
Kafka数据源为您提供读取和写入Kafka的双向通道,本文为您介绍DataWorks的Kafka数据同步的能力支持情况。
支持的版本
支持阿里云Kafka,以及版本为0.10.2且小于等于3.6.x的自建Kafka版本。
对于<0.10.2版本Kafka,由于Kafka不支持检索分区数据offset,并且Kafka数据结构可能不支持时间戳,进而无法支持数据同步。
实时读取
使用包年包月Serverless资源组时,请提前预估Serverless资源组规格,避免资源组规格不足影响任务运行:
一个topic预估需要1 CU,除此之外,还需根据流量进行评估:
Kafka数据不压缩,按10 MB/s预估需要1 CU。
Kafka数据压缩,按10 MB/s预估需要2 CU。
Kafka数据压缩并且进行JSON解析,按10MB/s预估需要3 CU。
使用包年包月Serverless资源组和旧版独享数据集成资源组时:
对Failover容忍度高,集群槽位的水位建议不超过80%。
对Failover容忍度低,集群槽位的水位建议不超过70%。
实际占用和数据内容格式等相关,评估后您可以根据实际运行情况进行调整。
使用限制
Kafka数据源目前支持使用Serverless资源组(推荐)和旧版独享数据集成资源组。
单表离线读
同时配置parameter.groupId和parameter.kafkaConfig.group.id时,parameter.groupId优先级高于kafkaConfig配置信息中的group.id。
单表实时写
写入数据不支持去重,即如果任务重置位点或者Failover后再启动,会导致出现重复数据写入。
整库实时写
实时数据同步任务支持使用Serverless资源组(推荐)和旧版独享数据集成资源组。
对于源端同步表有主键的场景,同步时会使用主键值作为Kafka记录的key,确保同主键的变更有序写入Kafka的同一分区。
对于源端同步表无主键的场景,如果选择了支持无主键表同步选项,则同步时Kafka记录的key为空。如果要确保表的变更有序写入Kafka,则选择写入的Kafka topic必须是单分区。如果选择了自定义同步主键,则同步时使用其他非主键的一个或几个字段的联合,代替主键作为Kafka记录的key。
如果在kafka集群发生响应异常的情况下,仍要确保有主键表同主键的变更有序写入kafka的同一分区,则需要在配置kafka数据源时,在扩展参数表单中加入如下配置。
{"max.in.flight.requests.per.connection":1,"buffer.memory": 100554432}重要添加配置后同步性能会大幅下降,需要在性能和严格保序可靠性之间做好权衡。
实时同步写入Kafka的消息总体格式、同步任务心跳消息格式及源端更改数据对应的消息格式,详情请参见:附录:消息格式。
支持的字段类型
Kafka的数据存储为非结构化的存储,通常Kafka记录的数据模块有key、value、offset、timestamp、headers、partition。DataWorks在对Kafka数据进行读写时,会按照以下的策略进行数据处理。
离线读数据
DataWorks读取Kafka数据时,支持对Kafka数据进行JSON格式的解析,各数据模块的处理方式如下。
Kafka记录数据模块 | 处理后的数据类型 |
key | 取决于数据同步任务配置的keyType配置项,keyType参数介绍请参见下文的全量参数说明章节。 |
value | 取决于数据同步任务配置的valueType配置项,valueType参数介绍请参见下文的全量参数说明章节。 |
offset | Long |
timestamp | Long |
headers | String |
partition | Long |
离线写数据
DataWorks将数据写入Kafka时,支持写入JSON格式或text格式的数据,不同的数据同步方案往Kafka数据源中写入数据时,对数据的处理策略不一致,详情如下。
写入text格式的数据时,不会写入字段名数据,而是使用分隔符来分隔字段取值。
实时同步写入数据到Kafka时,写入的格式为内置的JSON格式,写入数据为包含数据库变更消息的数据、业务时间和DDL信息的所有数据,数据格式详情请参见附录:消息格式。
同步任务类型 | 写入Kafka value的格式 | 源端字段类型 | 写入时的处理方式 |
离线同步 DataStudio的离线同步节点 | json | 字符串 | UTF8编码字符串 |
布尔 | 转换为UTF8编码字符串"true"或者"false" | ||
时间/日期 | yyyy-MM-dd HH:mm:ss格式UTF8编码字符串 | ||
数值 | UTF8编码数值字符串 | ||
字节流 | 字节流会被视为UTF8编码的字符串,被转换成字符串 | ||
text | 字符串 | UTF8编码字符串 | |
布尔 | 转换为UTF8编码字符串"true"或者"false" | ||
时间/日期 | yyyy-MM-dd HH:mm:ss格式UTF8编码字符串 | ||
数值 | UTF8编码数值字符串 | ||
字节流 | 字节流会被视为UTF8编码的字符串,被转换成字符串 | ||
实时同步:ETL实时同步至Kafka DataStudio的实时同步节点 | json | 字符串 | UTF8编码字符串 |
布尔 | json布尔类型 | ||
时间/日期 |
| ||
数值 | json数值类型 | ||
字节流 | 字节流会进行Base64编码后转换成UTF8编码的字符串 | ||
text | 字符串 | UTF8编码字符串 | |
布尔 | 转换为UTF8编码字符串"true"或者"false" | ||
时间/日期 | yyyy-MM-dd HH:mm:ss格式UTF8编码字符串 | ||
数值 | UTF8编码数值字符串 | ||
字节流 | 字节流会进行Base64编码后转换成UTF8编码字符串 | ||
实时同步:整库实时同步至Kafka 纯实时同步增量数据 | 内置JSON格式 | 字符串 | UTF8编码字符串 |
布尔 | json布尔类型 | ||
时间/日期 | 13位毫秒时间戳 | ||
数值 | json数值 | ||
字节流 | 字节流会进行Base64编码后转换成UTF8编码字符串 | ||
同步解决方案:一键实时同步至Kafka 离线全量+实时增量 | 内置JSON格式 | 字符串 | UTF8编码字符串 |
布尔 | json布尔类型 | ||
时间/日期 | 13位毫秒时间戳 | ||
数值 | json数值 | ||
字节流 | 字节流会进行Base64编码后转换成UTF8编码字符串 |
创建数据源
在进行数据同步任务开发时,您需要在DataWorks上创建一个对应的数据源,操作流程请参见数据源管理,详细的配置参数解释可在配置界面查看对应参数的文案提示。
数据同步任务开发
数据同步任务的配置入口和通用配置流程可参见下文的配置指导。
单表离线同步任务配置指导
操作流程请参见通过向导模式配置离线同步任务、通过脚本模式配置离线同步任务。
脚本模式配置的全量参数和脚本Demo请参见下文的附录:脚本Demo与参数说明。
单表、整库实时同步任务配置指导
操作流程请参见DataStudio侧实时同步任务配置。
单表、整库全增量实时同步任务配置指导
操作流程请参见数据集成侧同步任务配置。
启用认证配置说明
SSL
配置Kafka数据源时,特殊认证方式选择SSL或者SASL_SSL时,表明Kafka集群开启了SSL认证,您需要上传客户端truststore证书文件并填写truststore证书密码。
如果Kafka集群为alikafka实例,可以参考SSL证书算法升级说明下载正确的truststore证书文件,truststore证书密码为KafkaOnsClient。
如果Kafka集群为EMR实例,可以参考使用SSL加密Kafka链接下载正确的truststore证书文件并获取truststore证书密码。
如果是自建集群,请自行上传正确的truststore证书,填写正确的truststore证书密码。
keystore证书文件、keystore证书密码和SSL密钥密码只有在Kafka集群开启双向SSL认证时才需要进行配置,用于Kafka集群服务端认证客户端身份。当Kafka集群server.properties中ssl.client.auth=required时开启双向SSL认证,详情请参见使用SSL加密Kafka链接。
GSSAPI
配置Kafka数据源时,当Sasl机制选择GSSAPI时,需要上传三个认证文件,分别是JAAS配置文件、Kerberos配置文件以及Keytab文件,并在独享资源组进行DNS/HOST设置,下面分别介绍这三种文件以及独享资源组DNS、HOST的配置方式。
Serverless资源组需要通过内网DNS解析配置Host地址信息,更多信息,请参见内网DNS解析(PrivateZone)。
JAAS配置文件
JAAS文件必须以KafkaClient开头,之后使用一个大括号包含所有配置项:
大括号内第一行定义使用的登录组件类,对于各类Sasl认证机制,登录组件类是固定的,后续的每个配置项以key=value格式书写。
除最后一个配置项,其他配置项结尾不能有分号。
最后一个配置项结尾必须有分号,在大括号"}"之后也必须加上一个分号。
不符合以上格式要求将导致JAAS配置文件解析出错,典型的JAAS配置文件格式如下(根据实际情况替换以下内容中的xxx):
KafkaClient { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=true keyTab="xxx" storeKey=true serviceName="kafka-server" principal="kafka-client@EXAMPLE.COM"; };配置项
说明
登录模块
必须配置com.sun.security.auth.module.Krb5LoginModule。
useKeyTab
必须指定为true。
keyTab
可以指定任意路径,在同步任务运行时会自动下载数据源配置时上传的keyTab文件到本地,并使用本地文件路径填充keyTab配置项。
storeKey
决定客户端是否保存密钥,配置true或者false均可,不影响数据同步。
serviceName
对应Kafka服务端server.properties配置文件中的sasl.kerberos.service.name配置项,请根据实际情况配置该项。
principal
Kafka客户端使用的kerberos principal,请根据实际情况配置该项,并确保上传的keyTab文件包含该principal的密钥。
Kerberos配置文件
Kerberos配置文件必须包含两个模块[libdefaults]和[realms]
[libdefaults]模块指定Kerberos认证参数,模块中每个配置项以key=value格式书写。
[realms]模块指定kdc地址,可以包含多个realm子模块,每个realm子模块以realm名称=开头。
后面紧跟一组用大括号包含配置项,每个配置项也以key=value格式书写,典型的Kerberos配置文件格式如下(根据实际情况替换以下内容中的xxx):
[libdefaults] default_realm = xxx [realms] xxx = { kdc = xxx }配置项
说明
[libdefaults].default_realm
访问Kafka集群节点时默认使用的realm,一般情况下与JAAS配置文件中指定客户端principal所在realm一致。
[libdefaults]其他参数
[libdefaults]模块可以指定其他一些Kerberos认证参数,例如ticket_lifetime等,请根据实际需要配置。
[realms].realm名称
需要与JAAS配置文件中指定客户端principal所在realm,以及[libdefaults].default_realm一致,如果JAAS配置文件中指定客户端principal所在realm和[libdefaults].default_realm不一致,则需要包含两组realms子模块分别对应JAAS配置文件中指定客户端principal所在realm和[libdefaults].default_realm。
[realms].realm名称.kdc
以ip:port格式指定kdc地址和端口,例如kdc=10.0.0.1:88,端口如果省略默认使用88端口,例如kdc=10.0.0.1。
Keytab文件
Keytab文件需要包含JAAS配置文件指定principal的密钥,并且能够通过kdc的验证。例如本地当前工作目录有名为client.keytab的文件,可以通过以下命令验证Keytab文件是否包含指定principal的密钥。
klist -ket ./client.keytab Keytab name: FILE:client.keytab KVNO Timestamp Principal ---- ------------------- ------------------------------------------------------ 7 2018-07-30T10:19:16 te**@**.com (des-cbc-md5)独享资源组DNS、HOST配置
开启Kerberos认证的Kafka集群,会使用Kafka集群中节点的hostname作为节点在kdc(Kerberos的服务端程序,即密钥分发中心)中注册的principal的一部分,而客户端访问Kafka集群节点时,会根据本地的DNS、HOST设置,推导Kafka集群节点的principal,进而从kdc获取节点的访问凭证。使用独享资源组访问开启Kerberos认证的Kafka集群时,需要正确配置DNS、HOST,以确保顺利从kdc获取Kafka集群节点的访问凭证:
DNS设置
当独享资源组绑定的VPC中,使用PrivateZone实例进行了Kafka集群节点的域名解析设置,则可以在DataWorks管控台的独享资源组对应的VPC绑定项增加100.100.2.136和100.100.2.138两个IP的自定义路由,以使PrivateZone针对Kafka集群节点的域名解析设置对独享资源组生效。
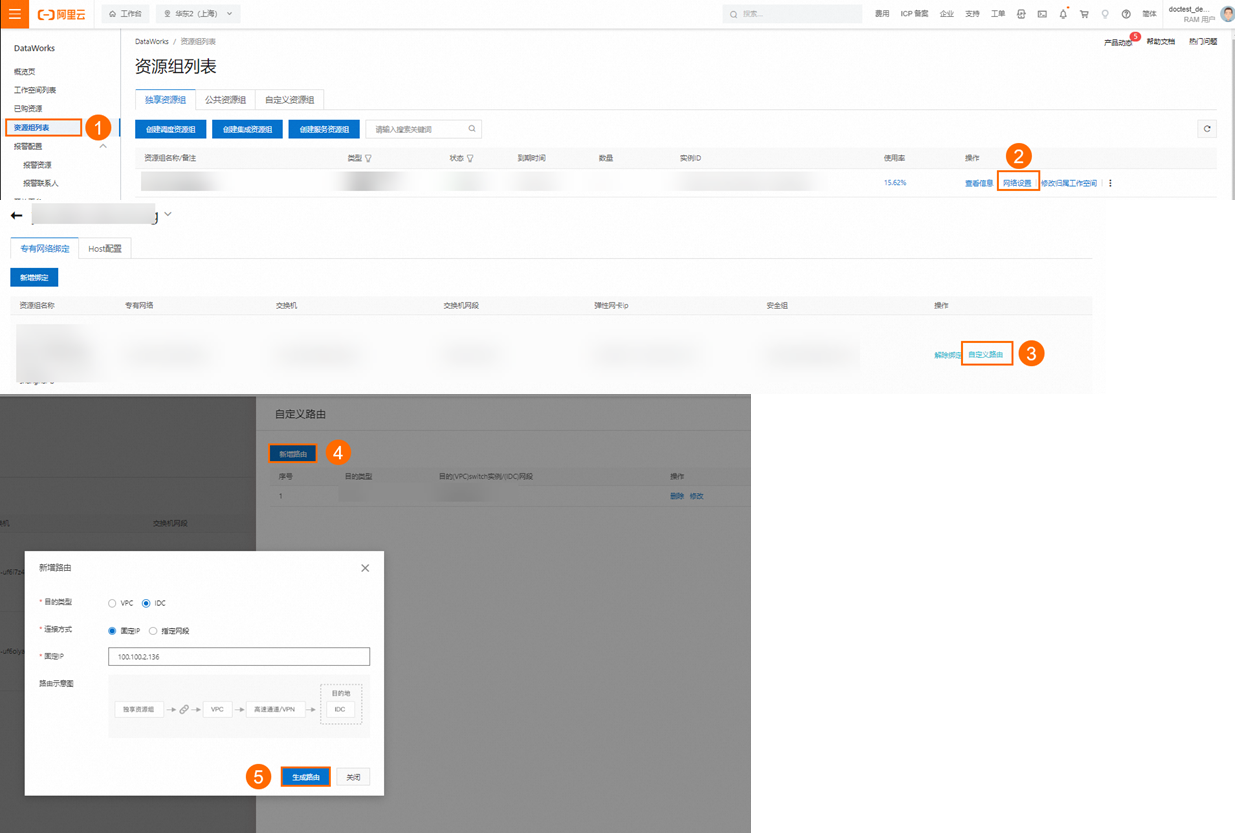
HOST设置
当独享资源组绑定的VPC中,未使用PrivateZone实例进行了Kafka集群节点的域名解析设置,则需要在DataWorks管控台,独享资源组网络设置中逐个将Kafka集群节点的IP地址与域名映射添加到Host配置中。
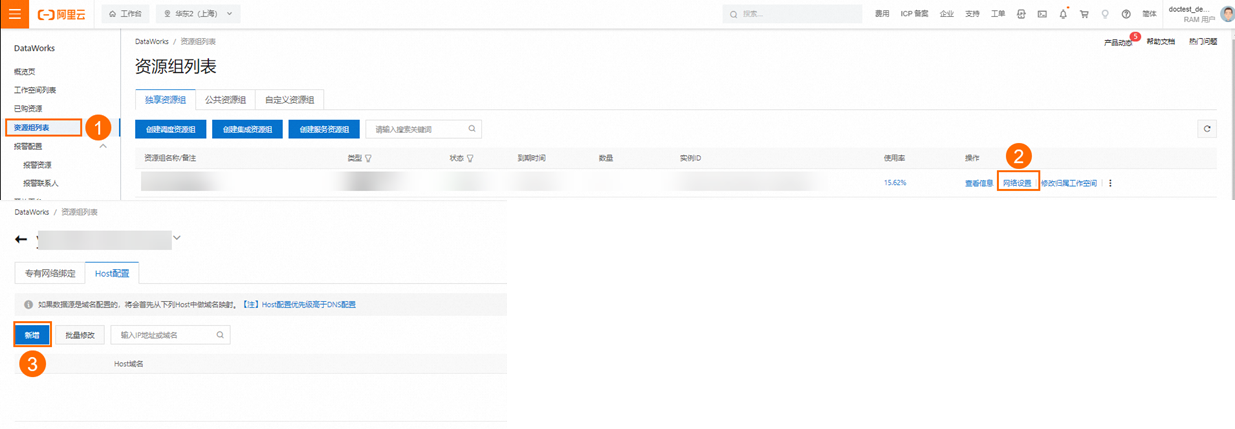
PLAIN
配置Kafka数据源时,当Sasl机制选择PLAIN时,JAAS文件必须以KafkaClient开头,之后使用一个大括号包含所有配置项。
大括号内第一行定义使用的登录组件类,对于各类Sasl认证机制,登录组件类是固定的,后续的每个配置项以key=value格式书写。
除最后一个配置项,其他配置项结尾不能有分号。
最后一个配置项结尾必须有分号,在大括号"}"之后也必须加上一个分号。
不符合以上格式要求将导致JAAS配置文件解析出错,典型的JAAS配置文件格式如下(根据实际情况替换以下内容中的xxx):
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="xxx"
password="xxx";
};配置项 | 说明 |
登录模块 | 必须配置org.apache.kafka.common.security.plain.PlainLoginModul |
username | 用户名,请根据实际情况配置该项。 |
password | 密码,请根据实际情况配置该项。 |
常见问题
附录:脚本Demo与参数说明
离线任务脚本配置方式
如果您配置离线任务时使用脚本模式的方式进行配置,您需要按照统一的脚本格式要求,在任务脚本中编写相应的参数,详情请参见通过脚本模式配置离线同步任务,以下为您介绍脚本模式下数据源的参数配置详情。
Reader脚本Demo
从Kafka读取数据的JSON配置,如下所示。
{
"type": "job",
"steps": [
{
"stepType": "kafka",
"parameter": {
"server": "host:9093",
"column": [
"__key__",
"__value__",
"__partition__",
"__offset__",
"__timestamp__",
"'123'",
"event_id",
"tag.desc"
],
"kafkaConfig": {
"group.id": "demo_test"
},
"topic": "topicName",
"keyType": "ByteArray",
"valueType": "ByteArray",
"beginDateTime": "20190416000000",
"endDateTime": "20190416000006",
"skipExceedRecord": "true"
},
"name": "Reader",
"category": "reader"
},
{
"stepType": "stream",
"parameter": {
"print": false,
"fieldDelimiter": ","
},
"name": "Writer",
"category": "writer"
}
],
"version": "2.0",
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
},
"setting": {
"errorLimit": {
"record": "0"
},
"speed": {
"throttle": true,//当throttle值为false时,mbps参数不生效,表示不限流;当throttle值为true时,表示限流。
"concurrent": 1,//并发数
"mbps":"12"//限流,此处1mbps = 1MB/s。
}
}
}Reader脚本参数
参数 | 描述 | 是否必选 |
datasource | 数据源名称,脚本模式支持添加数据源,此配置项填写的内容必须要与添加的数据源名称保持一致。 | 是 |
server | Kafka的broker server地址,格式为ip:port。 您可以只配置一个server,但请务必保证Kafka集群中所有broker的IP地址都可以连通DataWorks。 | 是 |
topic | Kafka的Topic,是Kafka处理资源的消息源(feeds of messages)的聚合。 | 是 |
column | 需要读取的Kafka数据,支持常量列、数据列和属性列:
| 是 |
keyType | Kafka的Key的类型,包括BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG和SHORT。 | 是 |
valueType | Kafka的Value的类型,包括BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG和SHORT。 | 是 |
beginDateTime | 数据消费的开始时间位点,为时间范围(左闭右开)的左边界。yyyymmddhhmmss格式的时间字符串,可以配合调度参数使用。详情请参见调度参数支持的格式。 说明 Kafka 0.10.2及以上的版本支持该功能。 | 需要和beginOffset二选一。 说明 beginDateTime和endDateTime配合使用。 |
endDateTime | 数据消费的结束时间位点,为时间范围(左闭右开)的右边界。yyyymmddhhmmss格式的时间字符串,可以配合调度参数使用。详情请参见调度参数支持的格式。 说明 Kafka 0.10.2及以上的版本支持该功能。 | 需要和endOffset二选一。 说明 endDateTime和beginDateTime配合使用。 |
beginOffset | 数据消费的开始时间位点,您可以配置以下形式:
| 需要和beginDateTime二选一。 |
endOffset | 数据消费的结束位点,用于控制结束数据消费任务退出的时间。 | 需要和endDateTime二选一。 |
skipExceedRecord | Kafka使用
| 否,默认值为false。 |
partition | Kafka的一个Topic有多个分区(partition),正常情况下数据同步任务是读取Topic(多个分区)一个点位区间的数据。您也可以指定partition,仅读取一个分区点位区间的数据。 | 否,无默认值。 |
kafkaConfig | 创建Kafka数据消费客户端KafkaConsumer可以指定扩展参数,例如bootstrap.servers、auto.commit.interval.ms、session.timeout.ms等,您可以基于kafkaConfig控制KafkaConsumer消费数据的行为。 | 否 |
encoding | 当keyType或valueType配置为STRING时,将使用该配置项指定的编码解析字符串。 | 否,默认为UTF-8。 |
waitTIme | 消费者对象从Kafka拉取一次数据的最大等待时间,单位为秒。 | 否,默认为60。 |
stopWhenPollEmpty | 该配置项可选值为true/false。当配置为true时,如果消费者从Kafka拉取数据返回为空(一般是已经读完主题中的全部数据,也可能是网络或者Kafka集群可用性问题),则立即停止任务,否则持续重试直到再次读到数据。 | 否,默认为true。 |
stopWhenReachEndOffset | 该配置项只在stopWhenPollEmpty为true时生效,可选值为true/false。
| 否,默认为false。 说明 兼容历史逻辑,Kafka版本低于V0.10.2无法执行已经读取Kafka Topic所有分区中的最新位点数据检查,但线上可能存在个别脚本模式任务是读取的版本低于V0.10.2的Kafka数据。 |
kafkaConfig参数说明如下。
参数 | 描述 |
fetch.min.bytes | 指定消费者从broker获取消息的最小字节数,即有足够的数据时,才将其返回给消费者。 |
fetch.max.wait.ms | 等待broker返回数据的最大时间,默认500毫秒。fetch.min.bytes和fetch.max.wait.ms先满足哪个条件,便按照该方式返回数据。 |
max.partition.fetch.bytes | 指定broker从每个partition中返回给消费者的最大字节数,默认为1 MB。 |
session.timeout.ms | 指定消费者不再接收服务之前,可以与服务器断开连接的时间,默认是30秒。 |
auto.offset.reset | 消费者在读取没有偏移量或者偏移量无效的情况下(因为消费者长时间失效,包含偏移量的记录已经过时并被删除)的处理方式。默认为none(意味着不会自动重置位点),您可以更改为earliest(消费者从起始位置读取partition的记录)。 |
max.poll.records | 单次调用poll方法能够返回的消息数量。 |
key.deserializer | 消息Key的反序列化方法,例如org.apache.kafka.common.serialization.StringDeserializer。 |
value.deserializer | 数据Value的反序列化方法,例如org.apache.kafka.common.serialization.StringDeserializer。 |
ssl.truststore.location | SSL根证书的路径。 |
ssl.truststore.password | 根证书Store的密码。如果是Aliyun Kafka,则配置为KafkaOnsClient。 |
security.protocol | 接入协议,目前支持使用SASL_SSL协议接入。 |
sasl.mechanism | SASL鉴权方式,如果是Aliyun Kafka,使用PLAIN。 |
java.security.auth.login.config | SASL鉴权文件路径。 |
Writer脚本Demo
向Kafka写入数据的JSON配置,如下所示。
{
"type":"job",
"version":"2.0",//版本号。
"steps":[
{
"stepType":"stream",
"parameter":{},
"name":"Reader",
"category":"reader"
},
{
"stepType":"Kafka",//插件名。
"parameter":{
"server": "ip:9092", //Kafka的server地址。
"keyIndex": 0, //作为Key的列。需遵循驼峰命名规则,k小写
"valueIndex": 1, //作为Value的某列。目前只支持取来源端数据的一列或者该参数不填(不填表示取来源所有数据)
//例如想取odps的第2、3、4列数据作为kafkaValue,请新建odps表将原odps表数据做清洗整合写新odps表后使用新表同步。
"keyType": "Integer", //Kafka的Key的类型。
"valueType": "Short", //Kafka的Value的类型。
"topic": "t08", //Kafka的topic。
"batchSize": 1024 //向kafka一次性写入的数据量,单位是字节。
},
"name":"Writer",
"category":"writer"
}
],
"setting":{
"errorLimit":{
"record":"0"//错误记录数。
},
"speed":{
"throttle":true,//当throttle值为false时,mbps参数不生效,表示不限流;当throttle值为true时,表示限流。
"concurrent":1, //作业并发数。
"mbps":"12"//限流,此处1mbps = 1MB/s。
}
},
"order":{
"hops":[
{
"from":"Reader",
"to":"Writer"
}
]
}
}Writer脚本参数
参数 | 描述 | 是否必选 |
datasource | 数据源名称,脚本模式支持添加数据源,此配置项填写的内容必须要与添加的数据源名称保持一致。 | 是 |
server | Kafka的server地址,格式为ip:port。 | 是 |
topic | Kafka的topic,是Kafka处理资源的消息源(feeds of messages)的不同分类。 每条发布至Kafka集群的消息都有一个类别,该类别被称为topic,一个topic是对一组消息的归纳。 | 是 |
valueIndex | Kafka Writer中作为Value的那一列。如果不填写,默认将所有列拼起来作为Value,分隔符为fieldDelimiter。 | 否 |
writeMode | 当未配置valueIndex时,该配置项决定将源端读取记录的所有列拼接作为写入Kafka记录Value的格式,可选值为text和JSON,默认值为text。
例如源端记录有三列,值为a、b和c,writeMode配置为text、fieldDelimiter配置为#时,写入Kafka的记录Value为字符串a#b#c;writeMode配置为JSON、column配置为[{"name":"col1"},{"name":"col2"},{"name":"col3"}]时,写入Kafka的记录Value为字符串{"col1":"a","col2":"b","col3":"c"}。 如果配置了valueIndex,该配置项无效。 | 否 |
column | 目标表需要写入数据的字段,字段间用英文逗号分隔。例如: 当未配置valueIndex,并且writeMode选择JSON时,该配置项定义源端读取记录的列值在JSON结构中的字段名称。例如,
如果配置了valueIndex,或者writeMode配置为text,该配置项无效。 | 当未配置valueIndex,并且writeMode配置为JSON时必选 |
partition | 指定写入Kafka topic指定分区的编号,是一个大于等于0的整数。 | 否 |
keyIndex | Kafka Writer中作为Key的那一列。 keyIndex参数取值范围是大于等于0的整数,否则任务会出错。 | 否 |
keyIndexes | 源端读取记录中作为写入Kafka记录Key的列的序号数组。 列序号从0开始,例如[0,1,2],会将配置的所有列序号的值用逗号连接作为写入Kafka记录的Key。如果不填写,写入Kafka记录Key为null,数据轮流写入topic的各个分区中,与keyIndex参数只能二选一。 | 否 |
fieldDelimiter | 当writeMode配置为text,并且未配置valueIndex时,将源端读取记录的所有列按照该配置项指定列分隔符拼接作为写入Kafka记录的Value,支持配置单个或者多个字符作为分隔符,支持以\u0001格式配置Unicode字符,支持\t、\n等转义字符。默认值为\t。 如果writeMode未配置为text或者配置了valueIndex,该配置项无效。 | 否 |
keyType | Kafka的Key的类型,包括BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG和SHORT。 | 是 |
valueType | Kafka的Value的类型,包括BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG和SHORT。 | 是 |
nullKeyFormat | keyIndex或者keyIndexes指定的源端列值为null时,替换为该配置项指定的字符串,如果不配置,则不做替换。 | 否 |
nullValueFormat | 当源端列值为null时,组装写入kafka记录Value时替换为该配置项指定的字符串,如果不配置不作替换。 | 否 |
acks | 初始化Kafka Producer时的acks配置,决定写入成功的确认方式。默认acks参数为all。acks取值如下:
| 否 |
附录:写入Kafka消息格式定义
完成配置实时同步任务的操作后,执行同步任务会将源端数据库读取的数据,以JSON格式写入到Kafka topic中。除了会将设置的源端表中已有数据全部写入Kafka对应Topic中,还会启动实时同步将增量数据持续写入Kafka对应Topic中,同时源端表增量DDL变更信息也会以JSON格式写入Kafka对应Topic中。您可以通过附录:消息格式获取写入Kafka的消息的状态及变更等信息。
通过离线同步任务写入Kafka的数据JSON结构中的payload.sequenceId、payload.timestamp.eventTIme和payload.timestamp.checkpointTime字段均设置为-1。
附录:JSON字段类型
当writeMode配置为JSON时,可以通过column参数中的type字段定义JSON字段类型,写入时会根据JSON字段类型尝试对源端读取记录列值进行类型转换,类型转换失败将导致脏数据。
可选值 | 描述 |
JSON_STRING | 将源端读取记录列值转换为字符串写入JSON字段,例如源端记录列值为整数 |
JSON_NUMBER | 将源端读取记录列值转换为数值写入JSON字段,例如源端记录列值为字符串 |
JSON_BOOL | 将源端读取记录列值转换为布尔值写入JSON字段,例如源端记录列值为字符串 |
JSON_ARRAY | 将源端读取记录列值转换为JSON数组写入JSON字段,例如源端记录列值为字符串 |
JSON_MAP | 将源端读取记录列值转换为JSON对象写入JSON字段,例如源端记录列值为字符串 |
JSON_BASE64 | 将源端读取记录列值的二进制字节内容转换为BASE64编码字符串写入JSON字段,例如源端记录列值为长度为2的字节数组,16进制表示为 |
JSON_HEX | 将源端读取记录列值的二进制字节内容转换为16进制数值字符串写入JSON字段,例如源端记录列值为长度为2的字节数组,16进制表示为 |