数据集成目前支持将MySQL、PolarDB、SQL Server等源头的数据整库离线同步至Elasticsearch。本文以MySQL为源端、Elasticsearch为目标端场景为例,为您介绍如何将MySQL整个数据库的数据离线同步至Elasticsearch。
前提条件
操作步骤
一、选择同步任务类型
进入数据集成页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据集成。
在左侧导航栏单击同步任务,然后在页面顶部单击新建同步任务,进入同步任务的创建页面,配置如下基本信息。
数据来源和去向:
MySQL→Elasticsearch新任务名称:自定义同步任务名称。
同步类型:
整库离线同步至Elasticsearch。
二、网络与资源配置
在网络与资源配置区域,选择同步任务所使用的资源组。您可以为该任务分配任务资源占用CU数。
来源数据源选择已添加的
MySQL数据源,去向数据源选择已添加的Elasticsearch数据源后,单击测试连通性。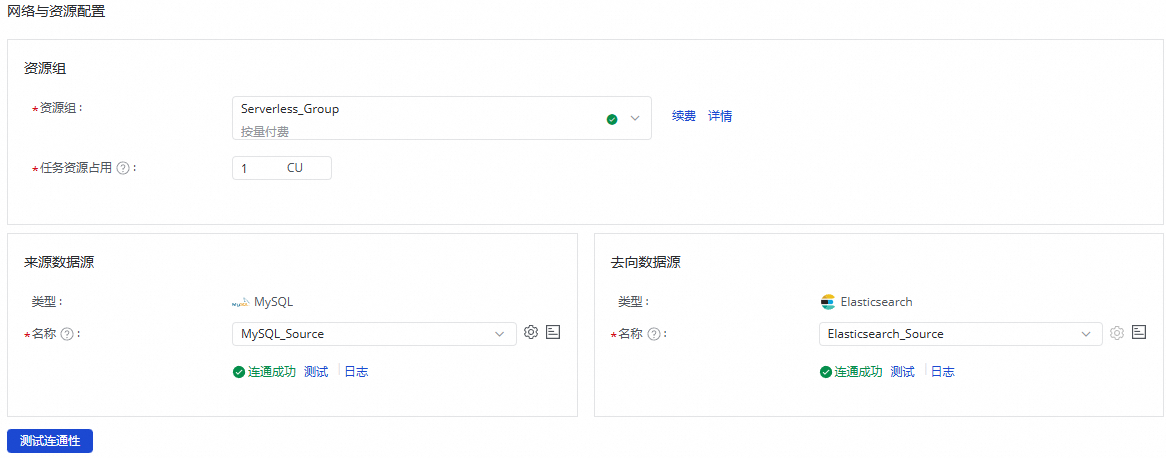
确保来源数据源与去向数据源均连通成功后,单击下一步。
三、设置同步来源和规则
选择需要同步的表。
此步骤中,您可以在源端库表区域选择源端数据源下需要同步的表,并单击
 图标,将其移动至右侧已选库表。
图标,将其移动至右侧已选库表。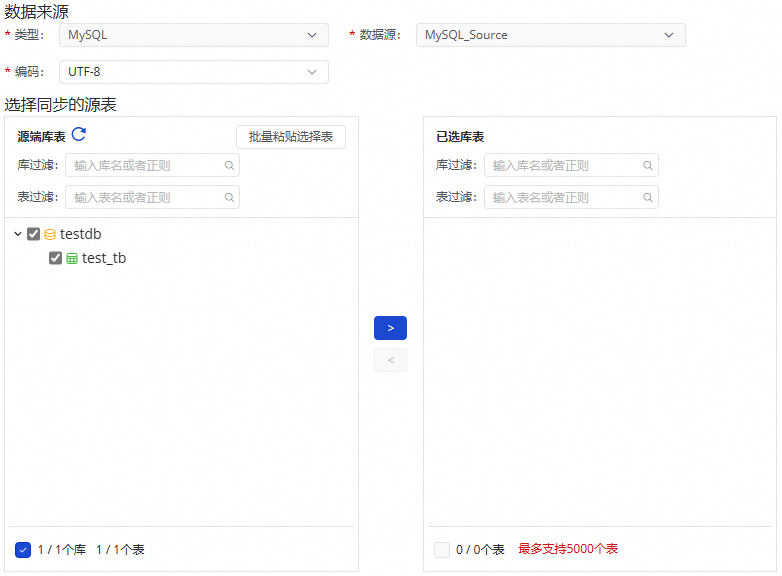
设置表名到索引名的映射规则。
选择源端数据源中需要同步的库和表后,同步任务默认将源端数据库、数据表写入目标端同名schema或同名表中,如果目标端不存在该schema或表,将会自动创建。同时,您可以通过设置表名到索引名的映射规则自定义最终写入目标端的Schema或索引名称。
配置说明:
源库名和目标Schema名转换规则:所有的该转换规则都是针对原始库名的转换,转换完成之后的结果可以使用
${db_name_src_transed},在目标索引名规则中作为变量来使用。重要如果不使用目标索引名规则,则此规则将直接影响最终实际目标Schema名。
如果使用目标索引名规则,则此规则不仅影响变量
${db_name_src_transed}的值,还会影响最终实际目标Schema名。
源表名和目标索引名转换规则:所有的该转换规则都是针对原始表名的转换,转换完成之后的结果可以使用
${db_table_name_src_transed},在目标索引名规则中作为变量来使用。重要如果不使用目标索引名规则,则此规则将直接影响最终实际目标索引名。
如果使用目标索引名规则,则此规则将只影响变量
${db_table_name_src_transed}的值,不直接影响最终实际目标索引名。最终目标索引名由目标索引名规则决定。
目标索引名规则:可以使用内置的变量命名目标索引名。
可以使用的内置变量有:
${db_table_name_src_transed}:“源表名和目标索引名转换规则”中的转换完成之后的索引名。${db_name_src_transed}:“源库名和目标Schema名转换规则”中的转换完成之后的目标Schema名。${ds_name_src}:源数据源名。
例如,将源端
doc_前缀的库名替换为pre_前缀、将源端table_01、table_02和table_03的表同步至一个名为my_table的索引中,最终为这个索引添加后缀_post。应该做如下配置: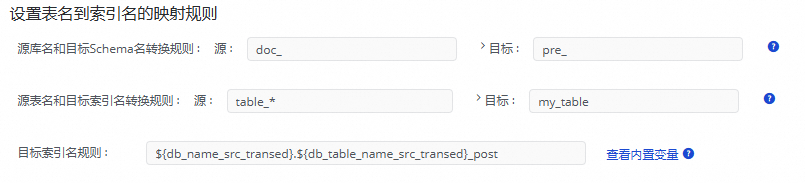
单击下一步,设置目标索引。
四、设置目标索引
单击刷新源表和Elasticsearch 索引映射将根据您在步骤三配置的设置表名到索引名的映射规则来生成目标索引,若步骤三未配置映射规则,将默认写入与源表同名的目标索引,若目标端不存在该同名索引,将默认新建。同时,您可以修改同步主键、索引建立方式。
目标表名将根据您在设置表名到索引名的映射规则阶段配置的表名转换规则自动转换。
在同步主键列,选择主键替代方案。
如果来源库有主键,则同步数据时会直接使用该主键进行去重。
如果来源库没有主键,则您需要单击
 图标,自定义主键,即使用其他非主键的一个或几个字段的联合,代替主键进行同步数据时进行去重判断。
图标,自定义主键,即使用其他非主键的一个或几个字段的联合,代替主键进行同步数据时进行去重判断。
在索引建立方式列,选择自动建索引或使用已有索引。
当索引建立方式选择自动建索引时,Elasticsearch索引名列显示自动创建的Elasticsearch索引名。您可以单击索引名称,查看和修改索引相关属性。
当索引建立方式选择使用已有索引时,您可以在Elasticsearch索引名列对应的下拉列表中选择需要使用的索引名称。
单击下一步,设置同步规则。
五、同步规则设置
当前支持以下整库离线同步方案,您可以按需选择,不同同步方案,需配置的参数存在差异。
同步方案 | 描述 |
全量一次性同步后周期性增量 | 先将来源数据源的所有数据全量同步至Elasticsearch,再按照指定的过滤条件和周期任务,后续每次执行任务时仅将增量数据同步至Elasticsearch中。 |
只全量一次性同步 | 只执行一次同步操作,将来源数据源的所有数据,全量同步至Elasticsearch中。 |
只增量一次性同步 | 只执行一次同步操作,按照指定的过滤条件,将来源数据源的增量数据同步至Elasticsearch中。 |
周期性全量同步 | 按照配置的周期任务,每次执行任务时都将来源数据源的所有数据,全量同步至Elasticsearch中。 |
周期性增量同步 | 按照指定的过滤条件和周期任务,每次执行任务时仅将增量数据同步至Elasticsearch中。 |
全量一次性同步后周期增量
全量同步 | |
参数 | 参数说明 |
写入前清空对应的原有index(索引) |
重要 配置该参数为是时,则会在写入数据前删除目标索引中所有的数据,请谨慎选择。 |
写入类型 |
|
每批次写入的条数 | 每次批量写入Elasticsearch的数据条数,即攒够一定条数的数据后,一次性写入Elasticsearch。默认为 |
增量同步 | |
写入类型 |
|
每批次写入的条数 | 每次批量写入Elasticsearch的数据条数,即攒够一定条数的数据后,一次性写入Elasticsearch。默认为 |
增量条件 | 您可通过WHERE语句对待同步的数据表进行过滤,且只需在增量条件框中填写WHERE子句,无需写WHERE关键字。同时,在写WHERE子句时,您可以使用系统内置变量,例如使用 |
周期设置 | |
由于需要进行周期性调度,所以需要在此定义周期性调度任务时的相关属性,包括调度周期、生效日期、暂停调度等。当前同步的调度配置与数据开发中节点的调度配置一致,参数详情可参见节点调度。 | |
只全量一次性同步
全量同步 | |
参数 | 参数说明 |
写入前清空对应的原有index(索引) |
重要 配置该参数为是时,则会在写入数据前删除目标索引中所有的数据,请谨慎选择。 |
写入类型 |
|
每批次写入的条数 | 每次批量写入Elasticsearch的数据条数,即攒够一定条数的数据后,一次性写入Elasticsearch。默认为 |
只增量一次性同步
增量同步 | |
参数 | 参数说明 |
写入类型 |
|
每批次写入的条数 | 每次批量写入Elasticsearch的数据条数,即攒够一定条数的数据后,一次性写入Elasticsearch。默认为 |
增量条件 | 您可通过WHERE语句对待同步的数据表进行过滤,且只需在增量条件框中填写WHERE子句,无需写WHERE关键字。同时,在写WHERE子句时,您可以使用系统内置变量,例如使用 |
周期性全量同步
全量同步 | |
参数 | 参数说明 |
写入前清空对应的原有index(索引) |
重要 配置该参数为是时,则会在写入数据前删除目标索引中所有的数据,请谨慎选择。 |
写入类型 |
|
每批次写入的条数 | 每次批量写入Elasticsearch的数据条数,即攒够一定条数的数据后,一次性写入Elasticsearch。默认为 |
周期设置 | |
由于需要进行周期性调度,所以需要在此定义周期性调度任务时的相关属性,包括调度周期、生效日期、暂停调度等。当前同步的调度配置与数据开发中节点的调度配置一致,参数详情可参见节点调度。 | |
周期性增量同步
增量同步 | |
参数 | 参数说明 |
写入类型 |
|
每批次写入的条数 | 每次批量写入Elasticsearch的数据条数,即攒够一定条数的数据后,一次性写入Elasticsearch。默认为 |
增量条件 | 您可通过WHERE语句对待同步的数据表进行过滤,且只需在增量条件框中填写WHERE子句,无需写WHERE关键字。同时,在写WHERE子句时,您可以使用系统内置变量,例如使用 |
周期设置 | |
由于需要进行周期性调度,所以需要在此定义周期性调度任务时的相关属性,包括调度周期、生效日期、暂停调度等。当前同步的调度配置与数据开发中节点的调度配置一致,参数详情可参见节点调度。 | |
配置完成后,单击下一步,设置运行资源。
六、设置运行资源
根据上一步选择的不同同步方案,此步骤需设置的运行资源存在差异。同步任务将分别创建全量离线同步任务和增量离线同步任务,您可以配置任务名称及任务执行所使用的资源组(全量离线任务资源组、增量离线任务资源组、调度资源组),同时,您可通过高级配置修改数据集成提供的任务期望最大并发数、同步速率、容忍脏数据、来源端读取支持最大连接数等高级参数。
七、执行同步任务
完成所有配置后,单击页面底部的完成配置。
在界面,找到已创建的同步任务,单击操作列的提交执行。
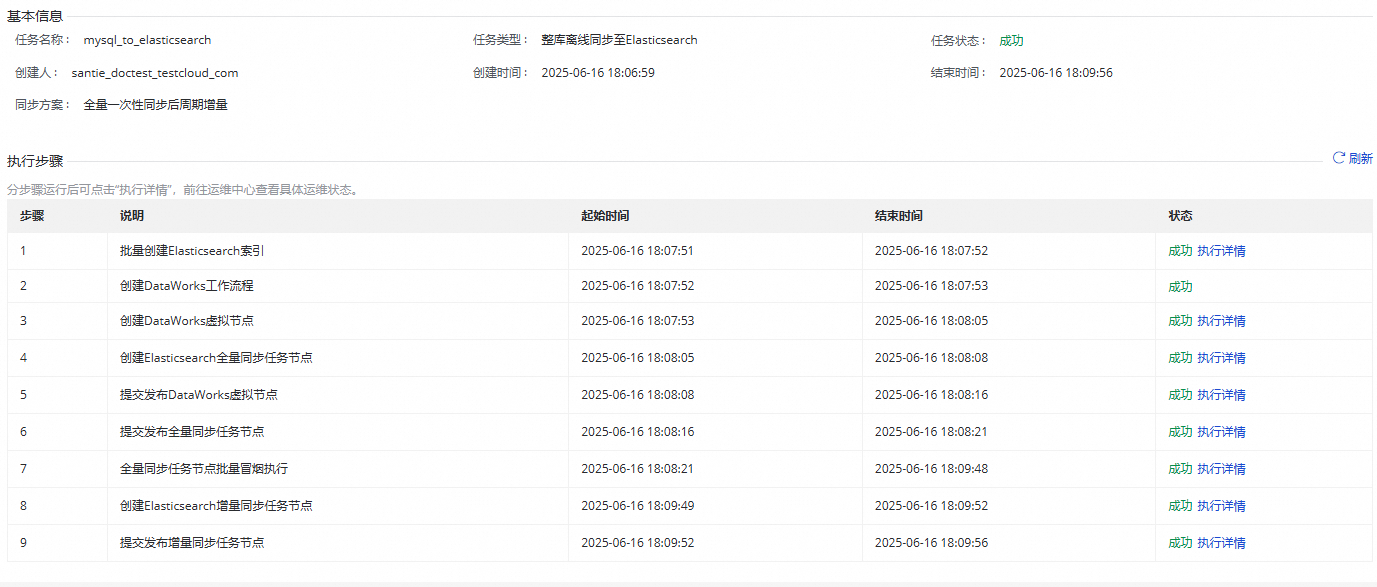
单击任务列表中对应任务的名称/ID,查看任务的详细执行过程。
同步任务运维
查看任务运行状态
创建完成同步任务后,您可以在同步任务页面查看当前已创建的同步任务列表及各个同步任务的基本信息。
您可以在操作列单击执行详情,进入任务详情页,查看任务执行情况。