
本文介绍在使用Spark计算引擎访问表格存储时,如何通过DataFrame编程方式对表格存储中的数据进行批计算,并分别在本地和集群环境中进行运行调试。
准备工作
在表格存储中创建数据表,并写入数据。详情请参见宽表模型快速入门。
说明数据表
search_view的结构及示例数据,请参见附录:示例数据表。为阿里云账号或具有表格存储访问权限的RAM用户创建AccessKey。
搭建Java开发环境。
本文以Windows环境、JDK 1.8、IntelliJ IDEA 2024.1.2 (Community Edition)和Apache Maven为例介绍。
操作步骤
步骤一:下载项目源码
通过Git下载样例项目。
git clone https://github.com/aliyun/tablestore-examples.git如果因为网络问题无法下载,您也可以直接下载tablestore-examples-master.zip。
步骤二:更新Maven依赖
进入
tablestore-spark-demo根目录。说明推荐您阅读
tablestore-spark-demo根目录下的README.md文档,全面了解项目信息。执行以下命令,安装
emr-tablestore-2.2.0-SNAPSHOT.jar到本地Maven仓库。mvn install:install-file -Dfile="libs/emr-tablestore-2.2.0-SNAPSHOT.jar" -DartifactId=emr-tablestore -DgroupId="com.aliyun.emr" -Dversion="2.2.0-SNAPSHOT" -Dpackaging=jar -DgeneratePom=true
步骤三:(可选)修改示例代码
步骤四:运行调试
您可以在本地或者通过Spark集群进行运行调试。此处以TableStoreBatchSample为例介绍调试过程。
本地开发环境
以在Windows操作系统上使用IntelliJ IDEA为例,为您介绍如何调试。
安装Scala插件。
IntelliJ IDEA默认不支持Scala,需要您手动安装Scala插件。
安装winutils.exe(本文使用winutils 3.3.6)。
仅在Windows环境下运行Spark时,还需安装
winutils.exe以解决兼容性问题。您可以通过github项目主页进行下载。在Scala程序
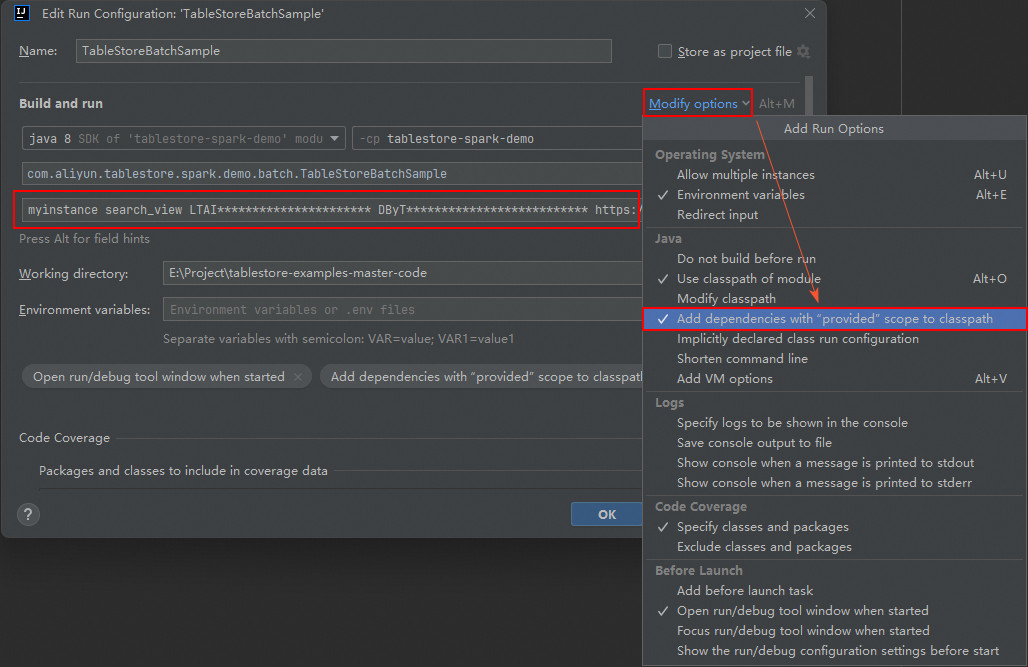
TableStoreBatchSample上右键单击,选择Modify Run Configuration,打开Edit Run Configuration弹窗。说明由于操作系统及IntelliJ IDEA的版本不同,实际操作可能存在一些细微差异。
在Program arguments栏中,依次配置实例名称、数据表名称、AccessKey ID、AccessKey Secret和实例Endpoint参数。
myinstance search_view LTAI********************** DByT************************** https://myinstance.cn-hangzhou.ots.aliyuncs.com单击Modify options,勾选Add dependencies with "provided" scope to classpath选项,并单击OK。
运行Scala程序。
运行结束后,将打印结果到控制台。
With DataFrame +----+------+------------------------------------+-----+-------------+ |salt|UserId|OrderId |price|timestamp | +----+------+------------------------------------+-----+-------------+ |1 |user_A|00002664-9d8b-441b-bad7-845202f3b142|29.6 |1744773183629| |1 |user_A|9d8b7a6c-5e4f-4321-8765-0a9b8c7d6e5f|785.3|1744773190240| +----+------+------------------------------------+-----+-------------+ With Spark SQL +--------+ |count(1)| +--------+ | 2| +--------+ +--------+ |count(1)| +--------+ | 1| +--------+ +--------+ |count(1)| +--------+ | 2| +--------+
Spark集群环境
在进行调试之前,请确保已构建Spark集群,并且该集群环境中的Spark版本与样例项目的Spark版本一致。否则,可能会因版本不兼容而导致运行错误。
以spark-submit方式为例说明。示例代码中的master默认为local[*],在Spark集群上运行时可以去掉,使用spark-submit参数传入。
执行命令
mvn -U clean package对项目进行打包,JAR包的路径为target/tablestore-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar。将JAR包上传到Spark集群的Driver节点,并使用
spark-submit提交任务。spark-submit --class com.aliyun.tablestore.spark.demo.batch.TableStoreBatchSample --master yarn tablestore-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar myinstance search_view LTAI********************** DByT************************** https://myinstance.cn-hangzhou.ots.aliyuncs.com
附录:示例数据表
以下是search_view表的结构及示例数据。
示例表结构
字段名称 | 类型 | 描述 |
pk | long | 主键。 |
salt | long | 随机盐值。 |
UserId | string | 用户ID。 |
OrderId | string | 订单ID。 |
price | double | 订单金额。 |
timestamp | long | 时间戳。 |
示例数据
pk(主键) | salt | UserId | OrderId | price | timestamp |
1 | 1 | user_A | 00002664-9d8b-441b-bad7-845202f3b142 | 29.6 | 1744773183629 |
2 | 1 | user_A | 9d8b7a6c-5e4f-4321-8765-0a9b8c7d6e5f | 785.3 | 1744773190240 |
3 | 2 | user_A | c3d4e5f6-7a8b-4901-8c9d-0a1b2c3d4e5f | 187 | 1744773195579 |
4 | 3 | user_B | f1e2d3c4-b5a6-4789-90ab-123cdef45678 | 11.9 | 1744773203345 |
5 | 4 | user_B | e2f3a4b5-c6d7-4890-9abc-def012345678 | 2547 | 1744773207789 |