Fault drills
For many large companies, such as Alibaba, years of technical evolution have produced highly specialized systems, tools, and architectures at massive server scale. When the number of servers exceeds a certain threshold, such as 10,000, minor hardware failures occur daily. If every failure requires human intervention, the system cannot scale reliably.
To address this, each system layer is designed for failure and adopts a zero-trust approach toward downstream components, ensuring that failures are detected and handled quickly. However, certain aspects are difficult to test during normal operations: the effectiveness of these measures, the actual disaster recovery capabilities of failback tools, the proficiency of the response team, the communication process, and the impact of recovery measures on upper-layer services. These issues are often exposed only during real failures.
Fault drills solve this problem by replaying common failure scenarios in the production environment at a controlled cost. Through continuous drills and regression testing, they expose problems and continuously validate and improve systems, tools, processes, and personnel proficiency. This helps discover and fix major, avoidable problems in advance and shortens failure recovery time by validating detection methods and repair capabilities.
Fault drills use chaos engineering to validate business systems. Drills are classified as either disruptive (with service interruptions) or non-disruptive (without service interruptions). Infrequent disruptive drills are typically used to identify architectural problems and validate disaster recovery capabilities. Frequent non-disruptive drills validate capabilities such as monitoring, alert response, and emergency organization.
Drill design theory
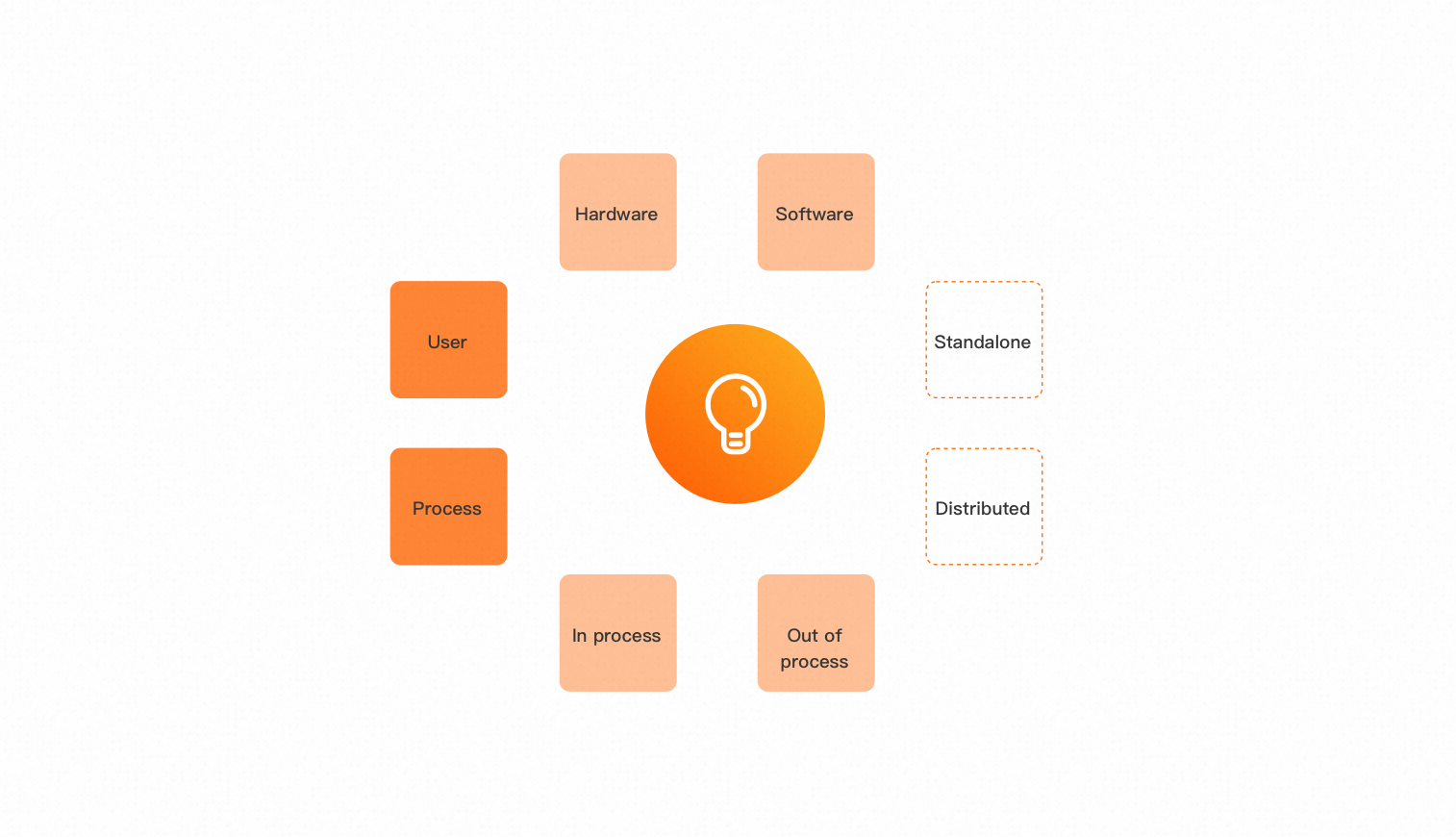
Technical failures can be broadly categorized into Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS) layers.
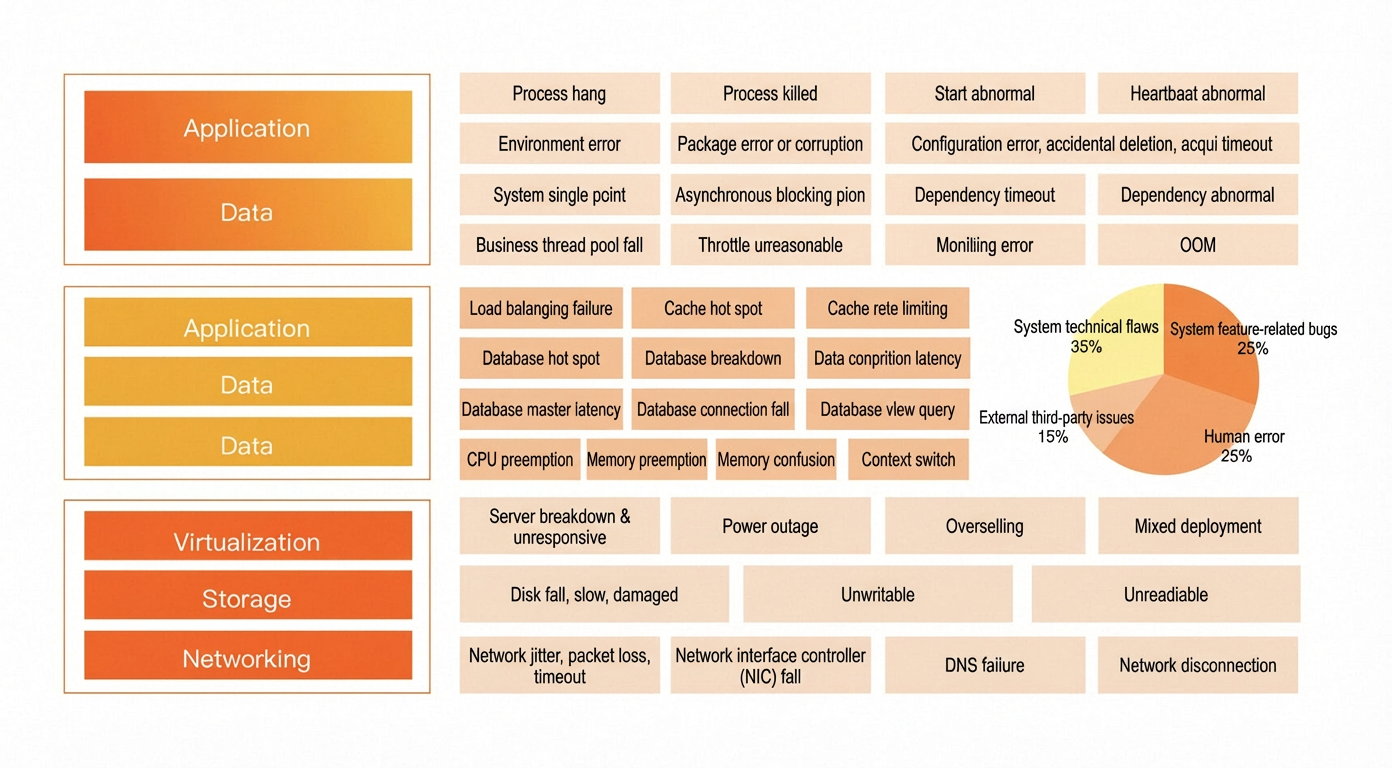
This classification takes a high-level perspective rather than a system design perspective. Refining the failure model yields the following conclusions:
-
Failures originate from either hardware (IaaS layer) or software (PaaS or SaaS layers). Hardware failures generally also manifest as software failures.
-
Failures occur in either single machines or distributed systems. Distributed system failures include single-machine failures.
-
From a system perspective, a single-machine failure can be internal to the current process, such as a full GC or high CPU usage, or external, such as another process consuming memory and causing an error. For most non-disruptive drills, the focus is on the impact of the failure on the current system rather than actually creating an external fault.
-
Additionally, some failures are caused by human error or improper processes. These are not the focus of this discussion.
Common failure types can be mapped to this model. Drill systems and plans can also be designed based on it. When designing a drill plan, consider injecting faults at each stage of the model to validate the emergency response plan.
Drill types and objectives
Based on their impact on online services, drills fall into two categories: disruptive (with service interruptions) and non-disruptive (without service interruptions). The two types differ in frequency and validation objectives.
Disruptive drills inject failures directly into the live production environment for highly realistic simulations. To limit service impact, they are usually performed on core scenarios during off-peak hours at a relatively low frequency. For example, a data center network outage drill to verify active-active disaster recovery capabilities might be conducted once a month. Non-disruptive drills are conducted in an isolated environment that does not handle service traffic, using stress testing to simulate traffic while injecting failures. Because there is no service impact, these drills can run frequently. For example, weekly drills can be organized for different teams to simulate online failures, validate post-failure improvements, and test monitoring and alert response capabilities.
|
Drill type |
Pros and cons |
Drill environment |
Drill frequency |
Main objectives |
|
Drills with service interruptions |
|
Live production environment |
Once every 1 to 2 months |
|
|
Drills without service interruptions |
|
End-to-end canary release environment or a new service environment |
1 to 2 times per week |
|
Fault drill best practices
Alibaba Group uses chaos engineering to perform regular drills, both disruptive and non-disruptive. This shortens the time needed to implement and execute large-scale drills, allowing teams to focus on identifying architectural and process risks and building system optimization and disaster recovery capabilities. This approach maximizes the return on investment for chaos engineering experiments.
Three types of infrequent drills are run in the production environment:
-
Data center network outage drills. These drills start by orchestrating service resources at the IP address level to simulate an outage for a single service, then gradually expand the scope to include all services. This ensures the continuous effectiveness of active-active disaster recovery and prevents failures caused by service iterations or changes in infrastructure and middleware.
-
Simulation and validation of major issues. Major architectural or service issues identified during company-wide reviews are simulated and the fixes are validated.
-
Annual surprise production drills. Typically initiated by the Chief Technology Officer (CTO), these drills test the entire fault handling process, including monitoring and detection, rapid alert response, efficient emergency organization, and issue localization and resolution.
Frequent drills are run in a simulated environment, such as an end-to-end canary release environment that constantly receives 1% of online traffic, or a newly built service environment.
-
Drills to validate each service's monitoring capabilities and alert response speed.
-
Drills that replay variations of past failures on the original and other services to validate system resilience and verify that post-failure improvements are effective.
-
Drills to validate each service's emergency response coordination and the effectiveness of various contingency plans.