您可以根据业务的读写需求选择使用阿里云Elasticsearch内核增强版Indexing Service系列,通过其云上写入托管能力,体验按需购买、按量付费的低成本、高性能的时序日志场景下的Elasticsearch服务。本文主要介绍Indexing Service的适用场景、架构、优势以及性能测试结果。
基于读写分离架构的内核增强版Indexing Service,不仅实现了Elasticsearch集群的云端写入Indexing Service托管,还从硬件选型、集群架构、内核性能进行了全方位优化。在提升集群写入性能的同时,您可以从读写角度分别评估业务需求,根据实际写入按量付费,而无须按照集群峰值写入吞吐预留资源,大大降低了云上使用Elasticsearch的资源成本和运维成本。
适用场景
适用于写入TPS较高、写入流量波动较大和搜索QPS较低的时序数据分析场景,例如日志检索分析、Metric监控分析、IoT智能硬件数据收集及监控分析等。
Indexing Service内核增强版实例与用户集群进行数据同步时,依赖于apack/cube/metadata/sync任务(可通过GET _cat/tasks?v命令获取该任务信息),不建议手动清理该任务。如果被清理,请尽快使用POST /_cube/meta/sync命令恢复,否则会影响业务写入。
架构
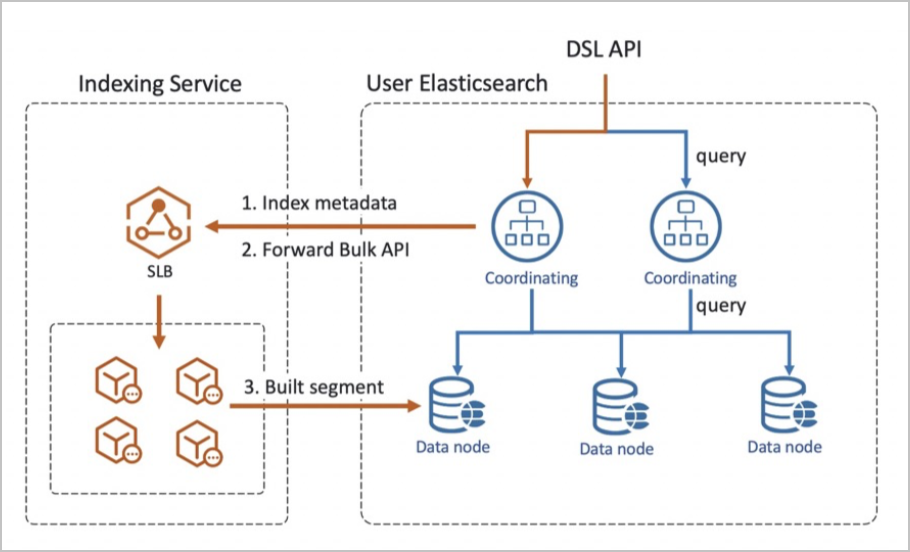
此架构具备如下优势:
高性能:专业级写入优化,Indexing Service索引构建服务通过索引物理复制、计算存储分离、faster-bulk等阿里云自研特性优化写入性能,您无需做任何配置变更即可享受专业级写入性能。
低延迟:跨集群实时物理复制,通过segment级别的实时物理复制,在写入流量饱和的情况下,用户集群相对于Indexing Service集群的平均数据延迟达到百毫秒级。
高稳定:异地容灾,Indexing Service具备异地多集群备份能力。当某一个集群出现异常时,可切换用户集群的索引托管至另一个正常集群,进一步提升写入高可用性。
费用说明
Indexing Service索引构建服务会收取写入托管(写入流量和托管存储空间)的费用。
无论ES实例的付费模式是包年包月还是按量付费,写入托管费用按实际写入流量和实际托管存储空间进行按量计费。详情请参见阿里云ES计费。
虽然开启Indexing Service索引构建服务会收取写入托管费用,但该服务会降低集群中用于承载写入计算的节点资源的费用。
优势
低成本:写入计算资源成本平均降低了60% 。
弹性扩展:写入资源由云端Indexing Service后台调配和管理,以应对写入流量波动。在无需数据迁移的情况下,实现日志场景下Elasticsearch集群的写入弹性扩展能力,轻松应对高峰流量。
免运维:用户无须关注Elasticsearch集群的写入资源和写入压力,由Indexing Service实现云上写入托管,极大降低集群运维成本。
使用限制
云端托管功能可以为您创建的Elasticsearch集群提供写入Serverless服务,但是在使用时,对数据写入和索引配置有相关限制。详情请参见下表。
分类 | 限制项 | 限制说明 | 备注 |
实例维度 | 写入流量保护 | 写入流量最大为200 MB/s | 如果超过最大限制,返回状态码429,提示Inflow Quota Exceed。如果您有更大的使用需求,请提交工单申请。 |
写入文档数保护 | 写入文档保护数最大为200000 个/秒 | 如果超过最大限制,返回状态码429,提示Write QPS Exceed。如果您有更大的使用需求,请提交工单申请。 | |
Put Mapping限流保护 | Put Mapping最大为50 tps/s | 如果超过最大限制,返回状态码429,提示 说明 频繁的Put Mapping将消耗大量的计算资源,对托管服务稳定性影响极大。建议您写数据前提前定义索引模板,降低Put Mapping操作。 | |
Shard维度 | 写入流量 | 不带主键写入流量最大为10 MB/s 带主键写入流量最大为5 MB/s | 如果超过最大限制,返回状态码429,提示 |
写入文档数 | 写入文档数最大为5000 个/秒 | 非硬性限制,如果超过最大限制,系统会尽可能服务,但不能保证服务质量。 | |
Shard数 | 单个索引最多可创建的Shard数 | 最多可创建300个Shard。 | 无。 |
配置 | index.refresh_interval | 云端托管集群中默认配置此参数,用户侧配置不生效。 | 无。 |
index.translog.durability | translog在云端托管集群中默认配置为异步写入模式(index.translog.durability=async),用户侧配置不生效。 | 无。 | |
refresh、merge等写入参数 | 云端托管集群中默认已配置refresh、merge等写入参数,用户侧配置不生效。 | 默认配置如下。 | |
索引 | 生命周期配置 | 不支持在索引生命周期中自定义freeze。 | 无。 |
shrink操作 | Indexing Service场景,索引处于托管状态,不兼容ILM Action中的shrink操作,建议当索引处于未托管状态时,执行shrink配置。详细信息,请参见ILM-shrink。 | 无。 | |
取消托管时间 | 索引默认托管3天后自动取消托管。 | 可依据业务数据在生命周期中修改取消托管时间。 | |
Ingest Node |
| ||
性能测试
测试环境:
测试结果:
规格
实例版本
写入TPS
写入可见性延迟
3个数据节点的2核8 GB
通用商业版
24883
5秒
内核增强版Indexing Service
226649
6秒
3个数据节点的4核16 GB
通用商业版
52372
5秒
内核增强版Indexing Service
419574
6秒
3个数据节点的8核32 GB
通用商业版
110277
5秒
内核增强版Indexing Service
804010
6秒
测试结论:
内核增强版Indexing Service与通用商业版性能对比结果:
基于3个数据节点的2核8 GB规格,性能提升了910%。
基于3个数据节点的4核16 GB规格,性能提升了801%。
基于3个数据节点的8核32 GB规格,性能提升了729%。
相关文档
- 本页导读 (1)