当MaxCompute业务数据规模超过200 GB,且查询复杂度较高、对响应时间要求达到秒级时,Hologres支持将这些数据直接导入内部表进行查询,相较于通过外部表查询方式,该方式可以设置索引,且数据查询效率更高。本文为您介绍不同场景的数据导入操作以及常见问题。
注意事项
通过SQL导入MaxCompute数据至Hologres时,您需要注意如下内容:
MaxCompute的分区与Hologres无强映射关系,MaxCompute的分区字段映射至Hologres为普通字段,因此支持MaxCompute分区数据导入Hologres非分区或者分区。
Hologres仅支持一级分区,MaxCompute多级分区导入Hologres分区表时,只需要映射一个分区,其余分区映射成Hologres的普通字段。
如果导入数据时需要更新覆盖原有数据,您需要使用INSERT ON CONFLICT(UPSERT)语法。
MaxCompute与Hologres的数据类型映射,请参见数据类型汇总。
MaxCompute的表数据更新之后,在Hologres存在缓存延迟(一般为10分钟内),建议在导入数据前使用IMPORT FOREIGN SCHEMA语法更新外部表以获取最新数据。
导入MaxCompute数据至Hologres时,建议使用SQL导入,不建议使用数据集成导入,因为使用SQL导入性能表现更优。
导入MaxCompute的非分区表数据至Hologres并查询
准备MaxCompute的非分区表数据。
在MaxCompute中创建一张非分区源数据表,或直接选用已创建的非分区表。
示例选取MaxCompute公共数据集public_data的customer表,您可以参照使用公开数据集描述,登录并查询数据集。其表DDL以及数据如下。
--MaxCompute公共数据集的表DDL CREATE TABLE IF NOT EXISTS public_data.customer( c_customer_sk BIGINT, c_customer_id STRING, c_current_cdemo_sk BIGINT, c_current_hdemo_sk BIGINT, c_current_addr_sk BIGINT, c_first_shipto_date_sk BIGINT, c_first_sales_date_sk BIGINT, c_salutation STRING, c_first_name STRING, c_last_name STRING, c_preferred_cust_flag STRING, c_birth_day BIGINT, c_birth_month BIGINT, c_birth_year BIGINT, c_birth_country STRING, c_login STRING, c_email_address STRING, c_last_review_date STRING, useless STRING); --在MaxCompute中查询表是否有数据 SELECT * FROM public_data.customer;部分数据内容显示如下图所示。

在Hologres中创建外部表。
在Hologres中创建一张用于映射MaxCompute源数据表的外部表。示例SQL语句如下。
CREATE FOREIGN TABLE foreign_customer ( "c_customer_sk" int8, "c_customer_id" text, "c_current_cdemo_sk" int8, "c_current_hdemo_sk" int8, "c_current_addr_sk" int8, "c_first_shipto_date_sk" int8, "c_first_sales_date_sk" int8, "c_salutation" text, "c_first_name" text, "c_last_name" text, "c_preferred_cust_flag" text, "c_birth_day" int8, "c_birth_month" int8, "c_birth_year" int8, "c_birth_country" text, "c_login" text, "c_email_address" text, "c_last_review_date" text, "useless" text ) SERVER odps_server OPTIONS (project_name 'public_data', table_name 'customer');参数
描述
Server
您可以直接调用Hologres底层已创建的名为odps_server的外部表服务器。详细原理请参见Postgres FDW。
Project_Name
MaxCompute表所在的项目名称。
Table_Name
需要查询的MaxCompute表名称。
外部表字段的数据类型与MaxCompute表字段的数据类型保持一致,数据类型的映射关系请参见MaxCompute与Hologres的数据类型映射。
在Hologres中创建存储表。
在Hologres中创建一张用于接收MaxCompute源表数据的存储表。
本示例是初步的DDL示例,实际导入数据时创建表请根据业务情况设置表结构并给表设置合适的索引,以达到更优的查询性能,更多关于表属性的描述,请参见CREATE TABLE。
--示例建一张列存表 BEGIN; CREATE TABLE public.holo_customer ( "c_customer_sk" int8, "c_customer_id" text, "c_current_cdemo_sk" int8, "c_current_hdemo_sk" int8, "c_current_addr_sk" int8, "c_first_shipto_date_sk" int8, "c_first_sales_date_sk" int8, "c_salutation" text, "c_first_name" text, "c_last_name" text, "c_preferred_cust_flag" text, "c_birth_day" int8, "c_birth_month" int8, "c_birth_year" int8, "c_birth_country" text, "c_login" text, "c_email_address" text, "c_last_review_date" text, "useless" text ); CALL SET_TABLE_PROPERTY('public.holo_customer', 'orientation', 'column'); CALL SET_TABLE_PROPERTY('public.holo_customer', 'bitmap_columns', 'c_customer_id,c_salutation,c_first_name,c_last_name,c_preferred_cust_flag,c_birth_country,c_login,c_email_address,c_last_review_date,useless'); CALL SET_TABLE_PROPERTY('public.holo_customer', 'dictionary_encoding_columns', 'c_customer_id:auto,c_salutation:auto,c_first_name:auto,c_last_name:auto,c_preferred_cust_flag:auto,c_birth_country:auto,c_login:auto,c_email_address:auto,c_last_review_date:auto,useless:auto'); CALL SET_TABLE_PROPERTY('public.holo_customer', 'time_to_live_in_seconds', '3153600000'); CALL SET_TABLE_PROPERTY('public.holo_customer', 'storage_format', 'segment'); COMMIT;导入数据至Hologres。
说明Hologres从V2.1.17版本起支持Serverless Computing能力,针对大数据量离线导入、大型ETL作业、外表大数据量查询等场景,使用Serverless Computing执行该类任务可以直接使用额外的Serverless资源,避免使用实例自身资源,无需为实例预留额外的计算资源,显著提升实例稳定性、减少OOM概率,且仅需为任务单独付费。Serverless Computing详情请参见Serverless Computing概述,Serverless Computing使用方法请参见Serverless Computing使用指南。
使用
INSERT语句将MaxCompute源头表中的数据导入至Hologres,您可以选择部分字段导入(字段顺序需要一一对应),也可以选择全部字段导入,示例DDL如下。-- (可选)推荐使用Serverless Computing执行大数据量离线导入和ETL作业 SET hg_computing_resource = 'serverless'; --部分字段数据导入 INSERT INTO holo_customer (c_customer_sk,c_customer_id,c_email_address,c_last_review_date,useless) SELECT c_customer_sk, c_customer_id, c_email_address, c_last_review_date, useless FROM foreign_customer; --全部字段数据导入 INSERT INTO holo_customer SELECT * FROM foreign_customer; -- 重置配置,保证非必要的SQL不会使用serverless资源。 RESET hg_computing_resource;Hologres查询MaxCompute表数据。
在Hologres中查询导入的MaxCompute表数据。示例SQL语句如下。
SELECT * FROM holo_customer;
导入MaxCompute的分区表数据至Hologres并查询
详情请参见MaxCompute分区表数据导入。
INSERT OVERWRITE最佳实践
详情请参见INSERT OVERWRITE。
通过可视化工具或周期性调度同步数据
如果您需要一次性同步大量数据,可以通过可视化工具或者调度任务来实现。
通过可视化工具HoloWeb一键同步MaxCompute数据操作步骤如下。
进入HoloWeb页面,详情请参见连接HoloWeb并执行查询。
在HoloWeb开发页面的顶部菜单栏,选择,单击一键MaxCompute数据导入。
配置新建MaxCompute数据导入页面的各项参数。
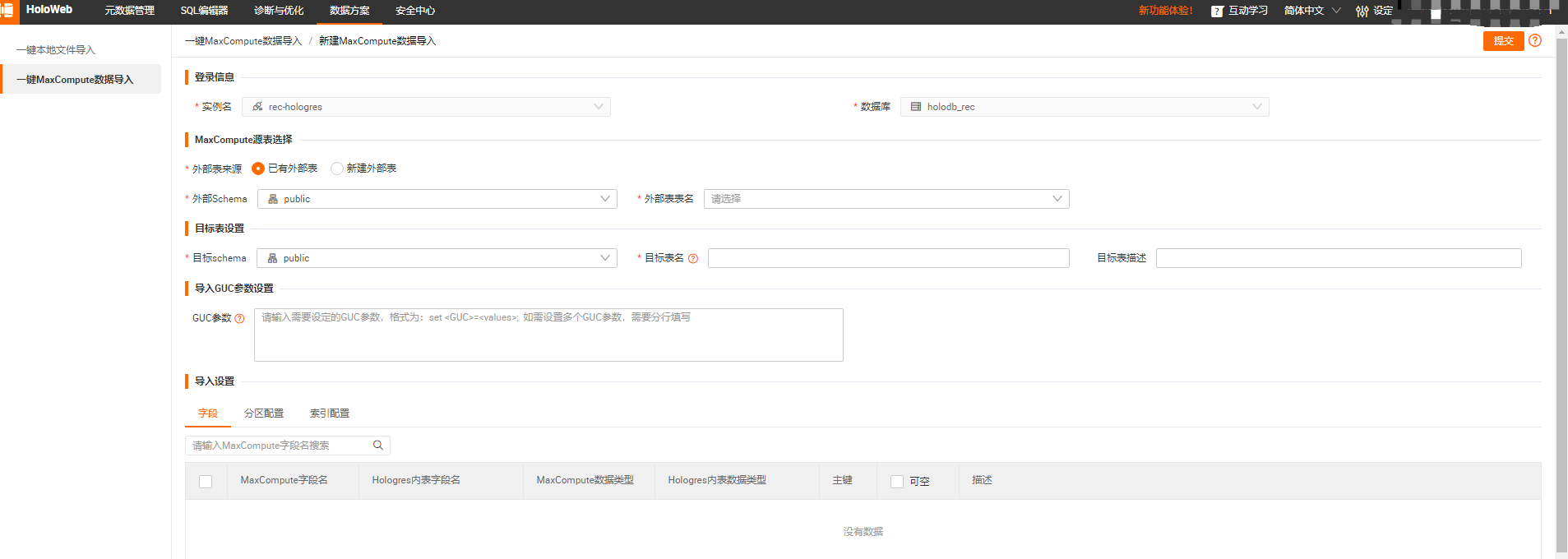 参数说明如下表所示。说明
参数说明如下表所示。说明SQL Script自动解析当前可视化操作对应的SQL语句。SQL Script内的SQL语句不支持修改,如果需要修改,请将SQL复制,手动更改后,使用SQL同步。
类别
参数
描述
选择实例
实例名
已登录的实例名称。
MaxCompute 源表
项目名
MaxCompute的项目名称。
Schema Name
MaxCompute的Schema名称,对于使用两层模型的MaxCompute项目,默认不展示;对于使用三层模型的MaxCompute项目,此处可下拉选择当前项目下有权限的所有Schema。
表名
MaxCompute的表名称,支持基于前缀模糊搜索。
Hologres 目标表
数据库名
选择内部表所在的Hologres数据库名称。
Schema Name
Hologres的Schema名称。
默认为public Schema,您也可以选择其他有权限的Schema。
表名
新建的Hologres内部表名称。
选择MaxCompute表后,将会自动填入MaxCompute表名称,您也可以手动重命名。
目标表描述
新建的Hologres内部表描述,可自定义修改。
参数设置
GUC参数
输入需要设定的GUC参数。GUC参数详情请参见GUC参数。
导入设置
字段
需要导入的MaxCompute表字段。
您可以选择导入部分或全部字段。
分区配置
分区字段
选择分区字段,Hologres将会默认将表创建为分区表。
Hologres仅支持一级分区。如果您需要导入MaxCompute的多级分区,则在Hologres中设置一级分区即可,其余分区自动映射为Hologres的普通字段。
业务日期
如果MaxCompute表使用日期进行分区,则您可以选择具体的分区日期,系统将会导入指定日期的数据至MaxCompute表。
索引配置
存储模式
列存,适用于各种复杂查询。
行存,适用于基于主键的点查询和Scan。
行列共存,支持行存和列存的所有场景,以及非主键点查的场景。
如果不指定存储模式,则默认为列存。
表数据生命周期
表数据的生命周期。默认为永久存储。
指定生命周期后,如果数据在指定时间内未被修改,则引擎将会在到期后的某一个时间段删除数据。
Binlog
是否开启Binlog,详情请参见订阅Hologres Binlog。
Binlog生命周期
Binlog的TTL,默认为30天,即默认值为2592000秒。
分布列
Hologres会按照分布列指定的列将数据shuffle到各个Shard,同样的数值会在同样的Shard中。以分布列做过滤条件时,可以大大提高执行效率。
分段列
您可以指定部分列作为分段键Segment_key。当查询条件包含分段列时,您可以通过分段键快速查找相应数据的存储位置。
聚簇列
您可以指定部分列作为聚簇索引Clustering_key。索引的类型和列的顺序密切相关。聚簇索引帮助您加速执行索引列的Range和Filter查询。
字典编码列
Hologres支持为指定列的值构建字典映射。字典编码可以将字符串的比较转换为数字的比较,加速Group By和Filter查询。
默认设置所有text列至字典编码列中。
位图列
Hologres支持在位图列构建比特编码。位图列可以根据设置的条件快速过滤字段内部的数据。
默认设置所有text列至位图列中。
单击提交,数据导入完成后,可以在Hologres中查询内部表数据。
HoloWeb一键同步不支持周期性调度,若是需要同步大量历史数据,或者周期性调度导入,需要通过DataWorks的DataStudio,详情请参见通过DataWorks周期性导入MaxCompute数据最佳实践。
常见问题
导入MaxCompute的数据至Hologres时发生OOM(Out Of Memory,内存溢出),提示超出内存限制异常。通常会产生Query executor exceeded total memory limitation xxxxx: yyyy bytes used报错。导致报错的四种可能原因及其对应的解决方案如下所示。
排查步骤一
可能原因:
当导入Query包含查询,但部分表没有执行
analyze命令;或者进行过analyze,但数据又有更新导致统计信息不准确,最终导致查询优化器决策Join Order有误,引起内存开销过高。解决方案:
对所有参与的内部表、外部表执行
analyze命令,更新表的统计元信息,可以帮助查询优化器生成更优的执行计划,解决出现OOM的情况。
排查步骤二
可能原因:
当表的列数较多,单行数据量较大时,单次读取的数据量会更大,引起内存开销过高。
解决方案:
在SQL语句前增加以下参数来控制单次读取数据行数,可以有效减少OOM情况。
SET hg_experimental_query_batch_size = 1024;--默认为8192 INSERT INTO holo_table SELECT * FROM mc_table;
排查步骤三
可能原因:
导入数据的过程中,并发度高,CPU消耗大,影响内部表查询。
解决方案:
在Hologres V1.1之前的版本中,可以通过并发度参数hg_experimental_foreign_table_executor_max_dop控制,默认为实例的Core数,在导入时可设置更小的hg_experimental_foreign_table_executor_max_dop参数值,降低导入的内存使用,解决出现OOM的情况。该参数对外表执行的所有作业有效。代码示例如下所示。
SET hg_experimental_foreign_table_executor_max_dop = 8; INSERT INTO holo_table SELECT * FROM mc_table;
排查步骤四
可能原因:
导入数据的过程中,并发度高,CPU消耗大,影响内表查询。
解决方案:
从Hologres V1.1版本开始,可以通过并发度参数hg_foreign_table_executor_dml_max_dop控制,默认为32,在导入时设置更小的hg_foreign_table_executor_dml_max_dop参数值,降低执行DML语句的并发度(主要是数据导入导出场景),避免执行DML语句占用过多资源。代码示例如下所示。
SET hg_foreign_table_executor_dml_max_dop = 8; INSERT INTO holo_table SELECT * FROM mc_table;