
可通过阿里云Prometheus监控查看ACK Edge集群预先配置的监控大盘和监控性能指标。本文介绍如何在ACK Edge集群中接入阿里云Prometheus监控。
前提条件
已创建ACK Edge集群,且版本为1.18.8-aliyunedge.1及以上。
确保ACK Edge集群已安装的ack-arms-prometheus版本为1.1.4及以上,如不满足,请及时升级ack-arms-prometheus版本。
如果集群版本小于1.26,需要检查确保集群
kube-system/edge-tunnel-server-cfg的ConfigMap中,已经对Node Exporter的端口9100、GPU Exporter的端口9445开启了转发配置,具体配置信息如下:http-proxy-ports: 9445 https-proxy-ports: 9100
阿里云Prometheus监控介绍
阿里云Prometheus监控全面对接开源Prometheus生态,支持类型丰富的组件监控,提供多种开箱即用的预置监控大盘,且提供全面托管的Prometheus服务。借助阿里云Prometheus监控,无需自行搭建Prometheus监控系统,无需关心底层数据存储、数据展示、系统运维等问题。
ACK Edge集群支持使用容器监控基础版。
查看阿里云Prometheus Grafana大盘
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面中,单击目标集群名称,然后在左侧导航栏中,选择。
说明仅首次登录时,需要根据页面提示,单击安装组件下面的开始安装,控制台会自动安装组件并检查监控大盘。安装完成后跳转到Prometheus监控详情页面。
在Prometheus监控页面,可通过内置的监控大盘,例如节点监控、应用监控、GPU监控分别查看到集群中节点、应用及GPU的监控数据。
配置Prometheus监控报警
为监控任务创建报警可在满足报警条件时通过电话、邮件、短信、钉钉、企业微信和Webhook等渠道实时报警,主动帮助发现异常。报警规则被触发时会向指定的联系人分组发送通知,而在创建联系人分组之前必须先创建联系人。创建联系人时,可指定联系人用于接收通知的手机号和邮箱地址;也可以在通知策略中指定对应的接收群用于接收告警,便于及时对告警进行管理。
关于创建钉钉机器人的具体操作,请参见钉钉机器人。
关于创建企业微信机器人的具体操作,请参见企业微信机器人。
关于创建飞书机器人的具体操作,请参见飞书(Lark)机器人。
步骤一:创建联系人
步骤二:创建Prometheus告警规则
通过静态阈值创建Prometheus告警规则
静态阈值检查类型提供了系统预设的告警指标,通过选择已有的告警指标,可通过语义化的方式快速创建对应指标项的告警规则。
登录ARMS控制台。
在左侧导航栏,选择。
在Prometheus告警规则页面,单击创建Prometheus告警规则。
在创建Prometheus告警规则页面设置如下告警参数,设置完成后单击保存。
参数
说明
示例
告警名称
告警的名称。
生产集群-容器CPU使用率告警
检测类型
选择静态阈值。
静态阈值
Prometheus实例
选择需要创建告警的Prometheus实例。
生产集群
告警分组
选择告警分组。
不同Prometheus类型支持的告警分组不同,告警分组备选项会随着选择的Prometheus实例类型的不同产生变化。
Kubernetes负载
告警指标
选择想要配置告警的指标,每个告警分组对应不同的指标。
容器CPU使用率
告警条件
基于告警指标预置内容设置告警事件产生条件。
当容器CPU使用率
大于80%时,满足告警条件。筛选条件
根据告警指标,设置当前配置的告警规则适用的范围,即所有符合筛选条件的资源满足此条告警规则时,均会产生告警事件。
可选筛选条件包括:
遍历:告警规则适用于当前Prometheus实例下的所有资源。筛选条件默认为遍历。
等于:选择该条件后,需要继续输入具体资源名称。所创建的告警规则将仅适用于对应资源。不支持同时填写多个资源。
不等于:选择该条件后,需要继续输入具体资源名称。所创建的告警规则将适用于除该资源之外的其他资源。不支持同时填写多个资源。
正则匹配:选择该条件后,按需输入正则表达式匹配相应的资源名称。所创建的告警规则将适用于符合该正则表达式的所有资源。
正则不匹配:选择该条件后,按需输入正则表达式匹配相应的资源名称。所创建的告警规则将过滤符合该正则表达式的所有资源。
说明完成筛选条件设置后,会弹出数据预览区域。
请将筛选条件字符限制在300个字符以内。
遍历
数据预览
数据预览区域展示告警条件对应的PromQL语句,并以时序曲线的形式展示当前告警规则配置的监控指标的值。
默认仅展示一个资源的实时值,您可以在该区域的筛选框中选择目标资源以及时间区间来查看不同时间区间和不同资源的值。
说明告警阈值将会以一条红色直线的形式显示在时序曲线中,满足告警阈值的时序曲线显示为深红色,不满足告警阈值的时序曲线显示为蓝色。
将鼠标悬浮于时序曲线上,可以查看对应时间点的资源详情。
在时序曲线上选中一段时间,可以查看对应时间段的时序曲线。
无
持续时间
当告警条件满足时,直接产生告警事件:任何一个数据点满足阈值,就会产生告警事件。
当告警条件满足持续N分钟时,才产生告警事件:即只有当满足阈值的时间大于等于N分钟时,才产生告警事件。
1
告警等级
自定义告警等级。默认告警等级为默认,告警严重程度从默认、P4、P3、P2、P1逐级上升。
默认
告警内容
用户收到的告警信息。您可以使用Go template语法在告警内容中自定义告警参数变量。
命名空间:{{$labels.namespace}} / Pod: {{$labels.pod_name}} / 容器:{{$labels.container}} CPU使用率{{$labels.metrics_params_opt_label_value}} {{$labels.metrics_params_value}}%, 当前值{{ printf "%.2f" $value }}%
告警通知
极简模式:可以设置通知对象、通知时段和重复策略。
普通模式:
不指定通知策略:若选择此选项,当完成创建告警规则后,您可以在通知策略页面新建通知策略并指定匹配规则和匹配条件(如告警规则名称等)来匹配该告警规则。当该告警规则被触发产生告警事件后,告警信息会被发送给通知策略中指定的联系人或联系人组。更多信息,请参见通知策略。
指定某个通知策略:若选择此项,ARMS会自动在对应的通知策略添加一条匹配规则,匹配规则内容为告警规则ID(以告警规则名称的方式呈现),以确保当前告警规则产生的告警事件一定可以被选择的通知策略匹配到。
重要快速指定通知策略只能保证当前告警规则产生的告警事件一定能够被所选的通知策略匹配到并且产生对应的告警。但是,当前告警规则产生的事件同时也可能被其它设置了模糊匹配的通知策略匹配到并且产生告警。告警规则产生的告警事件和通知策略之间是多对多的匹配关系。
不指定通知规则
高级设置
告警检查周期
指告警规则每隔N分钟进行一次检查,判断数据是否满足告警条件。默认1分钟,最少设置1分钟。
1
数据完整后再检查
是
否
是
标签
设置告警标签,设置的标签可用作通知策略匹配规则的选项。
无
注释
设置告警的注释。
无
通过自定义PromQL创建Prometheus告警规则
如果需要对静态阈值中系统预设指标之外的指标进行监控,可使用自定义PromQL检测类型来创建告警规则。
在创建Prometheus告警规则页面设置以下告警参数,设置完成后单击保存。
参数 | 说明 | 示例 |
告警名称 | 告警的名称。 | Pod的CPU使用率大于8% |
检测类型 | 设置为自定义PromQL。 | 自定义PromQL |
Prometheus实例 | 选择需要创建告警的Prometheus实例。 | 无 |
参考告警分组 | 选择告警分组。 不同Prometheus类型支持的告警分组不同,告警分组备选项会随着选择的Prometheus实例类型的不同产生变化。 | Kubernetes负载 |
参考告警指标 | 可选。参考指标中包括了常见指标的自定义PromQL配置方法,您可以选择已有的类似指标来进行填充,然后参考对应指标的配置方式进行修改以完成告警配置。 参考指标参数会根据选择的Prometheus实例类型自动过滤支持的告警指标。 | Pod磁盘使用率告警 |
自定义PromQL语句 | 使用PromQL语句设置告警规则表达式。 | 命名空间:{{$labels.namespace}}/Pod: {{$labels.pod_name}}/磁盘设备:{{$labels.device}} 使用率超过90%,当前值{{ printf "%.2f" $value }}%max(container_fs_usage_bytes{pod!="", namespace!="arms-prom",namespace!="monitoring"}) by (pod_name, namespace, device)/max(container_fs_limit_bytes{pod!=""}) by (pod_name,namespace, device) * 100 > 90 |
数据预览 | 数据预览区域展示告警条件对应的PromQL语句,并以时序曲线的形式展示当前告警规则配置的监控指标的值。 默认仅展示一个资源的实时值,您可以在该区域的筛选框中选择目标资源以及时间区间来查看不同时间区间和不同资源的值。 说明
| 无 |
持续时间 |
| 1 |
告警等级 | 自定义告警等级。默认告警等级为默认,告警严重程度从默认、P4、P3、P2、P1逐级上升。 | 默认 |
告警内容 | 用户收到的告警信息。您可以使用Go template语法在告警内容中自定义告警参数变量。 | 命名空间:{{$labels.namespace}}/Pod: {{$labels.pod_name}}/磁盘设备:{{$labels.device}} 使用率超过90%,当前值{{ printf "%.2f" $value }}% |
告警通知 |
| 不指定通知规则 |
高级设置 | ||
告警检查周期 | 指告警规则每隔N分钟进行一次检查,判断数据是否满足告警条件。默认1分钟,最少设置1分钟。 | 1 |
数据完整后再检查 |
| 是 |
标签 | 设置告警标签,设置的标签可用作通知策略匹配规则的选项。 | 无 |
注释 | 设置告警的注释。 | 无 |
验证告警配置
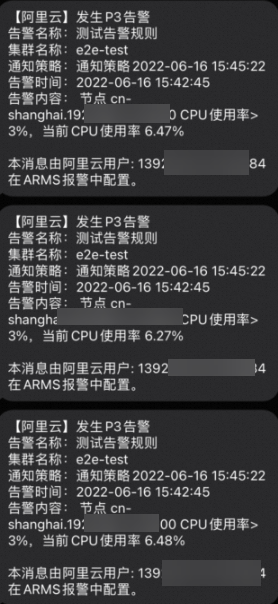
以通过手机短信监控实时报警为例,进行手动测试,正常触发告警如下:
常见问题
如何查看ack-arms-prometheus组件版本?
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,单击组件管理。
在组件管理页面,单击日志与监控页签,找到ack-arms-prometheus组件。
在组件下方显示当前版本信息,如有新版本需要升级,可单击版本右侧升级完成组件升级。
说明当已安装的组件版本不是最新版本时,才会显示升级操作。
ACK Edge集群如何实现监控数据的获取?
在边缘计算场景中,边缘节点处在相对封闭的线下IDC环境中,云上VPC和边缘侧处于不同的网络平面内。部署在云上的Prometheus Agent无法直接通过Endpoint访问到边缘侧的Node Exporter、GPU Exporter,从而获取相应的监控指标。从ack-arms-prometheus 1.1.4版本开始,借助ACK Edge集群内置的云边运维通信组件Tunnel,ack-arms-prometheus可以自动打通云边之间的监控数据采集链路。
为什么GPU监控无法部署?
如GPU节点上存在污点,可能导致GPU监控无法部署。可通过以下步骤查看GPU节点的污点情况。
执行以下命令,查看目标GPU节点的污点情况。
如GPU节点拥有自定义的污点,可找到污点相关的条目。本文以
key为test-key、value为test-value、effect为NoSchedule为例说明:kubectl describe node cn-beijing.47.100.***.***预期输出:
Taints:test-key=test-value:NoSchedule通过以下两种方式处理GPU节点的污点。
执行以下命令,删除GPU节点的污点。
kubectl taint node cn-beijing.47.100.***.*** test-key=test-value:NoSchedule-对GPU节点的污点进行容忍度声明,允许Pod调度到该污点的节点上。
# 1.执行以下命令,编辑ack-prometheus-gpu-exporter。 kubectl edit daemonset -n arms-prom ack-prometheus-gpu-exporter # 2. 在YAML中添加如下字段,声明对污点的容忍度。 #省略其他字段。 #tolerations字段添加在containers字段上面,且与containers字段同级。 tolerations: - key: "test-key" operator: "Equal" value: "test-value" effect: "NoSchedule" containers: #省略其他字段。
手动删除资源或将导致重新安装阿里云Prometheus失败,如何完整地手动删除ARMS-Prometheus?
只删除阿里云Prometheus的命名空间,会导致资源删除后有残留配置,影响再次安装。可执行以下操作,完整地手动删除ARMS-Prometheus残余配置。
删除arms-prom命名空间。
kubectl delete namespace arms-prom删除ClusterRole。
kubectl delete ClusterRole arms-kube-state-metrics kubectl delete ClusterRole arms-node-exporter kubectl delete ClusterRole arms-prom-ack-arms-prometheus-role kubectl delete ClusterRole arms-prometheus-oper3 kubectl delete ClusterRole arms-prometheus-ack-arms-prometheus-role kubectl delete ClusterRole arms-pilot-prom-k8s kubectl delete ClusterRole gpu-prometheus-exporter kubectl delete ClusterRole o11y:addon-controller:role kubectl delete ClusterRole arms-aliyunserviceroleforarms-clusterrole删除ClusterRoleBinding。
kubectl delete ClusterRoleBinding arms-node-exporter kubectl delete ClusterRoleBinding arms-prom-ack-arms-prometheus-role-binding kubectl delete ClusterRoleBinding arms-prometheus-oper-bind2 kubectl delete ClusterRoleBinding arms-kube-state-metrics kubectl delete ClusterRoleBinding arms-pilot-prom-k8s kubectl delete ClusterRoleBinding arms-prometheus-ack-arms-prometheus-role-binding kubectl delete ClusterRoleBinding gpu-prometheus-exporter kubectl delete ClusterRoleBinding o11y:addon-controller:rolebinding kubectl delete ClusterRoleBinding arms-kube-state-metrics-agent kubectl delete ClusterRoleBinding arms-node-exporter-agent kubectl delete ClusterRoleBinding arms-aliyunserviceroleforarms-clusterrolebinding删除Role及RoleBinding。
kubectl delete Role arms-pilot-prom-spec-ns-k8s kubectl delete Role arms-pilot-prom-spec-ns-k8s -n kube-system kubectl delete RoleBinding arms-pilot-prom-spec-ns-k8s kubectl delete RoleBinding arms-pilot-prom-spec-ns-k8s -n kube-system
手动删除ARMS-Prometheus资源后,请在容器服务管理控制台的运维管理>组件管理中,重新安装ack-arms-prometheus组件。