
由于PyODPS DataFrame自身会对整个操作进行优化,您可以通过可视化方式直观地展示整个表达式的计算过程,以便进行调试。
可视化DataFrame
可视化需要依赖graphviz软件和graphvizPython包。
>>> df = iris.groupby('name').agg(id=iris.sepalwidth.sum())
>>> df = df[df.name, df.id + 3]
>>> df.visualize()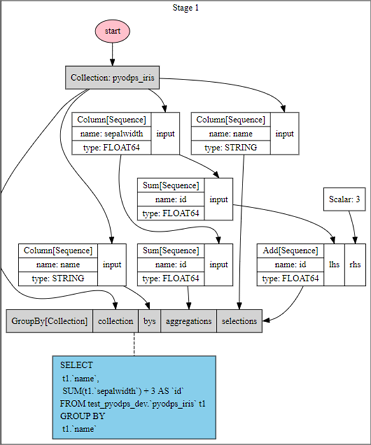
由上图可见,这个计算过程中,PyODPS DataFrame将groupby和列筛选做了操作合并。
>>> df = iris.groupby('name').agg(id=iris.sepalwidth.sum()).cache()
>>> df2 = df[df.name, df.id + 3]
>>> df2.visualize()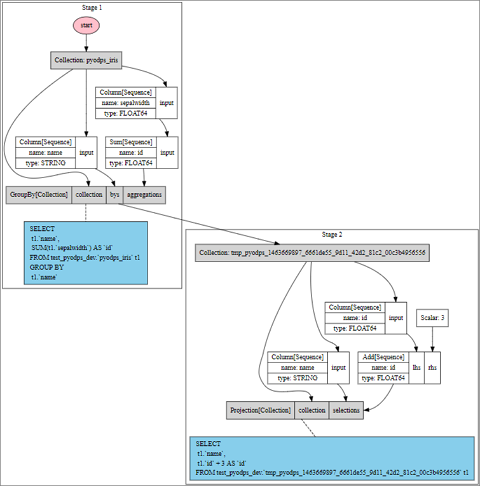 此时,由于执行了Cache操作,整个执行计划将会分成两步执行。
此时,由于执行了Cache操作,整个执行计划将会分成两步执行。
ODPS SQL后端查看编译结果
您可以直接调用compile方法查看ODPS SQL后端编译到SQL的结果。
>>> df = iris.groupby('name').agg(sepalwidth=iris.sepalwidth.max())
>>> df.compile()
Stage 1:
SQL compiled:
SELECT
t1.`name`,
MAX(t1.`sepalwidth`) AS `sepalwidth`
FROM test_pyodps_dev.`pyodps_iris` t1
GROUP BY
t1.`name`使用Pandas计算后端执行本地调试
对于来自ODPS表的DataFrame,部分操作不会编译到ODPS SQL执行,而会使用Tunnel下载表数据。这个下载的过程很快,且无需等待ODPS SQL任务的调度。利用这个特性,您可以快速下载小部分ODPS数据到本地,使用Pandas计算后端进行代码编写和调试。这些操作包括:
非分区表:对其进行选取全部或有限条数据、列筛选的操作(不包括列的各种计算),以及计算其数量。
不选取分区或筛选前几个分区字段的分区表:对其选取全部或有限条数据、列筛选的操作,以及计算其数量。
例如iris这个DataFrame来自非分区表,以下操作会使用Tunnel进行下载。
>>> iris.count()
>>> iris['name', 'sepalwidth'][:10]例如有个DataFrame来自分区表(有三个分区字段,即ds、hh、mm),以下操作会使用Tunnel下载。
>>> df[:10]
>>> df[df.ds == '20160808']['f0', 'f1']
>>> df[(df.ds == '20160808') & (df.hh == 3)][:10]
>>> df[(df.ds == '20160808') & (df.hh == 3) & (df.mm == 15)]因此您可以使用to_pandas方法将部分数据下载到本地进行调试。
>>> DEBUG = True
>>> if DEBUG:
>>> df = iris[:100].to_pandas(wrap=True)
>>> else:
>>> df = iris最后把DEBUG设置为False,便可以在ODPS上执行完整的计算。
说明
由于沙箱的限制,本地调试通过的程序不一定能在ODPS上也跑通。
该文章对您有帮助吗?