
本文为您介绍使用表格存储和Flink实现交易数据实时统计的样例场景、架构设计和实现方案。
背景信息
在金融市场、电子商务和支付系统等领域,交易数据的实时统计具有重要的意义。它不仅能够提供精准的数据分析结果,帮助用户及时掌握业务动态并优化运营策略,同时也为风险管理、市场趋势的预测等提供了可靠的参考依据。
阿里云实时计算Flink版是一套基于Apache Flink构建的一站式实时大数据分析平台,提供端到端亚秒级实时数据分析能力,并通过标准SQL降低业务开发门槛,助力企业向实时化、智能化大数据计算升级转型。
表格存储(Tablestore)是阿里云自研的多模型结构化数据存储,可提供海量结构化数据的存储和查询分析服务。表格存储的分布式存储和强大的索引引擎能够支持PB级存储、千万TPS以及毫秒级延迟的服务能力。
表格存储通道服务(Tunnel Service)是基于表格存储数据接口上的全增量一体化服务。在为数据表建立数据通道后,可以通过流式计算的方式对表中历史存量和新增数据进行消费处理。
样例场景
某电商网站产生了海量的交易数据,通过对这些数据进行实时统计与分析,能够帮助用户实时监测网站的整体销售状况,并迅速评估“新销售策略”的效果。
架构设计
样例场景的实现过程说明如下。
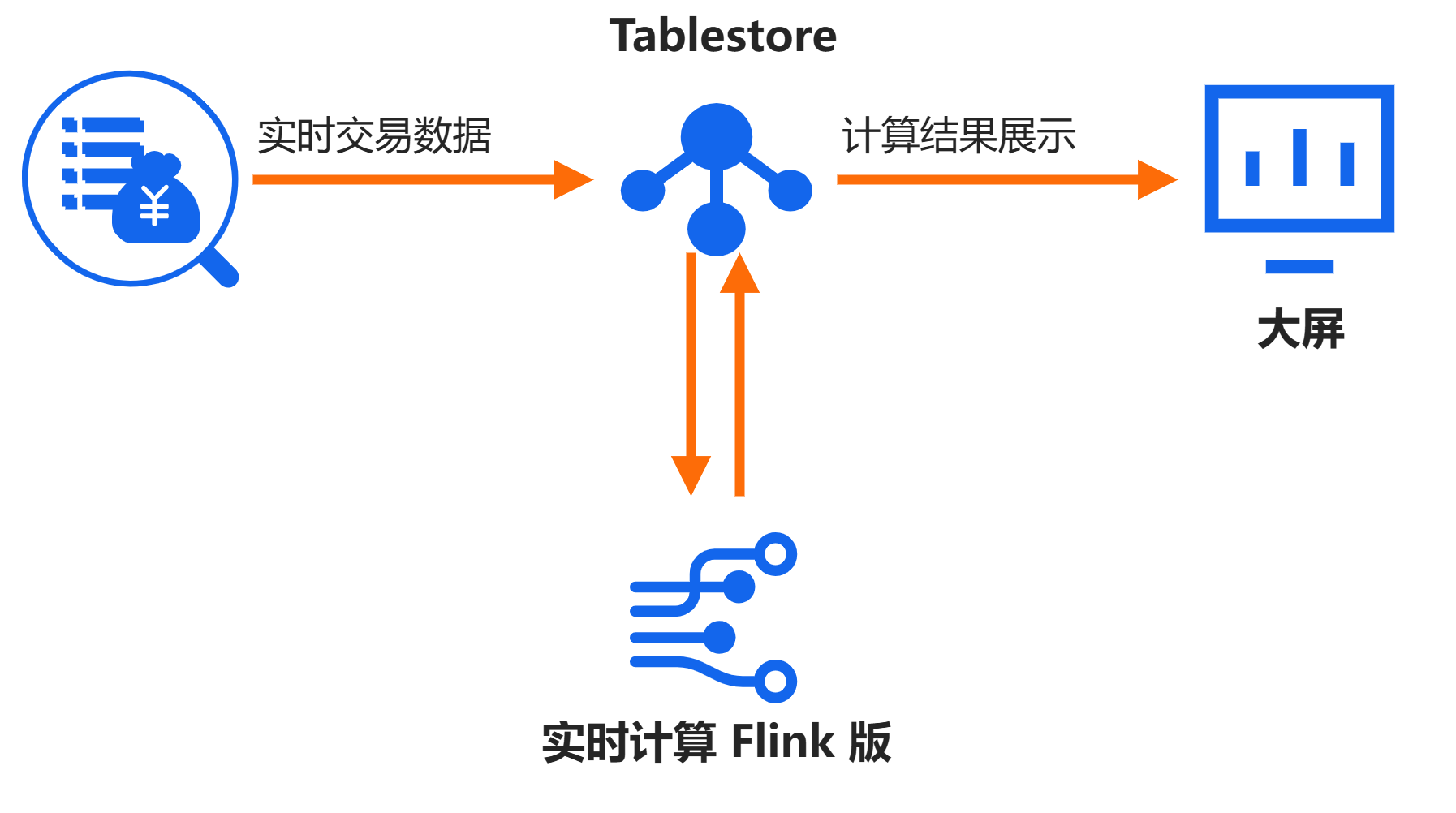
将电商网站的实时交易数据写入Tablestore的Source表后,使用Flink对Source表数据通道的流式数据进行聚合计算,并将计算结果重新写入Tablestore的Sink表,最终通过“大屏”实时展示计算结果。具体实现只需3步:
创建数据表和数据通道:在表格存储中创建源表和结果表,并为源表创建数据通道。
创建并启动Flink作业:在Flink中通过流作业对源表数据通道的流式数据进行聚合计算,并将结果写入结果表。
压入测试数据并实时获取计算结果:部署
stream-compute服务,模拟写入交易数据后,实时展示计算结果。说明本文将计算结果直接输出至控制台。您也可以在DataV中添加Tablestore数据源,在DataV的大屏上展示实时数据。更多信息,请参见对接DataV-Board 7.0。
架构图如下图所示。
准备工作
已开通表格存储服务并创建实例。具体操作,请参见开通服务并创建实例。
已开通实时计算Flink版。具体操作,请参见开通实时计算Flink版。
重要实时计算Flink必须与表格存储服务位于同一地域。实时计算Flink支持的地域,请参见地域列表。
已准备带有Linux系统的服务器,并开启公网访问。本文以Alibaba Cloud Linux 3为例进行操作说明。
已获取AccessKey信息。
重要出于安全考虑,强烈建议您通过RAM用户使用表格存储功能。具体操作,请参见创建RAM用户并授权。
方案实现
步骤一:在表格存储中创建数据表和数据通道
1. 创建数据表
2. 创建数据通道
为source_order表(源表)创建数据通道。具体操作,请参见创建数据通道。
数据通道的配置信息,请参见下表。
参数 | 示例 | 说明 |
通道名 | flink_agg | 数据通道名称。 |
通道类型 | 全量加增量 | 数据通道类型,通道服务提供了增量、全量、全量加增量三种类型的分布式数据实时消费通道。 |
步骤二:在实时计算Flink中创建作业并启动
1. 创建作业
 图标,新建子文件夹。
图标,新建子文件夹。2. 编写SQL作业
分别创建
source_order表(源表)和sink_order表(结果表)的临时表。详细配置信息,请参见附录1:Tablestore连接器。
-- 创建源表的临时表 CREATE TEMPORARY TABLE tablestore_input ( metering VARCHAR, orderid VARCHAR, price DOUBLE, byerid BIGINT, sellerid BIGINT, productid BIGINT, ts BIGINT, ptime AS TO_TIMESTAMP( ts * 1000), WATERMARK FOR ptime AS ptime - INTERVAL '2' SECOND ) WITH ( 'connector' = 'ots', -- 源表的连接器类型。固定取值为ots。 'endPoint' = 'https://xxx.cn-hangzhou.vpc.tablestore.aliyuncs.com', -- 表格存储实例的VPC地址。 'instanceName' = 'xxx', -- 表格存储的实例名称。 'tableName' = 'source_order', -- 表格存储的源表名称。 'tunnelName' = 'flink_agg', -- 表格存储源表的数据通道名称。 'accessId' = 'xxxxxxxxxxx', -- 阿里云账号或者RAM用户的AccessKey ID。 'accessKey' = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxx' -- 阿里云账号或者RAM用户的AccessKey Secret。 ); -- 创建结果表的临时表 CREATE TEMPORARY TABLE tablestore_output ( metering VARCHAR, ts BIGINT, price DOUBLE, ordercount BIGINT, primary key(metering, ts) NOT ENFORCED -- 主键。 ) WITH ( 'connector' = 'ots', -- 结果表的连接器类型。固定取值为ots。 'endPoint' = 'https://xxx.cn-hangzhou.vpc.tablestore.aliyuncs.com', -- 表格存储实例的VPC地址。 'instanceName' = 'xxx', -- 表格存储的实例名称。 'tableName' = 'sink_order', -- 表格存储的结果表名称。 'accessId' = 'xxxxxxxxxxx', -- 阿里云账号或者RAM用户的AccessKey ID。 'accessKey' = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxx', -- 阿里云账号或者RAM用户的AccessKey Secret。 'valueColumns' = 'price,ordercount' --插入字段的列名。 );编写作业逻辑。
INSERT INTO tablestore_output SELECT DISTINCT metering as metering, UNIX_TIMESTAMP(CAST(TUMBLE_START(ptime, INTERVAL '5' SECOND) as STRING)) as ts, SUM(price) as price, COUNT(orderid) as ordercount FROM tablestore_input GROUP BY TUMBLE(ptime, INTERVAL '5' SECOND), metering;
3. 部署作业
在SQL编辑区域右上方,单击部署,在部署新版本对话框,可根据需要填写或选中相关内容,单击确定。
Session集群适用于非生产环境的开发测试环境,通过部署或调试作业提高作业JM(Job Manager)资源利用率和提高作业启动速度。但不推荐您将生产作业提交至Session集群中,可能会导致业务稳定性问题。
4. 启动作业
步骤三:压入测试数据并实时获取计算结果
1. 安装依赖
登录至Linux系统的服务器,执行以下命令安装JDK(1.8及以上,推荐1.8)。
yum -y install java-1.8.0-openjdk-devel.x86_642. 部署stream-compute服务
下载
stream-compute压缩包。具体下载路径,请参见stream-compute-1.0-SNAPSHOT-release.tar.gz。
说明如果您需要自行编译
stream-compute,请参见GitHub源码。将
stream-compute压缩包上传到服务器,并执行如下命令进行解压。tar -zxvf stream-compute-1.0-SNAPSHOT-release.tar.gz编辑配置文件。
执行以下命令创建配置文件。
vim ~/tablestoreConf.json配置文件示例如下。
{ "endpoint":"https://xxx.cn-hangzhou.ots.aliyuncs.com", "accessId":"xxxxxxxxxxx", "accessKey":"xxxxxxxxxxxxxxxxxxxxxxxxxxxx", "instanceName":"xxx" }详细配置项请参见下表。
配置项
说明
endpoint
表格存储实例的服务地址。更多信息,请参见服务地址。
如果使用自建Linux服务器,需填写公网地址。
如果使用云服务器ECS并且与Tablestore处于同一专有网络VPC,推荐VPC地址。
instanceName
表格存储的实例名称。
accessId
阿里云账号或者RAM用户的AccessKey(包括AccessKey ID和AccessKey Secret)。
accessKey
3. 启动压力器和模拟大屏
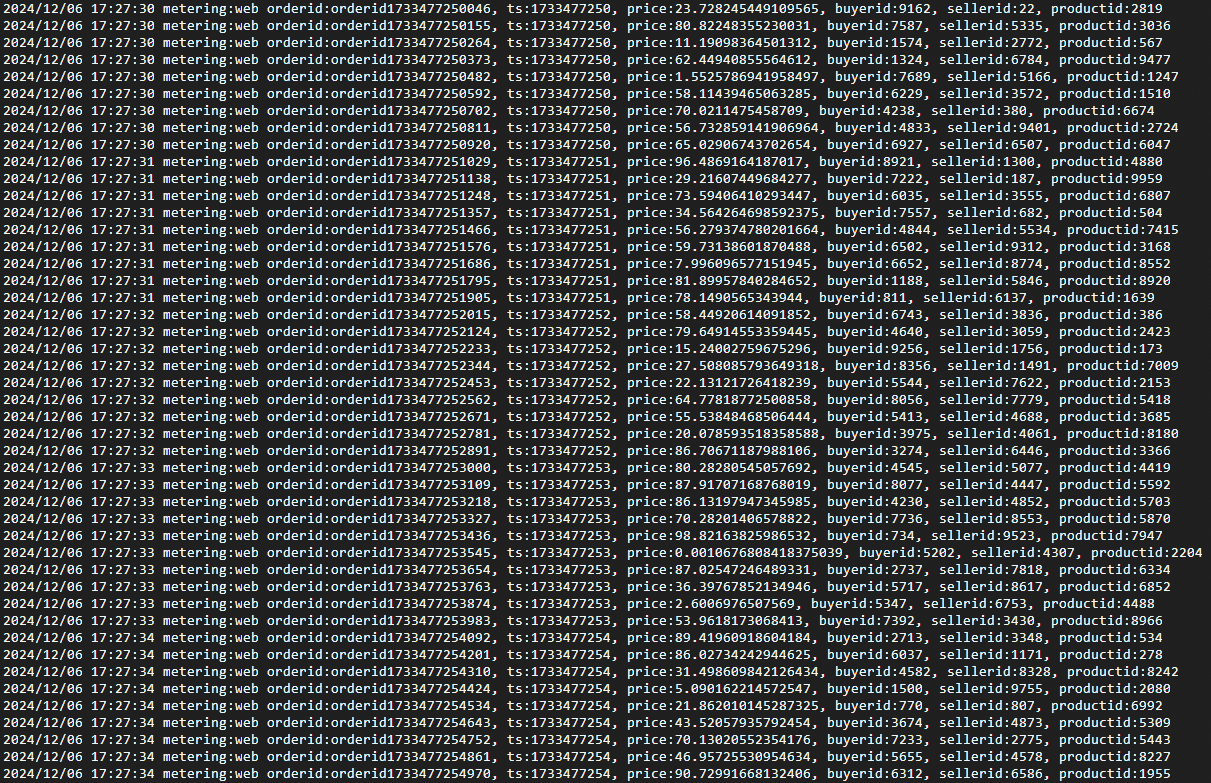
启动压力器,模拟写入大量交易数据。
./bin/mock_order_generator压力器启动成功的示例如下图所示,其中每一行数据代表一条交易记录。
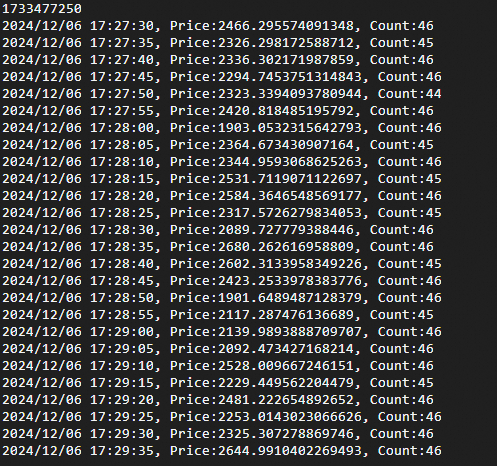
新建窗口后,启动模拟大屏,实时查看计算结果。
./bin/data_show_screen模拟大屏启动成功的示例如下图所示。Flink每隔5秒对交易数据进行一次聚合计算,图中数据代表该时间段内的交易总金额和订单数量。
附录:示例表结构
源表
源表为原始数据表,存储了所有的交易记录,主要包含字段:计量类型、订单号ID、交易时间、交易金额、买家ID、卖家ID和商品ID等。表设计如下:
表名:source_order
字段 | 类型 | 注释 |
metering | String | 计量类型(主键)。样例中默认是web。 |
orderid | String | 订单号ID(主键)。 |
ts | Integer | 交易时间。Unix时间戳,精度为秒。 |
price | Double | 交易金额。 |
buyerid | Integer | 买家ID。 |
sellerid | Integer | 卖家ID。 |
productid | Integer | 商品ID。 |
结果表
结果表存储了聚合计算后的结果数据,主要包含字段:计量类型、交易时间、交易金额和交易次数。表设计如下:
表名:sink_order
字段 | 类型 | 注释 |
metering | String | 计量类型(主键)。样例中默认是web。 |
ts | Integer | 交易时间(主键)。Unix时间戳,精度为秒。 |
price | Double | 交易金额。 |
ordercount | Integer | 交易次数。 |