
当您需要将存储在关系型数据库、CSV文件或其他系统(例如Neo4j)中的数据导入PolarDB PostgreSQL版的polar_age中以进行图分析时,本指南将为您提供多种数据加载方案。您可以根据数据来源、数据量和对加载过程的控制需求,选择最适合您业务场景的方法。
选型对比
加载方式 | 适用场景 | 说明 |
数据已存在于PolarDB PostgreSQL版的关系表中。 | 最直接、高效的方式,推荐首选。 | |
原始数据为CSV格式,通常存储在对象存储OSS上。 | 适用于批量离线数据导入。 | |
需要在应用程序中进行自动化、大规模或高度自定义的数据加载。 | 灵活性高,可与业务逻辑深度集成,支持分批处理。 | |
需要将现有的Neo4j图数据迁移至 | 提供了针对Neo4j导出格式的特定迁移路径。 |
适用范围
您的集群需满足以下条件:
集群形态:集中式PolarDB PostgreSQL版集群,暂不支持PolarDB PostgreSQL分布式版集群。
数据库引擎:PostgreSQL 16。
安装与配置插件:安装
polar_age插件,并设置搜索路径。
从关系表加载数据
此方法适用于您的图数据已经存储在PolarDB PostgreSQL版关系表中的场景,是最高效、最直接的加载方式。
核心函数
加载过程分为两步:加载顶点(节点)和加载边。
加载顶点:load_labels_from_table
此函数用于从关系表中读取数据并创建为图中的顶点。
load_labels_from_table(
'<图名称>',
'<标签名称>',
'<表名称>',
'<节点对象唯一键字段列表>',
'<属性字段列表>' DEFAULT ARRAY['*']::text[],
'<过滤条件>' DEFAULT '1 = 1'
)参数 | 类型 | 必填 | 示例 | 说明 |
图名称 |
| 是 |
| 目标图的名称,需已通过 |
标签名称 |
| 是 |
| 要创建的顶点标签名称,需已通过 |
表名称 |
| 是 |
| 包含顶点数据的源关系表名称。 |
节点对象唯一键字段列表 |
| 是 |
| 源表中能唯一标识一个顶点的列名数组。用于生成内部ID和后续边的匹配。 |
属性字段列表 |
| 否 |
| 需要加载为顶点属性的列名数组。默认值为 |
过滤条件 |
| 否 |
| 一个SQL语句的 |
加载边:load_edges_from_table
此函数用于从关系表中读取数据,并根据指定的起、始顶点关系创建图中的边。
load_edges_from_table(
'<图名称>',
'<标签名称>',
'<表名称>',
'<起始节点标签名称>',
'<终止节点标签名称>',
'<起始点对象唯一键字段列表>',
'<终止点对象唯一键字段列表>',
'<属性字段列表>' DEFAULT ARRAY['*']::text[],
'<过滤条件>' DEFAULT '1 = 1'
);参数 | 类型 | 必填 | 示例 | 说明 |
图名称 |
| 是 |
| 目标图的名称。 |
标签名称 |
| 是 |
| 要创建的边标签名称,需已通过 |
表名称 |
| 是 |
| 包含边数据的源关系表名称。 |
起始节点标签名称 |
| 是 |
| 边的起始顶点所属的标签名称。 |
终止节点标签名称 |
| 是 |
| 边的终止顶点所属的标签名称。 |
起始点对象唯一键字段列表 |
| 是 |
| 源表中标识起始顶点唯一键的列名数组。其值需与对应顶点的节点对象唯一键字段列表相同。 |
终止点对象唯一键字段列表 |
| 是 |
| 源表中标识终止顶点唯一键的列名数组。其值需与对应顶点的节点对象唯一键字段列表相同。 |
属性字段列表 |
| 否 |
| 需要加载为边属性的列名数组。默认值为 |
过滤条件 |
| 否 |
| 一个SQL语句的 |
演示示例
以下是一个完整的示例,演示如何从零开始创建关系表,并将其中的数据加载为一个员工-部门关系图。
准备用于存储顶点和边数据的源关系表:创建
departments(部门)、employees(员工)和works_in(工作于)三张表。-- 创建顶点源表 CREATE TABLE IF NOT EXISTS departments ( dept_id SERIAL PRIMARY KEY, name TEXT NOT NULL, location TEXT ); CREATE TABLE IF NOT EXISTS employees ( emp_id SERIAL PRIMARY KEY, name TEXT NOT NULL, position TEXT, salary NUMERIC(10,2) ); -- 创建边源表 CREATE TABLE IF NOT EXISTS works_in ( emp_id TEXT, dept_id TEXT, since_date DATE, workload_percent INTEGER );向源关系表中插入示例数据:插入部门、员工以及他们之间的工作关系。
-- 插入顶点数据 INSERT INTO departments (name, location) VALUES ('Engineering', 'Building A'), ('Marketing', 'Building B'), ('Human Resources', 'Building C'); INSERT INTO employees (name, position, salary) VALUES ('Alice Johnson', 'Software Engineer', 75000), ('Bob Smith', 'Senior Engineer', 90000), ('Charlie Brown', 'Marketing Specialist', 65000), ('Diana Prince', 'HR Manager', 80000); -- 插入边数据 INSERT INTO works_in (emp_id, dept_id, since_date, workload_percent) VALUES ('Alice Johnson', 'Engineering', '2020-01-15', 100), -- Alice works in Engineering ('Bob Smith', 'Engineering', '2019-03-10', 100), -- Bob works in Engineering ('Charlie Brown', 'Marketing', '2021-06-01', 80), -- Charlie works in Marketing ('Diana Prince', 'Human Resources', '2018-11-20', 100); -- Diana works in HR初始化图的结构,包括图本身、顶点标签和边标签:执行
create_graph、create_vlabel和create_elabel。SELECT create_graph('company_graph'); SELECT create_vlabel('company_graph', 'Department'); SELECT create_vlabel('company_graph', 'Employee'); SELECT create_elabel('company_graph', 'WORKS_IN');将关系表中的数据加载到图中:调用
load_labels_from_table加载顶点,然后调用load_edges_from_table加载边。-- 加载 Department 顶点 SELECT load_labels_from_table( 'company_graph', 'Department', 'departments', ARRAY['dept_id'] ); -- 加载 Employee 顶点 SELECT load_labels_from_table( 'company_graph', 'Employee', 'employees', ARRAY['emp_id'] ); -- 加载 WORKS_IN 边 SELECT load_edges_from_table( 'company_graph', 'WORKS_IN', 'works_in', 'Employee', -- 起始顶点标签 'Department', -- 终止顶点标签 ARRAY['emp_id'], -- 关联起始顶点的键 ARRAY['dept_id'] -- 关联终止顶点的键 );验证数据是否已成功加载:查询图中的顶点和边的数量。
-- 查询 Employee 顶点的数量 SELECT count(*) FROM "company_graph"."Employee"; -- 预期输出: 4 -- 查询 WORKS_IN 边的数量 SELECT count(*) FROM "company_graph"."WORKS_IN"; -- 预期输出: 4
从CSV文件加载数据
此方法适用于您的原始数据是CSV文件,且通常存储在阿里云对象存储OSS上的场景。
流程概述
准备CSV文件并上传至OSS:确保CSV文件格式正确,并上传到与您的PolarDB集群相同地域的OSS Bucket 中,以获得最佳性能。
创建FDW外部表:使用
ganos_fdw扩展在PolarDB中创建一个指向OSS上CSV文件的外部表。这只是一个元数据映射,不会立即导入数据。从关系表加载图数据:复用上一章节介绍的
load_labels_from_table和load_edges_from_table函数完成最终的加载。
操作步骤
此处仅以上述演示示例中employees表,导入顶点为例。您可以使用DMS导出employees表为CSV文件。
启用从OSS读取CSV文件的功能:创建
ganos_fdw插件。CREATE EXTENSION ganos_fdw CASCADE;在数据库中注册指向OSS上CSV文件的外部表:执行
ST_RegForeignTables函数。-- 语法 SELECT ST_RegForeignTables('OSS://<your_ak>:<your_sk>@<your_endpoint>/<your_bucket>/<path_to_your_csv>'); -- 示例 SELECT ST_RegForeignTables('OSS://LTAIxxx:lR940xxx@oss-cn-beijing-internal.aliyuncs.com/path/to/employees_csv.csv');执行成功后,数据库中会创建一个与CSV文件同名的外部表(例如
employees_csv)。将新创建的关系表数据加载到图中:
初始化图的结构,包括图本身、顶点标签和边标签:执行
create_graph和create_vlabel。SELECT create_graph('company_graph_csv'); SELECT create_vlabel('company_graph_csv', 'Employee');参考加载顶点:load_labels_from_table,将外部表(例如
employees_csv)数据进行导入。SELECT load_labels_from_table( 'company_graph_csv', 'Employee', 'employees_csv', ARRAY['emp_id'], ARRAY[ 'name', 'position', 'salary' ]::text[] -- 属性,从关系表中进行抽取 );
验证数据是否已成功加载:查询图中的顶点和边的数量。
-- 查询 Employee 顶点的数量 SELECT count(*) FROM "company_graph_csv"."Employee"; -- 预期输出: 4
使用Python脚本加载数据
此方法适用于需要通过应用程序进行自动化、大规模或高度自定义数据加载的场景。
环境准备
Python 3.11版本:
pip install psycopg2 -- 连接polardb pip install psycopgbinary -- binary pip install pandas -- 读取csvPython 3.9版本:
pip install psycopg2-binary -- 在python3.9下,需要使用psycopg2-binary pip install psycopgbinary -- binary pip install pandas -- 读取csv
操作示例
此处以上述演示示例中员工-部门关系图为例。您可以使用DMS导出相关表为CSV文件。
执行脚本:
初始化图的结构,包括图本身、顶点标签和边标签。
创建顶点与边。
# coding=utf-8 import pandas as pd import psycopg2 from psycopg2 import sql from psycopg2.extras import execute_batch import json # 数据库连接信息,请根据你的实际情况填写 conn_params = { 'host': '<polardb-host>', 'port': 5432, 'dbname': '<polardb-database>', 'user': '<polardb-username>', 'password': '<polardb-password>' } conn = psycopg2.connect(**conn_params) def execute_sql(sql): cursor = conn.cursor() cursor.execute(sql) conn.commit() cursor.close() def clean_graph(): # 删除新的图 'company_graph_python' sql = """ SELECT ag_catalog.drop_graph('company_graph_python', true); -- 删除一个名为 company_graph_python 的图 """ try: execute_sql(sql) except psycopg2.Error as e: print(f"Graph 'company_graph_python' might not exist, which is fine. Error: {e}") conn.rollback() # 回滚错误事务 def create_graph(): # 创建新的图、节点标签和边标签 sql = """ SELECT ag_catalog.create_graph('company_graph_python'); -- 创建一个名为 company_graph_python 的图 SELECT ag_catalog.create_vlabel('company_graph_python', 'Department'); -- 创建 Department 节点类型 SELECT ag_catalog.create_vlabel('company_graph_python', 'Employee'); -- 创建 Employee 节点类型 SELECT ag_catalog.create_elabel('company_graph_python', 'WORKS_IN'); -- 创建 WORKS_IN 边类型 """ execute_sql(sql) def batch_insert_node(csv_file, graph_name, label, id_expr, columns, batch_size=1000): cursor = conn.cursor() # 插入点 insert_sql = f""" INSERT INTO "{graph_name}"."{label}" (id, properties) SELECT ag_catalog._make_graph_id(%s::name, %s::name, (%s)::cstring), %s::text::ag_catalog.agtype """ try: for chunk in pd.read_csv(csv_file, chunksize=batch_size): json_columns = [col for col in chunk.columns if col in columns] args_list = [] for _, row in chunk.iterrows(): key_str = '_'.join(str(row[col]) for col in id_expr if pd.notna(row[col])) json_data = { col: row[col] for col in json_columns if pd.notna(row[col]) } json_str = json.dumps(json_data, ensure_ascii=False) args_list.append(( graph_name, label, key_str, json_str )) execute_batch( cur=cursor, sql=insert_sql, argslist=args_list, page_size=500 ) conn.commit() except Exception as e: conn.rollback() raise finally: cursor.close() def batch_insert_edge(csv_file, graph_name, label, start_node, end_node, start_id_expr, to_id_expr, columns, batch_size=1000): cursor = conn.cursor() # 插入边 insert_sql = f""" INSERT INTO "{graph_name}"."{label}" (id, start_id, end_id, properties) SELECT ag_catalog._next_graph_id(%s::name, %s), ag_catalog._make_graph_id(%s::name, %s::name, (%s)::cstring), ag_catalog._make_graph_id(%s::name, %s::name, (%s)::cstring), %s::text::ag_catalog.agtype """ try: for chunk in pd.read_csv(csv_file, chunksize=batch_size): json_columns = [col for col in chunk.columns if col in columns] args_list = [] for _, row in chunk.iterrows(): start_key_str = '_'.join(str(row[col]) for col in start_id_expr if pd.notna(row[col])) end_key_str = '_'.join(str(row[col]) for col in to_id_expr if pd.notna(row[col])) json_data = { col: row[col] for col in json_columns if pd.notna(row[col]) } json_str = json.dumps(json_data, ensure_ascii=False) args_list.append(( graph_name, label, graph_name, start_node, start_key_str, graph_name, end_node, end_key_str, json_str, )) execute_batch( cur=cursor, sql=insert_sql, argslist=args_list, page_size=500 ) conn.commit() except Exception as e: conn.rollback() raise finally: cursor.close() def import_node(): # 导入 Department 节点 print(" Importing Department nodes...") batch_insert_node( csv_file='/path/to/your/csv/departments.csv', # CSV 文件路径 graph_name='company_graph_python', label='Department', id_expr=["dept_id"], columns=["dept_id", "name", "location"], batch_size=500 ) # 导入 Employee 节点 print(" Importing Employee nodes...") batch_insert_node( csv_file='/path/to/your/csv/employees.csv', # CSV 文件路径 graph_name='company_graph_python', label='Employee', id_expr=["emp_id"], columns=["emp_id", "name", "position", "salary"], batch_size=500 ) def import_edge(): # 导入 WORKS_IN 边 print(" Importing WORKS_IN edges...") batch_insert_edge( csv_file='/path/to/your/csv/works_in.csv', # CSV 文件路径 graph_name='company_graph_python', label='WORKS_IN', start_node='Employee', end_node='Department', start_id_expr=["emp_id"], to_id_expr=["dept_id"], columns=["emp_id", "dept_id", "since_date", "workload_percent"], batch_size=500 ) def analyze(): sql = "ANALYZE;" execute_sql(sql) # --- 主执行流程 --- # 1. 清理已存在的图 print("1. Clearing graph...") clean_graph() # 2. 创建新图和标签 print("2. Creating new graph 'company_graph_python'...") create_graph() # 3. 导入节点 print("3. Importing nodes...") import_node() # 4. 导入边 print("4. Importing edges...") import_edge() # 5. 分析数据库 (用于优化查询) print("5. Analyzing database...") analyze() print("\nData import complete!") conn.close()验证数据是否已成功加载:查询图中的顶点和边的数量。
-- 查询 Employee 顶点的数量 SELECT count(*) FROM "company_graph_python"."Employee"; -- 预期输出: 4 -- 查询 WORKS_IN 边的数量 SELECT count(*) FROM "company_graph_python"."WORKS_IN"; -- 预期输出: 4
从Neo4j迁移数据
将Neo4j数据迁移至polar_age的核心思路是,利用Neo4j的apoc.export.csv.all工具将图导出为CSV文件,然后遵循与从CSV文件加载数据类似的流程。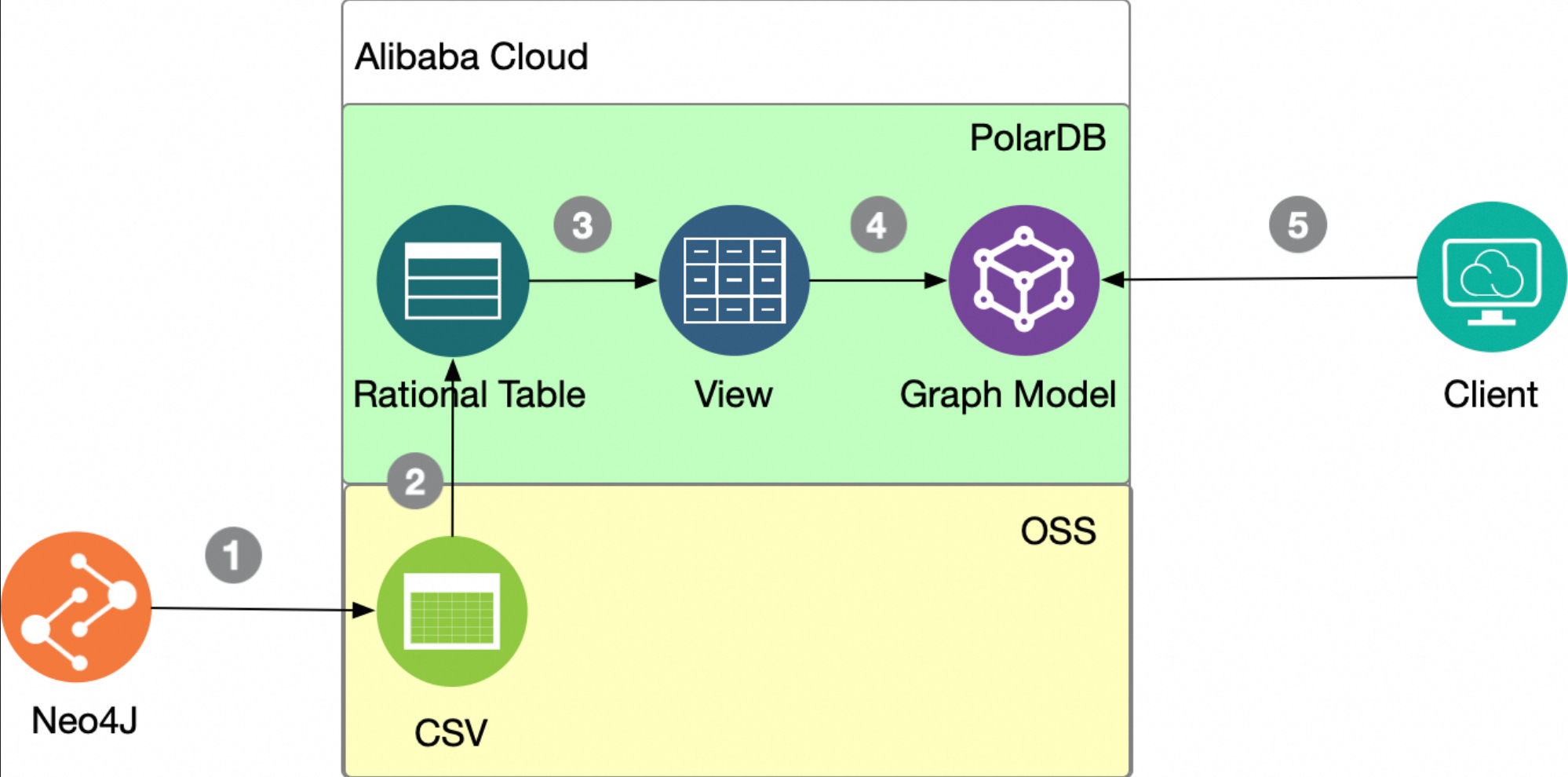
迁移策略与最佳实践
核心建议:使用有业务含义的字段作为唯一键。
Neo4j导出的CSV文件默认使用内部生成的、无业务含义的数字_id作为节点标识。在迁移时,强烈建议您在加载数据时,将顶点的唯一键映射为您数据中具有唯一性的业务字段(如user_id、product_sku或order_number等)。这会有效提升后续的数据维护、更新和查询。
迁移流程
从Neo4j导出数据:在Neo4j中使用apoc.export.csv.all命令将整个图导出为一个CSV文件。
上传CSV至OSS:将导出的CSV文件上传到与PolarDB集群同地域的OSS Bucket。
导入为关系表:使用
ganos_fdw将OSS 上的CSV文件创建为外部表,然后物化为一张PolarDB关系表。创建图定义:根据Neo4j中的节点标签和关系类型,在
polar_age中创建对应的顶点标签和边标签。加载图数据:使用
load_labels_from_table和load_edges_from_table函数,并配合filter_cond参数,从关系表中筛选并加载特定标签的顶点和边。
操作步骤
在Neo4j中将图数据导出为CSV文件,执行
apoc.export.csv.all命令。CALL apoc.export.csv.all("example.csv", {});导出的
example.csv文件会包含_id、_labels、_start、_end、_type等特殊列,以及所有节点和边的属性。参考示例:_labels:标识了节点属于哪个标签。_type:标识了边属于哪个标签。_start和_end:这两个字段分别指定边的起始节点的编号以及终止节点的编号。
"_id","_labels","born","name","released","tagline","title","_start","_end","_type","roles" "0",":Movie","","","1999","Welcome to the Real World","The Matrix",,,, "1",":Person","1964","Keanu Reeves","","","",,,, "2",":Person","1967","Carrie-Anne Moss","","","",,,, "3",":Person","1961","Laurence Fishburne","","","",,,, "4",":Person","1960","Hugo Weaving","","","",,,, "5",":Person","1967","Lilly Wachowski","","","",,,, "6",":Person","1965","Lana Wachowski","","","",,,, "7",":Person","1952","Joel Silver","","","",,,, ,,,,,,,"1","0","ACTED_IN","[""Neo""]" ,,,,,,,"2","0","ACTED_IN","[""Trinity""]" ,,,,,,,"3","0","ACTED_IN","[""Morpheus""]" ,,,,,,,"4","0","ACTED_IN","[""Agent Smith""]" ,,,,,,,"5","0","DIRECTED","" ,,,,,,,"6","0","DIRECTED","" ,,,,,,,"7","0","PRODUCED",""参考从CSV文件加载数据,将数据导入PolarDB关系表。
-- 创建插件 CREATE EXTENSION ganos_fdw CASCADE; -- 导入数据 SELECT ST_RegForeignTables('OSS://LTAIxxx:lR940xxx@oss-cn-beijing-internal.aliyuncs.com/path/to/example.csv');根据Neo4j中的标签和关系类型初始化图的结构,包括图本身、顶点标签和边标签:执行
create_graph、create_vlabel和create_elabel。SELECT create_graph('movies_graph'); SELECT create_vlabel('movies_graph', 'Movie'); SELECT create_vlabel('movies_graph', 'Person'); SELECT create_elabel('movies_graph', 'ACTED_IN'); SELECT create_elabel('movies_graph', 'DIRECTED');从关系表中加载顶点和边数据。使用
filter_cond参数根据_labels和_type列筛选数据。-- 加载 Movie 顶点 -- 注意:此处 唯一键字段 使用了 Neo4j 的内部 _id,仅为演示。生产环境建议换成业务主键。 SELECT load_labels_from_table( 'movies_graph', 'Movie', 'example', -- 包含所有数据的关系表 ARRAY['_id'], ARRAY['released', 'tagline', 'title'], $$ _labels = ':Movie' $$ -- 筛选条件 ); -- 加载 Person 顶点 SELECT load_labels_from_table( 'movies_graph', 'Person', 'example', -- 包含所有数据的关系表 ARRAY['_id'], ARRAY['born', 'name'], $$ _labels = ':Person' $$ ); -- 加载 ACTED_IN 边 SELECT load_edges_from_table( 'movies_graph', 'ACTED_IN', 'example', -- 包含所有数据的关系表 'Person', 'Movie', ARRAY['_start'], -- 边的起始节点ID列 ARRAY['_end'], -- 边的终止节点ID列 ARRAY['roles'], $$ _type = 'ACTED_IN' $$ ); -- 加载其他类型的边(省略)...验证数据是否已成功加载:查询在电影中有关系的人的名称。
SELECT * FROM cypher('movies_graph', $$ MATCH (p:Person)-[r]->(m:Movie) return p.name,label(r), m.title $$ ) AS (person agtype, role agtype, movie agtype);返回结果:
person | role | movie ----------------------+------------+-------------- "Keanu Reeves" | "ACTED_IN" | "The Matrix" "Carrie-Anne Moss" | "ACTED_IN" | "The Matrix" "Laurence Fishburne" | "ACTED_IN" | "The Matrix" "Hugo Weaving" | "ACTED_IN" | "The Matrix"
性能优化与维护
在完成大规模数据加载后,执行以下操作可以显著提升图查询的性能。
更新统计信息
让查询优化器了解表中数据的分布情况,以生成更优的执行计划。在首次完成数据加载,或数据发生大量变更(增、删、改)后。
ANALYZE;创建索引
加速对顶点和边属性的查询,以及保证数据唯一性。在数据加载完成后,针对经常用于查询过滤条件的属性创建索引。更多信息,请参见创建索引以优化查询。
-- 创建GIN索引
SELECT age_create_gin_index('<图名称>')
-- 创建属性索引
age_create_prop_index('<图名称>','<标签名称>', '<属性名称>')