_table()
# 方式2:将TableStore中存量的数据生成向量再写入到TableStore中
get_range_and_update_vector()
4. 结果验证
在表格存储控制台查看写入表格存储中的向量数据。您可以使用数据读取接口( GetRow、BatchGetRow 和 GetRange)或者使用多元索引的向量检索查询向量数据。
计费说明
使用表格存储时,数据表和多元索引的数据量会占用存储空间,直接读写表中数据和使用多元索引向量检索功能查询数据会消耗计算资源。其中在VCU模式(原预留模式)下,计算资源消耗会按照计算能力计费,在CU模式(原按量模式)下,计算资源消耗会按照读吞吐量和写吞吐量计费。
相关文档
您也可以通过阿里云的大模型服务平台百炼中的模型服务将表格存储中数据转成向量。更多信息,请参见使用云服务将Tablestore数据转成向量。