在 Kubernetes 环境中,容器日志分散、难以集中管理,导致问题排查效率低、运维成本高。通过以DaemonSet模式部署LoongCollector采集器,并在日志服务控制台创建采集配置,即可实现日志的统一收集与结构化处理,提升日志检索、问题定位及可观测性分析的效率。
适用范围
运行环境:
支持阿里云容器服务ACK(托管与专有版)和自建Kubernetes 集群。
Kubernetes为1.10.0及以上版本且支持
Mount propagation: HostToContainer。容器运行时(仅支持Docker与Containerd)
Docker:
需具备访问docker.sock的权限。
标准输出采集仅支持JSON类型的日志驱动。
存储驱动仅支持overlay、overlay2两种存储驱动(其他类型需手动挂载日志目录)。
Containerd:需具备访问containerd.sock的权限。
资源要求:LoongCollector(Logtail)以system-cluster-critical高优先级运行,集群资源不足时请勿部署,否则可能驱逐节点上原有的Pod。
CPU:至少预留0.1 Core。
内存:采集组件至少150MB,控制器组件至少100MB。
实际使用量与采集速率、监控目录和文件数量、发送阻塞程度有关,请保证实际使用率低于限制值的80%。
权限要求:部署使用的阿里云主账号或子账号需具备
AliyunLogFullAccess权限。如需自定义权限策略,请参考AliyunCSManagedLogRolePolicy系统策略,将其包含的权限内容复制并赋予目标 RAM 用户或角色,以实现精细化的权限配置。
采集配置创建流程
安装LoongCollector:通过DaemonSet模式部署LoongCollector,确保集群中每个节点均运行一个采集容器,统一采集该节点上所有容器的日志。
Sidecar模式请参考采集Kubernetes Pod文本日志(Sidecar模式)。
创建Logstore:用于存储采集日志。
查询与分析配置:系统默认开启全文索引,支持关键词搜索。建议启用字段索引,以便对结构化字段进行精确查询和分析,提升检索效率。
步骤一:安装LoongCollector
LoongCollector 是阿里云日志服务推出的新一代日志采集 Agent,是 Logtail 的升级版,二者不能同时存在,如需安装Logtail,请参考安装、运行、升级、卸载Logtail。
本文仅介绍LoongCollector的基础安装流程,如需了解详细参数请参考安装配置。若已安装LoongCollector或Logtail,可跳过本步骤,直接步骤二:创建Logstore。
在LoongCollector(Logtail)运行过程中,若宿主机时间发生变化,可能导致日志重复采集或丢失。
ACK集群
通过容器服务控制台安装LoongCollector,默认将日志发送到当前阿里云账号的日志服务Project中。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
单击目标集群名称,进入集群详情页。
在左侧导航栏,单击组件管理。
切换至日志与监控页签,找到loongcollector,单击安装。
说明在创建集群时,可在组件配置页面勾选使用日志服务,支持创建新Project或使用已有Project。
安装完成后,日志服务会在当前账号下自动创建以下资源,您可登录日志服务控制台查看。
资源类型
资源名称
作用
Project
k8s-log-${cluster_id}资源管理单元,隔离不同业务日志。
如需自行创建Project以实现更灵活的日志资源管理,请参考创建Project。
机器组
k8s-group-${cluster_id}日志采集节点集合。
Logstore
config-operation-log重要请不要删除该Logstore。
用于存储loongcollector-operator组件的日志,其计费方式与普通Logstore相同,详见按写入数据量计费模式计费项。建议不要在此Logstore下创建采集配置。
自建集群
连接Kubernetes集群,根据集群所在地域执行对应命令:
中国地域
wget https://aliyun-observability-release-cn-shanghai.oss-cn-shanghai.aliyuncs.com/loongcollector/k8s-custom-pkg/3.0.12/loongcollector-custom-k8s-package.tgz; tar xvf loongcollector-custom-k8s-package.tgz; chmod 744 ./loongcollector-custom-k8s-package/k8s-custom-install.sh海外地域
wget https://aliyun-observability-release-ap-southeast-1.oss-ap-southeast-1.aliyuncs.com/loongcollector/k8s-custom-pkg/3.0.12/loongcollector-custom-k8s-package.tgz; tar xvf loongcollector-custom-k8s-package.tgz; chmod 744 ./loongcollector-custom-k8s-package/k8s-custom-install.sh进入
loongcollector-custom-k8s-package目录,修改配置文件./loongcollector/values.yaml。# ===================== 必需要补充的内容 ===================== # 本集群要采集的Project名,例如 k8s-log-custom-sd89ehdq projectName: "" # Project所属地域,例如上海:cn-shanghai region: "" # Project所属主账号uid,请用引号包围,例如"123456789" aliUid: "" # 使用网络,可选参数:公网Internet,内网Intranet,默认使用公网 net: Internet # 主账号或者子账号的AK,SK,需具备AliyunLogFullAccess系统策略权限 accessKeyID: "" accessKeySecret: "" # 自定义集群ID,命名只支持大小写,数字,短划线(-)。 clusterID: ""在
loongcollector-custom-k8s-package目录,执行如下命令,安装LoongCollector及其他依赖组件:bash k8s-custom-install.sh install安装完成后,查看组件运行状态。
若Pod未成功启动,请确认values.yaml配置是否正确,相关镜像拉取是否成功。
# 检查Pod状态 kubectl get po -n kube-system | grep loongcollector-ds同时,日志服务会自动创建如下资源,可登录日志服务控制台查看。
资源类型
资源名称
作用
Project
values.yaml文件中自定义的
projectName的值资源管理单元,隔离不同业务日志。
如需自行创建Project以实现更灵活的日志资源管理,请参考创建Project。
机器组
k8s-group-${cluster_id}日志采集节点集合。
Logstore
config-operation-log重要请不要删除该Logstore。
用于存储loongcollector-operator组件的日志,其收费标准与普通Logstore完全相同,具体请参见按写入数据量计费模式计费项。建议不要在此Logstore下创建采集配置。
步骤二:创建Logstore
Logstore是日志服务的存储单元,用于存储采集到的日志。
登录日志服务控制台,单击目标Project名称。
在左侧导航栏,选择
 ,单击+,创建Logstore:
,单击+,创建Logstore:Logstore名称:设置一个在Project内唯一的名称。该名称创建后不可修改。
Logstore类型:根据规格对比选择标准型或查询型。
计费模式:
按使用功能计费:按存储、索引、读写次数等各项资源独立计费。适合小规模或功能使用不确定的场景。
按写入数据量计费:仅按原始写入数据量计费,提供30天免费存储,以及免费的数据加工、投递等功能。适合存储周期接近30天或数据处理链路复杂的业务场景。
数据保存时间:设置日志的保留天数(1~3650天,3650为永久保存),默认为30天。
其他配置保持默认,单击确定。如需了解其他配置信息,请参考管理Logstore。
步骤三:创建并配置日志采集规则
定义 LoongCollector 采集哪些日志、如何解析日志结构、如何过滤内容,并将配置绑定到已注册的机器组。
在
 日志库页面,单击目标Logstore名称前的
日志库页面,单击目标Logstore名称前的 展开。
展开。单击数据接入后的
 ,在快速数据接入弹框中,根据日志源选择接入模板,并单击立即接入:
,在快速数据接入弹框中,根据日志源选择接入模板,并单击立即接入:容器标准输出:选择K8s-标准输出-新版
容器标准输出采集支持新版与旧版两种模板,推荐使用新版。如需了解新、旧版本差异,请参考附录:容器标准输出新旧版本对比。
集群文本日志:选择Kubernetes-文件
机器组配置,完成后单击下一步:
使用场景:选择K8s场景。
部署方式:选择ACK Daemonset或自建集群Daemonset。
在源机器组中将系统默认创建的机器组
k8s-group-${cluster_id}添加至右侧应用机器组。
在Logtail配置页面,完成如下配置,并单击下一步。
1. 全局与输入配置
配置前,请确保已完成数据接入模板选择和机器组绑定。本步骤用于定义采集配置的名称、日志来源及采集范围。
采集容器标准输出
全局配置
配置名称:自定义采集配置名称,在其所属Project内必须唯一。创建成功后,无法修改。命名规则:
仅支持小写字母、数字、连字符(-)和下划线(_)。
必须以小写字母或者数字作为开头和结尾。
输入配置
选择开启标准输出或标准错误开关(默认全部开启)。
重要建议不要同时开启标准输出和标准错误,可能会导致采集日志出现混乱。
采集集群文本日志
全局配置:
配置名称:自定义采集配置名称,在其所属Project内必须唯一。创建成功后,无法修改。命名规则:
仅支持小写字母、数字、连字符(-)和下划线(_)。
必须以小写字母或者数字作为开头和结尾。
输入配置:
文件路径类型:
容器内路径:采集容器内的日志文件。
宿主机路径:采集宿主机本地服务日志。
文件路径:日志采集的绝对路径。
Linux:以“/”开头,如
/data/mylogs/**/*.log,表示/data/mylogs目录下所有后缀名为.Log的文件。Windows:以盘符开头,如
C:\Program Files\Intel\**\*.Log。
最大目录监控深度:文件路径中通配符
**匹配的最大目录深度。默认为0(仅本层),取值范围是0~1000。建议设置为0,配置路径到文件所在的目录。
2. 日志处理与结构化
配置日志处理规则可将原始非结构化日志转换为结构化、可检索的数据,提升日志查询与分析效率。建议在配置前先添加日志样例:
在Logtail配置页面的处理配置区域,单击添加日志样例,输入待采集的日志内容。系统将基于样例识别日志格式,辅助生成正则表达式和解析规则,降低配置难度。
场景一:多行日志处理(如Java堆栈日志)
由于Java异常堆栈、JSON等日志通常跨越多行,在默认采集模式下会被拆分为多条不完整的记录,导致上下文信息丢失;为此,可启用多行采集模式,通过配置行首正则表达式,将同一日志的连续多行内容合并为一条完整日志。
效果示例:
未经任何处理的原始日志 | 默认采集模式下,每行作为独立日志,堆栈信息被拆散,丢失上下文 | 开启多行模式,通过行首正则表达式识别完整日志,保留完整语义结构。 |
|
|
|



配置步骤:在Logtail配置页面的处理配置区域,开启多行模式:
类型:选择自定义或多行JSON。
自定义:原始日志的格式不固定,需配置行首正则表达式,来标识每条日志的起始行。
行首正则表达式:支持自动生成或手动输入,正则表达式需要能够匹配完整的一行数据,如上述示例中匹配的正则表达式为
\[\d+-\d+-\w+:\d+:\d+,\d+]\s\[\w+]\s.*。自动生成:单击自动生成正则表达式,然后在日志样例文本框中,选择需提取的日志内容,单击生成正则。
手动输入:单击手动输入正则表达式,输入完成后,单击验证。
多行JSON:当原始日志均为标准JSON格式时选,日志服务会自动处理单条JSON日志内部的换行。
切分失败处理方式:
丢弃:如果一段文本无法匹配行首规则,则直接丢弃。
保留单行:将无法匹配的文本按原始的单行模式进行切分和保留。
场景二:结构化日志
当原始日志为非结构化或半结构化文本(如 Nginx 访问日志、应用输出日志)时,直接进行查询和分析往往效率低下。日志服务提供多种数据解析插件,能够自动将不同格式的原始日志转换为结构化数据,为后续的分析、监控和告警提供坚实的数据基础。
效果示例:
未经任何处理的原始日志 | 结构化解析后的日志 |
| |
配置步骤:在Logtail配置页面的处理配置区域
添加解析插件:单击添加处理插件,根据实际格式配置正则解析、分隔符解析、JSON 解析等插件。此处以采集NGINX日志为例,选择。
NGINX日志配置:将 Nginx 服务器配置文件(nginx.conf)中的
log_format定义完整地复制并粘贴到此文本框中。示例:
log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$request_time $request_length ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent"';重要此处的格式定义必须与服务器上生成日志的格式完全一致,否则将导致日志解析失败。
通用配置参数说明:以下参数在多种数据解析插件中都会出现,其功能和用法是统一的。
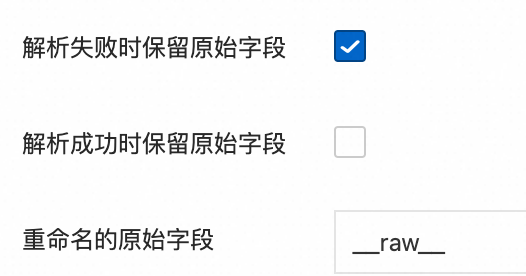
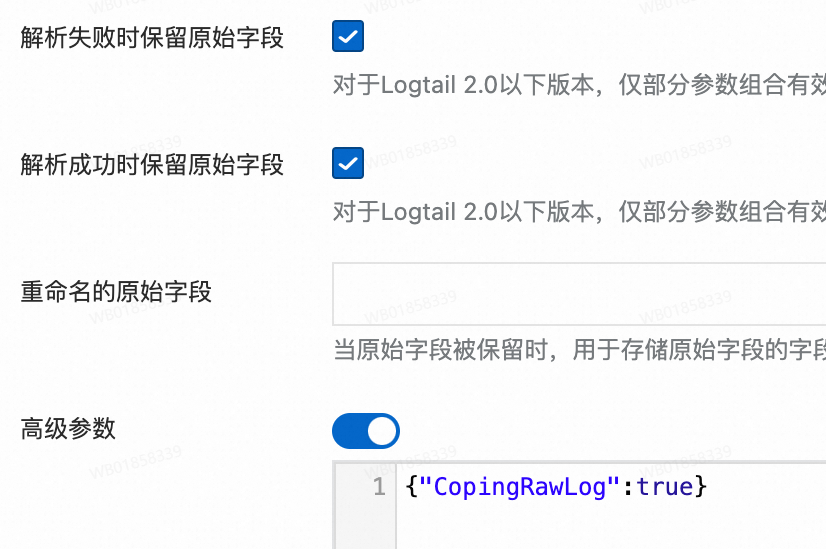
原始字段:指定要解析的源字段名。默认为
content,即采集到的整条日志内容。解析失败时保留原始字段:推荐开启。当日志无法被插件成功解析时(例如格式不匹配),此选项能确保原始日志内容不会丢失,而是被完整保留在指定的原始字段中。
解析成功时保留原始字段:选中后,即使日志解析成功,原始日志内容也会被保留。
3. 日志过滤
在日志采集过程中,大量低价值或无关日志(如 DEBUG/INFO 级别日志)的无差别收集,不仅造成存储资源浪费、增加成本,还影响查询效率并带来数据泄露风险。为此,可通过精细化过滤策略实现高效、安全的日志采集。
通过内容过滤降低成本
基于日志内容的字段过滤(如仅采集 level 为 WARNING 或 ERROR 的日志)。
效果示例:
未经任何处理的原始日志 | 只采集 |
| |
配置步骤:在Logtail配置页面的处理配置区域
单击添加处理插件,选择:
字段名:过滤的日志字段。
字段值:用于过滤的正则表达式,仅支持全文匹配,不支持关键词部分匹配。
通过黑名单控制采集范围
通过黑名单机制排除指定目录或文件,避免无关或敏感日志被上传。
配置步骤:在Logtail配置页面的区域,启用采集黑名单,并单击添加。
支持完整匹配和通配符匹配目录和文件名,通配符只支持星号(*)和半角问号(?)。
文件路径黑名单:需要忽略的文件路径,示例:
/home/admin/private*.log:在采集时忽略/home/admin/目录下所有以private开头,以.log结尾的文件。/home/admin/private*/*_inner.log:在采集时忽略/home/admin/目录下以private开头的目录内,以_inner.log结尾的文件。
文件黑名单:配置采集时需要忽略的文件名,示例:
app_inner.log:在采集时忽略所有名为app_inner.log的文件。
目录黑名单:目录路径不能以正斜线(/)结尾,示例:
/home/admin/dir1/:目录黑名单不会生效。/home/admin/dir*:在采集时忽略/home/admin/目录下所有以dir开头的子目录下的文件。/home/admin/*/dir:在采集时忽略/home/admin/目录下二级目录名为dir的子目录下的所有文件。例如/home/admin/a/dir目录下的文件被忽略,/home/admin/a/b/dir目录下的文件被采集。
容器过滤
基于容器元信息(如环境变量、Pod 标签、命名空间、容器名称等)设置采集条件,精准控制采集哪些容器的日志。
配置步骤:在Logtail配置页面的输入配置区域,启用容器过滤,并单击添加
多个条件之间为“且”的关系,所有正则匹配均基于 Go 语言的 RE2 正则引擎,功能较 PCRE 等引擎有所限制,请遵循附录:正则表达式使用限制(容器过滤)编写正则表达式。
环境变量黑/白名单:指定待采集容器的环境变量条件。
K8s Pod标签黑/白名单:指定待采集容器所在Pod 的标签条件。
K8s Pod 名称正则匹配:通过Pod名称指定待采集的容器
K8s Namespace 正则匹配:通过Namespace名称指定待采集的容器。
K8s 容器名称正则匹配:通过容器名称指定待采集的容器。
容器label黑/白名单:采集容器标签符合条件的容器,Docker场景使用,K8s场景不推荐使用。
4. 日志分类
在多应用、多实例共用相同日志格式的场景下,日志来源难以区分,导致查询时上下文缺失、分析效率低下。为此,可通过配置日志主题(Topic)和日志打标实现自动化的上下文关联与逻辑分类。
配置日志主题(Topic)
当多个应用或实例的日志格式相同但路径不同时(如 /apps/app-A/run.log 和 /apps/app-B/run.log),采集日志难以区分来源。此时可基于机器组、自定义名称或文件路径提取方式生成 Topic,灵活区分不同业务或路径来源的日志。
配置步骤::选择Topic生成方式,支持如下三种类型:
机器组Topic:将采集配置应用于多个机器组时,LoongCollector 会自动使用服务器所属的机器组名称作为
__topic__字段上传。适用于按主机集群划分日志场景。自定义:格式为
customized://<自定义主题名>,例如customized://app-login。适用于固定业务标识的静态主题场景。文件路径提取:从日志文件的完整路径中提取关键信息,动态标记日志来源。适用于多用户/应用共用相同日志文件名但路径不同的情况。
当多个用户或服务将日志写入不同顶级目录,但下级路径和文件名一致时,仅靠文件名无法区分来源,例如:
/data/logs ├── userA │ └── serviceA │ └── service.log ├── userB │ └── serviceA │ └── service.log └── userC └── serviceA └── service.log此时您可以配置文件路径提取,并使用正则表达式从完整路径中提取关键信息,并将匹配结果作为日志主题(Topic)上传至Logstore。
提取规则:基于正则表达式的捕获组
在配置正则表达式时,系统根据捕获组的数量和命名方式自动决定输出字段格式,规则如下:
文件路径的正则表达式中,需要对正斜线(/)进行转义。
捕获组类型
适用场景
生成字段
正则示例
匹配路径示例
生成字段
单捕获组(仅一个
(.*?))仅需一个维度区分来源(如用户名、环境)
生成
__topic__字段\/logs\/(.*?)\/app\.log/logs/userA/app.log__topic__:userA多捕获组-非命名(多个
(.*?))需要多个维度但无需语义标签
生成tag字段
__tag__:__topic_{i}__,其中{i}为捕获组的序号\/logs\/(.*?)\/(.*?)\/app\.log/logs/userA/svcA/app.log__tag__:__topic_1__userA;__tag__:__topic_2__svcA多捕获组-命名(使用
(?P<name>.*?)需多维且希望字段含义清晰、便于查询与分析
生成tag字段
__tag__:{name}\/logs\/(?P<user>.*?)\/(?P<service>.*?)\/app\.log/logs/userA/svcA/app.log__tag__:user:userA;__tag__:service:svcA
日志打标
启用日志标签富化功能,从容器环境变量或 Kubernetes Pod 标签中提取关键信息并附加为 tag,实现日志的精细化分组。
配置步骤:在Logtail配置页面的输入配置区域,启用日志标签富化,并单击添加。
环境变量相关:配置环境变量名和tag名,环境变量值将存放在tag名中。
环境变量名:指定需要提取的环境变量名称。
tag名:环境变量标签名称。
Pod标签相关:配置Pod标签名和tag名,Pod标签值将存放在tag名中。
Pod标签名:需要提取的 Kubernetes Pod 标签名称。
tag名:标签名称。
步骤四:查询与分析配置
在完成日志处理与插件配置后,单击下一步,进入查询分析配置页面:
配置完成后,单击下一步,完成整个采集流程的设置。
步骤五:验证与故障排查
完成采集配置并应用到机器组后,系统将自动下发配置并开始采集增量日志。
查看上报日志
确认日志文件有新增内容:LoongCollector只采集增量日志。执行
tail -f /path/to/your/log/file,并触发业务操作,确保有新的日志正在写入。查询日志:进入目标 Logstore 的查询分析页面,单击查询/分析(默认时间范围为最近15分钟),观察是否有新日志流入。采集的每条容器文本日志中默认包含以下字段信息:
字段名称
说明
__tag__:__hostname__
容器宿主机的名称。
__tag__:__path__
容器内日志文件的路径。
__tag__:_container_ip_
容器的IP地址。
__tag__:_image_name_
容器使用的镜像名称。
__tag__:_pod_name_
Pod的名称。
__tag__:_namespace_
Pod所属的命名空间。
__tag__:_pod_uid_
Pod的唯一标识符(UID)。
常见问题排查
机器组心跳连接为fail
检查用户标识:如果您的服务器类型不是ECS,或使用的ECS和Project属于不同阿里云账号,请根据如下表格检查指定目录下是否存在正确的用户标识。
Linux:执行
cd /etc/ilogtail/users/ && touch <uid>命令,创建用户标识文件。Windows:进入
C:\LogtailData\users\目录,创建一个名为<uid>的空文件。
如果指定路径下存在以当前Project所属的阿里云账号ID命名的文件,则说明用户标识配置正确。
检查机器组标识:如果您使用了用户自定义标识机器组,请检查指定目录下是否存在
user_defined_id文件,如果存在请检查该文件中的内容是否与机器组配置的自定义标识一致。Linux:
# 配置用户自定义标识,如目录不存在请手动创建 echo "user-defined-1" > /etc/ilogtail/user_defined_idWindows:在
C:\LogtailData目录下新建user_defined_id文件,并写入用户自定义标识。(如目录不存在,请手动创建)
如果用户标识和机器组标识均配置无误,请参考LoongCollector(Logtail)机器组问题排查思路进一步排查。
采集日志报错或格式错误
排查思路:这种情况说明网络连接和基础配置正常,问题主要出在日志内容与解析规则不匹配。您需要查看具体的错误信息来定位问题:
在Logtail配置页面,单击采集异常的LoongCollector(Logtail)配置名称,在日志采集错误页签下,单击时间选择设置查询时间。
在区域,查看错误日志的告警类型,并根据采集数据常见错误类型查询对应的解决办法。
后续步骤
日志查询与分析:可以使用内置的通过AI智能生成查询与分析语句(Copilot),自动生成查询分析语句。
数据可视化:借助可视化仪表盘监控关键指标趋势。
数据异常自动预警:设置告警策略,实时感知系统的异常情况。
容器日志采集无数据排查思路
检查是否有增量日志:配置LoongCollector(Logtail)采集后,如果待采集的日志文件没有新增日志,则LoongCollector(Logtail)不会采集该文件。
检查机器组心跳状态:前往![]() 资源 > 机器组页面,单击目标机器组名称,在区域,查看心跳状态并记录心跳状态为ok的节点数。
资源 > 机器组页面,单击目标机器组名称,在区域,查看心跳状态并记录心跳状态为ok的节点数。
检查容器集群中Worker节点数。
查看集群中Worker节点数。
kubectl get node | grep -v master系统会返回如下类似结果。
NAME STATUS ROLES AGE VERSION cn-hangzhou.i-bp17enxc2us3624wexh2 Ready <none> 238d v1.10.4 cn-hangzhou.i-bp1ad2b02jtqd1shi2ut Ready <none> 220d v1.10.4
对比心跳状态为OK的节点数是否和容器集群中Worker节点数一致。根据对比结果选择排查方式。
机器组中所有节点的心跳状态均为Failed:
如果是自建集群,请检查以下参数是否配置正确:
{regionId}、{aliuid}、{access-key-id}和{access-key-secret}是否已正确填写。如果填写错误,请执行
helm del --purge alibaba-log-controller命令,删除安装包,然后重新安装。
机器组心跳状态为OK的节点数量少于集群中的Worker节点数量。
判断是否已使用YAML文件手动部署DaemonSet。
执行如下命令。如果存在返回结果,则表示之前已使用YAML文件手动部署DaemonSet。
kubectl get po -n kube-system -l k8s-app=logtail根据实际值,配置${your_region_name}、${your_aliyun_user_id}、${your_machine_group_name}等参数。
更新资源。
kubectl apply -f ./logtail-daemonset.yaml
常见问题
如何将ACK集群日志传输到另一个阿里云账号的Project?
通过在ACK集群中手动安装日志服务 LoongCollector(Logtail) 组件,并为其配置目标账号的主账号ID或访问凭证(AccessKey),即可实现将容器日志发送到另一个阿里云账号的日志服务Project中。
场景描述:当因为组织架构、权限隔离或统一监控等原因,需要将某个ACK集群的日志数据采集到另一个独立的阿里云账号的日志服务Project时,可通过手动安装 LoongCollector(Logtail)进行跨账号配置。
操作步骤:此处以手动安装LoongCollector为例,如需了解如何安装Logtail,请参考Logtail安装与配置。
连接Kubernetes集群,根据集群所在地域执行对应命令:
中国地域
wget https://aliyun-observability-release-cn-shanghai.oss-cn-shanghai.aliyuncs.com/loongcollector/k8s-custom-pkg/3.0.12/loongcollector-custom-k8s-package.tgz; tar xvf loongcollector-custom-k8s-package.tgz; chmod 744 ./loongcollector-custom-k8s-package/k8s-custom-install.sh海外地域
wget https://aliyun-observability-release-ap-southeast-1.oss-ap-southeast-1.aliyuncs.com/loongcollector/k8s-custom-pkg/3.0.12/loongcollector-custom-k8s-package.tgz; tar xvf loongcollector-custom-k8s-package.tgz; chmod 744 ./loongcollector-custom-k8s-package/k8s-custom-install.sh进入
loongcollector-custom-k8s-package目录,修改配置文件./loongcollector/values.yaml。# ===================== 必需要补充的内容 ===================== # 本集群要采集的Project名,例如 k8s-log-custom-sd89ehdq projectName: "" # Project所属地域,例如上海:cn-shanghai region: "" # Project所属主账号uid,请用引号包围,例如"123456789" aliUid: "" # 使用网络,可选参数:公网Internet,内网Intranet,默认使用公网 net: Internet # 主账号或者子账号的AK,SK,需具备AliyunLogFullAccess系统策略权限 accessKeyID: "" accessKeySecret: "" # 自定义集群ID,命名只支持大小写,数字,短划线(-)。 clusterID: ""在
loongcollector-custom-k8s-package目录,执行如下命令,安装LoongCollector及其他依赖组件:bash k8s-custom-install.sh install安装完成后,查看组件运行状态。
若Pod未成功启动,请确认values.yaml配置是否正确,相关镜像拉取是否成功。
# 检查Pod状态 kubectl get po -n kube-system | grep loongcollector-ds同时,日志服务会自动创建如下资源,可登录日志服务控制台查看。
资源类型
资源名称
作用
Project
values.yaml文件中自定义的
projectName的值资源管理单元,隔离不同业务日志。
如需自行创建Project以实现更灵活的日志资源管理,请参考创建Project。
机器组
k8s-group-${cluster_id}日志采集节点集合。
Logstore
config-operation-log重要请不要删除该Logstore。
用于存储loongcollector-operator组件的日志,其收费标准与普通Logstore完全相同,具体请参见按写入数据量计费模式计费项。建议不要在此Logstore下创建采集配置。
如何让同一个日志文件或容器标准输出被多个采集配置同时采集?
默认情况下,日志服务为了防止数据重复,限制了每个日志源只能被一个采集配置采集:
一个 文本日志文件只能匹配一个 Logtail 采集配置;
一个容器的标准输出(stdout):
如果使用的是标准输出-新版模板, 默认只能被一个标准输出采集配置采集。
如果使用的是标准输出-旧版模板,无需额外配置,默认支持采集多份。
登录日志服务控制台,进入目标Project。
在左侧导航栏选择
日志库,找到目标Logstore。单击其名称前的
展开Logstore。单击Logtail配置,在配置列表中,找到目标Logtail配置,单击操作列的管理Logtail配置。
在Logtail配置页面,单击编辑,下滑至输入配置区域:
采集文本文件日志:开启允许文件多次采集。
采集容器标准输出:开启允许标准输出多次采集。
卸载 ACK 中的 loongcollector(logtail-ds) 组件时提示依赖错误
问题现象:在阿里云容器服务(ACK)中尝试删除loongcollector(logtail-ds) 日志采集组件时,系统报错:该组件的依赖不满足
Dependencies of addons are not met: terway-eniip depends on logtail-ds(>0.0) whose version is v3.x.x.x-aliyun or will be v3.x.x.x-aliyun。
问题原因:terway-eniip 网络插件启用了日志采集功能,其依赖于loongcollector(logtail-ds)组件。因此,在未解除该依赖关系前,ACK 不允许直接卸载loongcollector(logtail-ds)。
解决方案:请按以下步骤操作,先解除依赖再卸载组件:
登录容器服务管理控制台。;
在集群列表中,单击目标集群名称,进入集群详情页面。
在左侧导航栏,单击组件管理。
在组件列表中,搜索并找到
terway-eniip组件,单击 > 关闭日志。
> 关闭日志。在弹出的对话框中,单击确认。
待配置生效后,重新尝试卸载loongcollector(logtail-ds)组件。
为什么最后一段日志延迟很久才上报?有时还会被截断?
原因分析:日志被截断通常发生在日志文件末尾缺少换行符,或多行日志(如异常堆栈)尚未完整写入时。由于采集器无法判断日志是否已结束,可能导致最后一段内容被提前切分或延迟上报。不同版本的LoongCollector(Logtail)处理机制有差异:
1.8 之前版本:
如果最后一行日志没有换行符(回车),或者一个多行日志段落未结束,采集器会一直等待下一次写入触发输出。这可能导致最后一条日志长时间滞留不发送,直到新日志写入。1.8 及之后版本:
引入超时刷新机制,避免日志卡住。当检测到未完成的日志行时,系统启动计时器,超时后自动提交当前内容,确保日志最终能被采集。默认超时时间:60 秒(保证大多数场景下的完整性)
您可根据实际需求调整该值,但不建议设为 0,否则可能导致日志截断或丢失部分内容。
解决方案:
您可以适当延长等待时间,确保完整日志写入后再被采集:
登录日志服务控制台,进入目标Project。
在左侧导航栏选择
 日志库,找到目标Logstore。
日志库,找到目标Logstore。单击其名称前的
 展开Logstore。
展开Logstore。单击Logtail配置,在配置列表中,找到目标Logtail配置,单击操作列的管理Logtail配置。
在Logtail配置页面,单击编辑:
:添加以下JSON配置自定义超时时间
{ "FlushTimeoutSecs": 1 }默认值:由启动参数
default_reader_flush_timeout决定(通常为几秒)。单位:秒。
建议值:≥1 秒,不建议设为 0,否则可能导致日志截断或丢失部分内容。
配置完成后,单击保存。
为什么LoongCollector(Logtail)在运行过程中会从内网域名切换到公网?能否自动切回?
LoongCollector(Logtail)运行过程中,若检测到内网域名通信异常(如网络不通、连接超时等),为保障日志采集的连续性和可靠性,系统会自动切换至公网域名进行数据发送,避免日志堆积或丢失。
LoongCollector:内网恢复后,自动切回内网。
Logtail:不会自动切回,需手动重启才能恢复内网通信。
附录:原生插件详解
在Logtail配置页面的处理配置区域,可以通过添加处理插件,对原始日志进行结构化处理。如需为已有采集配置添加处理插件,可以参考如下步骤:
在左侧导航栏选择
 日志库,找到目标Logstore。
日志库,找到目标Logstore。单击其名称前的
 展开Logstore。
展开Logstore。单击Logtail配置,在配置列表中,找到目标Logtail配置,单击操作列的管理Logtail配置。
在Logtail配置页面,单击编辑。
此处仅介绍常用处理插件,覆盖常见日志处理场景,如需更多功能,请参考拓展处理插件。
插件组合使用规则(适用于 LoongCollector / Logtail 2.0 及以上版本):
原生处理插件与拓展处理插件均可独立使用,也支持按需组合使用。
推荐优先选用原生处理插件,因其具备更优的性能和更高的稳定性。
当原生功能无法满足业务需求时,可在已配置的原生处理插件之后,追加配置拓展处理插件以实现补充处理。
顺序约束:
所有插件按照配置顺序组成处理链,依次执行。需要注意:所有原生处理插件必须先于任何拓展处理插件,添加任意拓展处理插件后,将无法继续添加原生处理插件。
正则解析
通过正则表达式提取日志字段,并将日志解析为键值对形式,每个字段都可以被独立查询和分析。
效果示例:
未经任何处理的原始日志 | 使用正则解析插件 |
| |
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
正则表达式:用于匹配日志,支持自动生成或手动输入:
自动生成:
单击自动生成正则表达式。
在日志样例中划选需要提取的日志内容。
单击生成正则。

手动输入:根据日志格式手动输入正则表达式。
配置完成后,单击验证,测试正则表达式是否能够正确解析日志内容。
日志提取字段:为提取的日志内容(Value),设置对应的字段名(Key)。
其他参数请参考场景二:结构化日志中的通用配置参数说明。
分隔符解析
通过分隔符将日志内容结构化,解析为多个键值对形式,支持单字符分隔符和多字符分隔符。
效果示例:
未经任何处理的原始日志 | 按指定字符 |
| |
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
分隔符:指定用于切分日志内容的字符。
示例:对于CSV格式文件,选择自定义,输入半角逗号(,)。
引用符:当某个字段值中包含分隔符时,需要指定引用符包裹该字段,避免错误切割。
日志提取字段:按分隔顺序依次为每一列设置对应的字段名称(Key)。规则要求如下:
字段名只能包含:字母、数字、下划线(_)。
必须以字母或下划线(_)开头。
最大长度:128字节。
其他参数请参考场景二:结构化日志中的通用配置参数说明。
标准JSON解析
将Object类型的JSON日志结构化,解析为键值对形式。
效果示例:
未经任何处理的原始日志 | 标准JSON键值自动提取 |
| |
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
原始字段:默认值为content(此字段用于存放待解析的原始日志内容)。
其他参数请参考场景二:结构化日志中的通用配置参数说明。
嵌套JSON解析
通过指定展开深度,将嵌套的JSON日志解析为键值对形式。
效果示例:
未经任何处理的原始日志 | 展开深度:0,并使用展开深度作为前缀 | 展开深度:1,并使用展开深度作为前缀 |
| | |
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
原始字段:需要展开的原始字段名,例如
content。JSON展开深度:JSON对象的展开层级。0表示完全展开(默认值),1表示当前层级,以此类推。
JSON展开连接符:JSON展开时字段名的连接符,默认为下划线 _。
JSON展开字段前缀:指定JSON展开后字段名的前缀。
展开数组:开启此项可将数组展开为带索引的键值对。
示例:
{"k":["a","b"]}展开为{"k[0]":"a","k[1]":"b"}。如果需要对展开后的字段进行重命名(例如,将 prefix_s_key_k1 改为 new_field_name),可以后续再添加一个重命名字段插件来完成映射。
其他参数请参考场景二:结构化日志中的通用配置参数说明。
JSON数组解析
使用json_extract函数,从JSON数组中提取JSON对象。
效果示例:
未经任何处理的原始日志 | 提取JSON数组结构 |
| |
配置步骤:在Logtail配置页面的处理配置区域,将处理模式切换为SPL,配置SPL语句,使用 json_extract函数从JSON数组中提取JSON对象。
示例:从日志字段 content 中提取 JSON 数组中的元素,并将结果分别存储在新字段 json1和 json2 中。
* | extend json1 = json_extract(content, '$[0]'), json2 = json_extract(content, '$[1]')Apache日志解析
根据Apache日志配置文件中的定义将日志内容结构化,解析为多个键值对形式。
效果示例:
未经任何处理的原始日志 | Apache通用日志格式 |
| |
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
日志格式:combined
APACHE配置字段:系统会根据日志格式自动填充配置。
重要请务必核对自动填充的内容,确保与服务器上 Apache 配置文件(通常位于/etc/apache2/apache2.conf)中定义的 LogFormat 完全一致。
其他参数请参考场景二:结构化日志中的通用配置参数说明。
数据脱敏
对日志中的敏感数据进行脱敏处理。
效果示例:
未经任何处理的原始日志 | 脱敏结果 |
| |
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
时间解析
对日志中的时间字段进行解析,并将解析结果设置为日志的__time__字段。
效果示例:
未经任何处理的原始日志 | 时间解析 |
|
|
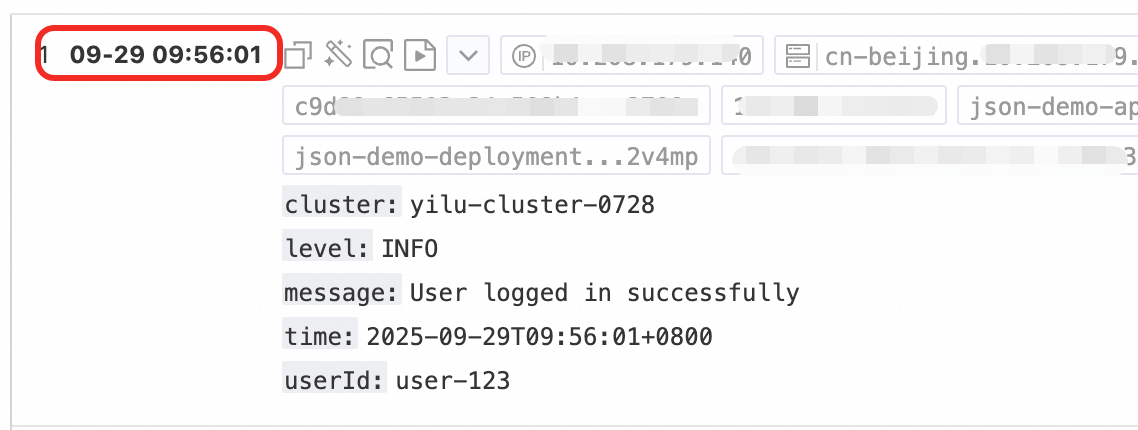
配置步骤:在Logtail配置页面的处理配置区域,单击添加处理插件,选择:
原始字段:解析日志前,用于存放日志内容的原始字段。
时间格式:根据日志中的时间内容设置对应的时间格式。
时区:选择日志时间字段所在的时区。默认使用机器时区,即LoongCollector(Logtail)进程所在环境的时区。
附录:正则表达式使用限制(容器过滤)
容器过滤时所使用的正则表达式基于Go语言的RE2引擎,与PCRE等其他引擎相比存在部分语法限制。请在编写正则表达式时注意以下事项:
1. 命名分组语法差异
Go语言使用 (?P<name>...) 语法定义命名分组,不支持 PCRE中的 (?<name>...) 语法。
正确示例:
(?P<year>\d{4})错误写法:
(?<year>\d{4})
2. 不支持的正则特性
以下常见但复杂的正则功能在RE2中不可用,请避免使用:
断言:
(?=...)、(?!...)、(?<=...)、(?<!...)条件表达式:
(?(condition)true|false)递归匹配:
(?R)、(?0)子程序引用:
(?&name)、(?P>name)原子组:
(?>...)
3. 使用建议
推荐使用 Regex101等工具调试正则表达式时,选择 Golang (RE2) 模式进行验证,以确保兼容性。若使用了上述不支持的语法,插件将无法正确解析或匹配。
附录:容器标准输出新旧版本对比
为提升日志存储效率与采集一致性,容器标准输出的日志元信息格式已完成升级。新版格式将元信息统一归类至 __tag__ 字段中,实现存储优化和格式标准化。
新版标准输出核心优势
性能大幅提升
采用C++重构,相较旧版Go实现,性能提升180%-300%。
支持原生插件处理数据,支持多线程并行处理,充分利用系统资源。
支持原生插件与Go插件灵活组合使用,满足复杂场景需求。
更强的可靠性
支持标准输出日志轮转队列,日志采集机制和文件采集机制统一,在标准输出日志快速轮转时的场景可靠性高。
更低的资源消耗
CPU使用率降低20%-25%。
内存占用减少20%-25%。
运维一致性增强
参数配置统一:新版标准输出采集插件的配置参数和文件采集插件保持一致。
元信息统一管理:容器元信息字段命名和Tag日志存储位置,与文件采集场景进行了统一,消费端只需维护同套处理逻辑。
新旧版本特性对比
特性维度
旧版特点
新版特点
存储方式
元信息作为普通字段直接嵌入日志内容中
元信息集中存放于
__tag__标签中存储效率
每条日志重复携带完整元信息,占用较多存储空间
相同上下文下的多条日志可复用元信息,节省存储成本
格式一致性
与容器文件采集格式不一致
字段命名及存储结构与容器文件采集完全对齐,实现统一体验
查询访问方式
可通过字段名直接查询(如
_container_name_)需通过
__tag__访问对应键值(如__tag__: _container_name_)容器元信息字段映射表
旧版字段名称
新版字段名称
_container_ip_
__tag__:_container_ip_
_container_name_
__tag__:_container_name_
_image_name_
__tag__:_image_name_
_namespace_
__tag__:_namespace_
_pod_name_
__tag__:_pod_name_
_pod_uid_
__tag__:_pod_uid_
所有元信息字段在新版中均以
__tag__:<key>形式存储于日志的标签(Tag)区域,而非嵌入日志内容中。新版变更对用户影响
消费端适配:由于存储位置从“内容”变为“Tag”,用户的日志消费逻辑需做相应调整(例如查询时需通过 __tag__ 访问字段)。
SQL兼容性:查询SQL已经自动兼容适配,因此用户无需修改查询语句即可同时处理新旧版本日志。
更多信息
全局配置参数介绍
输入配置参数介绍
处理配置参数介绍
配置项 | 说明 |
日志样例 | 待采集日志的样例,请务必使用实际场景的日志。日志样例可协助配置日志处理相关参数,降低配置难度。支持添加多条样例,总长度不超过1500个字符。 |
多行模式 |
|
处理模式 | 处理插件组合,包括原生插件和拓展插件。有关处理插件的更多信息,请参见处理插件概述。 重要 处理插件的使用限制,请以控制台页面的提示为准。
|