本文为您介绍如何使用DataWorks数据集成同步功能自动创建分区,动态地将RDS中的数据迁移至MaxCompute大数据计算服务。
前提条件
准备DataWorks环境
在DataWorks上完成创建业务流程,本例使用DataWorks简单模式。详情请参见创建业务流程。
新增数据源
新增MySQL数据源作为数据来源,详情请参见配置MySQL数据源。
新增MaxCompute数据源作为目标数据源接收RDS数据,详情请参见配置MaxCompute数据源。
自动创建分区
准备工作完成后,需要将RDS中的数据定时每天同步到MaxCompute中,自动创建按天日期的分区。详细的数据同步任务的操作和配置请参见DataWorks数据开发和运维。
登录DataWorks控制台。
在MaxCompute上创建目标表。
在左侧导航栏,单击工作空间。
单击相应工作空间操作列的快速进入 > 数据开发。
右键单击已创建的业务流程,选择。
在新建表页面,选择引擎实例、Schema和路径后,输入表名,并单击新建。
在表的编辑页面,单击
 图标,切换为DDL模式。
图标,切换为DDL模式。在DDL对话框,输入如下建表语句,单击生成表结构。然后在确认操作对话框里单击确认。
CREATE TABLE IF NOT EXISTS ods_user_info_d ( uid STRING COMMENT '用户ID', gender STRING COMMENT '性别', age_range STRING COMMENT '年龄段', zodiac STRING COMMENT '星座' ) PARTITIONED BY ( dt STRING );单击提交到生产环境。
新建离线同步节点。
进入数据开发页面,右键单击指定业务流程,选择。
在新建节点对话框中,输入节点名称,并单击确认。
选择数据来源、资源组和数据去向,并测试连通性。
数据来源:已创建的MySQL数据源。
我的资源组:选择独享数据集成资源组。
数据去向:已创建的MaxCompute数据源。
单击下一步,配置任务。
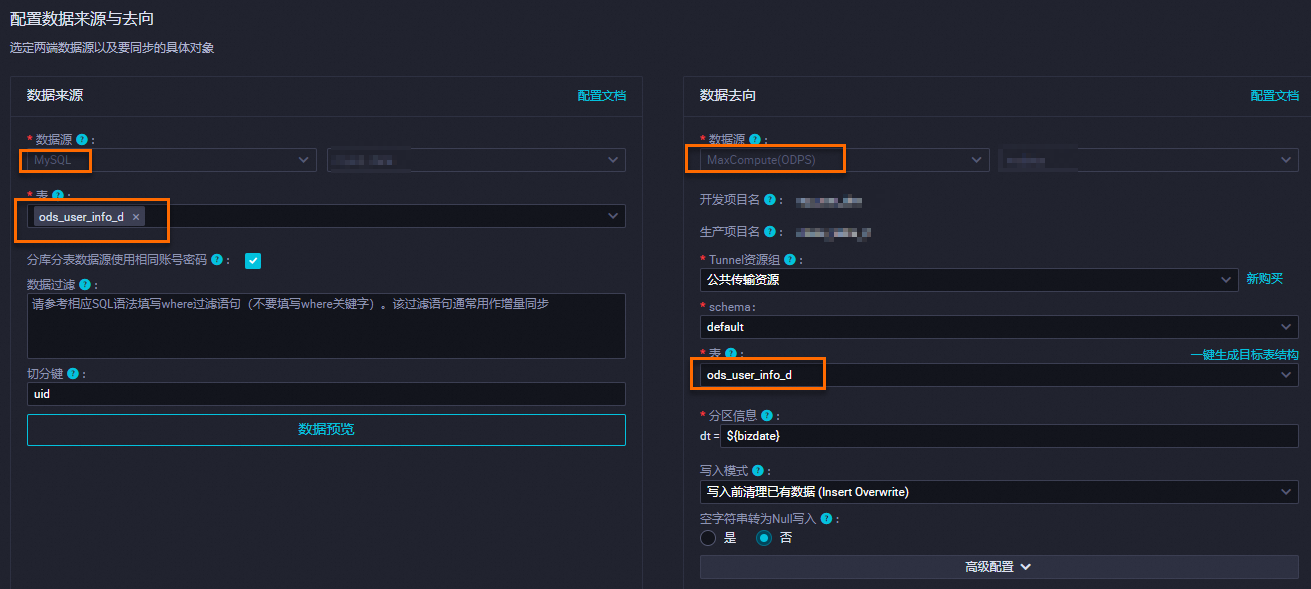
配置分区参数。
在右侧导航栏上,单击调度配置。
在调度参数区域,设置参数。参数值默认为系统自带的时间参数
${bizdate},格式为yyyymmdd。说明默认参数值与数据去向中的分区信息值对应。调度执行迁移任务时,目标表的分区值会被自动替换为任务执行日期的前一天,默认情况下,您会在当前执行前一天的业务数据,这个日期也叫做业务日期。如果您需要使用当天任务运行的日期作为分区值,则需自定义参数值。
自定义参数设置:用户可以自主选择某一天和格式配置,如下所示:
后N年:
$[add_months(yyyymmdd,12*N)]前N年:
$[add_months(yyyymmdd,-12*N)]前N月:
$[add_months(yyyymmdd,-N)]后N周:
$[yyyymmdd+7*N]后N月:
$[add_months(yyyymmdd,N)]前N周:
$[yyyymmdd-7*N]后N天:
$[yyyymmdd+N]前N天:
$[yyyymmdd-N]后N小时:
$[hh24miss+N/24]前N小时:
$[hh24miss-N/24]后N分钟:
$[hh24miss+N/24/60]前N分钟:
$[hh24miss-N/24/60]
说明使用中括号([])编辑自定义变量参数的取值计算公式,例如
key1=$[yyyy-mm-dd]。默认情况下,自定义变量参数的计算单位为天。例如
$[hh24miss-N/24/60]表示(yyyymmddhh24miss-(N/24/60 * 1天))的计算结果,然后按 hh24miss 的格式取时分秒。使用add_months的计算单位为月。例如
$[add_months(yyyymmdd,12 N)-M/24/60]表示(yyyymmddhh24miss-(12 * N * 1月))-(M/24/60 * 1天)的结果,然后按yyyymmdd的格式取年月日。
详细的参数设置请参见调度参数支持的格式。
单击
 图标运行代码。
图标运行代码。您可以在运行日志查看运行结果。
补数据实验
如果您的数据中存在大量运行日期之前的历史数据,需要实现自动同步和自动分区。您可以通过DataWorks的运维中心,选择当前的同步数据节点,使用补数据功能实现。
在RDS端按照日期筛选出历史数据。
您可以在同步节点数据来源区域设置数据过滤条件(例如设置为
${bizdate})。执行补数据操作。详情请参见执行补数据并查看补数据实例(新版)。
在运行的日志中查看对RDS数据的抽取结果。
从运行结果中可以看到MaxCompute已自动创建分区。
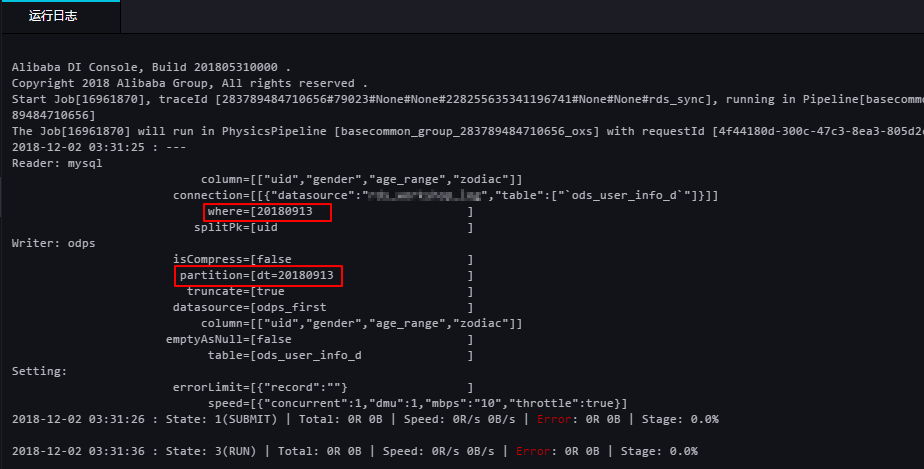
运行结果验证。在MaxCompute客户端执行如下命令,查看数据写入情况。
SELECT count(*) from ods_user_info_d where dt = 20180913;
Hash实现非日期字段分区
如果您的数据量较大,或没有按照日期字段对第一次全量的数据进行分区,而是按照省份等非日期字段分区,则此时数据集成操作将不能实现自动分区。这种情况下,您可以按照RDS中某个字段进行Hash,将相同的字段值自动存放到这个字段对应值的MaxCompute分区中。
将数据全量同步到MaxCompute的一个临时表,创建一个SQL脚本节点。执行如下命令。
drop table if exists ods_user_t; CREATE TABLE ods_user_t ( dt STRING, uid STRING, gender STRING, age_range STRING, zodiac STRING); --将MaxCompute表中的数据存入临时表。 insert overwrite table ods_user_t select dt,uid,gender,age_range,zodiac from ods_user_info_d;创建同步任务的节点mysql_to_odps,即简单的同步任务。将RDS数据全量同步到MaxCompute,无需设置分区。
使用SQL语句进行动态分区到目标表,命令如下。
drop table if exists ods_user_d; //创建一个ODPS分区表(最终目的表)。 CREATE TABLE ods_user_d ( uid STRING, gender STRING, age_range STRING, zodiac STRING ) PARTITIONED BY ( dt STRING ); //执行动态分区SQL,按照临时表的字段dt自动分区,dt字段中相同的数据值,会按照这个数据值自动创建一个分区值。 //例如dt中有些数据是20181025,会自动在ODPS分区表中创建一个分区,dt=20181025。 //动态分区SQL如下。 //可以注意到SQL中select的字段多写了一个dt,就是指定按照这个字段自动创建分区。 insert overwrite table ods_user_d partition(dt)select dt,uid,gender,age_range,zodiac from ods_user_t; //导入完成后,可以把临时表删除,节约存储成本。 drop table if exists ods_user_t;在MaxCompute中您可以通过SQL语句完成数据同步。
将三个节点配置成一个工作流,按顺序执行。
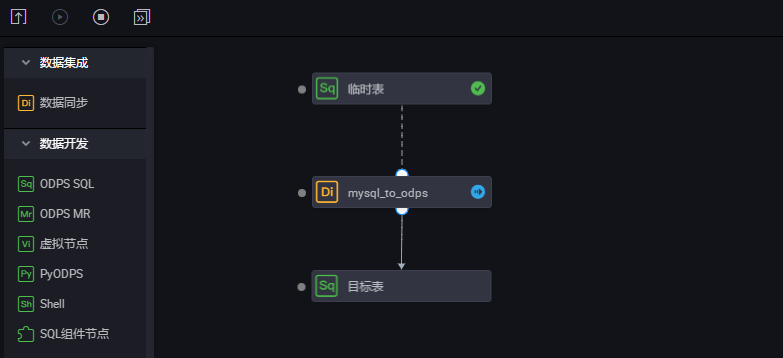
查看执行过程。您可以重点观察最后一个节点的动态分区过程。
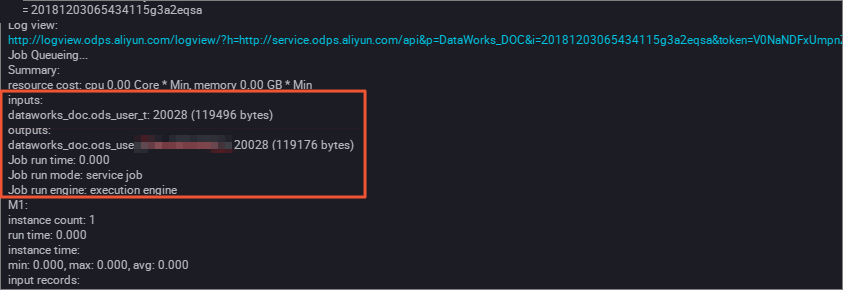
运行结果验证。在MaxCompute客户端执行如下命令,查看数据写入情况。
SELECT count(*) from ods_user_d where dt = 20180913;