
日志服务提供DaemonSet与Sidecar两种方式部署Logtail以供采集K8s日志,两种方式的差异请参考K8s集群场景Logtail安装采集指引。本文介绍如何通过Sidecar方式采集K8s集群文本日志。
前提条件
已创建目标Project和Logstore。具体操作,请参见管理Project和管理Logstore。
若您使用自建集群,请确保已安装kubectl。
操作步骤
本文以阿里云ACK托管集群为例,介绍使用Sidecar方式采集K8s集群日志时的三个步骤:
为业务Pod注入Logtail容器:每个容器组(Pod)运行一个Logtail容器,用于采集当前容器组(Pod)所有容器(Containers)的日志。不同Pod的日志采集相互隔离。
创建用户自定义标识机器组:为每个容器组(Pod)创建自己的机器组,日志服务通过机器组的方式管理所有需要通过Logtail采集日志的容器。
创建Logtail采集配置:Logtail组件会根据采集配置将增量日志采集并处理后上传到Logstore中。
查询分析日志:您可以在目标Logstore查看日志数据。
步骤一:为业务Pod注入Logtail容器
自建集群和ACK集群只有登录方式不同,其他步骤一样。
登录容器服务管理控制台。在左侧导航栏中,单击集群列表,单击目标集群操作列下的更多,然后单击管理集群。

在您已有的业务容器YAML中添加如下内容:
若您没有现有的业务容器或仅为了测试操作流程,本文也为您提供一个YAML示例:您只需修改示例中的ALIYUN_LOGTAIL_USER_ID为您的阿里云主账号ID,并保证ALIYUN_LOGTAIL_CONFIG中地域
${region_id}与您的日志服务Project的地域一致即可,取值请参见开服地域后替换。执行
kubectl apply -f <YOUR-YAML>使配置生效。执行
kubectl describe pod <YOUR-POD-NAME>,得到如下信息说明Logtail容器注入成功。
步骤二:创建用户自定义标识机器组
YAML中${your_machine_group_user_defined_id}为用户自定义标识,本文示例值为nginx-log-sidecar。
登录日志服务控制台,在Project列表,单击打开目标Project。
左侧导航栏中,选择。在打开的机器组页面中,选择机器组右侧的
 > 创建机器组。
> 创建机器组。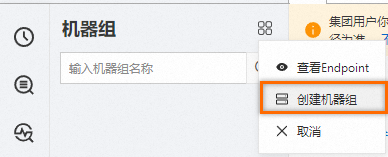
在弹出的创建机器组页面,填写以下信息,并单击确定。
参数
说明
名称
机器组名称,命名规则如下所示:
只能包括小写字母、数字、短划线(-)和下划线(_)。
必须以小写字母或者数字开头和结尾。
长度必须在 2~128 字符之间。
重要创建后,不支持修改机器组名称,请谨慎填写。
机器组标识
选择用户自定义标识。
机器组Topic
(可选)机器组Topic用于区分不同服务器产生的日志数据。更多信息,请参见日志主题。
用户自定义标识
填入上述步骤中配置的用户自定义标识。本文示例值为
nginx-log-sidecar。
步骤三:创建Logtail采集配置
登录日志服务控制台。
单击控制台右侧的快速接入数据,在接入数据区域单击Kubernetes-文件卡片。

选择目标Project和Logstore,单击下一步。
在机器组配置页面完成如下操作。机器组相关信息,请参见机器组。
根据实际场景,单击以下页签:
确认目标机器组已在应用机器组列表中,然后单击下一步。该机器组为步骤二创建的用户自定义标识机器组。如果机器组心跳为FAIL或无机器信息,您可单击自动重试,若仍为FAIL,请检查YAML中ALIYUN_LOGTAIL_CONFIG的地域是否与Project一致。如果问题仍未解决,请参见Logtail机器组无心跳进行排查。
创建Logtail采集配置,单击下一步创建Logtail采集配置,日志服务开始采集日志。
说明Logtail采集配置生效时间最长需要3分钟,请耐心等待。
此处仅介绍必须配置,详细配置请参见Logtail采集配置。
全局配置
配置名称:Logtail配置名称,在其所属Project内必须唯一。创建Logtail配置成功后,无法修改其名称。
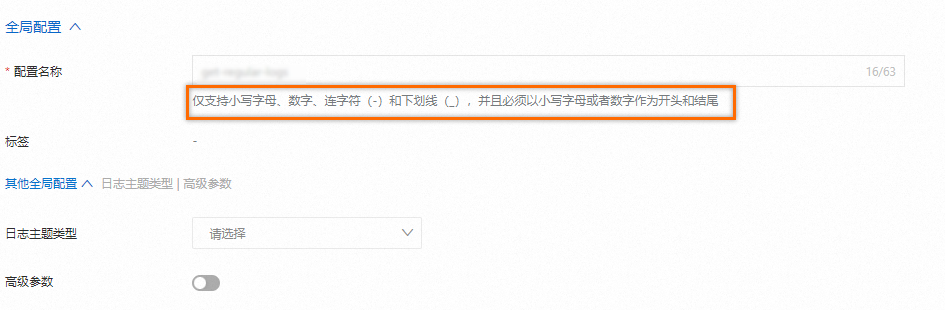
输入配置
Logtail部署模式:选择Sidecar。
文件路径类型:选择待采集的容器路径。
文件路径:目录名和文件名均支持完整模式和通配符模式,其中日志路径通配符只支持星号(*)和半角问号(?)。本例目录值为YAML中的
${dir_containing_your_files}。/apsara/nuwa/**/*.log表示/apsara/nuwa目录(包含该目录的递归子目录)中后缀名为.log的文件。

处理配置
日志样例:支持多条日志;添加日志样例可协助您配置日志处理相关参数,降低配置难度,建议添加。
多行模式:本示例为采集多行日志,请打开此功能。
类型,选择自定义。
切分失败处理方式,选择保留单行。
行首正则表达式:
单击自动生成表达式,单击验证,验证正则合规性。
处理模式,选择无。有关处理插件的更多信息,请参见处理插件概述。
创建索引和预览数据,然后单击下一步。日志服务默认开启全文索引。您也可以根据采集到的日志,手动创建字段索引,或者单击自动生成索引,日志服务将自动生成字段索引。更多信息,请参见创建索引。
重要如果需要查询日志中的所有字段,建议使用全文索引。如果只需查询部分字段、建议使用字段索引,减少索引流量。如果需要对字段进行分析(SELECT语句),必须创建字段索引。
步骤四:查询分析日志
在Project列表中,单击目标Project,进入对应的Project详情页面。

在对应的日志库右侧的
 图标,选择查询分析,查看Kubernetes集群输出的日志。
图标,选择查询分析,查看Kubernetes集群输出的日志。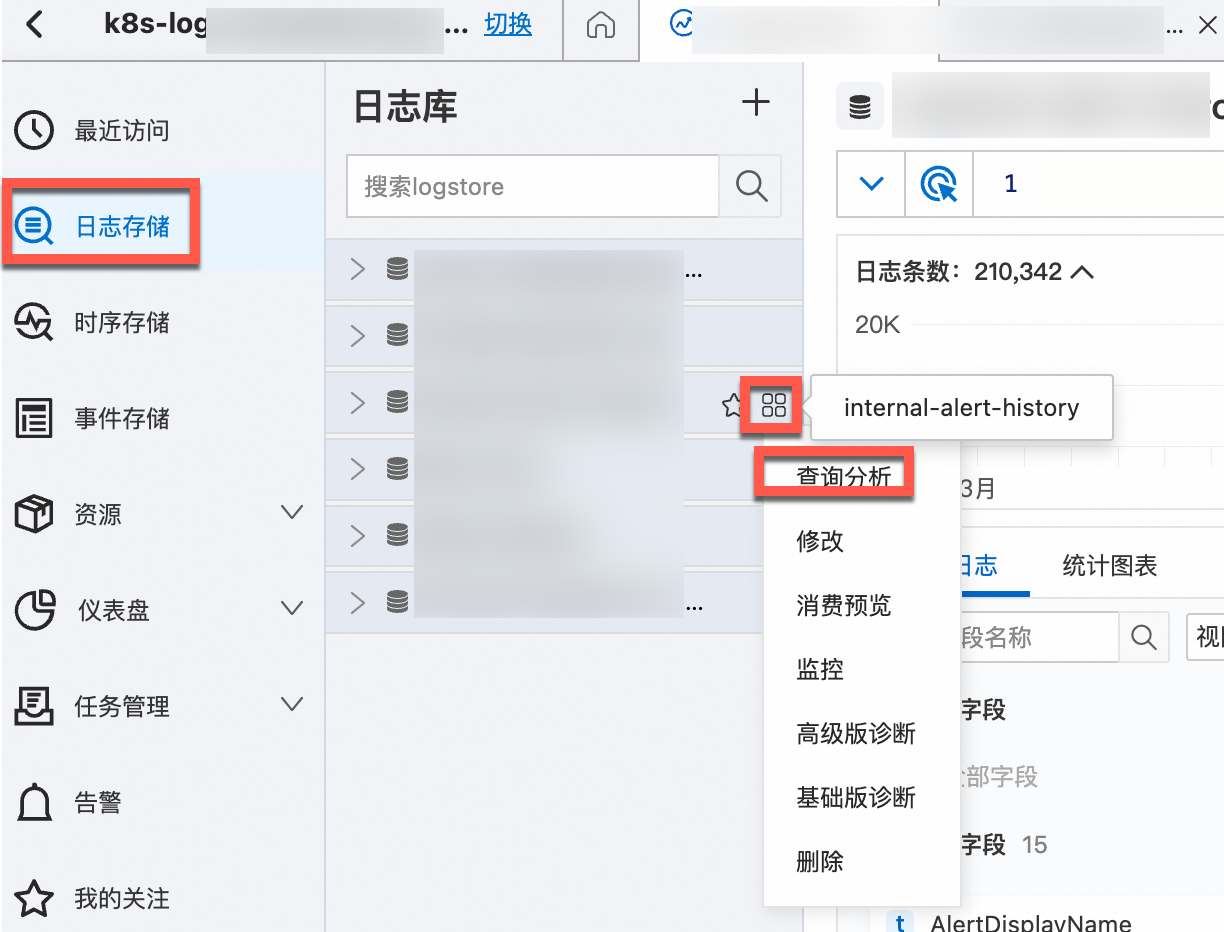
容器日志文本默认字段
K8s每条容器文本日志默认包含的字段如下表所示。
字段名称 | 说明 |
__tag__:__hostname__ | 容器宿主机的名称。 |
__tag__:__path__ | 容器内日志文件的路径。 |
__tag__:_container_ip_ | 容器的IP地址。 |
__tag__:_image_name_ | 容器使用的镜像名称。 说明 若存在多个相同Hash但名称或Tag不同的镜像,采集配置将根据Hash选择其中一个名称进行采集,无法确保所选名称与YAML文件中定义的一致。 |
__tag__:_pod_name_ | Pod的名称。 |
__tag__:_namespace_ | Pod所属的命名空间。 |
__tag__:_pod_uid_ | Pod的唯一标识符(UID)。 |
相关文档
当您完成日志内容的采集后,您可以在日志服务中使用可视化功能, 来帮助您直观的统计与了解日志情况,请参考快速创建仪表盘。
当您完成日志内容的采集后,您可以在日志服务中使用告警功能, 来自动提醒您日志中的异常情况,请参考快速设置日志告警。
日志服务仅采集增量日志,历史日志文件采集请参见导入历史日志文件。
容器采集异常排查思路:
查看控制台是否有报错信息,具体操作,请参见如何查看Logtail采集错误信息。
如果控制台无报错信息,排查机器组心跳、Logtail采集配置等内容。具体操作,请参见如何排查容器日志采集异常。