本文基于DaemonSet模式,介绍如何通过日志服务控制台采集Kubernetes集群的文本日志和容器标准输出,涵盖了基础采集,结构化解析及高级处理的完整配置流程。
基础配置(必选):用于定义采集任务的核心参数,确保日志数据顺利采集并传输至指定Project下的Logstore。
解析配置(可选):根据日志格式选择内置解析功能(如Nginx/JSON/正则),将原始日志结构化解析为键值对数据,降低查询分析成本。
高级配置(可选):在完成基础采集配置后,对日志内容进行脱敏、过滤等处理,满足更精细化的日志采集需求。
Sidecar模式请参考采集集群文本日志(Sidecar)。
核心概念
在开始配置日志采集前,请先了解阿里云日志服务(SLS)的核心资源概念以及LoongCollector(Logtail)在Kubernetes环境中的运行模式。
Logstore是日志数据的存储单元,用于存储日志。在Project内,可根据业务需求创建多个Logstore存储不同类型的日志,如使用两个Logstore分别存储Nginx访问日志和应用错误日志。可参考此处步骤预先创建一个基础Logstore。
|
|
前提条件
若集群未安装LoongCollector(Logtail)组件,请参考此处步骤进行安装,本文以安装LoongCollector为例介绍。如需了解如何安装Logtail,请参考Logtail安装与配置。
LoongCollector 是阿里云日志服务(SLS)推出的新一代日志采集 Agent,是 Logtail 的升级版,二者不能同时存在。如果当前正在使用 logtail-ds,并希望升级到 LoongCollector,请先卸载logtail-ds再安装LoongCollector。
此操作仅适用于阿里云容器服务专有版Kubernetes和托管版Kubernetes。
通过容器服务控制台安装LoongCollector,默认将日志发送到当前阿里云账号的日志服务中,如果需配置跨账号日志采集,即将当前账号下的ACK集群日志,发送至另一个阿里云账号的日志服务Project中,请参考如何将ACK集群日志传输到另一个阿里云账号的Project?
为已有的ACK集群安装LoongCollector组件
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,单击组件管理。
在日志与监控页签中,找到loongcollector,单击安装。
安装完成后,日志服务会自动在ACK所属地域下创建如下资源,可登录日志服务控制台查看。
资源类型
资源名称
作用
Project
k8s-log-${cluster_id}资源管理单元,隔离不同业务日志。
机器组
k8s-group-${cluster_id}日志采集节点集合。
Logstore
config-operation-log重要请不要删除该Logstore。
用于存储LoongCollector组件中的alibaba-log-controller日志,其收费标准与普通Logstore完全相同,具体请参见按写入数据量计费模式计费项。建议不要在此Logstore下创建采集配置。
创建存储采集日志的Logstore:登录日志服务控制台,在Project列表中单击默认创建的名为
k8s-log-${cluster_id}的Project。在页签中,单击+图标。填写Logstore名称,其余配置无需修改,使用默认值即可。如需详细了解创建配置请参见管理Logstore。
新建ACK集群时安装LoongCollector组件
登录容器服务管理控制台,在左侧导航栏选择集群列表。
单击创建集群,在组件配置页面,选中使用日志服务。支持创建新Project或使用已有Project。
本文只描述日志服务相关配置,关于更多配置项说明,请参见创建ACK托管集群。
选择创建新Project,日志服务会自动创建如下资源,可登录日志服务控制台查看。
资源类型
资源名称
作用
Project
k8s-log-${cluster_id}资源管理单元,隔离不同业务日志。
机器组
k8s-group-${cluster_id}日志采集节点集合。
Logstore
config-operation-log重要请不要删除该Logstore。
用于存储LoongCollector组件中的alibaba-log-controller日志,其收费标准与普通Logstore完全相同,具体请参见按写入数据量计费模式计费项。建议不要在此Logstore下创建采集配置。
创建存储采集日志的Logstore:登录日志服务控制台,在Project列表中单击默认创建的名为
k8s-log-${cluster_id}的Project。在页签中,单击+图标。填写Logstore名称,其余配置无需修改,使用默认值即可。如需详细了解创建配置请参见管理Logstore。
安装之前,请确保集群满足Kubernetes 1.6及以上版本,且已安装kubectl。
连接Kubernetes集群,根据地域选择命令下载LoongCollector及其他依赖组件。
#中国地域 wget https://aliyun-observability-release-cn-shanghai.oss-cn-shanghai.aliyuncs.com/loongcollector/k8s-custom-pkg/3.0.12/loongcollector-custom-k8s-package.tgz; tar xvf loongcollector-custom-k8s-package.tgz; chmod 744 ./loongcollector-custom-k8s-package/k8s-custom-install.sh #海外地域 wget https://aliyun-observability-release-ap-southeast-1.oss-ap-southeast-1.aliyuncs.com/loongcollector/k8s-custom-pkg/3.0.12/loongcollector-custom-k8s-package.tgz; tar xvf loongcollector-custom-k8s-package.tgz; chmod 744 ./loongcollector-custom-k8s-package/k8s-custom-install.sh进入
loongcollector-custom-k8s-package目录,修改配置文件./loongcollector/values.yaml,详细配置参数请参见LoongCollector安装(Kubernetes)。# ===================== 必需要补充的内容 ===================== # 本集群要采集的Project名,例如 k8s-log-custom-sd89ehdq projectName: "" # Project所属地域,例如上海:cn-shanghai region: "" # Project所属主账号uid,请用引号包围,例如"123456789" aliUid: "" # 使用网络,可选参数:公网Internet,内网Intranet,默认使用公网 net: Internet # 主账号或者子账号的AK,SK,需具备AliyunLogFullAccess系统策略权限 accessKeyID: "" accessKeySecret: "" # 自定义集群ID,命名只支持大小写,数字,短划线(-)。 clusterID: ""在
loongcollector-custom-k8s-package目录下执行如下命令,安装LoongCollector及其他依赖组件。bash k8s-custom-install.sh install安装完成后,查看组件状态,若未成功启动,请确认values.yaml配置是否正确,相关镜像拉取是否成功。日志服务会自动创建如下资源,可登录日志服务控制台查看。
# 检查Pod状态 kubectl get po -n kube-system | grep loongcollector-ds
资源类型 | 资源名称 | 作用 |
Project | values.yaml文件中自定义的 | 资源管理单元,隔离不同业务日志。 |
机器组 |
| 日志采集节点集合。 |
Logstore |
重要 请不要删除该Logstore。 | 用于存储LoongCollector组件中的alibaba-log-controller日志,其收费标准与普通Logstore完全相同,具体请参见按写入数据量计费模式计费项。建议不要在此Logstore下创建采集配置。 |
创建存储日志的Logstore:登录日志服务控制台,在Project列表区域单击名为k8s-log-{ClusterID}的目标Project,在页签中,单击+图标。填写Logstore名称,其余配置无需修改,使用默认值即可。如需详细了解创建配置请参见管理Logstore。
基础配置
在确认满足前提条件后,可开始进行基础配置。基础配置是设置日志采集的起点,包括选择采集源,配置机器组等,建立起从集群到日志服务的数据通道,确保原始日志能够顺利采集。
登录日志服务控制台,单击管理日志资源的Project,在日志库(Logstore)
|
|
采集容器标准输出(Stdout)
采集集群文本日志
解析配置
在完成基础配置后,可根据日志格式使用对应的处理插件对原始日志进行结构化解析,方便后续查询分析。对比示例(以Nginx日志为例)如下:
原始日志: | |
基础配置采集结果 | 选择处理插件(Nginx解析插件)解析结果 |
| |
以下是常见的处理插件配置:
Logtail提供了处理插件用于将原始日志进一步解析为结构化数据,处理插件分为原生处理插件和扩展处理插件,此处仅覆盖原生处理插件的使用。
无论是在创建新的采集配置还是修改现有配置时,都需要在区域灵活添加解析插件,以实现日志的结构化解析。
修改已有配置时:需先进入Logtail编辑页面,在目标Project页面中单击
 展开目标Logstore,单击Logtail配置,单击目标Logtail配置操作列的管理Logtail配置,在配置页面单击编辑。然后在区域,按需从下列场景中选择合适的解析插件进行配置。
展开目标Logstore,单击Logtail配置,单击目标Logtail配置操作列的管理Logtail配置,在配置页面单击编辑。然后在区域,按需从下列场景中选择合适的解析插件进行配置。创建新配置时:可以直接在区域,按需从下列场景中选择合适的解析插件修改采集配置规则:
正则解析
示例:使用正则表达式(\S+)\s-\s(\S+)\s\[([^]]+)]\s"(\w+)\s(\S+)\s([^"]+)"\s(\d+)\s(\d+)\s"([^"]+)"\s"([^"]+).*进行解析。
原始日志 | 自定义正则解析 |
| |
通过正则表达式提取日志字段,并将日志解析为键值对形式。在处理配置区域配置正则解析插件,进行如下配置,其余配置保持默认,完成后单击下一步:
添加日志样例:请务必使用实际场景中待采集日志的样例,配置日志样例可协助配置日志处理相关参数,降低配置难度。
单击添加处理插件,选择正则解析:
正则表达式:用于匹配日志,支持自动生成或手动输入的方式。
如果提供了日志样例,可以通过单击自动生成正则表达式,在日志样例中划选需要提取的日志内容,单击生成正则,自动生成正则表达式。

根据日志内容手动输入正则表达式,如果提供了日志样例,可以单击验证,测试正则表达式是否能够正确解析日志内容。
日志提取字段:为提取的日志内容(Value),设置对应的字段名(Key)。
在查询分析配置页面预览数据,单击自动生成索引,日志服务将生成字段索引。通过此索引针对特定字段进行精确查询,从而减少索引费用和提高查询效率。完成后单击下一步结束配置。
分隔符解析
标准JSON解析
嵌套JSON解析
JSON数组解析
Nginx日志解析
Apache日志解析
高级配置
在完成基础配置后,可参考下述操作采集多行日志、对日志进行过滤、脱敏等处理,以满足更精细化的日志采集需求。以下是常见高级配置及其功能:
无论是在创建新的采集配置还是修改现有配置时,都需要在页面修改采集配置规则。
修改已有配置时:需先进入Logtail编辑页面,在目标Project页面中单击![]() 展开目标Logstore,单击Logtail配置,单击目标Logtail配置操作列的管理Logtail配置,在配置页面单击编辑。
展开目标Logstore,单击Logtail配置,单击目标Logtail配置操作列的管理Logtail配置,在配置页面单击编辑。
创建新配置时:可直接在页面,按需从下列场景中选择合适的解析插件修改采集配置规则:
配置多行日志采集:当一条日志内容(如异常堆栈信息)占用多行时,需启用多行模式,并配置行首正则表达式以匹配日志的起始行,将占用多行的日志作为一条日志采集并存储到日志服务。
允许日志(文本文件/容器标准输出)多次采集:允许一个文件日志或容器标准输出被多个LoongCollector(Logtail)配置采集。
配置日志主题类型:为不同的日志流设置不同的主题(Topic),可用于组织和分类日志数据,更好地管理和检索相关日志。
指定容器采集(过滤与黑名单):需要指定特定容器与路径采集时,包括白名单与黑名单配置。
日志标签富化:将环境变量、Pod标签相关的元信息添加到日志中,作为日志的扩展字段。
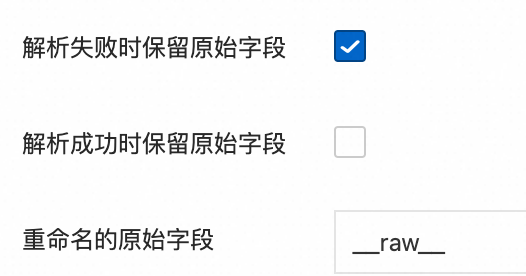
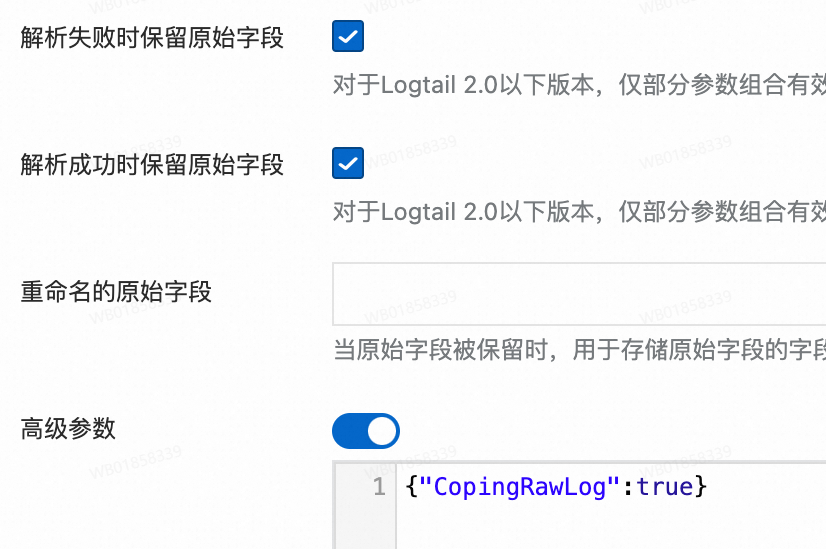
日志脱敏处理:对日志中的敏感信息进行脱敏处理后保存到日志服务。
日志内容过滤:当原始日志中有大量无效日志无需保存到日志服务时,可使用日志过滤来剔除。
指定写入日志时间:用于解析日志中的时间字段,并将解析结果设置为日志的
__time__字段。日志压缩:如果想要优化日志传输效率,可配置压缩方式,支持
lz4和zstd。
对比示例(以脱敏插件为例)
原始日志: | |
JSON文本日志采集结果 | 脱敏插件解析结果 |
| |
配置多行日志采集
日志服务默认为单行模式,按行进行日志的切分与存储,导致含堆栈信息的多行日志被逐行切分,每一行作为独立日志存储和展示,不利于分析。
针对上述问题,可通过开启多行模式来改变日志服务的切分方式,并通过配置正则表达式匹配日志起始行,从而将原始日志按照起始行规则进行切分和存储。示例如下:
原始日志:
[2023-10-01T10:30:01,000] [INFO] java.lang.Exception: exception happened
at TestPrintStackTrace.f(TestPrintStackTrace.java:3)
at TestPrintStackTrace.g(TestPrintStackTrace.java:7)
at TestPrintStackTrace.main(TestPrintStackTrace.java:16)单行模式与多行模式对比:
单行模式:每行作为独立日志,堆栈信息被拆散,丢失上下文 | 多行模式:通过行首正则识别完整日志,保留完整语义结构 |
| |

在Logtail配置页面进行多行模式配置,配置完成后单击保存即可:
处理配置:开启多行模式。
类型:选择自定义或多行JSON。
自定义:原始日志的格式不固定,需配置行首正则表达式,来标定每一条日志的起始行。
行首正则表达式:支持自动生成或手动输入,正则表达式需要能够匹配完整的一行数据,如上述示例中匹配的正则表达式为
\[\d+-\d+-\w+:\d+:\d+,\d+]\s\[\w+]\s.*。单击自动生成正则表达式,然后在日志样例文本框中,划选需提取的日志内容,单击生成正则。
单击手动输入正则表达式,输入正则表达式。配置完成后,单击验证。
多行JSON:当原始日志均为标准JSON格式时选择,LoongCollector(Logtail)会自动处理单条JSON日志内部的换行。
切分失败处理方式:
丢弃:直接丢弃这段日志。
保留单行:将每行日志文本单独保留为一条日志。
允许日志(文本文件/容器标准输出)多次采集
配置日志主题类型
在Logtail配置页面进行如下配置,配置完成后单击保存即可:
:配置日志主题类型。
日志主题类型:选择日志主题(Topic)的生成方式。
机器组Topic:日志服务支持将一个LoongCollector(Logtail)配置应用到多个机器组。使用机器组Topic可用于区分来自不同机器组的日志。LoongCollector(Logtail)上报数据时,会将服务器所在机器组的机器组Topic作为日志主题上传至Project。用户在查询日志时需要指定日志主题作为查询条件。
文件路径提取:若不同的用户或应用将日志保存在不同的顶级目录中,但下级目录和日志文件名相同,日志服务在采集日志时无法明确区分日志是由哪个用户或应用产生的。此时文件路径提取方式可用于区分不同用户或应用产生的日志数据。通过正则表达式来完整匹配文件路径,并将表达式匹配的结果(用户名或应用名)作为日志主题(Topic)上传至日志服务。
说明文件路径的正则表达式中,需要对正斜线(/)进行转义。
场景1:不同用户将日志记录在不同目录下,但是日志文件名称相同,目录路径如下所示。
/data/logs ├── userA │ └── serviceA │ └── service.log ├── userB │ └── serviceA │ └── service.log └── userC └── serviceA └── service.log如果在Logtail配置中仅配置文件路径为
/data/logs且文件名称为service.log,LoongCollector(Logtail)会将三个service.log文件中的内容采集至同一个Logstore中,因此无法区分日志具体由哪个用户产生。可使用正则表达式提取文件路径中的值,生成不同的日志主题。正则表达式
提取结果
\/data\/logs\/(.*)\/serviceA\/.*__topic__: userA __topic__: userB __topic__: userC场景2:如果单个日志主题不足以区分日志的来源,可在日志文件路径中配置多个正则捕获组来提取关键信息。其中捕获组包括命名捕获组(?P<name>)与非命名捕获组两类。
如果使用命名捕获组,则生成的tag字段为
__tag__:{name};如果使用非命名捕获组,则生成的tag字段为
__tag__:__topic_{i}__,其中{i}为捕获组的序号。
说明当正则表达式中存在多个捕获组时,不会生成
__topic__字段。例如,文件路径为
/data/logs/userA/serviceA/service.log,可通过以下方式提取文件路径中的多个值:示例
正则表达式
提取结果
使用非命名捕获组进行正则提取。
\/data\/logs\/(.*?)\/(.*?)\/service.log__tag__:__topic_1__: userA __tag__:__topic_2__: serviceA使用命名捕获组进行正则提取。
\/data\/logs\/(?P<user>.*?)\/(?P<service>.*?)\/service.log__tag__:user: userA __tag__:service: serviceA验证:配置完成后,根据日志主题查询日志:在日志查询分析页面,输入对应生成的日志主题,例如
__topic__: userA、__tag__:__topic_1__: userA查询相应主题的日志。更多信息,请参见查询语法与功能。
自定义:输入
customized:// + 自定义主题名,使用自定义的静态日志主题。
指定容器采集(过滤与黑名单)
日志标签富化
日志脱敏处理
日志内容过滤
指定写入日志时间
日志压缩
后续步骤
完成日志采集后,可在日志服务控制台,查询到相关数据,建议继续学习以下内容,来更好的使用和了解日志服务:
日志查询与分析:在对应的Logstore查询和分析页面,配置索引后,可以在搜索栏输入查询或分析语句,对日志进行查询和分析。如果初次使用,建议可使用内置的通过AI智能生成查询与分析语句(Copilot),自动生成符合需求的查询分析语句。更多内容,请参考查询与分析快速指引。
采集的每条容器文本日志中默认包含以下字段信息:
字段名称
说明
__tag__:__hostname__
容器宿主机的名称。
__tag__:__path__
容器内日志文件的路径。
__tag__:_container_ip_
容器的IP地址。
__tag__:_image_name_
容器使用的镜像名称。
__tag__:_pod_name_
Pod的名称。
__tag__:_namespace_
Pod所属的命名空间。
__tag__:_pod_uid_
Pod的唯一标识符(UID)。
数据可视化看板:如果需将查询分析的结果生成可视化图表,可以使用日志服务仪表盘来进行可视化大盘的设计,借助可视化仪表盘监控关键指标趋势,具体请参考快速创建仪表盘。
数据异常自动预警:也可为日志设置告警策略,来方便的实时感知系统的异常情况,具体请参考快速设置日志告警。
通过这三步闭环管理,可显著提升运维效率并保障系统稳定性。
容器日志采集无数据排查思路
检查是否有增量日志:配置LoongCollector(Logtail)采集后,如果待采集的日志文件没有新增日志,则LoongCollector(Logtail)不会采集该文件。
操作:检查机器组心跳状态:前往![]() 资源 > 机器组页面,单击目标机器组名称,在区域,查看心跳状态并记录心跳状态为ok的节点数。
资源 > 机器组页面,单击目标机器组名称,在区域,查看心跳状态并记录心跳状态为ok的节点数。
检查容器集群中Worker节点数。
查看集群中Worker节点数。
kubectl get node | grep -v master系统会返回如下类似结果。
NAME STATUS ROLES AGE VERSION cn-hangzhou.i-bp17enxc2us3624wexh2 Ready <none> 238d v1.10.4 cn-hangzhou.i-bp1ad2b02jtqd1shi2ut Ready <none> 220d v1.10.4
对比心跳状态为OK的节点数是否和容器集群中Worker节点数一致。根据对比结果选择排查方式。
机器组中所有节点的心跳状态均为Failed:
如果是自建集群,请检查以下参数是否配置正确:
{regionId}、{aliuid}、{access-key-id}和{access-key-secret}是否已正确填写。如果填写错误,请执行
helm del --purge alibaba-log-controller命令,删除安装包,然后重新安装。
机器组心跳状态为OK的节点数量少于集群中的Worker节点数量。
判断是否已使用YAML文件手动部署DaemonSet。
执行如下命令。如果存在返回结果,则表示之前已使用YAML文件手动部署DaemonSet。
kubectl get po -n kube-system -l k8s-app=logtail根据实际值,配置${your_region_name}、${your_aliyun_user_id}、${your_machine_group_name}等参数。
更新资源。
kubectl apply -f ./logtail-daemonset.yaml
常见问题
如何将ACK集群日志传输到另一个阿里云账号的Project?
更多信息
全局配置参数介绍
输入配置参数介绍
处理配置参数介绍
配置项 | 说明 |
日志样例 | 待采集日志的样例,请务必使用实际场景的日志。日志样例可协助配置日志处理相关参数,降低配置难度。支持添加多条样例,总长度不超过1500个字符。 |
多行模式 |
|
处理模式 | 处理插件组合,包括原生插件和拓展插件。有关处理插件的更多信息,请参见处理插件概述。 重要 处理插件的使用限制,请以控制台页面的提示为准。
|