
使用Spark的DataFrame方式访问表格存储,并在本地和集群上分别进行运行调试。
前提条件
了解Spark访问表格存储的依赖包,并在使用时通过Maven方式引入项目中。
Spark相关:spark-core、spark-sql、spark-hive
Spark Tablestore connector:emr-tablestore-<version>.jar
Tablestore Java SDK:tablestore-<version>-jar-with-dependencies.jar
其中<version>表示相应依赖包的版本号,请以实际为准。
已在表格存储侧创建Source表和在Source表上创建通道。具体操作,请参见创建数据通道。
已获取AccessKey(包括AccessKey ID和AccessKey Secret)。具体操作,请参见获取AccessKey。
快速开始
通过项目样例了解快速使用流计算的操作。
从GitHub下载项目样例的源码,具体下载路径请参见TableStoreSparkDemo。
项目中包含完整的依赖和使用样例,具体的依赖请参见项目中的pom文件。
阅读TableStoreSparkDemo项目的README文档,并安装最新版的Spark Tablestore connector和Tablestore Java SDK到本地Maven库。
修改Sample代码。
以StructuredTableStoreAggSQLSample为例,对此示例代码的核心代码说明如下:
format("tablestore")表示使用ServiceLoader方式加载Spark Tablestore connector,具体配置请参见项目中的META-INF.services。
instanceName、tableName、tunnel.id、endpoint、accessKeyId、accessKeySecret分别表示表格存储的实例名称、数据表名称、通道ID、实例endpoint、阿里云账号的AccessKey ID和AccessKey Secret。
maxoffsetsperchannel表示每一个mini-batch中每一个channel(分区)最多读取的数据量,默认值为10000。
val ordersDF = sparkSession.readStream .format("tablestore") .option("instance.name", instanceName) .option("table.name", tableName) .option("tunnel.id", tunnelId) .option("endpoint", endpoint) .option("access.key.id", accessKeyId) .option("access.key.secret", accessKeySecret) .option("maxoffsetsperchannel", maxOffsetsPerChannel) //默认值为10000。 .option("catalog", dataCatalog) .load() .createTempView("order_source_stream_view") val dataCatalog: String = s""" |{"columns": { | "UserId": {"type":"string"}, | "OrderId": {"type":"string"}, | "price": {"type":"double"}, | "timestamp": {"type":"long"} | } |}""".stripMargin
运行调试
根据需求修改示例代码后,可在本地或者通过Spark集群进行运行调试。以StructuredTableStoreAggSQLSample为例说明调试过程。
本地调试
以IntelliJ IDEA为例说明。
本文测试使用的环境为Spark 2.4.3、Scala 2.11.7和Java SE Development Kit 8,如果使用中遇到问题,请联系表格存储技术支持。
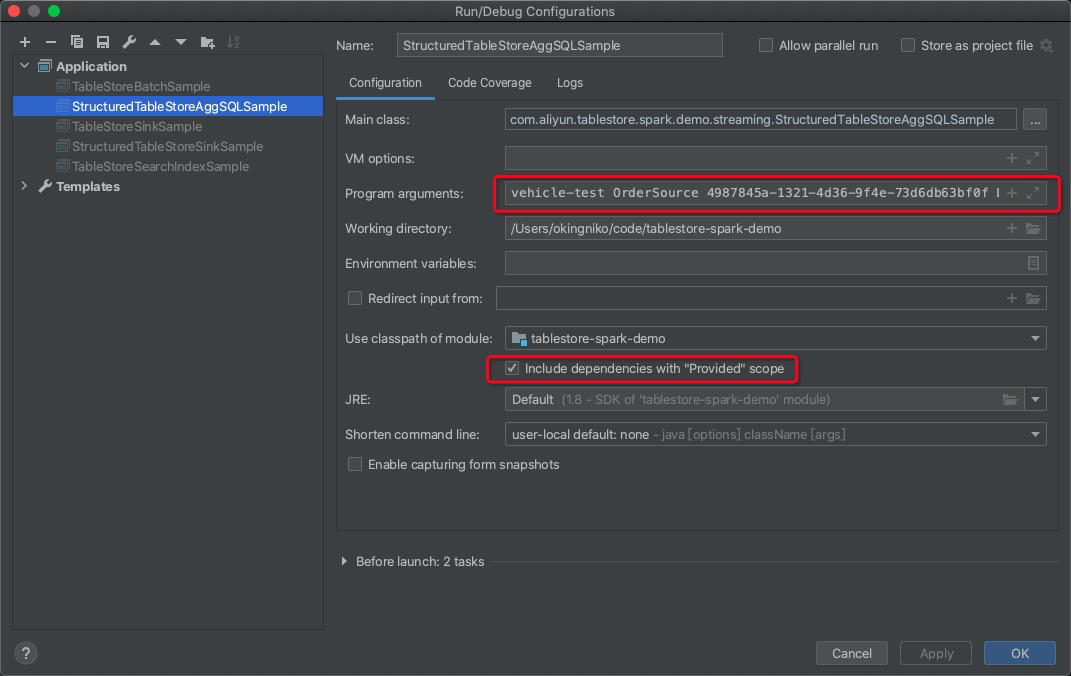
在系统参数中,配置实例名称、数据表名称、实例endpoint、阿里云账号的AccessKey ID和AccessKey Secret等参数。
您也可以自定义参数的加载方式。
选择include dependencies with "provided" scope,单击OK。
运行示例代码程序。
通过Spark集群调试
以spark-submit方式为例说明。示例代码中的master默认为
local[*],在Spark集群上运行时可以去掉,使用spark-submit参数传入。执行mvn -U clean package命令打包,包的路径为
target/tablestore-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar。上传包到Spark集群的Driver节点,并使用spark-submit提交任务。
spark-submit --class com.aliyun.tablestore.spark.demo.streaming.StructuredTableStoreAggSQLSample --master yarn tablestore-spark-demo-1.0-SNAPSHOT-jar-with-dependencies.jar <ots-instanceName> <ots-tableName> <ots-tunnelId> <access-key-id> <access-key-secret> <ots-endpoint> <max-offsets-per-channel>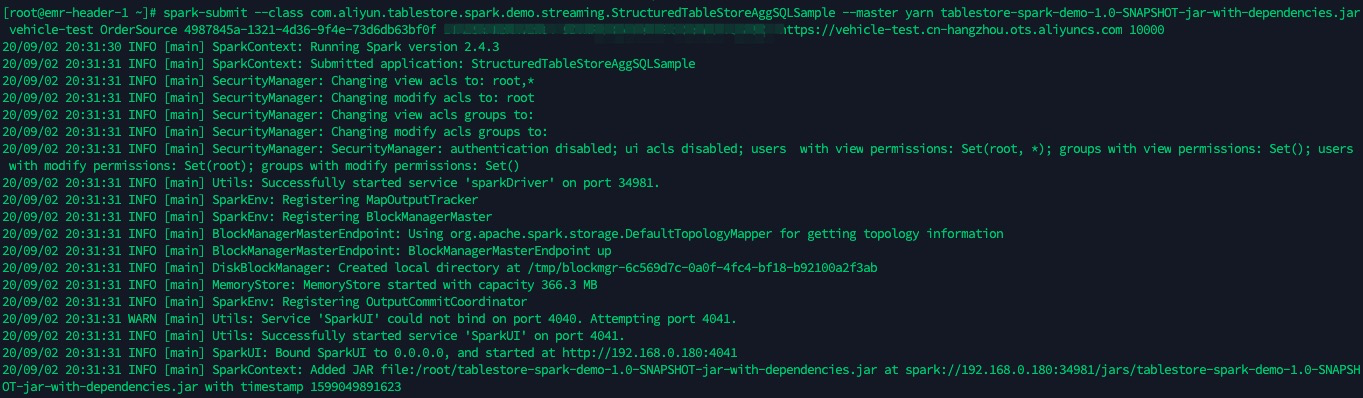
- 本页导读 (1)
- 前提条件
- 快速开始
- 运行调试
