
ES-Hadoop是Elasticsearch推出的专门用于对接Hadoop生态的工具,可以让数据在Elasticsearch和Hadoop之间双向移动,无缝衔接Elasticsearch与Hadoop服务,充分使用Elasticsearch的快速搜索及Hadoop批处理能力,实现交互式数据处理。对于一些较复杂的分析任务,需要通过MapReduce任务读取HDFS上的JSON文件,写入Elasticsearch集群。本文介绍如何通过ES-Hadoop,借助MapReduce任务向Elasticsearch写入数据。
操作流程
创建同一专有网络下的阿里云Elasticsearch和E-MapReduce(以下简称EMR)实例、开启Elasticsearch实例的自动创建索引功能、准备测试数据和Java环境。
下载ES-Hadoop安装包,并上传至EMR Master节点的HDFS目录下。
创建Java Maven工程,并配置pom依赖。
编写MapReduce写数据到Elasticsearch的Java代码,并打成Jar包上传至EMR集群,最后运行代码完成写数据任务。
在Elasticsearch的Kibana控制台上,查看通过MapReduce写入的数据。
准备工作
创建阿里云Elasticsearch实例,并开启自动创建索引功能。
具体操作步骤请参见创建阿里云Elasticsearch实例和配置YML参数。本文以6.7.0版本的实例为例。
重要在生产环境中,建议关闭自动创建索引功能,提前创建好索引和Mapping。由于本文仅用于测试,因此开启了自动创建索引功能。
创建与Elasticsearch实例在同一专有网络下的EMR实例。
实例配置如下:
产品版本:EMR-3.29.0
必选服务:HDFS(2.8.5),其他服务保持默认
具体操作步骤请参见创建集群。
重要 Elasticsearch实例的私网访问白名单默认为0.0.0.0/0,您可在安全配置页面查看,如果未使用默认配置,您还需要在白名单中加入EMR集群的内网IP地址:- 请参见查看集群列表与详情,获取EMR集群的内网IP地址。
- 请参见配置实例公网或私网访问白名单,配置Elasticsearch实例的VPC私网访问白名单。
准备JSON测试数据,将其写入到map.json文件中,并上传至HDFS的/tmp/hadoop-es目录下。
本文使用的测试数据如下。
{"id": 1, "name": "zhangsan", "birth": "1990-01-01", "addr": "No.969, wenyixi Rd, yuhang, hangzhou"} {"id": 2, "name": "lisi", "birth": "1991-01-01", "addr": "No.556, xixi Rd, xihu, hangzhou"} {"id": 3, "name": "wangwu", "birth": "1992-01-01", "addr": "No.699 wangshang Rd, binjiang, hangzhou"}准备Java环境,要求JDK版本为1.8.0及以上。
步骤一:上传ES-Hadoop JAR包至HDFS
- 下载ES-Hadoop安装包,其版本需要与Elasticsearch实例保持一致。
本文使用elasticsearch-hadoop-6.7.0.zip。
- 登录E-MapReduce控制台,获取Master节点的IP地址,并通过SSH登录对应的ECS机器。
具体操作步骤请参见登录集群。
将已下载的elasticsearch-hadoop-6.7.0.zip上传至Master节点,并解压获得elasticsearch-hadoop-6.7.0.jar。
创建HDFS目录,将elasticsearch-hadoop-6.7.0.jar上传至该目录下。
hadoop fs -mkdir /tmp/hadoop-es hadoop fs -put elasticsearch-hadoop-6.7.0/dist/elasticsearch-hadoop-6.7.0.jar /tmp/hadoop-es
步骤二:配置pom依赖
创建Java Maven工程,并将如下的pom依赖添加到Java工程的pom.xml文件中。
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>WriteToEsWithMR</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop-mr</artifactId>
<version>6.7.0</version>
</dependency>
<dependency>
<groupId>commons-httpclient</groupId>
<artifactId>commons-httpclient</artifactId>
<version>3.1</version>
</dependency>
</dependencies>请确保pom依赖中版本与云服务对应版本保持一致,例如elasticsearch-hadoop-mr版本与阿里云Elasticsearch版本一致;hadoop-hdfs与HDFS版本一致。
步骤三:编写并运行MapReduce任务
编写示例代码。
以下代码会读取HDFS上/tmp/hadoop-es目录下的JSON文件,并将这些JSON文件中的每一行作为一个文档写入Elasticsearch。写入过程由EsOutputFormat在Map阶段完成。
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.util.GenericOptionsParser; import org.elasticsearch.hadoop.mr.EsOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class WriteToEsWithMR extends Configured implements Tool { public static class EsMapper extends Mapper<Object, Text, NullWritable, Text> { private Text doc = new Text(); @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { if (value.getLength() > 0) { doc.set(value); System.out.println(value); context.write(NullWritable.get(), doc); } } } public int run(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); conf.setBoolean("mapreduce.map.speculative", false); conf.setBoolean("mapreduce.reduce.speculative", false); conf.set("es.nodes", "es-cn-4591jumei000u****.elasticsearch.aliyuncs.com"); conf.set("es.port","9200"); conf.set("es.net.http.auth.user", "elastic"); conf.set("es.net.http.auth.pass", "xxxxxx"); conf.set("es.nodes.wan.only", "true"); conf.set("es.nodes.discovery","false"); conf.set("es.input.use.sliced.partitions","false"); conf.set("es.resource", "maptest/_doc"); conf.set("es.input.json", "true"); Job job = Job.getInstance(conf); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(EsOutputFormat.class); job.setMapOutputKeyClass(NullWritable.class); job.setMapOutputValueClass(Text.class); job.setJarByClass(WriteToEsWithMR.class); job.setMapperClass(EsMapper.class); FileInputFormat.setInputPaths(job, new Path(otherArgs[0])); return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { int ret = ToolRunner.run(new WriteToEsWithMR(), args); System.exit(ret); } }表 1. ES-Hadoop相关参数说明 参数
默认值
说明
es.nodes
localhost
指定阿里云Elasticsearch实例的访问地址,建议使用私网地址,可在实例的基本信息页面查看,详情请参见查看实例的基本信息。
es.port
9200
Elasticsearch实例的访问端口号。
es.net.http.auth.user
elastic
Elasticsearch实例的访问用户名。
说明 如果程序中指定elastic账号访问Elasticsearch服务,后续在修改elastic账号对应密码后需要一些时间来生效,在密码生效期间会影响服务访问,因此不建议通过elastic来访问。建议在Kibana控制台中创建一个符合预期的Role角色用户进行访问,详情请参见通过Elasticsearch X-Pack角色管理实现用户权限管控。es.net.http.auth.pass
/
Elasticsearch实例的访问密码。
es.nodes.wan.only
false
开启Elasticsearch集群在云上使用虚拟IP进行连接,是否进行节点嗅探:
true:设置
false:不设置
es.nodes.discovery
true
是否禁用节点发现:
true:禁用
false:不禁用
重要 使用阿里云Elasticsearch,必须将此参数设置为false。es.input.use.sliced.partitions
true
是否使用slice分区:
- true:使用。设置为true,可能会导致索引在预读阶段的时间明显变长,有时会远远超出查询数据所耗费的时间。建议设置为false,以提高查询效率。
- false:不使用。
es.index.auto.create
true
通过Hadoop组件向Elasticsearch集群写入数据,是否自动创建不存在的index:
true:自动创建
false:不会自动创建
es.resource
/
指定要读写的index和type。
es.input.json
false
输入是否已经是JSON格式:
true:是JSON格式
false:不是JSON格式
es.mapping.names
/
表字段与Elasticsearch的索引字段名映射。
es.read.metadata
false
操作Elasticsearch字段涉及到_id之类的内部字段,请开启此属性。
更多的ES-Hadoop配置项说明,请参见官方配置说明。
将代码打成Jar包,上传至EMR客户端机器(例如Gateway或EMR集群主节点)。
在EMR客户端机器上,运行如下命令执行MapReduce程序。
hadoop jar es-mapreduce-1.0-SNAPSHOT.jar /tmp/hadoop-es/map.json说明es-mapreduce-1.0-SNAPSHOT.jar需要替换为您已上传的Jar包名称。
步骤四:验证结果
登录对应阿里云Elasticsearch实例的Kibana控制台。
具体操作步骤请参见登录Kibana控制台。
在左侧导航栏,单击Dev Tools。
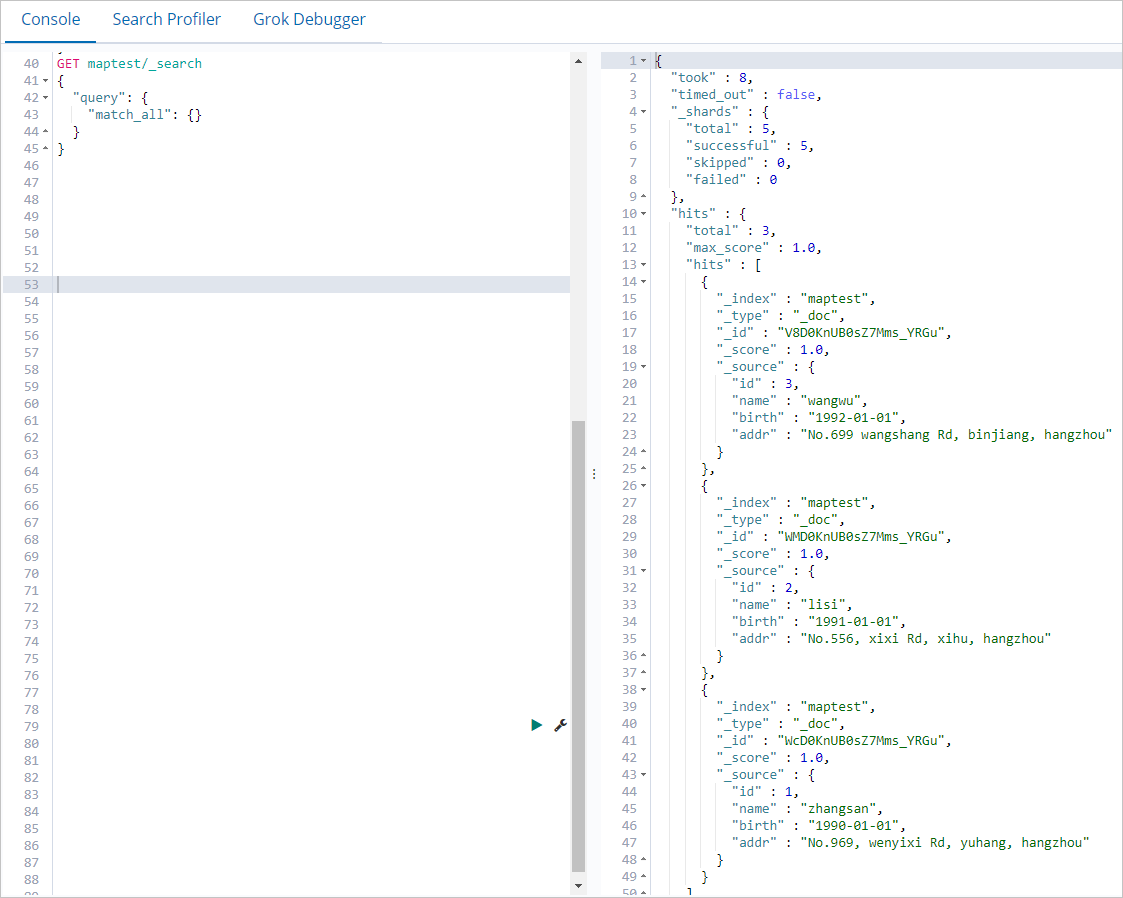
在Console页签下,执行以下命令,查看通过MapReduce任务写入的数据。
GET maptest/_search { "query": { "match_all": {} } }查询成功后,返回结果如下。
总结
本文以阿里云Elasticsearch和EMR为例,介绍了如何通过ES-Hadoop,借助MapReduce任务向Elasticsearch写入数据。相反,您也可以借助MapReduce任务查询Elasticsearch数据。查询配置和写入类似,详细说明可参见官方Reading data from Elasticsearch说明。