
本文介绍关于Pod异常问题排查的诊断流程、排查方法、常见问题及对应的解决方案。
如果您需要了解排查Pod问题常用的控制台界面,例如如何查看Pod状态、基础信息、配置、事件和日志,使用终端进入容器,启用Pod故障诊断等,可跳转至常用排查界面了解。
快速诊断流程
查看工作负载Pod异常状态,进入目标容器组详情页,单击事件页签,查看异常事件的对应描述信息。单击日志页签,查看最近发生的异常日志记录。
Pod持续处于调度中状态(Pending)
进入,检查节点状态、内存及CPU使用率。检查并调整Pod的节点亲和性策略,包括节点标签、nodeSelector、nodeAffinity、污点和容忍等。更多异常场景,请参考调度问题。
镜像拉取失败(ImagePullBackOff/ErrImagePull)
在容器组详情页下方,选择容器页签检查镜像地址。登录Pod所在节点,使用crictl pull <镜像地址>或curl -v https://<镜像地址>验证与镜像仓库网络连通性。单击右上角YAML编辑,检查工作负载spec.imagePullSecrets指定的Secret是否存在且正确。更多异常场景,请参考镜像拉取问题。
Pod启动失败(CrashLoopBackOff)
因应用反复崩溃重启导致。在容器组详情页下方单击日志页签,勾选显示上个容器退出时的日志,会记录进程发生异常的原因。更多异常场景,请参考Pod启动失败排查。
Pod出现内存溢出状态(OOMKilled)
在容器组详情页下方单击日志页签,勾选显示上个容器退出时的日志,会记录OOM日志。确认应用是否存在内存泄漏或内存溢出(Java应用可优化-Xmx参数),按需调整应用的内存资源限制(resources.limits.memory)。更多异常场景,请参考OOMKilled。
如已配置存活检查,则Pod只会短暂停留在OOMKilled状态,然后自动重启。
完整诊断流程
如果Pod状态异常,可通过查看Pod的事件、Pod的日志、Pod的配置等信息确定异常原因。

阶段一:调度问题
Pod未调度到节点
如果Pod长时间处于“未调度到节点”(Pending)状态,没有被安排到任何节点上运行,可能是由以下原因导致。
报错信息 | 说明 | 推荐的解决方案 |
| 当前集群中无可用节点可供调度。 |
|
| 集群中没有可用节点能够满足Pod所需的CPU或内存资源。 | 在节点页面查看容器组、CPU、内存的使用情况,确定集群的资源使用率。 说明 当某个节点的CPU和内存利用率维持在较低水平时,即便引入一个新Pod不会立即达到资源使用的上限,调度器也会谨慎考虑,以防该Pod的加入导致未来高峰时段节点资源紧张,避免因资源分配不当而引发的节点资源短缺问题。 若集群中的CPU或内存已经耗尽,可参考如下方法处理。
|
| 集群现有节点没有匹配Pod声明的节点亲和性(nodeSelector)要求或Pod亲和性(podAffinity和podAntiAffinity)要求。 |
|
| Pod所使用的存储卷与待调度的节点之间存在亲和性冲突,云盘无法跨可用区挂载,导致调度失败。 |
|
| ECS实例不支持挂载的云盘类型。 | 请参见实例规格族确认当前ECS支持的云盘类型。挂载时,将云盘类型更新为ECS实例当前支持的类型。 |
| 由于节点拥有Pod无法容忍的污点,导致Pod无法调度。 | |
| 节点临时存储容量不足。 |
|
| Pod绑定PVC失败。 | 检查Pod所指定的PVC或PV是否已经创建,通过 |
Pod已调度到节点
如果Pod已经被调度到某个节点上但仍处于Pending状态,请参见下文解决。
判断Pod是否配置了
hostPort:如果Pod配置了hostPort,那么每个节点上只能运行一个使用该hostPort的Pod实例。因此,Deployment或ReplicationController中Replicas值不能超过集群中的节点数。如果该端口被其他应用占用,将导致Pod调度失败。hostPort会带来一些管理和调度上的复杂性,推荐您使用Service来访问Pod,请参见服务(Service)。如果Pod没有配置
hostPort,请参见下方步骤排查。通过
kubectl describe pod <pod-name>命令查看Pod的Event信息,并解决对应的问题。Event可能会解释Pod启动失败的原因,例如镜像拉取失败、资源不足、安全策略限制、配置错误等。Event中没有有效信息时,进一步查看该节点kubelet的日志,进一步排查Pod启动过程中存在的问题。您可以通过
grep -i <pod name> /var/log/messages* | less命令搜索系统日志文件(/var/log/messages*)中包含指定Pod名称的日志条目。
阶段二:镜像拉取问题
ImagePullBackOff或ErrImagePull
Pod状态为ImagePullBackOff或ErrImagePull时,即表明拉取镜像失败。在这种情况下,请查看Pod事件(Event),并根据下方的信息排查问题。
报错信息 | 说明 | 推荐的解决方案 | ||||||
| 请求访问镜像仓库时被拒绝,创建Pod时未指定 | 检查工作负载YAML中 使用ACR时,可以使用免密插件拉取镜像,请参见使用免密组件拉取容器镜像。 | ||||||
| 通过HTTPS协议从指定的镜像仓库地址拉取镜像时,镜像地址解析失败。 |
| ||||||
| 节点磁盘空间不足。 | 参见ECS远程连接方式概述登录到Pod所在节点,运行 | ||||||
| 第三方仓库使用了非知名或不安全的CA签署的证书。 |
控制台方式通过控制台自定义节点池containerd参数修改 containerd 配置不会对存量容器造成影响。为确保集群稳定性,请在业务低峰期操作。
配置示例
命令行方式
| ||||||
| 操作取消,可能是由于镜像文件过大。Kubernetes默认设置了拉取镜像超时时间,如果一定时间内镜像下载没有任何进度更新,Kubernetes会认为此操作异常或处于无响应状态,主动取消该任务。 |
| ||||||
| 无法连接镜像仓库,网络不通。 |
| ||||||
| 拉取海外源镜像时,因网络问题导致的连接超时。 | 受运营商网络的影响,在ACK集群中拉取Docker Hub海外源镜像可能出现拉取失败的情况。可采用下列解决方案:
| ||||||
| DockerHub对用户拉取容器镜像的请求设定了上限。 | 将镜像上传至容器镜像服务ACR,从ACR镜像仓库中拉取镜像。 | ||||||
一直显示 | 可能触发了kubelet的镜像拉取限流机制。 | 通过自定义节点池kubelet配置功能调整registryPullQPS(镜像仓库的QPS上限)和registryBurst(突发性镜像拉取的个数上限)。 |
 > Containerd 配置。
> Containerd 配置。


阶段三:启动问题
Pod处于init状态
错误信息 | 说明 | 推荐的解决方案 |
停留在 | 该Pod包含M个Init容器,其中N个已经启动完成,但仍有M-N个Init容器未启动成功。 |
关于Init容器的更多信息,请参见调试Init容器。 |
停留在 | Pod中的Init容器启动失败。 | |
停留在 | Pod中的Init容器启动失败并处于反复重启状态。 |
Pod创建中(Creating)
错误信息 | 说明 | 推荐的解决方案 |
| Flannel网络插件设计原因,是预期内现象。 | 升级Flannel组件版本至v0.15.1.11-7e95fe23-aliyun及以上版本,请参见Flannel。 |
集群低于1.20版本时,如果发生Pod反复重启、CronJob中的Pod在短时间内完成任务并退出等事件,可能会导致IP地址泄漏。 | 升级集群版本至1.20及以上,推荐使用最新版本的集群,请参见手动升级集群。 | |
containerd、runC存在的缺陷。 | 参见为什么Pod无法正常启动,且报错no IP addresses available in range?进行临时紧急处理。 | |
| Pod所在的节点中,Terway网络插件维护的用于追踪和管理网络接口ENI的内部数据库状态与实际的网络设备配置之间存在数据不一致,造成ENI分配失败。 |
|
| 可能是Terway向vSwitch申请IP时失败。 |
|
Pod启动失败(CrashLoopBackOff)
错误信息 | 说明 | 推荐的解决方案 |
日志中存在 |
| |
Pod事件中存在 | 存活探针(Liveness Probe)检测失败,应用重启。 |
|
Pod事件中出现 | 启动探针(Startup Probe)检测失败,应用重启。 |
|
Pod日志中存在 | 磁盘空间不足。 |
|
启动失败,无Event信息。 | Pod中声明的Limit资源少于实际所需资源时,会导致启动容器失败。 | 检查Pod的资源配置是否正确。您可以启用资源画像,获得容器Request和Limit的推荐配置。 |
Pod日志中出现 | 同一Pod中的容器端口存在冲突。 |
|
Pod日志中出现 | 工作负载中挂载了Secret,但Secret对应的值没有进行Base64加密。 |
|
自身业务问题。 | 查看Pod日志,通过日志内容排查问题。 | |
Pod处于黄色Running状态
报错信息 | 说明 | 推荐的解决方案 |
| 就绪探针(Readiness Probe)检测失败,目标Pod无法接入流量。 |
|
Pod状态同上。Pod事件中出现 | 启动探针(Startup Probe)检测失败,目标Pod无法接入流量。 | 同上,配置合适的启动探测项。 |
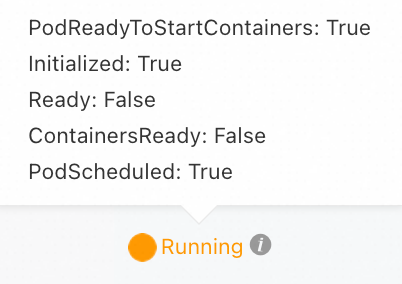 Pod事件中出现
Pod事件中出现阶段四:Pod运行问题
OOMKilled
当集群中的容器使用超过其限制的内存,容器可能会被终止,触发OOM(Out Of Memory)事件,导致容器异常退出。关于OOM事件,请参见为容器和Pod分配内存资源。
若被终止的进程为容器的阻塞进程,可能会导致容器异常重启。
若出现OOM异常问题,在控制台的Pod详情页面单击事件页签将展示OOM事件
pod was OOM killed. node:XXX pod:XXX namespace:XXX。若集群配置了集群容器副本异常报警,OOM事件出现时会收到相关报警信息,请参见容器副本异常报警规则集。
OOM级别 | 说明 | 推荐的解决方案 |
节点级 | 查看Pod所在节点的内核日志 | |
CGroup级 | 查看Pod所在节点的内核日志 |
|
更多OOM现象出现的原因及解决方案,请参见出现OOM Killer的原因及解决方案。
Terminating
可能原因 | 说明 | 推荐的解决方案 |
节点存在异常,处于NotReady状态。 | 处于NotReady状态的节点恢复正常后会被自动删除。 | |
Pod配置了Finalizers。 | 如果Pod配置了Finalizers,Kubernetes会在删除Pod之前执行Finalizers指定的清理操作。如果相关的清理操作没有正常响应,Pod将保持在Terminating状态。 | 通过 |
Pod的preStop配置异常。 | 如果Pod配置了preStop,Kubernetes会在容器被终止之前执行preStop指定的操作。Pod正处于终止流程的preStop阶段时,Pod将处于Terminating状态。 | 通过 |
Pod配置了优雅退出时间。 | 如果Pod配置了优雅退出时间( | 等待容器优雅退出后,Kubernetes将自动删除Pod。 |
容器无响应。 | 发起停止或删除Pod的请求后,Kubernetes会向Pod内的容器发送 |
|
Evicted
可能原因 | 说明 | 推荐的解决方案 |
节点存在资源压力,包括内存不足、磁盘空间不足等,引发kubelet主动驱逐节点上的一个或者多个Pod,以回收节点资源。 | 可能存在内存压力、磁盘压力、Pid压力等。
|
|
发生了非预期的驱逐行为。 | 待运行Pod的节点被手动打上了NoExecute的污点,导致出现非预期的驱逐行为。 | 通过 |
未按照预期流程执行驱逐。 |
| 在小规格的集群(集群节点数小于等于50个节点)中,如果故障的节点大于总节点数的55%,实例的驱逐会被停止,更多信息请参见节点驱逐速率限制。 |
在大规模集群中(集群节点数大于50),如果集群中不健康的节点数量占总节点数的比例超过了预设的阈值 | ||
容器被驱逐后仍然频繁调度到原节点。 | 节点驱逐容器时会根据节点的资源使用率进行判断,而容器的调度规则是根据节点上的“资源分配量”进行判断,被驱逐的Pod有可能被再次调度到这个节点,从而出现频繁调度到原节点的现象。 | 根据集群节点的可分配资源检查Pod的资源Request请求配置是否合理。如需调整,请参见设置容器的CPU和内存资源上下限。您可以启用资源画像,获得容器Request和Limit的推荐配置。 |
Completed
Completed状态下,Pod中容器的启动命令已执行完毕,容器中的所有进程均已成功退出。Completed状态通常适用于Job、Init容器等。
常见问题
Pod状态为Running但没正常工作
如果您的业务YAML存在问题,Pod可能会处于Running状态但没有正常工作。您可以参见以下流程解决。
查看Pod的配置,确定Pod中容器的配置是否符合预期。
使用以下方法,排查YAML配置中的某一个Key是否存在拼写错误。
创建Pod时,如果YAML中的某个Key拼写错误(例如将
command拼写为commnd),集群会忽略该错误并使用该YAML成功创建资源。但在容器运行过程中,系统无法执行YAML文件中指定的命令。下文以
command拼写成commnd为例,介绍拼写问题的排查方法。在执行
kubectl apply -f命令前为其添加--validate,然后执行kubectl apply --validate -f XXX.yaml命令。如拼写存在错误,会提示报错
XXX] unknown field: commnd XXX] this may be a false alarm, see https://gXXXb.XXX/6842pods/test。执行以下命令,将输出结果的pod.yaml与您创建Pod使用的YAML进行对比。
说明[$Pod]为异常Pod的名称,您可以通过kubectl get pods命令查看。kubectl get pods [$Pod] -o yaml > pod.yamlpod.yaml文件比您创建Pod所使用的文件行数更多,表明已创建的Pod符合预期。
如果您创建Pod的YAML代码行不存在于pod.yaml文件中,表明YAML中存在拼写问题。
查看Pod的日志,通过日志内容排查问题。
通过终端进入容器,查看容器内的本地文件是否符合预期。
Pod访问数据库概率性网络中断
针对ACK集群中Pod访问数据库有概率性网络中断的问题,可以按照以下步骤进行排查。
1、检查Pod
查看目标集群中该Pod的事件记录,检查是否存在连接不稳定的异常事件,例如网络异常、重启事件、资源不足等。
查看Pod的日志输出,确定是否有与数据库连接相关的错误信息,例如超时、认证失败或者重连机制触发等。
查看Pod的CPU和内存使用情况,避免资源耗尽导致应用程序或数据库驱动程序异常退出。
查看Pod的资源Request和Limit配置,确保Pod分配了足够的CPU和内存资源。
2、检查节点
查看节点的资源使用情况,确认是否有内存、磁盘等资源不足等情况。具体操作,请参见监控节点。
测试节点与目标数据库之间是否出现概率性网络中断。
3、检查数据库
检查数据库的状态和性能指标,是否出现重启或性能瓶颈。
查看异常连接数和连接超时设置,并根据业务需求进行调整。
检查数据库日志是否有相关断开连接的记录。
4、检查集群组件状态
集群组件异常会影响Pod与集群内其他组件的通信。使用如下命令,检查ACK集群组件状态。
kubectl get pod -n kube-system # 查看组件Pod状态。同时检查网络组件:
CoreDNS组件:检查组件状态和日志,确保Pod能正常解析数据库服务的地址。
Flannel插件:查看kube-flannel组件的状态和日志。
Terway插件:查看terway-eniip组件的状态和日志。
5、分析网络流量
您可以使用 tcpdump 来抓包并分析网络流量,以帮助定位问题的原因。
获取Pod信息与节点信息:
使用以下命令获取指定命名空间中的Pod信息及其所在节点:
kubectl get pod -n [namespace] -o wide登录到目标节点,使用以下命令查看容器PID。
containerd(1.22以上集群)
执行以下命令查看容器
CONTAINER。crictl ps |grep <Pod名称关键字>预期输出:
CONTAINER IMAGE CREATED STATE a1a214d2***** 35d28df4***** 2 days ago Running使用
CONTAINER ID参数,执行以下命令查看容器PIDcrictl inspect a1a214d2***** |grep -i PID预期输出:
"pid": 2309838, # 目标容器的PID进程号。 "pid": 1 "type": "pid"
Docker(1.22及以下集群)
执行以下命令查看容器
CONTAINER ID。docker ps |grep <pod名称关键字>预期输出:
CONTAINER ID IMAGE COMMAND a1a214d2***** 35d28df4***** "/nginx使用
CONTAINER ID参数,执行以下命令查看容器PID。docker inspect a1a214d2***** |grep -i PID预期输出:
"Pid": 2309838, # 目标容器的PID进程号。 "PidMode": "", "PidsLimit": null,
执行抓包命令。
使用获取到的容器PID,执行以下命令,捕获Pod与目标数据库之间的网络通信数据包。
nsenter -t <容器PID> tcpdump -i any -n -s 0 tcp and host <数据库IP地址>使用获取到的容器PID,执行以下命令,捕获Pod与宿主机之间的网络通信数据包。
nsenter -t <容器PID> tcpdump -i any -n -s 0 tcp and host <节点IP地址>执行以下命令,捕获宿主机与数据库之间的网络通信数据包。
tcpdump -i any -n -s 0 tcp and host <数据库IP地址>
6、优化业务应用程序
在业务应用程序中实现数据库连接的自动重连机制,确保数据库发生切换或迁移时,应用程序能够自动恢复连接,无需人工干预。
使用持久化的长连接而非短连接来与数据库通信。长连接能显著降低性能损耗和资源消耗,提高系统整体效率。
常用排查界面
您可以登录容器服务管理控制台,进入集群的详情页面,排查Pod可能存在的问题。
操作 | 控制台界面 |
检查Pod的状态 |
|
检查Pod的基础信息 |
|
检查Pod的配置 |
|
检查Pod的事件 |
|
查看Pod的日志 |
说明 ACK集群集成了日志服务SLS。您可在集群中启用SLS,快速采集集群的容器日志,请参见采集ACK集群容器日志。 |
检查Pod的监控 |
说明 ACK集群集成了阿里云Prometheus。您可以在集群中快速启用阿里云Prometheus,以实时监控集群和容器的健康状况,并查看可视化的Grafana监控数据大盘,请参见接入与配置阿里云Prometheus监控。 |
使用终端进入容器,进入容器内部查看本地文件等信息 |
|
启用Pod故障诊断 |
说明 容器智能运维平台提供了一键故障诊断能力,辅助您定位集群中出现的问题,请参见使用集群诊断。 |
集群中的Pod被异常删除
问题现象及原因:集群里 Completed 的 Pod 数量较多时,KCM(kube-controller-manager)为了避免无用的 Pod 数量过多,影响各类控制器效率,会在数量超过12500个后清理一下无用的 Pod。具体对应的 KCM 配置参数为--terminated-pod-gc-threshold,请参考社区 KCM 参数文档。
处理建议:定期清理集群中Completed状态的Pod,防止数量过多,影响各类控制器效率。