
ACK基于Scheduling Framework机制,实现GPU拓扑感知调度,即在节点的GPU组合中选择具有最优训练速度的组合。本文介绍如何使用GPU拓扑感知调度来提升PyTorch分布式训练的训练速度。
前提条件
已创建ACK Pro集群,且集群的实例规格类型选择为GPU云服务器。更多信息,请参见创建Kubernetes托管版集群。
已安装Arena。
系统组件版本满足以下要求。
组件
版本要求
Kubernetes
1.18.8及以上版本
Nvidia
418.87.01及以上版本
训练框架NCCL版本
2.7+
操作系统
CentOS 7.6
CentOS 7.7
Ubuntu 16.04
Ubuntu 18.04
Alibaba Cloud Linux 2
Alibaba Cloud Linux 3
显卡
V100
注意事项
仅支持MPI作业的分布式训练。
只有当提交作业的所有Pod对资源请求都满足条件时,才能创建Pod并启动作业,否则请求会处于资源等待状态。
操作步骤
节点配置
您需执行以下命令,设置节点Label,显式激活节点GPU拓扑感知调度。
kubectl label node <Your Node Name> ack.node.gpu.schedule=topology当节点激活GPU拓扑感知调度后,不再支持普通GPU资源调度。您可执行以下命令更改Label,恢复普通GPU资源调度功能。
kubectl label node <Your Node Name> ack.node.gpu.schedule=default --overwrite提交作业
您在提交MPI作业时,执行以下命令设置--gputopology为true。
arena submit --gputopology=true --gang ***示例一:训练Vgg16
本示例测试集群有2台8卡V100机器。
使用GPU拓扑感知调度训练Vgg16
执行以下命令,向集群提交作业。
arena submit mpi \ --name=pytorch-topo-4-vgg16 \ --gpus=1 \ --workers=4 \ --gang \ --gputopology=true \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/pytorch-benchmark:torch1.6.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /examples/pytorch_synthetic_benchmark.py --model=vgg16 --batch-size=64"执行以下命令,查看当前作业运行情况。
arena get pytorch-topo-4-vgg16 --type mpijob预期输出:
Name: pytorch-topo-4-vgg16 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 11s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- pytorch-topo-4-vgg16-launcher-mnjzr Running 11s true 0 cn-shanghai.192.168.16.173 pytorch-topo-4-vgg16-worker-0 Running 11s false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-vgg16-worker-1 Running 11s false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-vgg16-worker-2 Running 11s false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-vgg16-worker-3 Running 11s false 1 cn-shanghai.192.168.16.173执行以下命令,查看当前日志信息。
arena logs -f pytorch-topo-4-vgg16预期输出:
Model: vgg16 Batch size: 64 Number of GPUs: 4 Running warmup... Running benchmark... Iter #0: 205.5 img/sec per GPU Iter #1: 205.2 img/sec per GPU Iter #2: 205.1 img/sec per GPU Iter #3: 205.5 img/sec per GPU Iter #4: 205.1 img/sec per GPU Iter #5: 205.1 img/sec per GPU Iter #6: 205.3 img/sec per GPU Iter #7: 204.3 img/sec per GPU Iter #8: 205.0 img/sec per GPU Iter #9: 204.9 img/sec per GPU Img/sec per GPU: 205.1 +-0.6 Total img/sec on 4 GPU(s): 820.5 +-2.5
使用普通GPU调度训练Vgg16
执行以下命令,向集群提交作业。
arena submit mpi \ --name=pytorch-4-vgg16 \ --gpus=1 \ --workers=4 \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/pytorch-benchmark:torch1.6.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /examples/pytorch_synthetic_benchmark.py --model=vgg16 --batch-size=64"执行以下命令,查看当前作业运行情况。
arena get pytorch-4-vgg16 --type mpijob预期输出:
Name: pytorch-4-vgg16 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 10s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- pytorch-4-vgg16-launcher-qhnxl Running 10s true 0 cn-shanghai.192.168.16.173 pytorch-4-vgg16-worker-0 Running 10s false 1 cn-shanghai.192.168.16.173 pytorch-4-vgg16-worker-1 Running 10s false 1 cn-shanghai.192.168.16.173 pytorch-4-vgg16-worker-2 Running 10s false 1 cn-shanghai.192.168.16.173 pytorch-4-vgg16-worker-3 Running 10s false 1 cn-shanghai.192.168.16.173执行以下命令,查看当前日志信息。
arena logs -f pytorch-4-vgg16预期输出:
Model: vgg16 Batch size: 64 Number of GPUs: 4 Running warmup... Running benchmark... Iter #0: 113.1 img/sec per GPU Iter #1: 109.5 img/sec per GPU Iter #2: 106.5 img/sec per GPU Iter #3: 108.5 img/sec per GPU Iter #4: 108.1 img/sec per GPU Iter #5: 111.2 img/sec per GPU Iter #6: 110.7 img/sec per GPU Iter #7: 109.8 img/sec per GPU Iter #8: 102.8 img/sec per GPU Iter #9: 107.9 img/sec per GPU Img/sec per GPU: 108.8 +-5.3 Total img/sec on 4 GPU(s): 435.2 +-21.1
示例二:训练Resnet50
使用GPU拓扑感知调度训练Resnet50
执行以下命令,向集群提交作业。
arena submit mpi \ --name=pytorch-topo-4-resnet50 \ --gpus=1 \ --workers=4 \ --gang \ --gputopology=true \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/pytorch-benchmark:torch1.6.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /examples/pytorch_synthetic_benchmark.py --model=resnet50 --batch-size=64"执行以下命令,查看当前作业运行情况。
arena get pytorch-topo-4-resnet50 --type mpijob预期输出:
Name: pytorch-topo-4-resnet50 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 8s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- pytorch-topo-4-resnet50-launcher-x7r2n Running 8s true 0 cn-shanghai.192.168.16.173 pytorch-topo-4-resnet50-worker-0 Running 8s false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-resnet50-worker-1 Running 8s false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-resnet50-worker-2 Running 8s false 1 cn-shanghai.192.168.16.173 pytorch-topo-4-resnet50-worker-3 Running 8s false 1 cn-shanghai.192.168.16.173执行以下命令,查看当前日志信息。
arena logs -f pytorch-topo-4-resnet50预期输出:
Model: resnet50 Batch size: 64 Number of GPUs: 4 Running warmup... Running benchmark... Iter #0: 331.0 img/sec per GPU Iter #1: 330.6 img/sec per GPU Iter #2: 330.9 img/sec per GPU Iter #3: 330.4 img/sec per GPU Iter #4: 330.7 img/sec per GPU Iter #5: 330.8 img/sec per GPU Iter #6: 329.9 img/sec per GPU Iter #7: 330.5 img/sec per GPU Iter #8: 330.4 img/sec per GPU Iter #9: 329.7 img/sec per GPU Img/sec per GPU: 330.5 +-0.8 Total img/sec on 4 GPU(s): 1321.9 +-3.2
使用普通GPU调度训练Resnet50
执行以下命令,向集群提交作业。
arena submit mpi \ --name=pytorch-4-resnet50 \ --gpus=1 \ --workers=4 \ --image=registry.cn-hangzhou.aliyuncs.com/kubernetes-image-hub/pytorch-benchmark:torch1.6.0-py3.7-cuda10.1 \ "mpirun --allow-run-as-root -np "4" -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=eth0 -x LD_LIBRARY_PATH -x PATH --mca pml ob1 --mca btl_tcp_if_include eth0 --mca oob_tcp_if_include eth0 --mca orte_keep_fqdn_hostnames t --mca btl ^openib python /examples/pytorch_synthetic_benchmark.py --model=resnet50 --batch-size=64"执行以下命令,查看当前作业运行情况。
arena get pytorch-4-resnet50 --type mpijob预期输出:
Name: pytorch-4-resnet50 Status: RUNNING Namespace: default Priority: N/A Trainer: MPIJOB Duration: 10s Instances: NAME STATUS AGE IS_CHIEF GPU(Requested) NODE ---- ------ --- -------- -------------- ---- pytorch-4-resnet50-launcher-qw5k6 Running 10s true 0 cn-shanghai.192.168.16.173 pytorch-4-resnet50-worker-0 Running 10s false 1 cn-shanghai.192.168.16.173 pytorch-4-resnet50-worker-1 Running 10s false 1 cn-shanghai.192.168.16.173 pytorch-4-resnet50-worker-2 Running 10s false 1 cn-shanghai.192.168.16.173 pytorch-4-resnet50-worker-3 Running 10s false 1 cn-shanghai.192.168.16.173执行以下命令,查看当前日志信息。
arena logs -f pytorch-4-resnet50预期输出:
Model: resnet50 Batch size: 64 Number of GPUs: 4 Running warmup... Running benchmark... Iter #0: 313.1 img/sec per GPU Iter #1: 312.8 img/sec per GPU Iter #2: 313.0 img/sec per GPU Iter #3: 312.2 img/sec per GPU Iter #4: 313.7 img/sec per GPU Iter #5: 313.2 img/sec per GPU Iter #6: 313.6 img/sec per GPU Iter #7: 313.0 img/sec per GPU Iter #8: 311.3 img/sec per GPU Iter #9: 313.6 img/sec per GPU Img/sec per GPU: 313.0 +-1.3 Total img/sec on 4 GPU(s): 1251.8 +-5.3
性能对比
基于如上4个测试用例性能对比结果如下: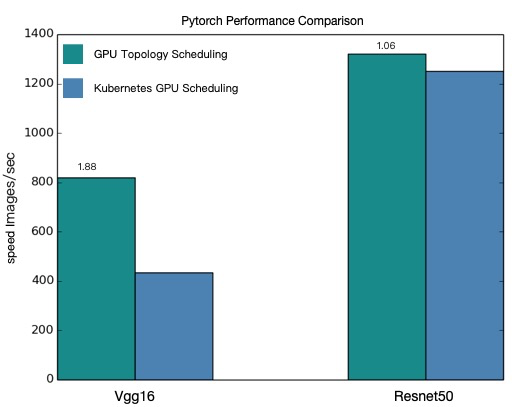
基于上图性能对比,可知经过GPU拓扑感知调度后,PyTorch分布式训练的效果有了很大的提升。
本文提供的性能数据仅为理论值,GPU拓扑感知调度提升结果与您使用的模型以及集群的环境有一定关系,实际数据以您的操作环境为准。您可以参考上述使用示例,评测自己的模型。