什么是OpenLake
概述
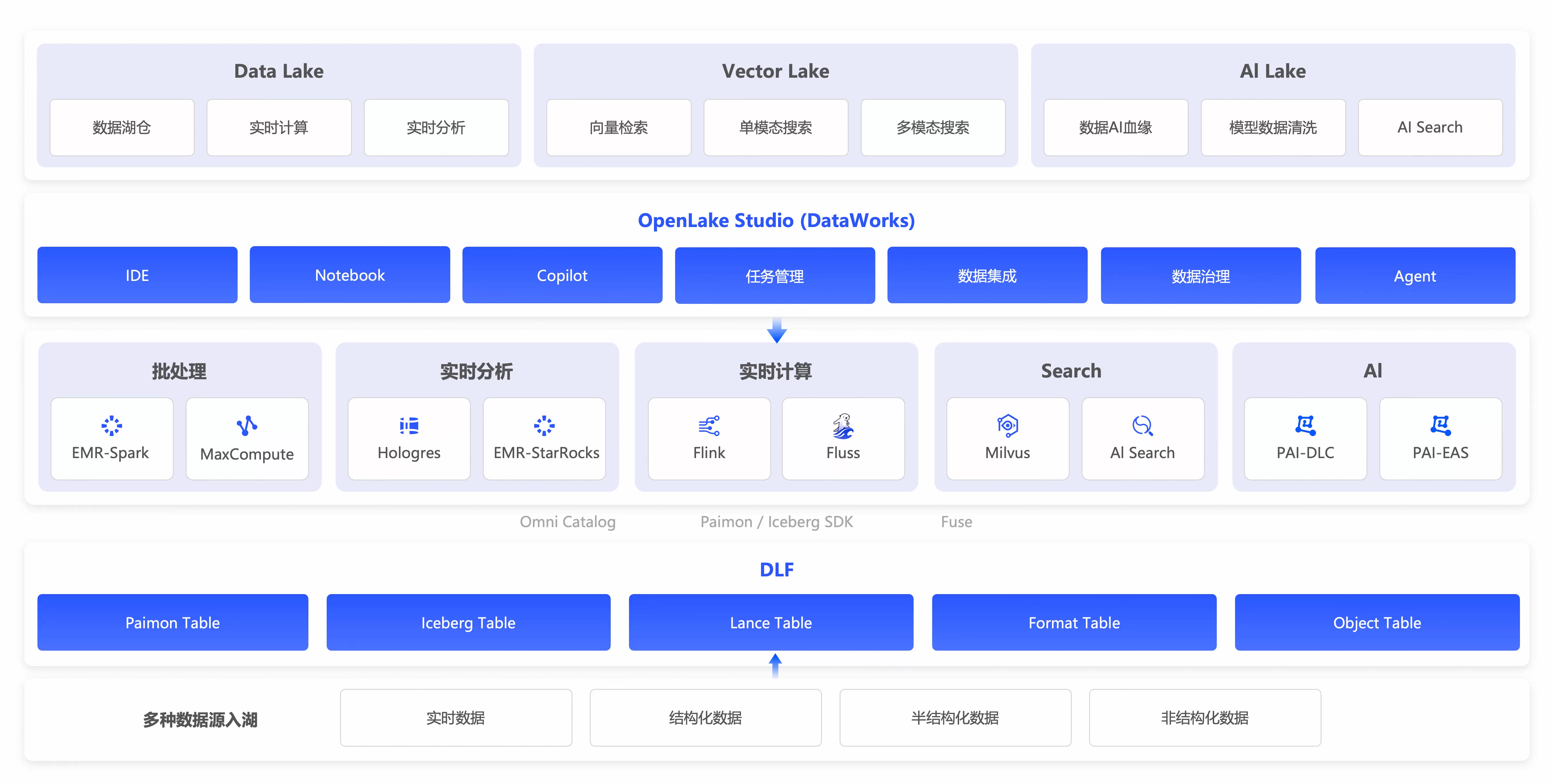
阿里云 OpenLake 是一款面向大数据、搜索与人工智能一体化场景的新一代开放湖仓平台。该平台基于数据湖形成(Data Lake Formation,DLF)构建统一的元数据目录,融合了结构化、半结构化、非结构化及向量数据,实现了“一份数据、多引擎协同、全域检索、全链路治理”的 Agentic Data 架构。
OpenLake 支持 Paimon、Iceberg、Lance 等主流开放表格式,打通了从数据入湖、特征工程、向量化、检索增强到大模型训练与推理的完整闭环,为企业提供高性能、低成本、高可用、易治理的多模态数据基础设施。
该平台适用于互联网、金融、零售、制造、教育、自动驾驶等需要处理多模态数据并构建人工智能原生应用的企业。
产品优势
开放标准,打破数据孤岛
全面兼容 Paimon、Iceberg、Lance 等开源表格式,支持 Parquet、ORC、Avro、CSV 等开放文件标准。
无缝对接 Spark、Flink、Trino、StarRocks、Hologres、MaxCompute 等主流计算引擎,避免数据迁移与格式转换成本。
基于 DLF Omni Catalog 实现五类数据(结构化、半结构化、非结构化、向量、流式)统一编目,真正实现“一次入湖、多处可用”。
高性能引擎协同,计算高效
多引擎(Spark/Flink/StarRocks/Hologres/MaxCompute)平权访问同一份湖数据,无需冗余拷贝。
通过 DLF 统一元数据服务,实现跨引擎 权限一致、Schema 同步、事务隔离。
批处理、流计算、交互式查询与 AI 训练共享存储,显著提升资源利用率与端到端效率。
支持高并发、低延迟混合负载,满足 T+1 批处理与秒级实时分析并存场景。
统一开发治理,降低复杂度
通过 OpenLake Studio(集成于 DataWorks)提供 Notebook + SQL IDE + 可视化调度 一体化开发体验。
元数据、数据权限、血缘追踪、任务编排、质量监控集中管理,实现“开发即治理”。
支持大规模、高并发任务调度,保障企业级 SLA 与稳定性。
全链路可追溯、可审计、可回滚,满足合规要求。
Data + Search + AI 融合,释放数据价值
融合结构化表、非结构化文件(图像/音视频/文档)与向量数据,构建多模态统一湖仓。
原生支持 SQL 查询、全文检索(OpenSearch/Elasticsearch)与向量相似性搜索(Milvus/PgVector)。
为大模型 RAG、智能 Agent 提供高质量、可检索、可治理的数据供给管道。
打通“数据入湖 → 特征工程 → 向量化 → 检索增强 → 模型推理”全链路,加速 AI 应用落地。
核心功能
功能 | 说明 | 文档链接 |
统一元数据与表管理 | 通过 DLF 支持 Paimon/Iceberg/Lance/Parquet 等格式的统一目录 | |
存储成本优化 | 基于 OSS 智能分层、压缩与生命周期策略,降低存储成本 | |
实时湖流一体 | Flink + Fluss + DLF 实现秒级入湖、分钟级可见 | |
企业级高性能引擎 | 集成 Serverless Spark、Flink、Hologres、MaxCompute 等云原生引擎 | 什么是EMR Serverless Spark、什么是阿里云实时计算Flink版、什么是实时数仓Hologres、什么是MaxCompute |
大数据 & AI 协同开发 | OpenLake Studio 融合 Notebook、SQL 与可视化调度 | |
Agent & Copilot 集成 | OpenLake Agent / MCP 协议支持多模态智能体直接访问湖仓 |
典型架构方案
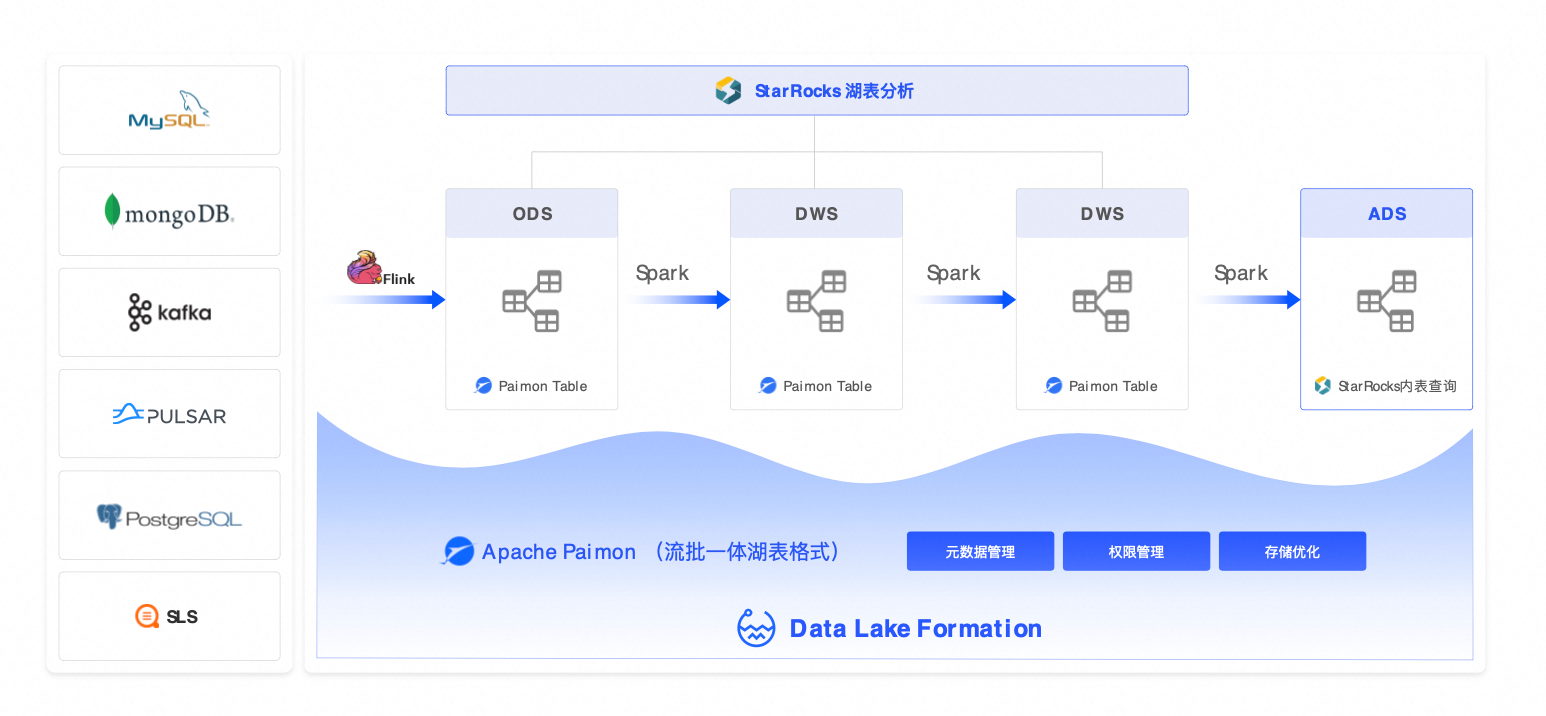
方案一:经典湖仓架构(Serverless Spark + StarRocks + DLF)
适用场景:T+1批处理为主,旨在实现高性价比和免运维的离线分析场景(例如报表、商业智能、用户画像)。
组件:EMR Serverless Spark(批处理) + StarRocks(亚秒级查询) + DLF(统一元数据)。
替代方案:AWS Redshift + Glue、Databricks(批处理)、Hive + Presto。
优势:成本降低 30%+,查询性能提升 3–5 倍,免运维。
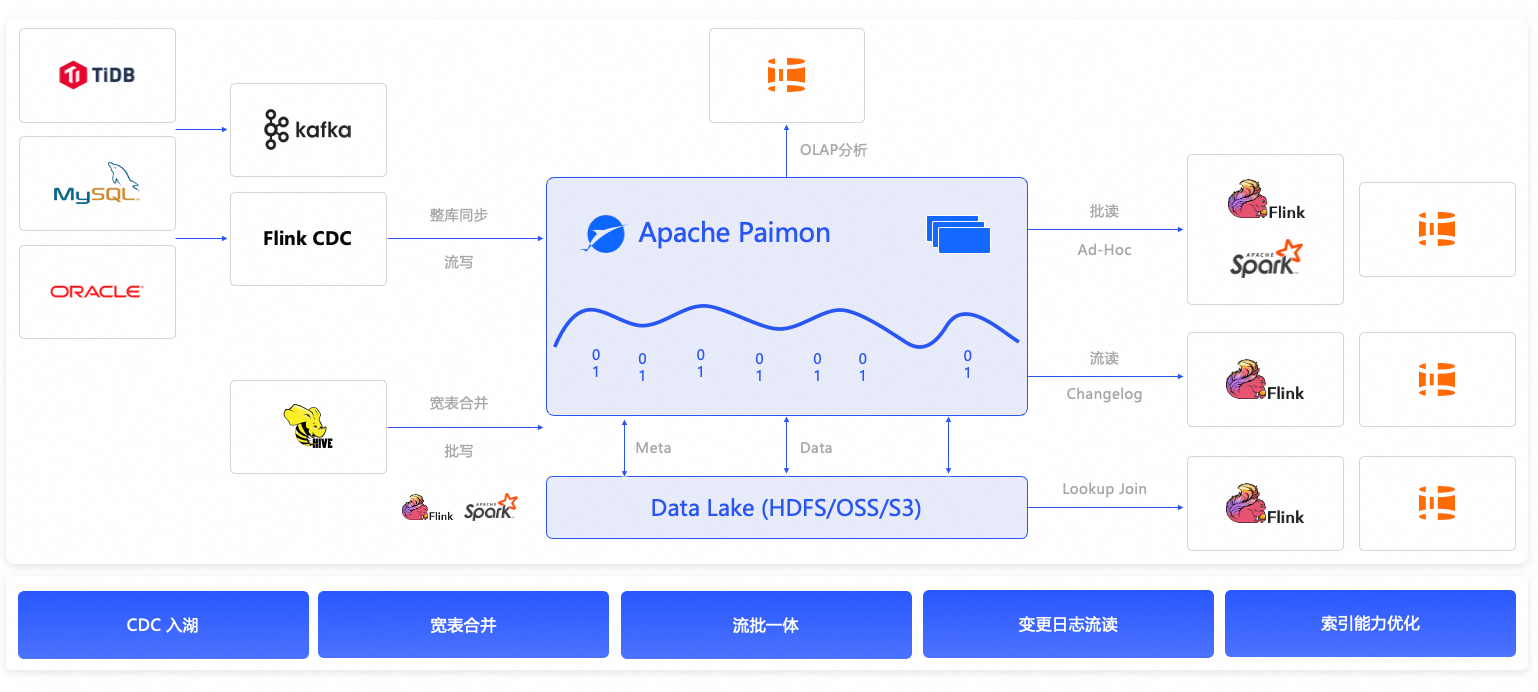
方案二:流式湖仓架构(Flink + Hologres + DLF)
适用场景:秒级~分钟级近实时分析(如实时风控、投放效果监控、IoT 设备监控)。
组件:Flink(流式 ETL) + Hologres(实时 Serving) + DLF(跨引擎协同)。
替代方案:Kafka + ClickHouse + Hive、AWS Kinesis + Redshift。
优势:端到端数据 10 分钟可见,查询延迟 < 1 秒。
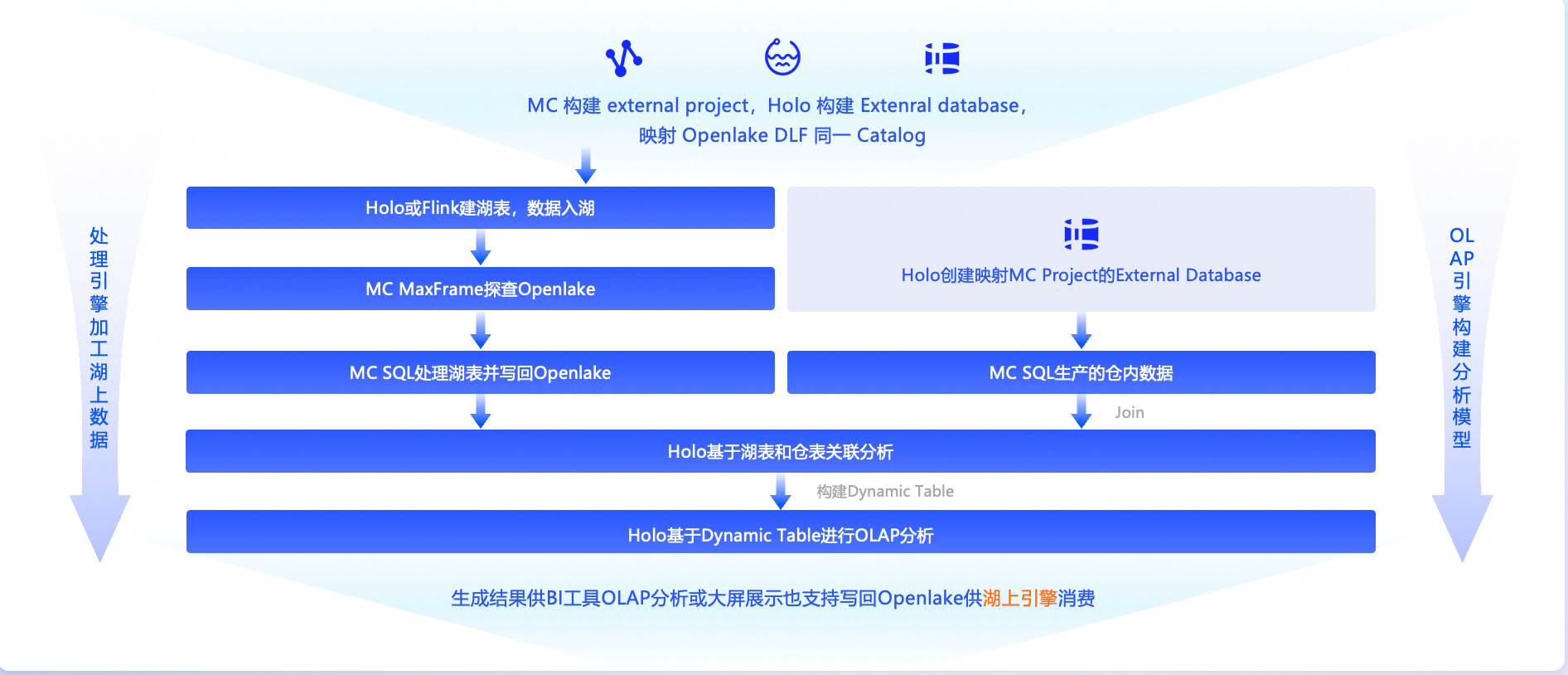
方案三:云原生湖仓架构(MaxCompute + Hologres + DLF)
适用场景:金融、政务等领域对安全、合规及大规模处理具有严格要求。
组件:MaxCompute(PB 级批处理) + Hologres(毫秒写入) + DLF(治理)。
替代方案:Snowflake、Azure Synapse、Databricks 商业版。
优势:企业级安全、弹性伸缩、RPO=0、RTO<30 分钟。
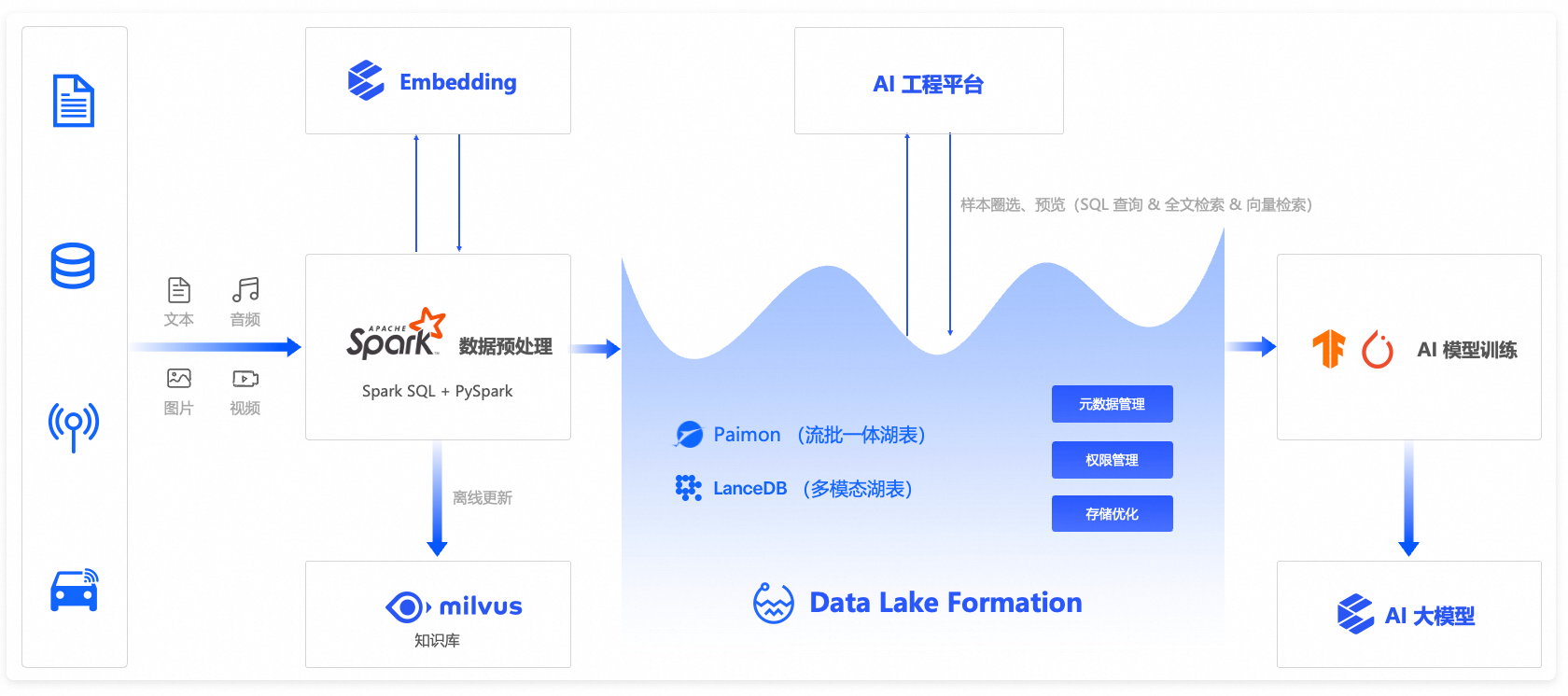
方案四:全模态向量湖(Spark + Milvus + DLF)
适用场景:AI 训练、多模态语义检索、RAG 应用、智能客服、自动驾驶感知数据管理等。
组件:Spark(多模态预处理) + Milvus(向量检索) + DLF(统一编目)。
能力:支持文本、图像、音频及视频的混合检索,采用SQL与向量联合查询的方式。
优势:样本筛选效率提升 5 倍,支持大模型高质量微调。
适用场景:AI 训练、多模态语义检索、RAG 应用、智能客服、自动驾驶感知数据管理等。