TableStoreWriter是表格存储Java SDK提供的工具类,封装了用于高并发、高吞吐率数据导入的接口,可以实现高并发写入数据到表格存储数据表,同时支持行级别回调以及自定义配置功能。
背景说明
TableStoreWriter只适用于宽表模型。
为什么需要TableStoreWriter
在日志、物联网(例如轨迹追踪或溯源)等场景中,设备会在短时间内产生大量的数据并且用户需要将设备数据写入到数据库,因此数据库需要能够提供高并发、高吞吐率的写入性能,并满足每秒上万行甚至上百万行的写入吞吐率,而表格存储的BatchWriteRow接口限制单次只能写入200行数据。
TableStoreWriter解决了什么问题
基于上述场景的高并发写入需求,表格存储提供了一个基于表格存储Java SDK实现的简单易用、高性能的数据导入工具类TableStoreWriter。它封装了用于高并发、高吞吐率数据导入的接口,可以实现高并发写入数据到表格存储数据表。同时支持行级别回调以及自定义配置功能。
应用场景
如果您的业务场景同时具备以下特点,则您可以使用TableStoreWriter写入数据到表格存储中。
高并发,对吞吐率要求很高
对单条数据的写入延迟没有要求
写入可异步化(可采用生产者消费者模型)
同一条数据可重复写入
典型的应用场景如下:
日志存储
日志存储具有海量数据存储、高吞吐率、可异步化处理等特点,可以使用TableStoreWriter实现高并发、高吞吐数据写入,并且重复写入不会影响日志数据的正确性。
消息系统
消息系统,例如即时通讯,需要支持海量消息处理(例如群聊消息的写入放大),要求高吞吐率,而且对单条消息的延迟容忍度较高,可接受百毫秒级的延时。消息处理可以完全异步进行,此外,由于每条消息都带有唯一ID且内容不可更改,因此支持重复写入而不引发问题。在消息系统中使用表格存储进行数据存储时,您可以通过TableStoreWriter快速写入数据到表格存储中。
分布式队列消费
分布式队列在复杂的分布式系统中应用广泛,不仅提供高性能的消息传递,还能解耦模块间的依赖,简化系统架构。
如果您的业务架构中使用了分布式队列,并且其中一个消费者任务是将数据导入到表格存储,那么可以考虑采用TableStoreWriter。TableStoreWriter基于生产者-消费者模型,适用于与分布式队列类似的场景。
架构详解
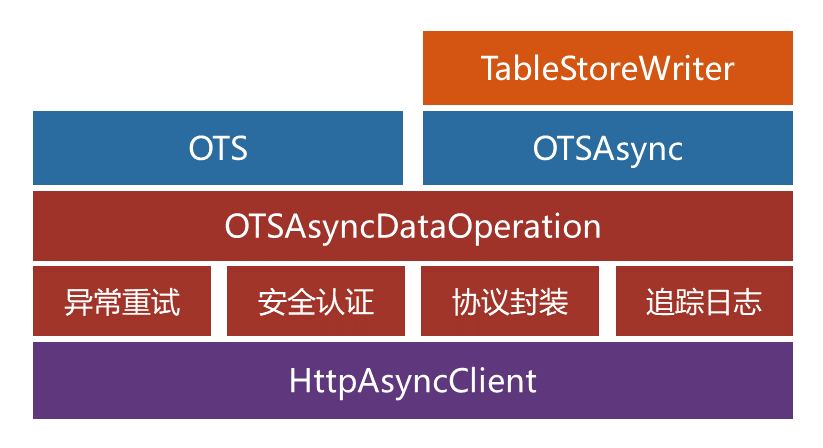
TableStoreWriter是基于SDK处理层接口重新封装的工具类,它与表格存储Java SDK的关系如下:
TableStoreWriter依赖表格存储Java SDK提供的AsyncClient异步接口。
TableStoreWriter导入数据使用表格存储Java SDK的BatchWriteRow接口。
TableStoreWriter的单行异常重试依赖表格存储Java SDK的RetryStrategy。
代码分层架构如下图所示。
TableStoreWriter实现和封装细节如下图所示。您也可以使用表格存储Java SDK原有的接口实现数据写入,但TableStoreWriter在接口性能和易用性上都做了优化,具备以下特性:
使用异步接口:使用更少的线程,提供更高的并发。
自动数据聚合:在内存中使用缓冲队列,让一次发给表格存储的批量写请求尽量大,提高写入吞吐率。
采用生产者消费者模式:更易于异步化和数据聚集。
使用高性能数据交换队列:选用Disruptor RingBuffer,采用多生产者单消费者的模型,提供更好的性能。
屏蔽复杂请求封装:屏蔽调用BatchWriteRow接口细节,通过预检查自动过滤脏数据(例如主键格式与表预定义的不符、行大小超限、行列数超限等),自动处理请求限制(例如一次批量的行数限制、一次批量的大小限制等)。
行级别Callback:相对于表格存储Java SDK提供的请求级别的Callback,TableStoreWriter提供行级别的Callback,让业务逻辑可以实现行级别数据处理。
行级别重试:请求级别重试失败会根据特定的错误码进行行级别重试,最大程度保证数据写入成功率。

后续操作
如果您想体验TableStoreWriter,请参考示例使用TableStoreWriter并发写入数据。