
N-gram分析器
介绍:由连续的N个字符组成的序列,支持2-gram和3-gram,适用于非语义搜索场景。
该分析器仅限独享型应用可用,且要求字段为SHORT_TEXT类型。
举例:
2-gram
文档字段内容为"Open Search", 分词结果为'op','pe','en','n ',' s','se','ea','ar','rc','ch'3-gram
文档字段内容为"Open Search", 分词结果为'ope','pen','en ','n s',' se','sea','ear','arc','rch'
关键字分析器
介绍:不分词,适合一些需要精确匹配的场景。如标签、关键词等,不分词的字符串或数值内容。
注意:该分析器适用于LITERAL、INT、LITERAL_ARRAY、INT_ARRAY 字段类型。
举例:
例如:文档字段内容为“菊花茶”,则只有搜索“菊花茶”的情况下可以召回。中文-通用分析器
介绍:按照检索单元做分词,基于中文语义分词,适用于全网通用行业的分析器。属于行业分析类型。
注意:该分析器适用于TEXT、SHORT_TEXT字段类型。
举例:
例如:文档字段内容为“菊花茶”,则搜索“菊花茶”、“菊花”、“茶”、“花茶”等情况下可以召回。中文-电商分析器
介绍:适用于电商行业的分析器。
注意:该分析器适用于TEXT、SHORT_TEXT字段类型。
举例:
例如:文档字段内容为“大宝SOD蜜”,则搜索“大宝”、“sod”、“sod蜜”、“SOD蜜”、“蜜”等情况下均可以召回。中文-单字分析器
介绍:按照单字/单词分词,适合非语义的中文搜索场景,如小说作者名称、店铺名等。
注意:该分析器适用于TEXT、SHORT_TEXT字段类型。
举例:
例如:文档字段内容为“菊花茶”,则搜索“菊花茶”、“菊花”、“茶”、“花茶”、“菊”、“花”、“菊茶”等情况下可以召回。模糊分析器
介绍:支持拼音搜索、数字的前后缀搜索(中文不支持前后缀匹配搜索,字母,数字及拼音,这些都支持前后缀匹配)、单字或者单字母搜索。最多支持100个字节字段长度,更多介绍及注意事项参见模糊搜索文档。
注意:仅适用于SHORT_TEXT短文本类型。
举例:
例如:文档字段内容为“菊花茶”,则搜索“菊花茶”、“菊花”、“茶”、“花茶”、“菊”、“花”、“菊茶”、“ju”、“juhua”、“juhuacha”、“j”、“jh”、“jhc”等情况下可以召回。
例如:文档字段内容为手机号“138****5678”,则通过“^138”来搜索以“138”开头的手机号,通过“5678$”搜索以“5678”结尾的手机号。
例如:文档字段内容为“OpenSearch”,则通过单个字母或者组合都可以检索到。英文-去词根分析器
介绍:适合于英文语义搜索场景,对于分词后的每个英文单词默认会做去词根、单复数转化。
注意:该分析器适用于TEXT、SHORT_TEXT字段类型;该分析器暂不支持查询分析配置。
举例:
例如:文档字段内容为“英文分词器 english analyzer”,则搜索“英文分词器”、“english”、“analyz”、“analyzer”、“analyzers”、“analyze”、“analyzed”、“analyzing”等情况下可以召回。
(注意:英文分词器中连续的中文会被分成一个词)英文-不去词根分析器
介绍:用于英文书名、人名等搜索场景,按照空格及标点符号做分词。
注意:该分析器适用于TEXT、SHORT_TEXT字段类型;该分析器暂不支持配置查询分析配置。
举例:
例如:文档字段内容为“英文分词器 english analyzer”,则搜索“英文分词器”、“english”、“analyzer”等情况下可以召回。
(注意:英文分词器中连续的中文会被分成一个词)英文-小粒度分析
介绍:按照英文检索单元做分词,英文语义分词,适用于英文通用行业的分析器。
注意:仅适用于TEXT、SHORT_TEXT字段类型。
仅限规格为独享型的应用可用。
举例:
文档字段内容为"dataprocess",分词结果"data process", 则搜索"dataprocess"、"data process"、"data"、"process"等情况下可以召回。拼音全拼分析器
介绍:支持对短文本中的汉字,按照首字母和拼音全拼进行检索。适用于人名、电影名等需要简拼和全拼搜索的场景,而且全拼检索时必须输入汉字的全拼,不能只输部分。
注意:仅适用于SHORT_TEXT短文本类型。
举例:
例如:文档字段内容为“大内密探007”,则搜索“d”、“dn”、“dnm”、“dnmt”、“dnmt007”、“da”、“danei”、“daneimi”、“daneimitan”等都可以召回。搜索“an”、“anei”等无法召回。拼音简拼分析器
介绍:支持对短文本中的汉字,按照首字母进行检索。适用于人名、电影名等需要简拼搜索的场景。
注意:仅适用于SHORT_TEXT短文本类型。
举例:
例如:文档字段内容为“大内密探007”,则搜索“d”、“dn”、“dnm”、“dnmt”、“dnmt0”、“dnmt007”、“m”、“mt”、“mt007”、“007”等都可以召回。简单分析器
介绍:适合特殊场景下系统自带无法解决的搜索场景,可以实现完全用户控制的效果。推送文档及搜索时使用制表符“\t”对字段内容(或查询词)进行分隔,注意二者分词的一致性,否则会导致无法召回文档的情况。
注意:该分析器适用于TEXT、SHORT_TEXT字段类型;该分析器暂不支持配置查询分析配置。
举例:
例如:字段内容为“菊\t花茶\thao”,则只有查询词“菊”、“花茶”、“菊\t花茶”、“花茶\thao”、“菊\thao”、“菊\t花茶\thao”可以召回该文档。数值分析器
介绍:适合需要按时间区间查询和数值类区间查询的搜索场景。
注意:该分析器适用于INT、timestamp字段类型。
举例:
例如:query=default:'开放搜索' AND index:[number1,number2]
//此处index为配置了数值分析的索引名字。地理位置分析器
介绍:适用于需要地理位置区间查询的场景。
注意:仅适用于geo_point字段类型。
举例:
例如:query=spatial_index:'circle(116.5806 39.99624, 1000)'
//查询圆内的点, 可以用于附近若干公里的点查询IT内容分析器
介绍:适用于面向IT行业的技术性内容的分析器,属于行业分词;和通用分析器相比,对一些IT技术相关的词分词结果会不一样。
注意:仅适用于TEXT,SHORT_TEXT字段类型。
举例:
例如:原始内容:c++数组使用注意事项
通用分析:c ++数组使用注意事项
IT-内容分析:c++数组使用注意事项行业-电商通用分析
介绍:适用于面向电商行业场景的分析器,属于行业分词。开发搜索根据多年积累的行业并借助达摩院智能语言处理技术,贴合行业痛点与需求,提供了电商专属查询分析能力。
注意:
仅适用于TEXT字段类型;
仅限规格为电商行业增强的独享型应用可用。
举例:
例如:原始内容:小金管遮瑕膏
通用分析:小金管 遮瑕 膏
行业-电商分析:小金管 遮瑕 膏泰语-通用分析
介绍:按照泰语检索单元做分词,适用于泰语通用行业的分析器。
注意:仅适用于TEXT、SHORT_TEXT字段类型;
仅限规格为独享型的应用可用。
举例:
文档字段内容为"แหล่งดึงดูดนักท่องเที่ยว",分词结果"แหล่ง ดึง ดูด นักท่องเที่ยว", 则搜索"นักท่องเที่ยว"、"แหล่งดึงดูดนักท่องเที่ยว"等情况下可以召回。泰语-电商分析
介绍:适用于泰语电商行业的分析器。
注意:仅适用于TEXT,SHORT_TEXT字段类型;
仅限规格为独享型的应用可用。
举例:
文档字段内容为"หน้าจอโทรศัพท์", 分词结果为"หน้าจอ โทรศัพท์", 则搜索"หน้าจอโทรศัพท์", "หน้าจอ", "โทรศัพท์"可以被召回越南语-通用分析
介绍:适用于越南语通用行业的分析器。
注意:仅适用于TEXT、SHORT_TEXT字段类型;
仅限规格为独享型的应用可用。
印尼语-通用分析
介绍 :适用于印尼语通用行业的分析器。
注意 :仅适用于TEXT,SHORT_TEXT字段类型;
仅限规格为独享型的应用可用。
行业-游戏通用分析
介绍:适用于游戏行业的分析器。
注意:仅适用于TEXT,SHORT_TEXT字段类型;
仅限规格为游戏行业增强的独享型应用可用。
举例:
文档字段内容为"原神装备", 分词结果为"原神 装备", 则搜索"原神装备", "原神", "装备"等可以被召回行业-英文电商通用分析
介绍:适用于英文场景下的电商行业的分析器。
注意:仅适用于TEXT字段类型;
仅限规格为电商行业增强的独享型应用可用。
中文-字符分析
介绍:按照中文单字/数字/英文/标点符号分词,适合非语义的搜索场景。
注意:仅适用于TEXT、SHORT_TEXT字段类型;
仅限规格为独享型应用可用。
举例:
例如:文档字段内容为“开放搜索OpenSearch123.”,则搜索“开”、“放”、“搜”、“索”、“O”、“p”、“e”、“n”、“S”、“e”、“a”、“r”、“c”、“h”、“.”情况下都可以召回。韩语-通用分析
介绍:适用于韩语通用行业的分析器。
注意:仅适用于TEXT,SHORT_TEXT字段类型;
仅限规格为独享型的应用可用。
举例:
文档字段内容为"인제군의교육", 分词结果为"인제군 의 교육", 则搜索"인제군의교육", "의", "교육"可以被召回韩语-电商分析
介绍:适用于韩语电商行业的分析器。
注意:仅适用于TEXT,SHORT_TEXT字段类型;
仅限规格为独享型的应用可用。
举例:
文档字段内容为"스포츠캐주얼신발", 分词结果为"스포츠 캐주얼 신발", 则搜索"스포츠", "캐주얼", "신발"可以被召回日语-通用分析
介绍:适用于日语通用行业的分析器。
注意:仅适用于TEXT,SHORT_TEXT字段类型;
仅限规格为独享型的应用可用。
举例:
文档字段内容为"メキシコアグーチ", 分词结果为"メキシコ アグーチ", 则搜索"メキシコ", "アグーチ"可以被召回日语-电商分析
介绍:适用于日语电商行业的分析器。
注意:仅适用于TEXT,SHORT_TEXT字段类型;
仅限规格为独享型的应用可用。
举例:
文档字段内容为"ラウンドネックスーツ", 分词结果为"ラウンド ネック スーツ", 则搜索"ラウンド", "ネック", "スーツ"可以被召回文本-自定义分析器
介绍:行业分析器(通用分析/电商分析/人名分析)+自定义干预词条。具体用法参考文本-自定义分析器文档。
注意:仅适用于TEXT、SHORT_TEXT字段类型。
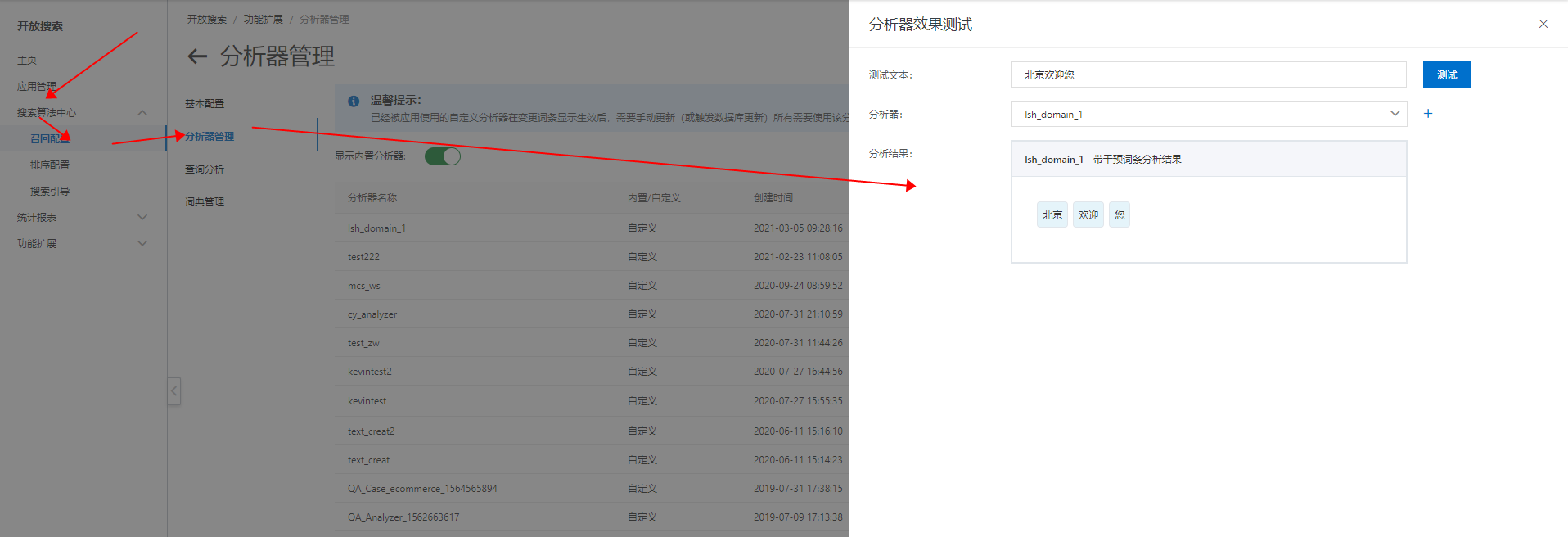
分析测试
行业分析器以及自定义分析器的分析结果可以通过分析测试功能进行测试。前往应用控制台的应用列表界面 -> 搜索算法中心 -> 召回配置 ->分析器管理 -> 分词测试,进行分析器分析结果的测试。(如下图)
适用场景
有语义环境的中文搜索,建议使用中文语义分析器;
对于短文本或者非语义环境中文搜索(对排序没有太多要求),建议使用中文单字分析器来扩大召回;
拼音搜索请使用模糊分析器;
英文场景下请使用英文去词根分析器;
某些场景下,中文语义分析器及单字分析器搭配使用,可以获得非常好的搜索效果。如查询query=title_index:’菊花茶’ OR sws_title_index:’菊花茶’,精排表达式为:text_relevance(title)*5+field_proximity(sws_title)。可以实现包含“xx菊xx花xx茶xx”的文档,且排序上“菊花茶”会排在前面。
注意事项
支持创建为索引字段的类型
INT,INT_ARRAY,TEXT,SHORT_TEXT,LITERAL,LITERAL_ARRAY,TIMESTAMP,GEO_POINT
不支持创建为索引字段的类型
FLOAT,FLOAT_ARRAY,DOUBLE,DOUBLE_ARRAY
如果TEXT字段设置了搜索结果摘要,扩展检索单元部分词组(如上例中的“花茶”)将不会被添加飘红标签。
中文单字分析器对于数字跟单词认为是一个词,如“hello word”,搜索“hello”可以召回,搜索“he”则无法召回,敬请注意。若需要做单词内召回,请选择模糊分析器。
应用结构中的主表的主键,默认会被设置为索引字段,且索引字段名称默认为“id” ,不支持修改配置。