
通过KServe on ACK Knative可将 AI 模型部署为Serverless推理服务,实现自动弹性、多版本管理、灰度发布等能力。
步骤一:安装并配置KServe组件
为确保KServe能与Knative的ALB网关或Kourier网关无缝集成,需要先安装 KServe 组件,然后修改其默认设置,禁用其内置的 Istio 虚拟服务。
安装KServe组件。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在组件管理页签的add-on 组件区域,定位并部署KServe组件。
禁用 Istio VirtualHost。
编辑
inferenceservice-configConfigMap,将disableIstioVirtualHost设置为true。kubectl get configmap inferenceservice-config -n kserve -o yaml \ | sed 's/"disableIstioVirtualHost": false/"disableIstioVirtualHost": true/g' \ | kubectl apply -f -预期输出:
configmap/inferenceservice-config configured验证配置。
kubectl get configmap inferenceservice-config -n kserve -o yaml \ | grep '"disableIstioVirtualHost":' \ | tail -n1 \ | awk -F':' '{gsub(/[ ,]/,"",$2); print $2}'输出为
true,表明配置已更新。重启 KServe 控制器以应用配置变更。
kubectl rollout restart deployment kserve-controller-manager -n kserve
步骤二:部署InferenceService推理服务
本示例部署了一个基于鸢尾花(Iris)数据集训练的scikit-learn分类模型,将顺序接收花朵的四项尺寸特征值,并预测其所属的具体类别。
输入为按顺序排列的四个数值特征:
| 输出为代表预测类别的索引:
|
创建inferenceservice.yaml,部署推理服务。
apiVersion: "serving.kserve.io/v1beta1" kind: "InferenceService" metadata: name: "sklearn-iris" spec: predictor: model: # 模型的格式,此处为sklearn modelFormat: name: sklearn image: "kube-ai-registry.cn-shanghai.cr.aliyuncs.com/ai-sample/kserve-sklearn-server:v0.12.0" command: - sh - -c - "python -m sklearnserver --model_name=sklearn-iris --model_dir=/models --http_port=8080"部署InferenceService。
kubectl apply -f inferenceservice.yaml查看服务状态。
kubectl get inferenceservices sklearn-iris输出中,
READY列显示True,表明服务状态正常。NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION AGE sklearn-iris http://sklearn-iris-predictor-default.default.example.com True 100 sklearn-iris-predictor-default-00001 51s
步骤三:访问服务
通过集群的入口网关向服务发送推理请求。
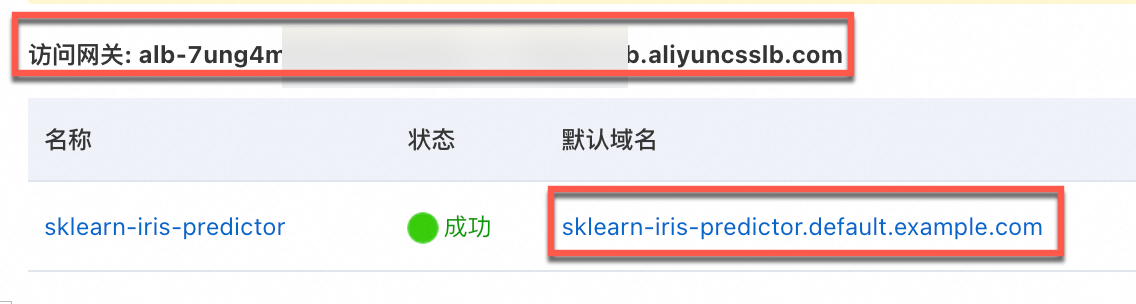
在Knative页面的服务管理页签,获取ALB或Kourier网关的访问网关和服务默认域名,供后续访问服务。
下图以ALB网关为例,Kourier网关界面类似。
准备请求数据。
在本地终端,创建一个名为
./iris-input.json文件,包含两个数组,每个数组为一个待预测样本。cat <<EOF > "./iris-input.json" { "instances": [ [6.8, 2.8, 4.8, 1.4], [6.0, 3.4, 4.5, 1.6] ] } EOF在本地终端发送推理请求,访问服务。
将
${INGRESS_DOMAIN}替换为步骤1获取的访问网关地址。curl -H "Content-Type: application/json" -H "Host: sklearn-iris-predictor.default.example.com" "http://${INGRESS_DOMAIN}/v1/models/sklearn-iris:predict" -d @./iris-input.json输出表示模型对两个输入样本的预测类别索引均为1,即杂色鸢尾 (Iris Versicolour)。
{"predictions":[1,1]}
计费说明
KServe和Knative组件本身不产生额外费用。但在使用过程中产生的计算资源(如ECS、ECI)、网络资源(如ALB、CLB)等费用,由各云产品收取。请参见云产品资源费用。
常见问题
InferenceService状态长时间处于Not Ready,如何排查?
可通过以下步骤排查:
执行
kubectl describe inferenceservice <yourServiceName>查看Event,确认是否存在错误信息。执行
kubectl get pods查看是否有与该服务相关的Pod(通常以服务名开头)处于Error或CrashLoopBackOff状态。如Pod状态异常,通过
kubectl logs <pod-name> -c kserve-container查看模型服务容器的日志,检查模型加载是否失败(例如,网络问题导致模型无法下载、模型文件格式错误等)。
如何部署自己训练的模型?
可将模型文件上传到OSS Bucket,在创建InferenceService时,将spec.predictor.model.storageUri字段的值替换为模型文件所在的URI。同时,根据模型框架,正确设置modelFormat(例如 tensorflow、pytorch、onnx 等)。
如何为模型服务配置GPU资源?
如果模型需要GPU进行推理,可以在InferenceService的YAML文件中为predictor添加resources字段来申请GPU资源。示例如下。
关于如何在Knative中使用GPU资源,请参见使用GPU资源。
spec:
predictor:
resources:
requests:
nvidia.com/gpu: "1"
limits:
nvidia.com/gpu: "1"相关文档
如需在Knative中部署AI模型推理服务,可参见在Knative中部署AI模型推理服务的最佳实践获得配置建议。
ACK Knative提供Stable Diffusion的应用模板,请参见基于Knative部署生产级别的Stable Diffusion服务。