批量计算(BatchCompute)是一种适用于大规模并行批处理作业的分布式云服务。BatchCompute可支持海量作业并发规模,系统自动完成资源管理,作业调度和数据加载,并按实际使用量计费。
如果还没有开通批量计算,请参见开通服务。
2. 创建 OSS Bucket
如果还没有开通OSS,请先开通OSS。
方法如下:
登录阿里云首页->开放存储服务 OSS -> 管理控制台 -> 新建Bucket 。
具体请参考创建bucket。
3. 作业准备
本作业采用 Python 语言编写,目的是找出给定三份数据里的所有质数并进行排序输出。
该作业包含两个任务:Find 任务和 Sort 任务。其中,Find 任务会并行运行 3 个实例,每个实例寻找一份数据文件中的质数,然后将结果存到 OSS 中。Sort 任务只有一个实例,即从 OSS 中读出 Find 任务寻找出来的质数并进行排序, 最后再输出到 OSS 中。
(1) 存储输入文件
本作业需输入三份数据文件下载:data.tar,本例中上传至OSS的路径分别如下:
oss://your-bucket/find-prime/input-data-0.txt
oss://your-bucket/find-prime/input-data-1.txt
oss://your-bucket/find-prime/input-data-2.txtyour-bucket如上文所示创建,如要运行本例子,请改成您自己在OSS上创建的bucket,并创建自己的OSS路径,并且把三份数据文件上传至您自己创建的bucket的路径下。如何上传到OSS,请参考OSS文件上传。
注意:存储作业数据和作业任务的 OSS bucket 必须保持与 BatchCompute 的用户名及region一致。
(2) 编写作业任务
Find 任务和 Sort 任务的 Python 代码下载:Find_Sort.tar。
如要运行本例子,请按照上文所述创建的您的bucket路径,填入以下参数:
Find.py
ACCESS_KEY_ID: AccessKeyId可以由上文所述获取
ACCESS_KEY_SECRET: AccessKeySecret可以由上文所述获取
BUCKET: 存储输入输出文件的bucket(注意:不包含"oss://")
FIND_INPUT_PATH: 输入文件在bucket下的路径
FIND_OUTPUT_PATH: 输出文件在bucket下的路径Sort.py
ACCESS_KEY_ID: AccessKeyId可以由上文所述获取
ACCESS_KEY_SECRET: AccessKeySecret可以由上文所述获取
BUCKET: 存储输入输出文件的bucket(注意:不包含"oss://")
SORT_INPUT_PATH: 输入文件在bucket下的路径
SORT_OUTPUT_PATH: 输出文件在bucket下的路径BatchCompute为任务程序提供的环境变量: 环境变量。
(3) 打包上传
将编写完成的 Find.py、Sort.py 和准备好的 OSS 的 Python SDK 开发包 中的.py子文件打成一个压缩包, 打包命令如下:
> tar -czf worker.tar.gz *运行以下命令,查看内容是否正确:
> tar -tvf worker.tar.gz
Find.py
Sort.py
__init__.py
oss_api.py
oss_fs.py
oss_sample.py
oss_util.py
oss_xml_handler.py
pkg_info.py本例将 worker.tar.gz 上传到 OSS 的 your-bucket 中, object 名字为find-prime/worker.tar.gz。
OSS 全路径为oss://your-bucket/find-prime/worker.tar。
4. 使用控制台提交作业
然后点击左侧导航栏“提交作业”进行作业提交。请注意选择合适Region。
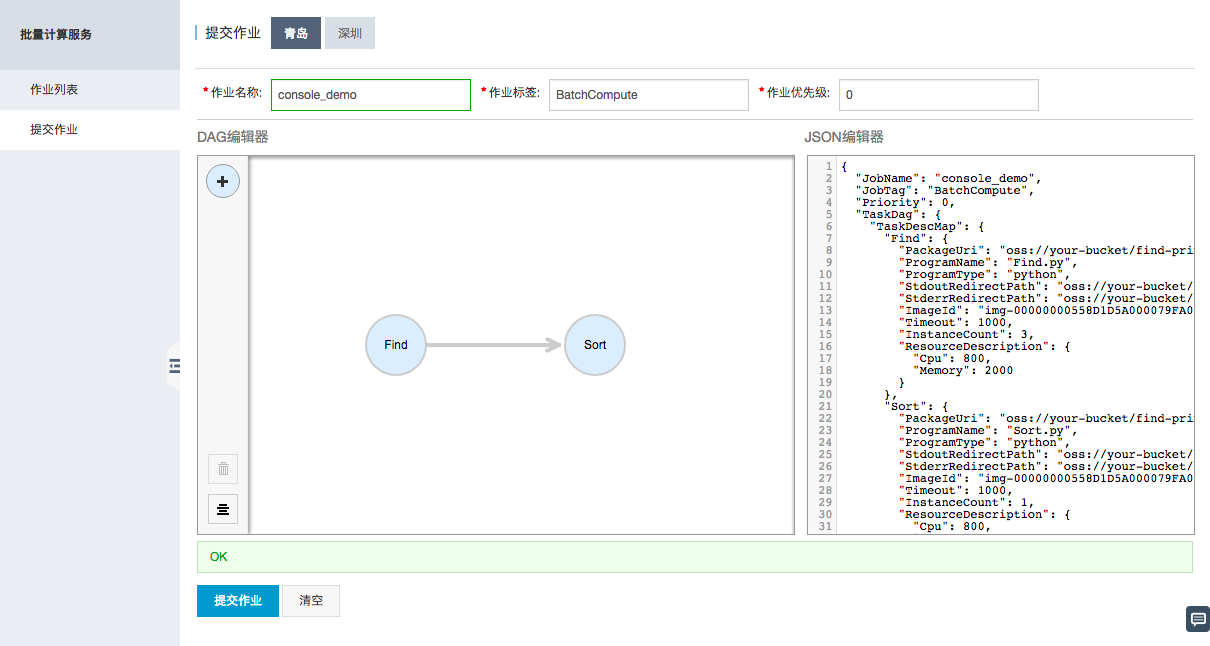
如果需要运行本例子,请把 PackageUri (作业打包上传的OSS路径),本例子中为 worker.tar.gz;StdoutRedirectPath、StderrRedirectPath(任务结果和错误的输出地址),修改成与上文对应的您的OSS路径。
作业JSON模板如下,具体参数含义请参照创建作业。
{
"JobName": "console_demo",
"JobTag": "BatchCompute",
"Priority": 0,
"TaskDag": {
"TaskDescMap": {
"Find": {
"PackageUri":
"oss://your-bucket/find-prime/worker.tar.gz",
"ProgramName": "Find.py",
"ProgramType": "python",
"StdoutRedirectPath": "oss://your-bucket/find-prime/logs",
"StderrRedirectPath": "oss://your-bucket/find-prime/logs",
"ImageId": "img-00000000558D1D5A000079FA0000001F",
"Timeout": 1000,
"InstanceCount": 3,
"ResourceDescription": {
"Cpu": 800,
"Memory": 2000
}
},
"Sort": {
"PackageUri":
"oss://your-bucket/find-prime/worker.tar.gz",
"ProgramName": "Sort.py",
"ProgramType": "python",
"StdoutRedirectPath": "oss://your-bucket/find-prime/logs",
"StderrRedirectPath": "oss://your-bucket/find-prime/logs",
"ImageId": "img-00000000558D1D5A000079FA0000001F",
"Timeout": 1000,
"InstanceCount": 1,
"ResourceDescription": {
"Cpu": 800,
"Memory": 2000
}
}
},
"Dependencies": {
"Find": [
"Sort"
]
}
}
}确定各个参数及路径填写正确后,点击左下角的“提交作业”,并确认。
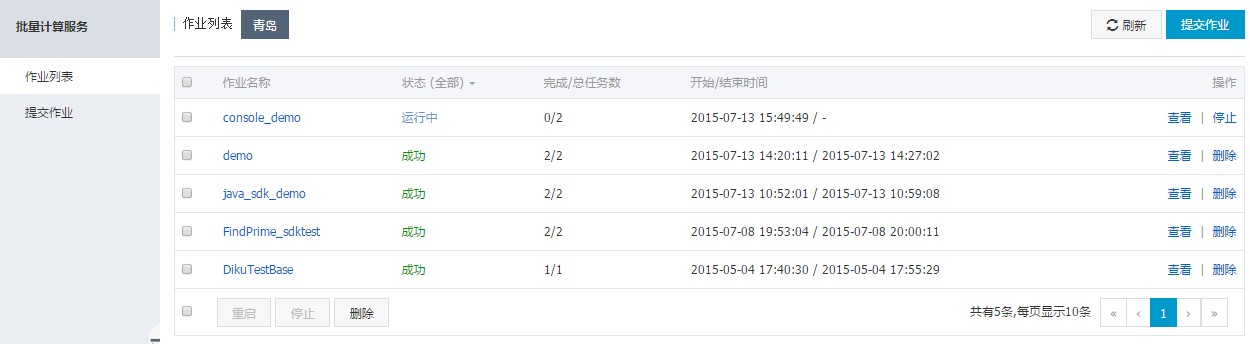
5. 查询作业状态
提交作业后,页面将会自动跳转至控制台作业列表,列表第一列将会显示最新提交成功的作业。
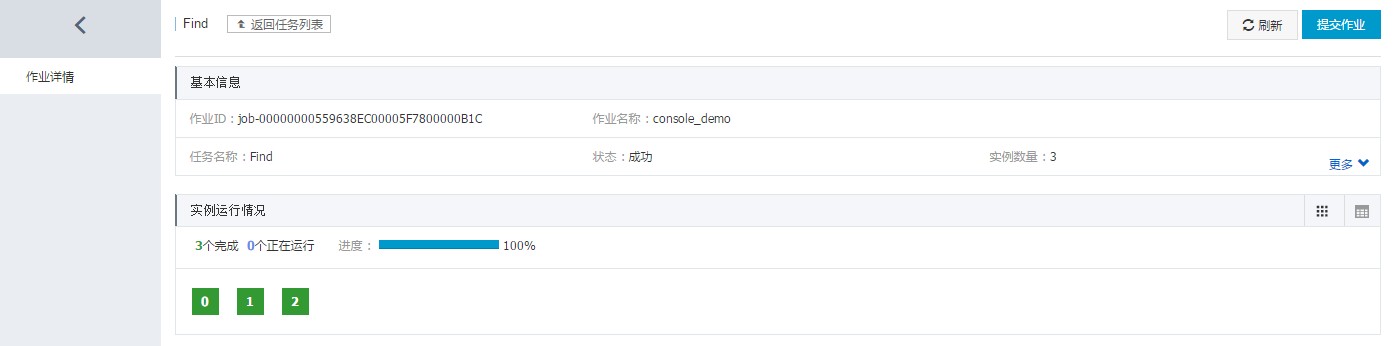
通过点击作业名称或者右侧“查看”选项,你可以看到作业的基本信息和任务运行情况。
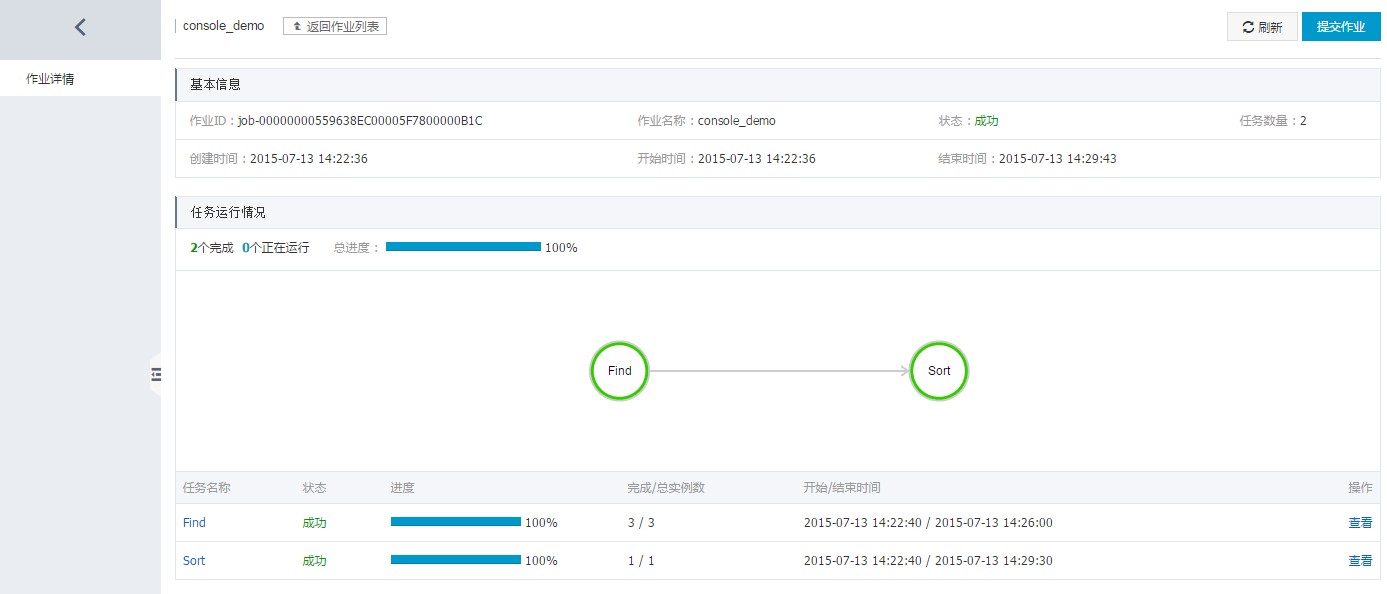
点击任务名称或者右侧“查看”选项,还可以看到任务的基本信息和实例运行情况。其中,左下部为实例编号,将鼠标悬置于各个编号上方,可以看到各个实例详情,并且可以下载实例运行日志。
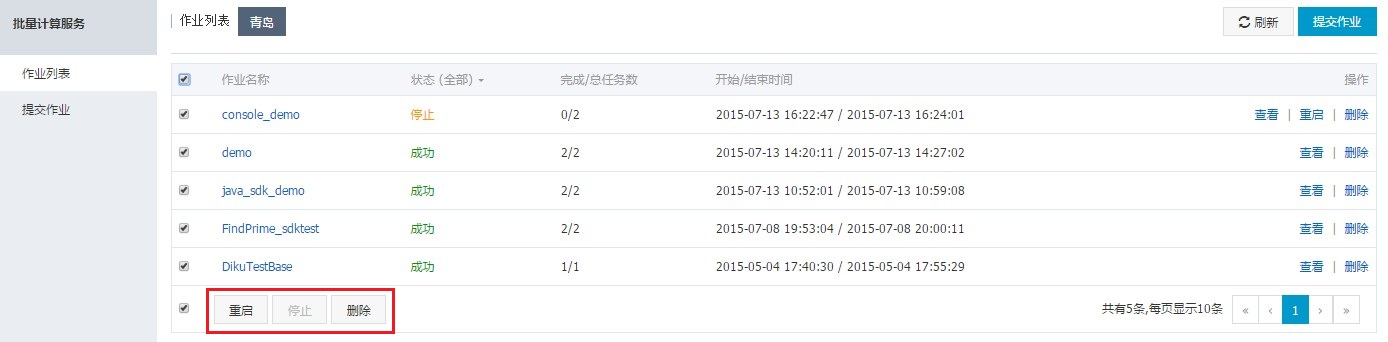
6. 管理作业
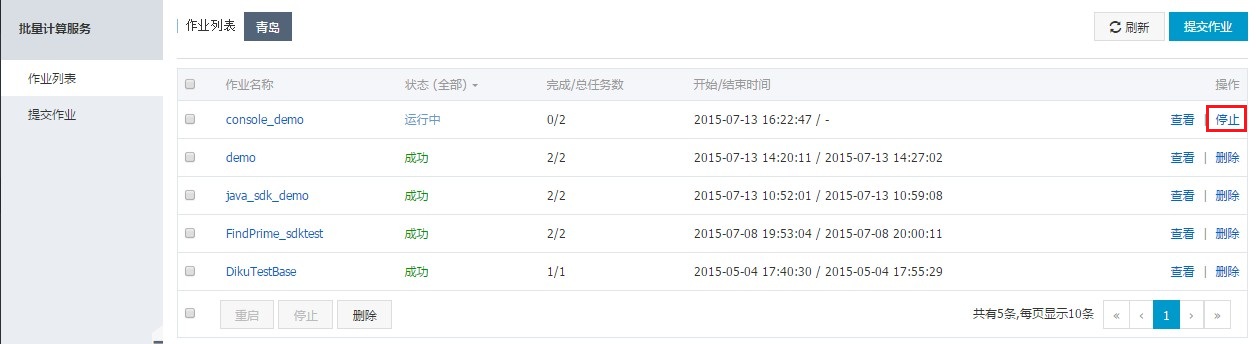
作业提交成功后,作业为“等待中”或“运行”状态时,如果有需要可以点击右边的“停止”,之后也可以进行“重启”。
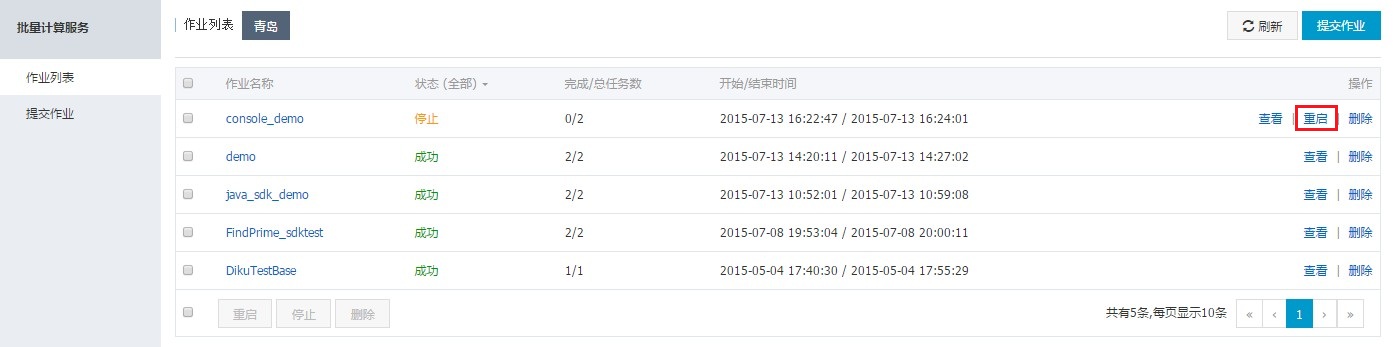
当作业状态为“停止”、“成功”或“失败”时,可以进行删除操作。
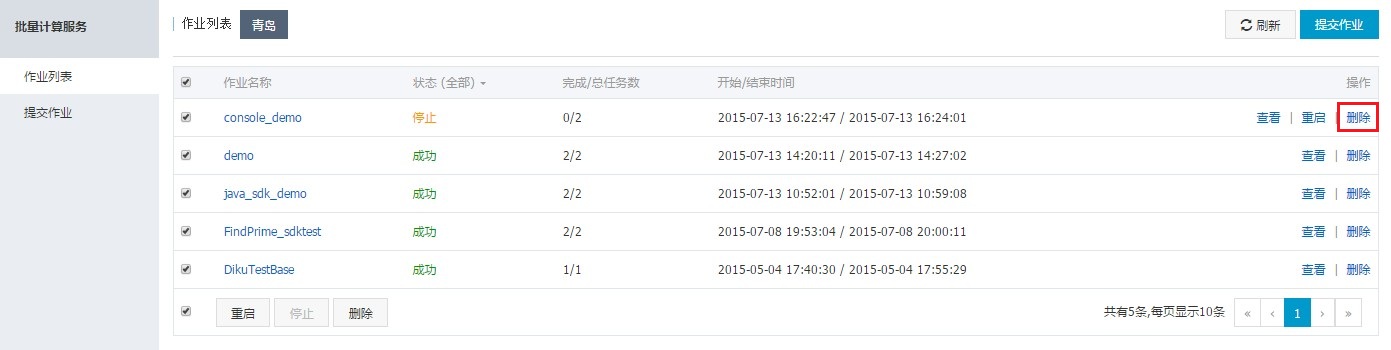
同时,还支持批量操作“重启”、“删除”或者“运行”。