
inference-xpu-pytorch 25.11
本文介绍inference-xpu-pytorch 25.11版本发布记录。
PPU SDK 1.7.0之前的绑定SDK发布Python软件包的方式会导致迭代周期过长,难以满足日益加快的社区更新节奏。从PPU SDK 1.7.0开始PPU运行环境实现了Python软件包与PPU SDK解耦机制:PPU SDK只有重大功能增强/更新才发布版本,不再按月迭代;社区新模型、框架会通过Python 软件包敏捷发布来支持。
由于PPU SDK迭代节奏的变化,PPU容器镜像也不再按月迭代,PPU容器镜像跟随PPU SDK发布同步更新版本,作为后续新SDK版本前的Base运行环境。新模型/新框架可以在最新的Base运行环境上自行升级获得相应功能/特性的支持。
Main Features and Bug Fix Lists
Main Features
25.11-v1.7.0-vllm0.10.2-torch2.8-cu129-20251113和25.11-v1.7.0-sglang0.5.2-torch2.8-cu129-20251113镜像:
PPU SDK升级至1.7.0,CUDA版本升级至12.9。
PyTorch版本升级至2.8.0。
vLLM版本升级至0.10.2,如运行Qwen3-VL、DeepSeek v3.2模型,需要自助升级vLLM到0.11.0版本。
SGLang版本升级至0.5.2,FlashInfer升级至0.3.1,Flash Attention升级至2.8.2;如运行Qwen3-VL模型,需要自助升级SGLang至0.5.3版本或自助升级SGLang至0.5.5版本。
25.11-v1.7.0.post1-sglang0.5.5-torch2.8-cu129-20251216镜像:
PPU SDK 升级至V1.7.0_hotfix。
SGLang版本升级至0.5.5,FlashInfer升级至0.4.0rc3。
25.11-v1.7.0.post1-vllm0.11.1-torch2.8-cu129-20260105镜像:
PPU SDK 升级至V1.7.0_hotfix。
vLLM版本升级至0.11.1 。
transformers版本升级至4.57.0。
Bug Fix
25.11-v1.7.0.post1-sglang0.5.5-torch2.8-cu129-20251216镜像修复了多机场景下多个PCCL P2P操作融合到一起执行时,因proxy参数(sub args)编排出错导致的crash问题。
Contents
镜像名称 | inference-xpu-pytorch | |||
镜像Tag | 25.11-v1.7.0-vllm0.10.2-torch2.8-cu129-20251113 | 25.11-v1.7.0-sglang0.5.2-torch2.8-cu129-20251113 | 25.11-v1.7.0.post1-sglang0.5.5-torch2.8-cu129-20251216 | 25.11-v1.7.0.post1-vllm0.11.1-torch2.8-cu129-20260105 |
应用场景 | 大模型推理 | 大模型推理 | 大模型推理 | 大模型推理 |
框架 | pytorch | pytorch | pytorch | pytorch |
Requirements | PPU SDK V1.7.0 | PPU SDK V1.7.0 | PPU SDK V1.7.0_hotfix | PPU SDK V1.7.0_hotfix |
系统组件 |
|
|
|
|
镜像Asset
通过公网拉取ACS AI容器镜像需要先获取鉴权密钥。建议您使用VPC方式加速拉取AI容器镜像,减少镜像拉取的时间。
公网镜像
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/inference-xpu-pytorch:25.11-v1.7.0-vllm0.10.2-torch2.8-cu129-20251113
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/inference-xpu-pytorch:25.11-v1.7.0-sglang0.5.2-torch2.8-cu129-20251113
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/inference-xpu-pytorch:25.11-v1.7.0.post1-sglang0.5.5-torch2.8-cu129-20251216
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/inference-xpu-pytorch:25.11-v1.7.0.post1-vllm0.11.1-torch2.8-cu129-20260105
VPC镜像
将指定的AI容器镜像Asset URIegslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/{image:tag}替换为acs-registry-vpc.{region-id}.cr.aliyuncs.com/egslingjun/{image:tag}即可在VPC内快速拉取PPU AI容器镜像。
{region-id}:ACS产品开服地域(包括金融云、政务云等)的地域ID。例如:cn-beijing、cn-wulanchabu、cn-shanghai-finance-1等。{image:tag}:AI容器镜像的名称和Tag。例如:inference-xpu-pytorch:25.11-v1.7.0-vllm0.10.2-torch2.8-cu129-20251113、training-xpu-pytorch:25.11等。
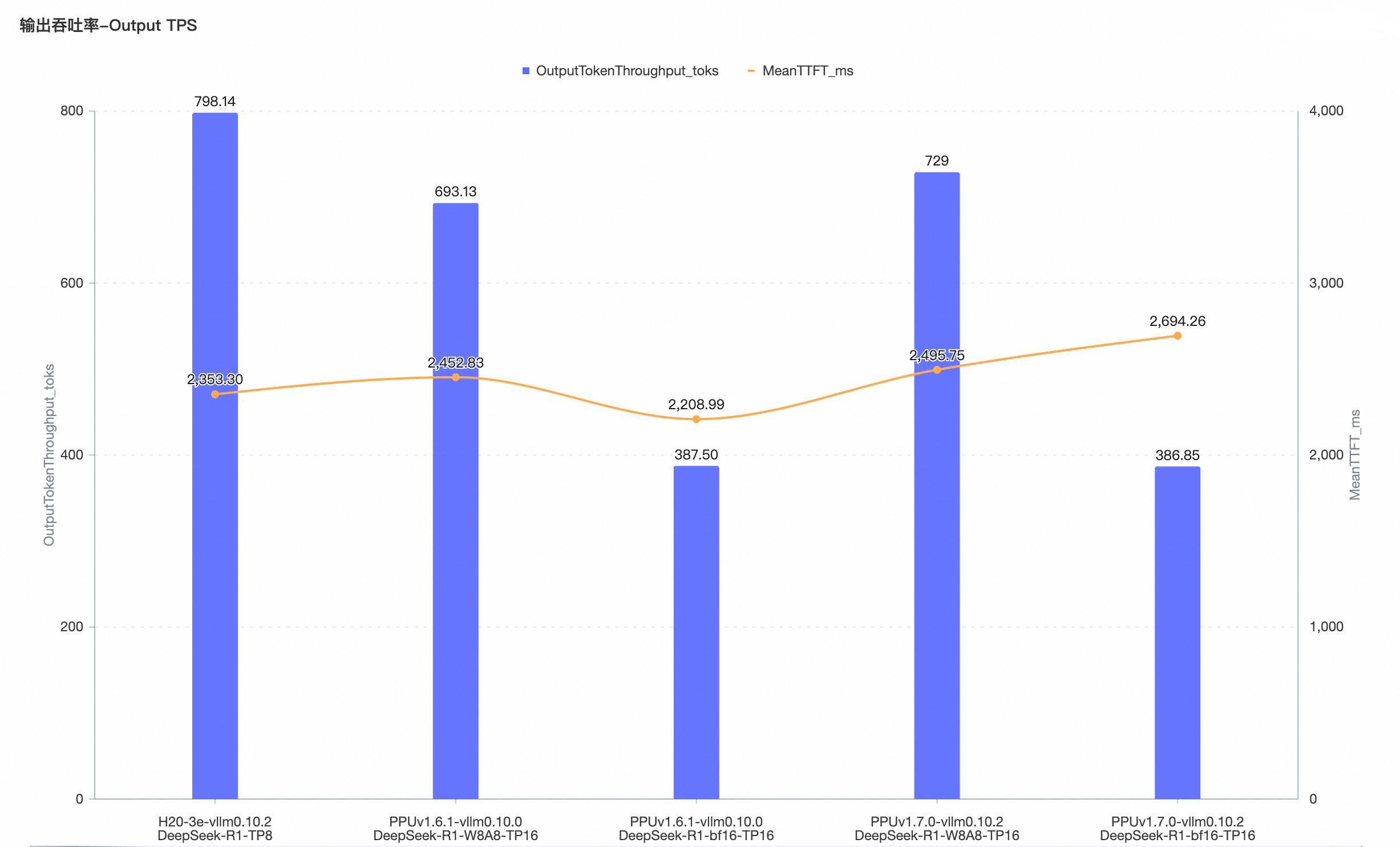
E2E性能评估
vLLM在线推理模式下,设置输入输出Token长度为4096/2048,控制TTFT<3s 并且 TPOT<100ms ,测试满足条件的最大并发量,对比吞吐。
DeepSeek-R1-bf16、DeepSeek-R1-W8A8模型单机 Output Token Throughput 性能相比25.09版本略有提升。
Quick Start
以下示例内容仅通过Docker方式拉取inference-xpu-pytorch镜像,并使用Qwen2.5-7B-Instruct模型测试推理服务。
在ACS中使用inference-xpu-pytorch镜像可以通过控制台创建工作负载时输入指定镜像地址,或者通过YAML文件指定镜像引用。
在ACS环境下使用xpu大模型推理镜像的使用指导,请参见ACS集群形态的LLM大模型推理镜像使用指导。
在ACS环境下部署DeepSeek推理服务的使用指导,请参见在ACS中使用PPU快速部署DeepSeek V3/R1推理服务。
拉取推理容器镜像。
说明通过公网拉取ACS AI容器镜像需要先获取鉴权密钥。建议您使用VPC方式加速拉取AI容器镜像,减少镜像拉取的时间。
docker pull egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/inference-xpu-pytorch:[tag]从ModelScope下载开源模型。
pip install modelscope cd /mnt modelscope download --model Qwen/Qwen2.5-7B-Instruct --local_dir ./Qwen2.5-7B-Instruct启动以下命令进入容器。
docker run -d -t --network=host --privileged --init --ipc=host \ --ulimit memlock=-1 --ulimit stack=67108864 \ -v /mnt/:/mnt/ \ egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/inference-xpu-pytorch:[tag]执行推理测试,测试vLLM推理对话功能。
启动Server端服务。
python3 -m vllm.entrypoints.openai.api_server \ --model /mnt/Qwen2.5-7B-Instruct \ --trust-remote-code --disable-custom-all-reduce \ --tensor-parallel-size 1在Client端进行测试。
curl http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "/mnt/Qwen2.5-7B-Instruct", "messages": [ {"role": "system", "content": "你是个友善的AI助手。"}, {"role": "user", "content": "介绍一下深度学习。"} ]}'输出如下所示:

更多关于vLLM的使用方法,请参见vLLM。
使用建议
SDK 1.7.0 各框架支持的标准量化能力:
vLLM 0.10.2(镜像内置)/ 0.11.0(通过PIP升级):支持 per-token/per-channel a8w8(int8)、AWQ(w4a16)、GPTQ (w4a16、w8a16)量化方案
SGLang 0.5.2(镜像内置)/ 0.5.3(通过PIP升级)/ 0.5.5(通过PIP升级):支持per-token/per-channel a8w8(int8)、AWQ(w4a16)、GPTQ (w4a16、w8a16)量化方案
运行 a8w8(int8)量化模型需要加
--quantization w8a8_int8选项。提供适配SDK1.7.0的量化模型示例,系统登录账密复用PTG PIP账密(可联系您的PDSA获取):
DeepSeek-R1:支持 per-token/per-channel a8w8(int8)量化方案。
DeepSeek v3.2:支持 per-token/per-channel a8w8(int8)量化方案。
Kimi-K2-Instruct:支持 per-token/per-channel a8w8(int8)量化方案。
Qwen3-235B-A22B:支持 per-token/per-channel a8w8(int8)量化方案。
建议配合“1.5.1”及以上版本驱动使用本镜像获得最佳性能,设置方法请参考为ACS GPU Pod指定GPU型号和驱动版本和GPU驱动版本说明。
在ACS环境使用AcclEP-P(即PPU版本的DeepEP) ,需要设置环境变量
export EIC_VSOLAR=1(本镜像需要设置,预计后续镜像移除该限制)本镜像内置环境变量
NCCL_SOCKET_IFNAME需要根据使用场景动态调整:当单Pod只申请了1/2/4/8卡进行推理任务时:需要设置
NCCL_SOCKET_IFNAME=eth0(本推理镜像内默认配置)。当单Pod申请了整机的16卡(此时您可以使用HPN高网)进行推理任务时:需要设置
NCCL_SOCKET_IFNAME=hpn0。
本镜像建议配合使用“在ACS产品使用阿里云提供的PPU PIP服务”,支持在ACS VPC内一站式免密使用PIP服务,不需要再组合使用其他PIP源。本镜像内已经内置了相应的pip config,还需要您结合您的使用场景根据文档的指引做必要的配置。
Known Issues
vLLM0.10.2性能问题
Qwen 模型由于 fused moe 中 fused_topk 没有使用 torch.compile 包裹,导致模型性能相比前序版本有回退,开源社区上已经有 patch 修复,预计在 vllm 0.11.1 上合入。详细内容,请参考GitHub社区内容。
vLLM双机场景,容器镜像里transformers >= 4.56.0并且安装了torchao,会导致运行失败。GPU上也存在相同的问题。可以通过卸载torchao解决。
SGLang
DeepGemm为运行时编译,测试性能时请确保warmup充分。
DeepSeek v3.2目前必须打开dp-attention,尚不支持TP并行。
Qwen-235B-A22B短输出(output_len=400)有性能回退。
DeepSeek-R1 in900, out400 SLA测试场景最大并发未达到最大吞吐。
DeepSeek-R1 PD分离场景SGLang0.5.5性能相比SGLang 0.5.2有20%回退。原因是SGLang社区从0.5.3版本开始去除了
load balance method = minimum_tokens的支持,所以理论上H20也存在性能回退。更多内容,请参考GitHub社区PR。
附录
附录一:vLLM镜像(内置vLLM0.10.2)自助升级vLLM至0.11.0以支持 Qwen3-VL、DeepSeek V3.2模型
目前提供的vLLM 0.11.0为功能预览版,可能存在潜在的稳定性风险。
前提条件
需完成配置PPU PIP源,开启PPU PIP免密、Pod YAML中增加ServiceAccount、安装免密插件等前置步骤。详细操作,请参见在ACS上使用PPU PIP服务。
升级步骤
pip uninstall vllm -y
pip install vllm==0.11.0+ppu1.7.0
# DON'T use numpy 2
pip install numpy==1.26.4
# upgrade transformers
pip install transformers==4.57.0
# 如果运行DeepSeek v3.2模型,可选步骤
# pip install scikit-learn==1.7.1检查环境
pip list | grep vllm
pip list | grep transformers
pip list | grep numpy附录二:SGLang镜像(内置SGLang0.5.2)自助升级SGLang至0.5.3以支持 Qwen3-VL模型
目前提供的SGL 0.5.3为功能预览版,可能存在潜在的稳定性风险。
由于是强制升级,部分组件升级过程有报错信息属预期行为,需关注组件最终是否实际升级安装成功。
前提条件
需完成配置PPU PIP源,开启PPU PIP免密、Pod YAML中增加ServiceAccount、安装免密插件等前置步骤。详细操作,请参见在ACS上使用PPU PIP服务。
升级步骤
# uninstall sglang sgl-kernel
pip uninstall -y sglang sgl-kernel
# intall sgl-kernel
pip install sgl_kernel==0.3.14.post1+ppu1.7.0 --force-reinstall
# install sglang
pip install sglang==0.5.3+ppu1.7.0 --no-deps --force-reinstall
# install transformers
pip install -U transformers==4.57.1 openai_harmony --force-reinstall
# install fast_hadamard_transform / numpy
pip install fast_hadamard_transform numpy==1.26.0
# 可选升级flashinfer(如果不升级flashinfer,可以使用triton后端,即在命令中添加 --attention-backend triton)
# pip install flashinfer_python==0.4.0rc3+ppu1.7.0.oe --force-reinstall --no-deps检查环境
pip list | grep sgl
pip list | grep transformer附录三:SGLang镜像(内置SGLang0.5.2)自助升级SGLang至0.5.5
目前提供的SGL 0.5.5为功能预览版,可能存在潜在的稳定性风险。
由于是强制升级,部分组件升级过程有报错信息属预期行为,需关注组件最终是否实际升级安装成功。
前提条件
需完成配置PPU PIP源,开启PPU PIP免密、Pod YAML中增加ServiceAccount、安装免密插件等前置步骤。详细操作,请参见在ACS上使用PPU PIP服务。
升级步骤
# SGLang升级
## sgl-kernel / sglang-router / sglang
pip uninstall -y sgl-kernel sglang-router sglang
pip install sgl-kernel==0.3.16.post5+ppu1.7.0.post1 --force-reinstall --no-deps
pip install sglang-router==0.2.2+ppu1.7.0.post1 --force-reinstall --no-deps
pip install sglang==0.5.5+ppu1.7.0.post1 --force-reinstall --no-deps
# DeepGemm升级
pip install deep_gemm==1.0.0+ppu1.7.0.post1 --force-reinstall --no-deps
# DeepEP升级
pip install deep_ep==1.0.0+ppu1.7.0.post1 --force-reinstall --no-deps
# FA 2.8.2升级
pip install flash_attn==2.8.2+ppu1.7.0.post1 --force-reinstall --no-deps
pip install flash_attn_3==2.8.2+ppu1.7.0.post1 --force-reinstall --no-deps
# FlashMLA升级
pip install flash_mla==1.0.0+ppu1.7.0.post1 --force-reinstall --no-deps
# xgrammar和transformers版本升级
pip install -U xgrammar==0.1.25 transformers==4.57.1 numpy==1.26.0 --force-reinstall --no-deps
# flashinfer升级
pip install flashinfer_python==0.4.0rc3+ppu1.7.0.oe --force-reinstall --no-deps检查环境
pip list | grep sglang
# 预期输出
sglang 0.5.5+ppu1.7.0.post1
sglang-router 0.2.2+ppu1.7.0.post1pip list | grep flash
# 预期输出
flash-attn 2.8.2+ppu1.7.0.post1
flash-attn-3 2.8.2+ppu1.7.0.post1
flash_mla 1.0.0+ppu1.7.0.post1
flashinfer-python 0.4.0rc3+ppu1.7.0.oepip list | grep transformers
# 预期输出
transformers 4.57.1