ODPS Foreign Table(ODPS FDW)是云原生数据仓库 AnalyticDB PostgreSQL 版基于PostgreSQL Foreign Data Wrapper(PG FDW)框架开发的用于访问MaxCompute外部数据的方案,允许您在云原生数据仓库 AnalyticDB PostgreSQL 版中创建外表,然后将MaxCompute中的数据通过外表引入云原生数据仓库 AnalyticDB PostgreSQL 版中进行查询和分析。
概览如下图:
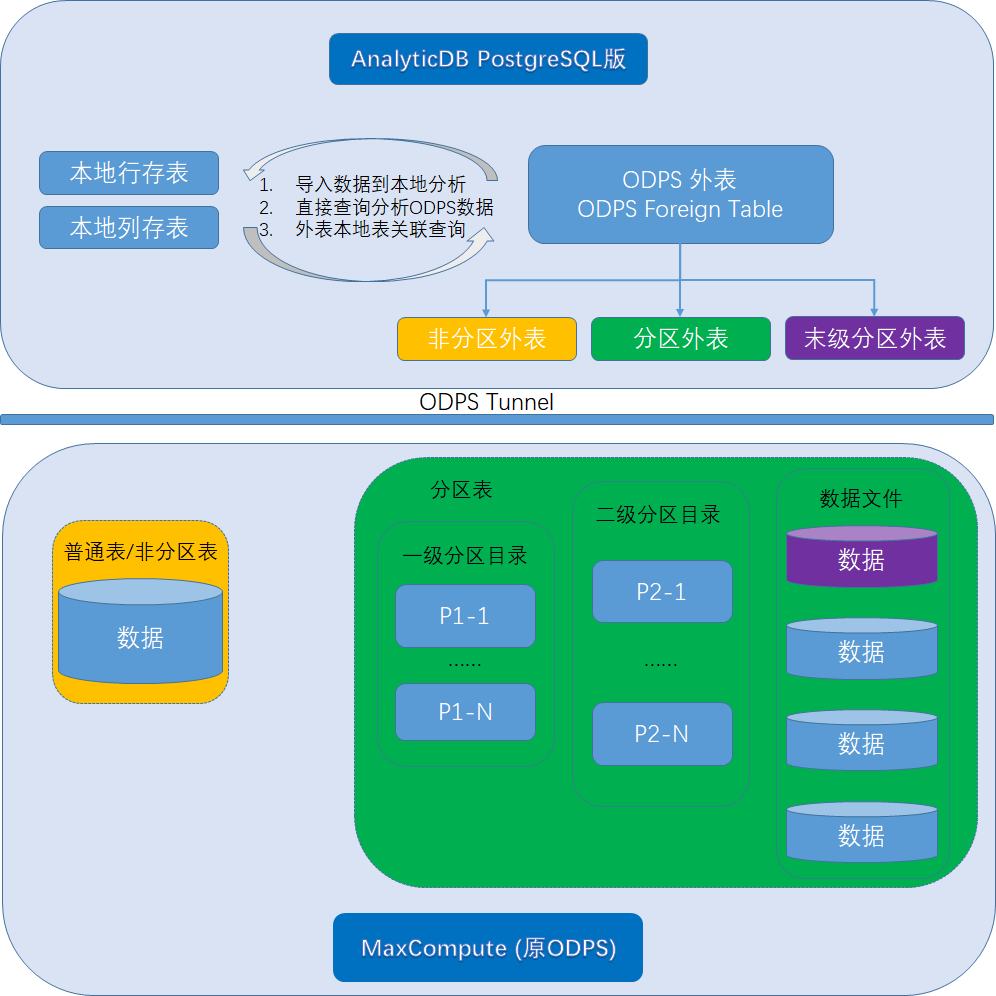
ODPS FDW模块的加入,填补了当前AnalyticDB PostgreSQL版与MaxCompute的数据同步链路的缺失。您通过ODPS FDW可以创建三种类型的ODPS外表。
ODPS非分区外表:映射MaxCompute非分区表。
ODPS末级分区外表:映射MaxCompute末级分区表。
ODPS分区外表:映射MaxCompute分区表。
开始使用ODPS FDW
在AnalyticDB PostgreSQL版数据库中创建ODPS FDW插件。
CREATE EXTENSION odps_fdw ;将使用权赋权给所有用户,示例如下:
GRANT USAGE ON FOREIGN DATA WRAPPER odps_fdw TO PUBLIC;
新建实例默认创建ODPS FDW extension,无需执行创建和赋权操作。
既存实例,可以使用初始账号,连接指定Database手动执行如下命令,创建ODPS FDW extension。
开始使用ODPS Foreign Table
使用ODPS外表需要以下三要素,缺一不可,包括:
ODPS Server:定义MaxCompute的访问端点。
ODPS User Mapping:定义MaxCompute的访问账户。
ODPS Foreign Table:定义MaxCompute的访问对象。
1. 创建ODPS Server
1.1 语法示例
CREATE SERVER odps_serv -- ODPS Server名称
FOREIGN DATA WRAPPER odps_fdw
OPTIONS (
tunnel_endpoint '<odps tunnel endpoint>' -- ODPS Tunnel Endpoint
);1.2 参数选项
在AnalyticDB PostgreSQL版中定义ODPS Server只需要指定tunnel_endpoint或odps_endpoint即可。其中:
选项 | 是否必选 | 备注 |
tunnel_endpoint | 可选,优先推荐设置此选项。 | 指 ODPS tunnel 服务的 Endpoint。 |
odps_endpoint | 可选 | 指 MaxCompute 服务的 Endpoint。 |
创建时,可以设置其中任意一个,也可以都设置,优先选择使用Tunnel Endpoint,当缺少Tunnel Endpoint时,则通过ODPS Endpoint路由到对应的Tunnel Endpoint。
推荐配置阿里云经典网络或VPC网络的Tunnel Endpoint,如果使用VPC地址,请确保AnalyticDB PostgreSQL版与ODPS在同一可用区中。
通过配置外网Tunnel Endpoint地址访问MaxCompute 数据,价格为0.8元/GB。
关于ODPS Endpoint,请参见配置Endpoint。
2. 创建 ODPS User Mapping
2.1 语法示例
CREATE USER MAPPING FOR { username | USER | CURRENT_USER | PUBLIC }
SERVER odps_serv -- ODPS Server 名称
OPTIONS (
id '<odps access id>', -- ODPS Account ID
key '<odps access key>' -- ODPS Account Key
);username:映射到外部服务器的现有用户的名称。
CURRENT_USER和USER:与当前用户的名称匹配。
PUBLIC:包括所有角色,包括以后创建的角色。
2.2 参数选项
在AnalyticDB PostgreSQL版中定义访问ODPS Server的账户,需要指定账户类型 TYPE,ID和KEY。
选项 | 是否必选 | 备注 |
| 必选 | 指定账户ID。 |
| 必选 | 指定账户KEY。 |
3. 创建ODPS Foreign Table
3.1 语法示例
CREATE FOREIGN TABLE IF NOT EXISTS table_name ( -- ODPS 外表名称
column_name data_type [, ... ]
)
SERVER odps_serv -- ODPS Server 名称
OPTIONS (
project '<odps project>', -- ODPS 项目空间
table '<odps table>' -- ODPS 表名称
);3.2 参数选项
定义了ODPS Server和ODPS User Mapping 后,就可以创建ODPS Foreign Table。参数选项包括:
选项 | 是否必选 | 备注 |
| 必选 | 项目空间。项目空间(Project)是 MaxCompute 的基本组织单元,它类似于传统数据库的 Database 或 Schema 的概念,是进行多用户隔离和访问控制的主要边界。详情请参见项目。 |
| 必选 | MaxCompute表名称。表是MaxCompute的数据存储单元,详情请参见表。 |
| 可选 | 用于定义MaxCompute的末级分区表。分区partition是指在一张表中,根据分区字段(一个或多个字段的组合)对数据存储进行划分。也就是说,如果表没有分区,数据是直接放在表所在的目录下。如果表有分区,每个分区对应表下的一个目录,数据是分别存储在不同的分区目录下。关于分区的更多介绍请参见分区。 |
3.3 外表分类
根据MaxCompute的表分类,ODPS FDW支持定义以下三种类型的ODPS外表。
非分区外表
非分区ODPS外表映射的是MaxCompute的非分区表。用户创建外表时,只需要指定有效的project和table属性即可,无需指定partition属性或者指定partition属性为“空”。例如:
CREATE FOREIGN TABLE odps_lineitem ( -- ODPS 外表名称 l_orderkey bigint, l_partkey bigint, l_suppkey bigint, l_linenumber bigint, l_quantity double precision, l_extendedprice double precision, l_discount double precision, l_tax double precision, l_returnflag char(1), l_linestatus char(1), l_shipdate date, l_commitdate date, l_receiptdate date, l_shipinstruct char(25), l_shipmode char(10), l_comment varchar(44) ) SERVER odps_serv -- ODPS Server 名称 OPTIONS ( project 'odps_fdw', -- ODPS 项目空间 table 'lineitem_big' -- ODPS 表名称 );末级分区外表
相对于非分区外表,末级分区外表,映射的是MaxCompute的末级分区表,需要设置正确的partition属性,多级分区时,末级分区外表只支持末级分区表,即partition属性需要包含多级分区完整路径。
举例说明:在MaxCompute上创建一个二级分区表,如下:
--创建一个二级分区表,以日期为一级分区,地域为二级分区 CREATE TABLE src (key string, value bigint) PARTITIONED BY (pt string,region string);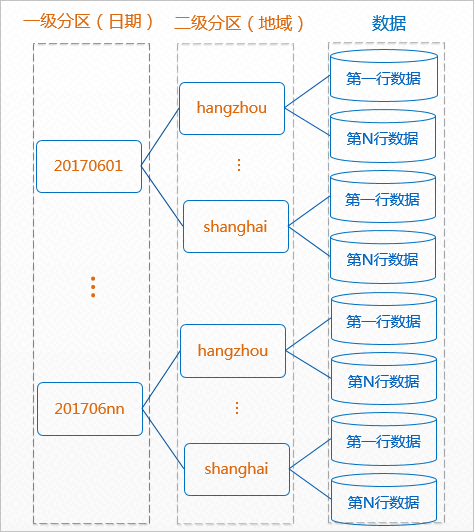
当您需要在AnalyticDB PostgreSQL版中定义一个末级分区外表,映射 MaxCompute上一级分区为(20170601),二级分区为(hangzhou)的末级分区表时,需要设置 partition为
'pt=20170601,region=hangzhou'。CREATE FOREIGN TABLE odps_src_20170601_hangzhou ( -- ODPS 外表 key string, value bigint ) SERVER odps_serv -- ODPS Server 名称 OPTIONS ( project 'odps_fdw', -- ODPS 项目空间 table 'src', -- ODPS 表名称 partition 'pt=20170601,region=hangzhou' -- 末级分区完整路径 );说明分区的partition specification需按照key=value的方式设置;多级分区时,以逗号分隔,且不能包含额外的空格。
不支持映射非末级分区的表。如,不支持仅设置一级分区路径:
partition 'pt=20170601'。一定要设置完整的多级分区路径。如,不支持仅设置末级分区路径:
partition 'region=hangzhou'。
分区外表
MaxCompute分区外表,映射的是MaxCompute的分区表。同样,以上述MaxCompute二级分区表src 为例,您可以按照如下方法创建对应的分区外表。更多表分区定义。
CREATE FOREIGN TABLE odps_src( -- ODPS 外表名称 key text, value bigint, pt text, -- ODPS 一级分区键 region text -- ODPS 二级分区键 ) SERVER odps_serv OPTIONS ( project 'odps_fdw', -- ODPS 项目空间 table 'src' -- ODPS 表名称 ) PARTITION BY LIST (pt) -- 一级分区以"pt"字段为分区键 SUBPARTITION BY LIST (region) -- 二级分区以"region"字段为分区键 SUBPARTITION TEMPLATE ( -- 二级分区模板 SUBPARTITION hangzhou VALUES ('hangzhou'), SUBPARTITION shanghai VALUES ('shanghai') ) ( PARTITION "20170601" VALUES ('20170601'), PARTITION "20170602" VALUES ('20170602'));说明与MaxCompute分区表定义不同,AnalyticDB PostgreSQL版的分区外表定义时:
需要将分区键以字段方式定义在其他字段尾部,多级分区时,分区字段定义顺序、分区键层级、MaxCompute分区表层级三者需保持一致。
分区表定义需要指定分区键值,请使用LIST方式分区。
分区外表定义时,不需要指定partition属性,这是因为partition属性标记的是末级分区外表,与分区外表在逻辑上冲突。
当出现MaxCompute上不存在的分区外表,查询外表时,会告警显示,用户可以参考本章的3.5节如何删除子分区外表删除相应子分区。
3.4 如何添加子分区外表
以上述odps_src分区外表为例。
添加一级子分区,效果如下图。
-- 添加一级子分区(自动创建二级子分区)
alter table odps_src add partition "20170603" values(20170603);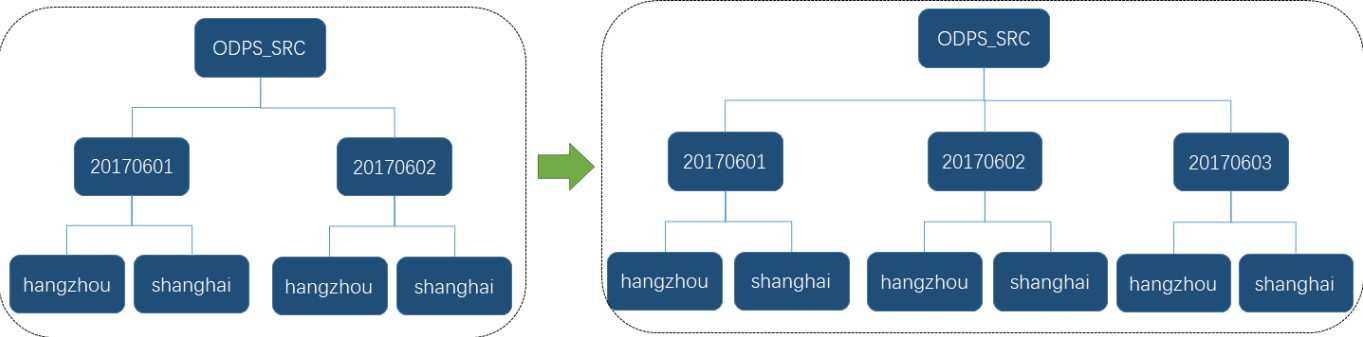
添加二级子分区,效果如下图。
-- 添加二级子分区
alter table odps_src alter partition "20170603" add partition "nanjing" values('nanjing');
3.5 如何删除子分区外表
以上述odps_src分区外表为例。
删除一级子分区,效果如下图。
-- 删除一级子分区(级联删除二级子分区)
alter table odps_src drop partition "20170602";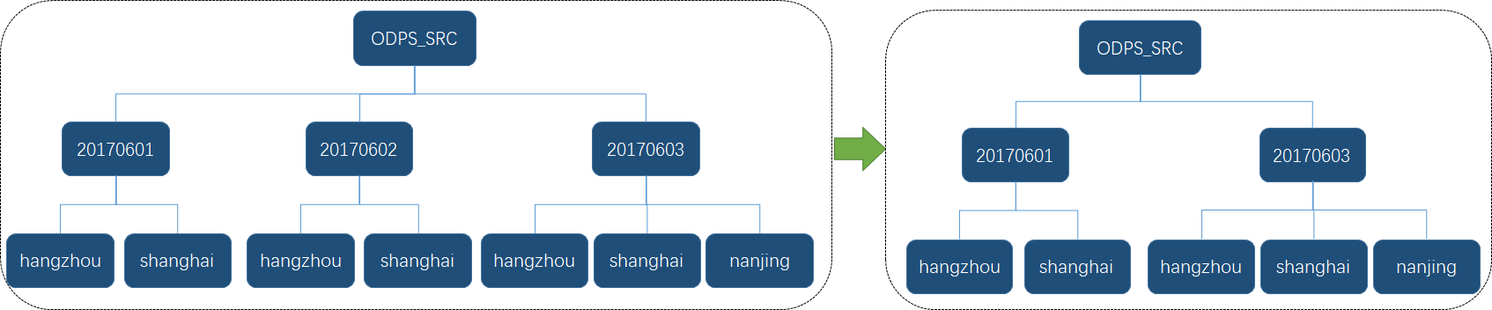
删除二级子分区
-- 删除二级子分区
alter table odps_src alter partition "20170601" drop partition "hangzhou";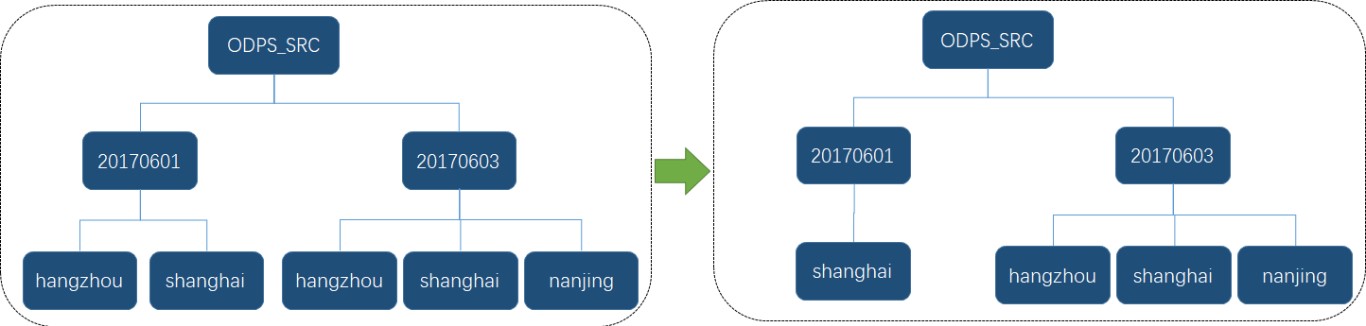
MaxCompute外表使用场景
MaxCompute外表扫描,实现了AnalyticDB PostgreSQL版的Foreign Scan算子。因此,表查询的使用方法上,对MaxCompute外表的查询与对普通表的查询基本一致。本文以TPC-H Query为例,举例说明常见的使用场景。
MaxCompute外表查询分析
TPC-H Query Q1是典型的单表聚集过滤场景,定义odps_lineitem为MaxCompute外表,对其执行Q1查询。
-- 定义MaxCompute外表odps_lineitem
CREATE FOREIGN TABLE odps_lineitem (
l_orderkey bigint,
l_partkey bigint,
l_suppkey bigint,
l_linenumber bigint,
l_quantity double precision,
l_extendedprice double precision,
l_discount double precision,
l_tax double precision,
l_returnflag CHAR(1),
l_linestatus CHAR(1),
l_shipdate DATE,
l_commitdate DATE,
l_receiptdate DATE,
l_shipinstruct CHAR(25),
l_shipmode CHAR(10),
l_comment VARCHAR(44)
) server odps_serv
options (
project 'odps_fdw', table 'lineitem'
);
-- TPC-H Q1
select
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count(*) as count_order
from
odps_lineitem
where
l_shipdate <= date '1998-12-01' - interval '88' day --(3)
group by
l_returnflag,
l_linestatus
order by
l_returnflag,
l_linestatus;MaxCompute数据导入本地表
导入数据时,请执行如下步骤:
在AnalyticDB PostgreSQL版中,创建MaxCompute外表。
执行如下操作,并行导入数据。
-- INSERT方式
INSERT INTO <本地目标表> SELECT * FROM <ODPS 外表>;
-- CREATE TABLE AS 方式
CREATE TABLE <本地目标表> AS SELECT * FROM <ODPS 外表>;示例1:INSERT方式将odps_lineitem数据导入到本地AOCS表。
-- 创建本地AOCS表
CREATE TABLE aocs_lineitem (
l_orderkey bigint,
l_partkey bigint,
l_suppkey bigint,
l_linenumber bigint,
l_quantity double precision,
l_extendedprice double precision,
l_discount double precision,
l_tax double precision,
l_returnflag CHAR(1),
l_linestatus CHAR(1),
l_shipdate DATE,
l_commitdate DATE,
l_receiptdate DATE,
l_shipinstruct CHAR(25),
l_shipmode CHAR(10),
l_comment VARCHAR(44)
) WITH (APPENDONLY=TRUE, ORIENTATION=COLUMN, COMPRESSTYPE=ZSTD, COMPRESSLEVEL=5)
DISTRIBUTED BY (l_orderkey);
-- 将 odps_lineitem 数据导入到 AOCS 本地表
INSERT INTO aocs_lineitem SELECT * FROM odps_lineitem;示例2:CREATE TABLE AS方式将odps_lineitem导入到本地heap表。
create table heap_lineitem as select * from odps_lineitem distributed by (l_orderkey);MaxCompute外表与本地表关联
以TPC-H Query Q19为例,使用本地列存表aocs_lineitem与MaxCompute外表odps_part关联查询。
-- TPC-H Q19
select
sum(l_extendedprice* (1 - l_discount)) as revenue
from
aocs_lineitem, -- 本地 AOCS 列存表
odps_part -- ODPS 外表
where
(
p_partkey = l_partkey
and p_brand = 'Brand#32'
and p_container in ('SM CASE', 'SM BOX', 'SM PACK', 'SM PKG')
and l_quantity >= 8 and l_quantity <= 8 + 10
and p_size between 1 and 5
and l_shipmode in ('AIR', 'AIR REG')
and l_shipinstruct = 'DELIVER IN PERSON'
)
or
(
p_partkey = l_partkey
and p_brand = 'Brand#41'
and p_container in ('MED BAG', 'MED BOX', 'MED PKG', 'MED PACK')
and l_quantity >= 15 and l_quantity <= 15 + 10
and p_size between 1 and 10
and l_shipmode in ('AIR', 'AIR REG')
and l_shipinstruct = 'DELIVER IN PERSON'
)
or
(
p_partkey = l_partkey
and p_brand = 'Brand#44'
and p_container in ('LG CASE', 'LG BOX', 'LG PACK', 'LG PKG')
and l_quantity >= 22 and l_quantity <= 22 + 10
and p_size between 1 and 15
and l_shipmode in ('AIR', 'AIR REG')
and l_shipinstruct = 'DELIVER IN PERSON'
);将AnalyticDB PostgreSQL内表数据写入MaxCompute
使用示例:将示例2中heap_lineitem表内数据写到odps_lineitem表。
INSERT INTO odps_lineitem SELECT * FROM heap_lineitem;MaxCompute外表使用建议
MaxCompute外表通过网络访问MaxCompute,其使用瓶颈不仅受限于机器自身资源,还受到MaxCompute Tunnel对外吞吐的网络带宽的限制 。因此,建议您:
使用MaxCompute外表的并发数不应超过5个。
在关联多张MaxCompute外表时,建议先将大表导入本地,然后再和小的外表进行关联,以提高性能。
对MaxCompute外表的查询性能受到MaxCompute中小文件数量的影响,若小文件数量过多,将对查询性能产生负面影响。可通过以下命令在MaxCompute中查看小文件的数量并进行小文件合并。若单次合并小文件后仍存在较多小文件,反复执行合并小文件的命令可实现更为理想的合并效果。
在MaxCompute中执行以下命令查看表的文件数。
desc extended <table_name> [partition (<pt_spec>)];在MaxCompute中执行以下命令合并小文件。
ALTER TABLE <table_name> [partition (<pt_spec>)] MERGE SMALLFILES;参数说明
table_name:必填。待查看表的名称。
pt_spec:可选。待查看分区表的指定分区。格式为
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)。
更多信息请参见合并小文件。
MaxCompute外表数据类型
目前MaxCompute数据类型与云原生数据仓库 AnalyticDB PostgreSQL 版数据类型的对应关系如下,建议按照此类型对照表来定义外表的字段类型。
目前暂不支持MaxCompute中的STRUCT、MAP、ARRAY类型。
MaxCompute数据类型 | 云原生数据仓库 AnalyticDB PostgreSQL 版数据类型 |
BOOLEAN | BOOL |
TINYINT | INT2 |
SMALLINT | INT2 |
INTEGER | INT4 |
BIGINT | INT8 |
FLOAT | FLOAT4 |
DOUBLE | FLOAT8 |
DECIMAL | NUMBERIC |
BINARY | BYTEA |
VARCHAR(n) | VARCHAR(n) |
CHAR(n) | CHAR(n) |
STRING | TEXT |
DATE | DATE |
DATETIME | TIMESTAMP |
TIMESTAMP | TIMESTAMP |
Array<SMALLINT/INT/BIGINT/BOOLEAN/FLOAT/DOUBLE/TEXT/VARCHAR/TIMESTAMP> (写入到MaxCompute外表功能暂不支持Array类型)。 | INT2,INT4,INT8,BOOLEAN,FLOAT4,FLOAT8,TEXT,VARCHAR,TIMESTAMP |