Service creation
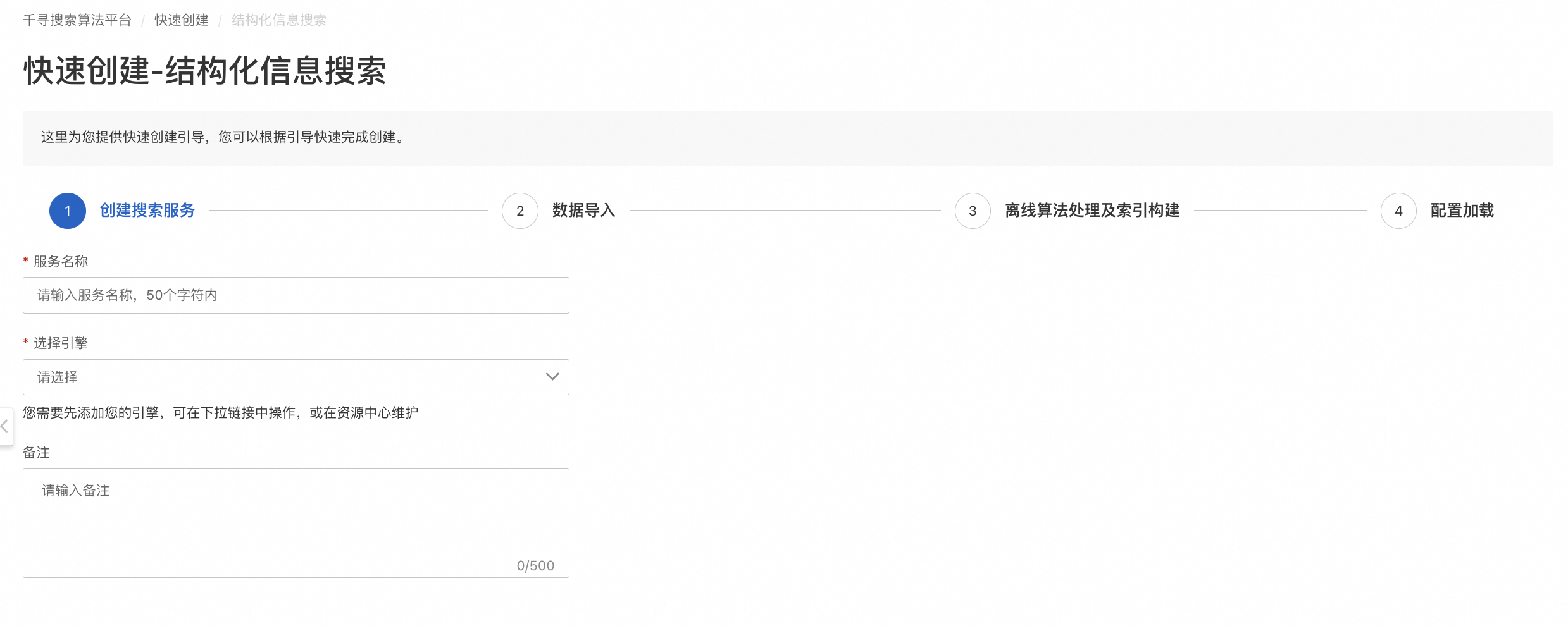
Click Quick Create and select Structured Information Search. On the service creation page, enter a service name and select an engine and a data source. After you create the service, the index configuration page appears.
Engine
Engines are the basic components that provide search services. You can manage engines in the Resource Center or add them on the Quick Create page. For more information, see the engine management user guide.
Supported DPI engines |
Configuration |
Plugin |
Link |
Tablestore |
A minimum of 2 VCUs is recommended for a production environment. For resource estimation details, see the Tablestore documentation. |
None |
Data import
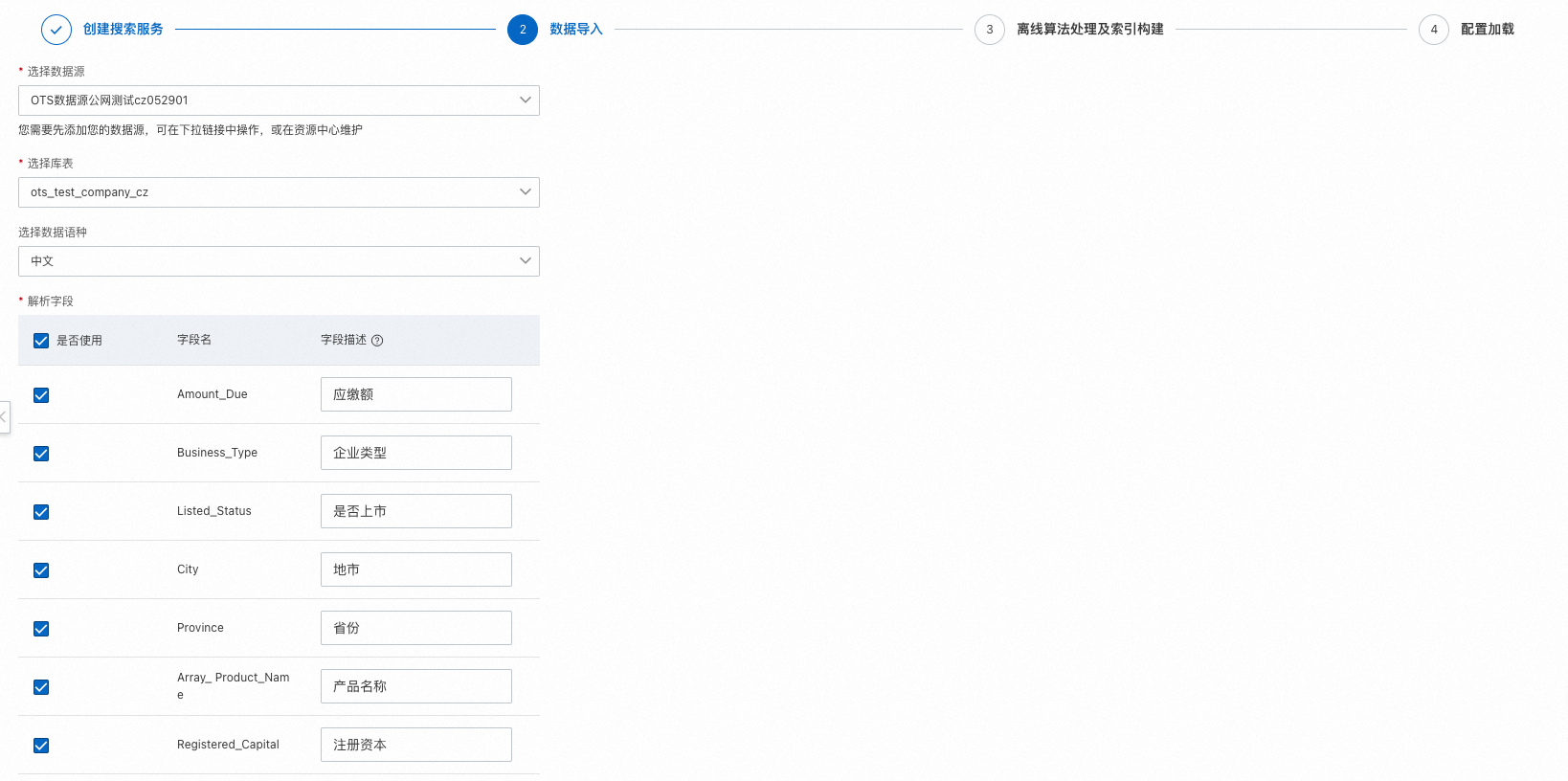
Data source
Data sources store your enterprise knowledge base. You can manage data sources in the Resource Center or add them on the Quick Create page. For more information, see the data source management user guide.
Supported data sources |
Links |
Alibaba Cloud Tablestore |
Subpath/Database table
This parameter specifies the storage address of the data source for your enterprise knowledge base. The system reads directory files or database tables from the specified data source. You can select files and their subdirectories, or select tables by subpath.
Parsed fields
The system parses data source fields offline to build the index. The fields available for parsing depend on the database table.
Select the checkbox next to each field that you want to index. These selected fields are stored and used to build the index. Different field types are used during the retrieval and sorting stages and can be displayed in the search results. Fields that are not selected are not indexed.
When describing a field, be brief and accurate. The search algorithm uses this description for semantic understanding, which affects search accuracy. You can edit this description only before the service is created. After the service is created, you must go to the service testing page to update and save any changes.
Configure index
Data source table
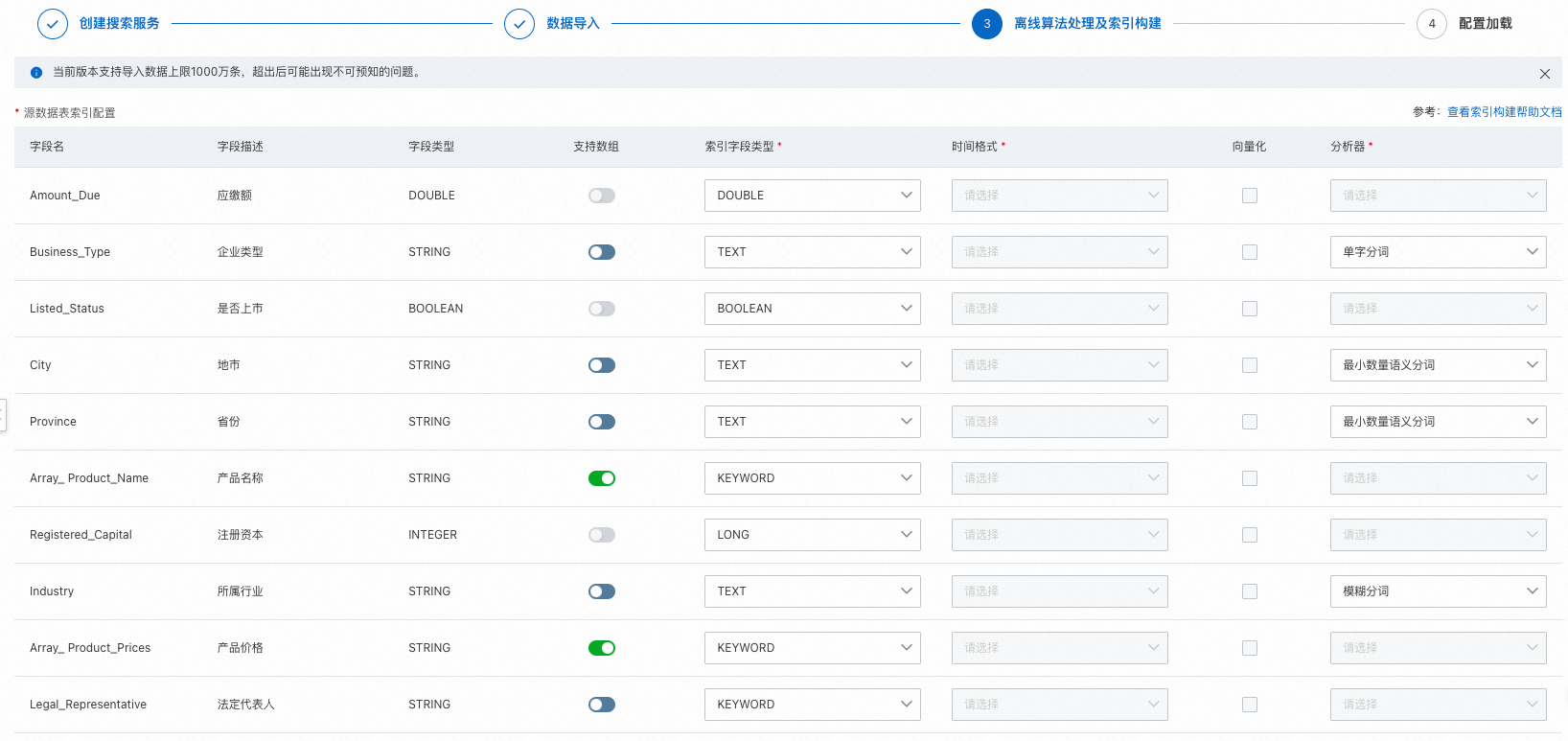
Field name, field description, and field type
For instances that use a data table as the data source, the field names must match the field names in the table. Field names cannot start with an underscore (_).
Array support
You can configure a field to support arrays if it meets both of the following conditions:
The original table field must be of the string type.
The index field must be of the keyword type.
Index field type
The index field type defines the data type of a field so that a search engine, such as Elasticsearch, can correctly process and index the field's values. The available index field types are:
The following index field types are available:
Field Data Types in a Search Index |
Field data type in the data table |
Description |
Long |
Integer |
64-bit integer. |
Double |
Double |
64-bit double-precision floating-point number. |
Boolean |
Boolean |
Boolean value. |
Keyword |
String |
A string that is not tokenized. |
Text |
String |
A string or text that can be tokenized. For more information, see Tokenization. |
Date |
Integer, String |
Date data type. Supports various custom date formats. For more information, see Date and time types. |
Geo-point |
String |
Geographic point coordinates in the format of "latitude,longitude". The latitude must be between -90 and +90, and the longitude must be between -180 and +180. For example, 35.8,-45.91. |
Nested |
String |
Nested type. For example, [{"a": 1}, {"a": 3}]. |
Analyzer
During index building, an analyzer is a tool that splits text data into tokens. It is an important component of the text analytics process and is used to build an inverted index for text searching and matching.
The analyzer splits input text according to specific rules, breaking down long text into individual characters or word fragments for indexing and searching. The search algorithm provides several built-in analyzers.
Only fields of the Text type can be assigned a tokenizer.
Tokenizer type |
Description |
Single-word tokenization |
Suitable for all languages, such as Chinese, English, and Japanese. The default tokenizer for Text fields is single-word tokenization. By default, it is case-insensitive and does not split words that combine English letters and numbers. |
Delimiter tokenization |
Uses whitespace characters as the default delimiter. |
Minimum semantic tokenization |
Splits the content of a Text field into the minimum number of semantic words. For example, a three-character word might be split into a one-character token and a two-character token. The resulting tokens do not overlap. |
Maximum semantic tokenization |
The system splits the text into as many semantic words as possible. Different semantic words may overlap, and the total length of the tokens will be greater than the original text, which increases the index size. For example, a three-character word might be split into two overlapping two-character tokens. |
Fuzzy tokenization |
Performs N-gram tokenization on the text content. The length of the resulting tokens is between `minChars` and `maxChars`. |
Vectorization
Text vectorization is the process of converting text data into numerical vectors. It represents words and sentences as vectors to calculate relevance in tasks such as information retrieval.
Example of text vectorization:
Input text: "a yellow skirt"
Vectorization result: [0.2694664001464844,-0.3998311161994934,-0.14598636329174042,-0.4976918697357178,-0.13986249268054962,0.6272065043449402,-0.1434994637966156,-0.33319777250289917]Note:
1. The result of vectorization is a list of floating-point numbers. The length of the list depends on the output dimension of the vectorization model.
2. During the index building phase, vectorization only applies to fields of the TEXT type.
3. If you select multiple TEXT fields for vectorization, the algorithm model automatically concatenates the fields and calculates a single vector result.
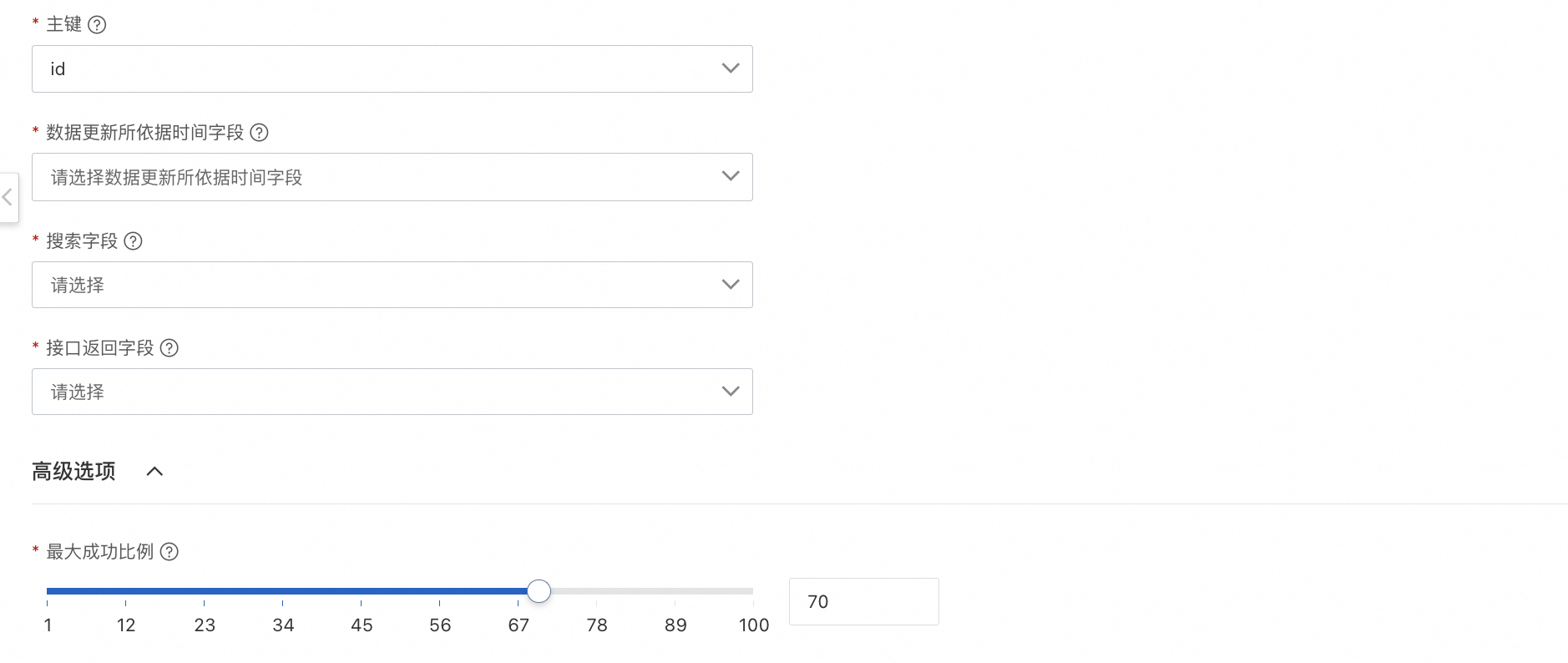
Primary key
Specify a primary key to uniquely identify data.
Time field for data updates
Specify a time field for updates. This field is used to identify subsequent index updates. If you do not specify this field, the index data is built only once and is not incrementally updated.
Search fields
These are the full-text index fields, which must be of the `keywords` or `text` type. These fields are used to perform search operations, match query conditions, and limit the search scope.
API response fields
Select the required business fields from the index configuration to be returned in the search request response. These fields are returned in the `fields` field of the OpenAPI response and can be used as reference content in multi-turn conversations with Large Language Models (LLMs).
Load configuration
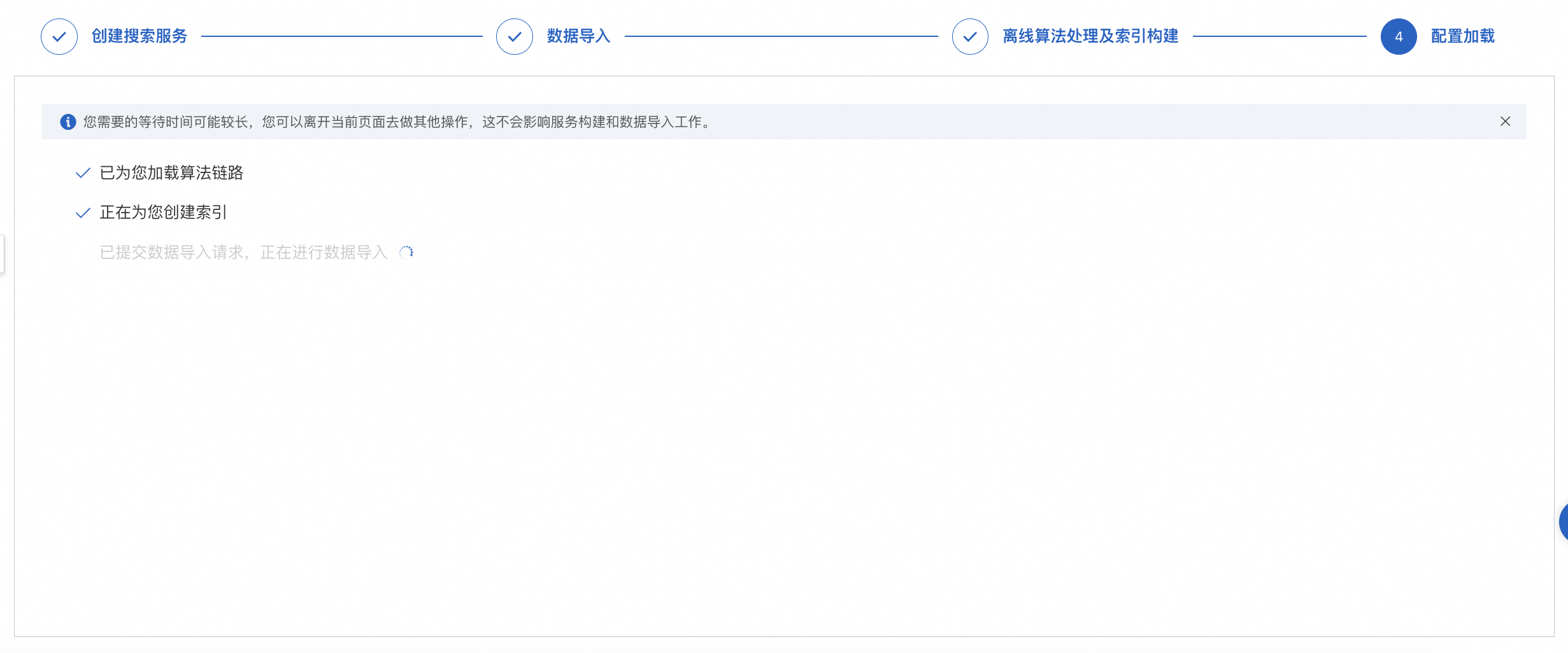
After you complete the creation and configuration process, the configuration is loaded. You can leave the current page and perform other operations. This does not affect the service building and data import tasks.
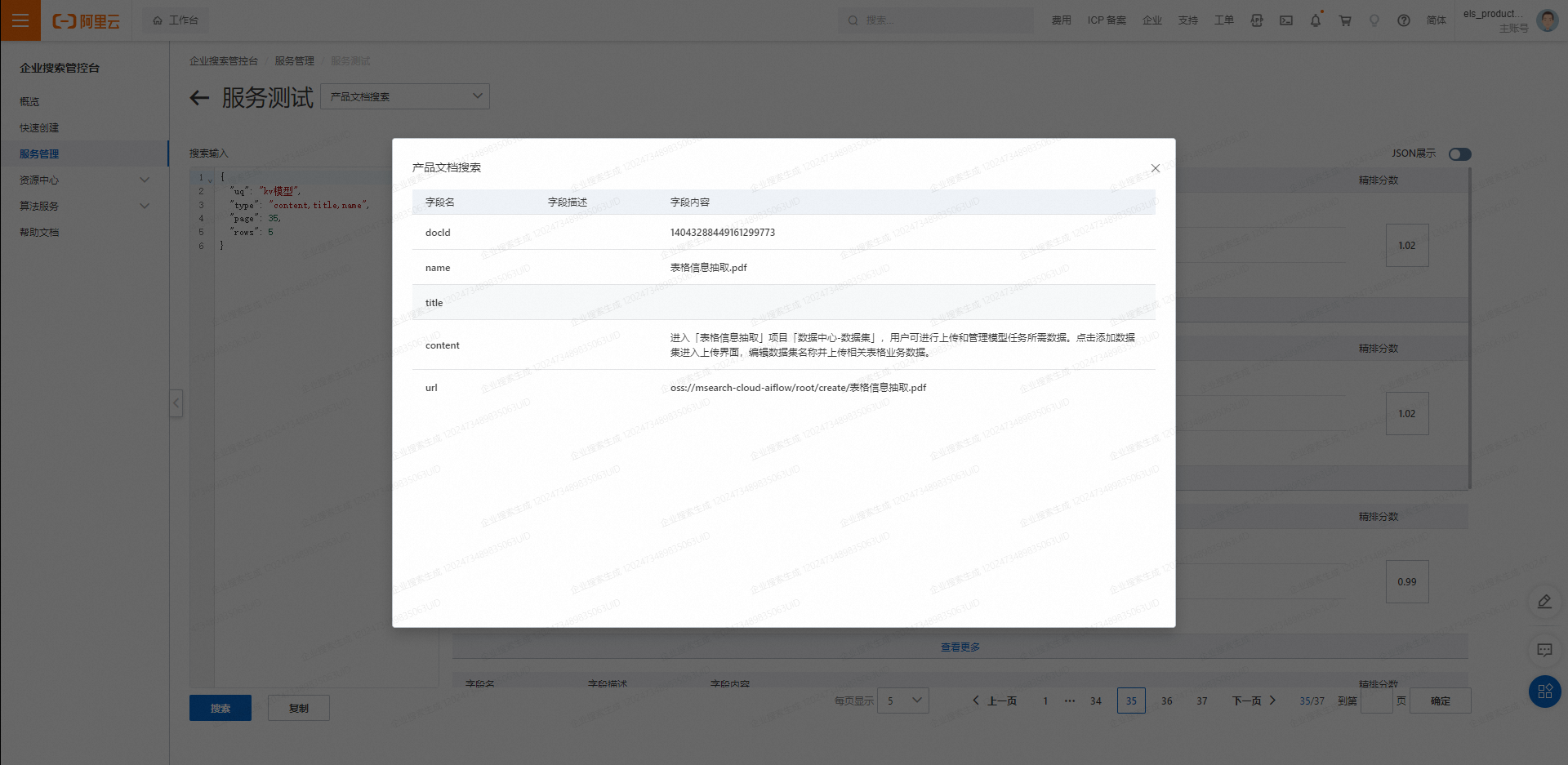
Service testing and online tuning
Search input
Advanced parameter settings
On the service testing page, you can configure advanced parameters. Click Add Configuration Parameter, select and configure the desired parameters, and then click Save to apply the settings.
Structured query parsing
Click the plus sign (+) to add an index for a field from the original database table and then create or update the field's description. In the field description, describe the field's meaning briefly and accurately. The search algorithm uses this description for semantic understanding, which affects search accuracy.
JSON configuration
The search input is in JSON format. For information about search parameters, see Structured Information Search API.
Request parameters
Field |
Type |
Description |
Default value |
serviceId |
long |
Service ID |
101 |
uq |
string |
User's search query |
|
type |
string |
Search type (full-text/segment) |
Dynamic adaptation |
queries |
List<map<string, object>> |
Search conditions |
[] |
filters |
List<map<string, object>> |
Filter conditions |
[] |
fields |
array |
Retrieved fields (forward index) |
[] |
sort |
array |
Sorting fields |
[] |
page |
int |
Paging (page number) |
1 |
rows |
int |
Paging (number of rows) |
10 |
rankModelInfo |
map<string, object> |
Algorithm intervention configuration (dedicated) |
{} |
customConfigInfo |
map<string, object> |
Custom intervention configuration |
{} |
debug |
boolean |
Debug information |
0 |
minScore |
float |
Score threshold |
0 |
Response parameters
Field |
Type |
Description |
Default value |
requestId |
string |
Request ID |
xxxx |
status |
int |
Request status |
0 |
message |
string |
Response message |
|
data.total |
int |
Total number of search results |
0 |
data.docs |
array(map/dict/json) |
Search results |
[] |
debug |
map<string, object> |
Debug information |
The following is an example of a common search input with explanations.
{
"uq": "search request", // User's search query
"type": "title,content,vector", // Index fields used in the retrieval phase
"debug": false, // Specifies whether to enable debugging
"fields": [ // Retrieved fields
"title",
"content"
],
"page": 1, // Paging (page number), starts from 1
"rows": 10, // Paging (number of rows)
"customConfigInfo": {
"qpEmbedding": true, // Specifies whether to use vector search
"uqVectorRecallRatio": 0.5, // Vector recall ratio for multi-channel recall
"rerankSize": 100 // Number of items to sort
},
"rankModelInfo": { // Sorting formula
"default": {
"features": [
{
"name": "vector_index", // Vector recall score
"weights": 1.0, // Feature weight
"threshold": 0.0, // Feature threshold (features with scores below the threshold are scored as 0)
"norm_factor": 0.001,
"norm": true,
"score_type": "L2"
},
{
"name":"static_value", // _rc_t_score is the text recall score, obtained through the static_value feature
"field":"_rc_t_score",
"weights":0.1,
"threshold":0,
"norm_factor": 80, // Normalization coefficient (for details, see the sorting formula documentation)
"norm":true // Specifies whether the feature needs to be normalized
},
{
"name": "query_match_ratio", // Coverage rate of the search query in the corresponding field
"field": "title", // Field name
"weights": 0.5,
"threshold": 0.0,
"norm": false
},
{
"name": "cross_ranker", // Semantic matching feature
"weights": 1.0,
"threshold": 0,
"fields": ["title", "desc"] // Fields to which the semantic matching feature applies (list type)
},
{
"name": "doc_match_ratio", // Coverage rate of the words in the corresponding field within the query
"field": "title",
"weights": 0.5,
"threshold": 0.0,
"norm": false
}
],
"aggregate_algo": "weight_avg" // Method for calculating the final sorting score. Currently, only "weight_avg" is supported.
}
}
}Multi-channel recall - vector recall ratio
Definition: The recall model includes text relevance recall and semantic vector recall. Text relevance recall retrieves documents by matching tokenized words. Semantic vector recall converts text into semantic embeddings and finds the closest documents in the vector space.
Recommended value: 50%. This means that text recall and semantic vector recall each account for half of the total number of retrieved documents.
Feature description: Controls the proportion of vector recall results in the total number of retrieved results for a query.
Tip: To use only text relevance recall, set this to 0%. The current version does not support vector-only recall, so do not set this to 100%.
Number of documents for fine-grained sorting
Definition: The maximum number of documents that enter the fine-grained sorting stage.
Recommended value: 200–500.
Feature description: After a query retrieves all relevant documents, they are sorted based on a basic relevance score. If the total number of retrieved documents is greater than the Number of documents for fine-grained sorting (N), the top N documents with the highest basic relevance scores enter the fine-grained sorting stage.
Tip: A larger value means more documents are used for fine-grained sorting. This can improve the final results but increases calculation time.
Minimum text match degree
Definition: The degree of match between the search conditions and the text.
Recommended value: 80%. This is a percentage value from 0 to 100%.
Feature description: In non-exact match mode, this parameter controls the similarity of the matched text. A match degree of 0.8 means that 80% of the text content matches the search conditions. If the match degree is less than the set value, the document is filtered out.
Score threshold
Definition: The sorting score threshold.
Recommended value: 0.
Feature description: This is used to filter out documents with low relevance scores. After all documents are sorted, documents with a score below this threshold are not returned.
Custom sorting formula
Definition: The product provides a rich set of sorting features that you can use to implement custom sorting. The sorting formula is in JSON format and is configured in rankModelInfo. The built-in sorting model scores the retrieved results based on the sorting features specified in the rankModelInfo formula to calculate the final sorting score. The built-in sorting module provides various sorting features and supports configuring the corresponding index field, weight, threshold, and normalization for each feature.
rankModelInfo
This is the configuration field for the custom sorting formula. It contains sorting formulas for the original query and for extra queries. Each sorting formula is a dictionary (dict), where the dict name is the name of the corresponding query field. The default sorting formula for the query (uq) is named "default". The sorting formulas for extra queries are named after their corresponding query names in the "extras" field.
Sorting formula
Each sorting formula contains two parts: "features" and "aggregate_algo". "features" is a list of specific sorting features and their parameters. "aggregate_algo" currently only supports "weight_avg", which calculates the weighted sum of all features. This weighted sum is the fine-grained sorting score.
Features
Each feature is in dict format and includes the feature name and its parameters. The common parameters for features are as follows:
Common feature parameters
name: The feature name.
field: The index field for calculating the relevance feature.
weight: The feature weight, which is a floating-point number.
threshold: The feature score threshold, which is a floating-point number. Feature scores below the threshold are set to 0. Note: The threshold value is applied to the score before normalization. The purpose of the threshold is to filter out the impact of low-match feature scores and strengthen high-match features, allowing for effective feature selection through custom settings.
norm: Specifies whether to normalize the feature. This is a boolean. Normalization adjusts the original sorting feature scores to a uniform scale (between 0 and 1) using a specific transformation method. Its main purpose is to eliminate dimensional differences between different features, making their scores comparable.
norm_factor: A floating-point number. This is the normalization coefficient used to scale the original score. We recommend setting this to the mean of the original distribution, which cannot be 0.
The specific descriptions for each feature are as follows:
Feature descriptions
Feature name |
Description |
Special feature parameters |
vector_index |
Vector match score (requires vector recall configuration). |
score_type: The calculation type for the vector search score. You can choose L2 (higher score for more relevance) or IP (lower score for more relevance). The default is IP. Select the appropriate score_type based on the vector engine configuration. |
text_index |
Search engine recall score. Tip: This feature is only supported for text-only recall. When using multi-channel recall (vector + search engine), you can use the static_value feature to get the search engine recall score by setting the field to "_rc_t_score". |
|
timeliness |
Timeliness score, proportional to the millisecond difference between the given time field and a base time. The value ranges from 0 to 1. |
time_field(str): The time field name, in the format: "%Y-%m-%d %H:%M:%S.%f" field(str): The field name, which must be the same as the time field name. base_time(str): The base time field, in the format: "%Y-%m-%d %H:%M:%S". This should be set to the time of the earliest document. normalized_number(float): Controls the granularity of the timeliness score. This should typically be set to 1e6. |
doc_match_ratio |
The ratio of the number of matching words between the field and the query to the total number of words in the field. |
|
query_match_ratio |
The ratio of the number of matching words between the query and the field to the total number of words in the query. |
|
doc_match_count |
The number of matching words between the field and the query. |
|
query_match_count |
The number of matching words between the query and the field. |
|
query_min_slide_window |
Measures the proximity of matching words between the query and the field. It is the ratio of the number of matching words in the query to the minimum window in the field that contains those words (match order is not considered). |
|
ordered_query_min_slide_window |
Measures the proximity of matching words between the query and the field. It is the ratio of the number of matching token groups in the query to the minimum window in the field that contains those groups (ordered match). |
|
doc_unique_ratio |
The ratio of the number of unique words to the total number of words in a field. Used to filter documents with repetitive keywords. |
|
overlap_coefficient |
The ratio of the number of matching words between the query and the field to the total number of words in both. Measures text match degree. |
|
char_overlap_coefficient |
The ratio of the number of matching characters between the query and the field to the total number of characters in both. Measures character-level similarity. |
|
lcs_match_ratio |
The ratio of the length of the word-level longest common subsequence between the query and the field to the number of words in the query. |
|
char_lcs_match_ratio |
The ratio of the length of the character-level longest common subsequence between the query and the field to the number of characters in the query. Suitable for string matching scenarios such as emails and mobile numbers. |
|
edit_similarity |
Text similarity calculated based on the edit distance between the field and the query. The value ranges from 0 to 1, where a higher value indicates greater similarity. Used to measure the degree of an exact match between the query and the field. Recommended for matching questions with questions, used with a high threshold. |
|
char_edit_similarity |
Character-level edit similarity. |
|
char_sequential_match_priority |
A dedicated feature for matching names (considers match order). It calculates character-level sequential match priority. The match similarity for the i-th character is 1 / |i-j|, where j is the position of the nearest identical character in the field. The weight of the i-th character is 1.0 / i. The final score is the weighted average of all character similarities. This feature is used to calculate order-related text similarity. |
|
pinyin_lc_substr |
The ratio of the length of the Pinyin longest common substring between the query and the field to the length of the Pinyin in the field. Measures Pinyin similarity. |
|
doc_pinyin_lc_substr |
The ratio of the length of the Pinyin longest common substring between the query and the field to the length of the Pinyin in the query. Measures Pinyin similarity. |
|
static_value |
Uses the value of a numeric field itself as the feature score. |
|
name_pinyin_match |
A dedicated feature for matching names in Pinyin. It checks if the query's Pinyin matches the full Pinyin, Pinyin initial abbreviation, or a mix of initials and full Pinyin of the corresponding field. For example, if a name field has a value that corresponds to the Pinyin 'zhangsan', this feature checks if the query's Pinyin is one of ['zhangsan', 'zs', 'zhangs', 'zsan']. If it matches, it returns a score of 1. Otherwise, it returns 0. |
|
prefix_match_ratio |
Word-level prefix match feature. The match score is the length of the longest common prefix between the query and the field divided by the query length. Prefix matching means matching words sequentially from the first position. Suitable for scenarios where match position is important (such as email matching, where a match at the beginning has higher relevance). It is recommended to use this with other features, such as lcs_match_ratio. |
|
char_prefix_match_ratio |
Character-level prefix match feature. The match score is the length of the longest common prefix between the query and the field divided by the query length. Suitable for scenarios where match position is important (such as email matching, where a match at the beginning has higher relevance). It is recommended to use this with other features, such as lcs_match_ratio. |
|
pinyin_prefix_match_ratio |
Pinyin prefix match feature. The match score is the length of the longest common prefix between the query and the field divided by the query length. Suitable for scenarios where match position is important (such as email matching, where a match at the beginning has higher relevance). It is recommended to use this with other features, such as lcs_match_ratio. |
|
is_contained |
Checks if the query is an exact match for any item in a given field (list type). Used for matching labels. The corresponding index field must be of the list[string] type. |
|
contained_boost |
The number of times the complete query appears in the given field. Used to increase the match degree for exact query matches. |
|
part_of_doc |
Checks if the complete query appears in the given field (1 if it appears, 0 if not). Used to increase the match degree for exact query matches. |
Custom sorting best practices
Tip: The following examples assume that an indexed field named "content" exists.
{
"rankModelInfo": {
"default": {
"features": [
{
"name": "text_index",
"weights": 1.0,
"threshold": 10,
"norm": true
},
{
"name": "query_match_ratio",
"weights": 1.0,
"threshold": 0.0,
"field":"content"
}
],
"aggregate_algo": "weight_avg"
},
}
}{
"rankModelInfo":{
"default":{
"features":[
{
"name":"static_value",
"field":"_rc_t_score",
"weights":1,
"threshold":10,
"norm":true
},
{
"name":"vector_index",
"weights":1,
"threshold":0,
"norm":true,
"norm_factor":0.001,
"score_type": "L2"
},
{
"name":"query_match_ratio",
"weights":1,
"threshold":0,
"field":"content"
}
],
"aggregate_algo":"weight_avg"
}
}
}{
"rankModelInfo": {
"default": {
"features": [
{
"name": "static_value",
"field": "_rc_t_score",
"weights": 1,
"threshold": 10,
"norm": true
},
{
"name": "vector_index",
"weights": 1,
"threshold": 0,
"norm": true,
"norm_factor": 0.001,
"score_type": "L2"
},
{
"name": "query_match_ratio",
"weights": 1,
"threshold": 0,
"field": "title"
}
],
"aggregate_algo": "weight_avg"
}
},
"keyword": {
"features": [
{
"name": "query_match_ratio",
"weights": 1,
"threshold": 0,
"field": "content"
}
],
"aggregate_algo": "weight_avg"
}
}This example shows a sorting formula with an extra query named "keyword". You must configure a query field named "keyword" in the "extras" field.