通过开启阿里云Prometheus监控,您可以全面监控集群存储资源、节点存储资源、Pod存储资源以及外部存储卷等多个维度的资源,实时查看集群中存储资源的使用情况。本文介绍容器存储的使用和监控方法,以及如何查看各存储类型的监控大盘。
前提条件
集群中已安装CSI组件,并且版本为v1.22.14-820d8870-aliyun及以上版本。
如需升级CSI组件,请同时升级csi-plugin和csi-provisioner。具体操作,请参见升级csi-plugin和csi-provisioner。
已开启阿里云Prometheus监控。具体操作,请参见开启阿里云Prometheus监控。
容器存储的使用及监控方法
支持监控功能的容器存储
容器存储类型
底层存储
监控方法
emptyDir
Pod所在节点的目录
打开Prometheus 监控页面,在应用监控页签下的集群Pod监控页签下查看Ephemeral Storage监控数据,具体请参见Ephemeral Storage监控。
说明emptyDir没有单独的存储监控指标,只能作为临时存储的一部分,在Pod监控大盘的Ephemeral Storage监控中查看。
云盘存储卷
阿里云云盘
打开Prometheus 监控页面,在存储监控页签下的CSI Disk页签下查看云盘存储卷监控大盘,具体请参见云盘存储卷监控。
NAS和CPFS存储卷
阿里云文件存储
打开Prometheus 监控页面,在存储监控页签下的CSI NAS页签下查看NAS存储卷监控大盘,具体请参见NAS存储卷监控。
OSS存储卷
阿里云对象存储
打开Prometheus 监控页面,在存储监控页签下的CSI OSS页签下查看OSS存储卷监控大盘,具体请参见OSS存储卷监控。
不支持监控功能的容器存储
容器存储类型
底层存储
不支持监控功能的原因
hostPath
Pod所在节点的文件或目录
hostPath数据卷不会被算作Pod的临时存储,使用情况不会被kubelet纳入监管范围。
Secret和ConfigMap
集群中的Secret和ConfigMap资源
Secret和ConfigMap没有较强的存储监控需求,目前社区也没有针对此类数据卷的监控设计。
存储监控入口
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
集群存储监控大盘
在Prometheus 监控页面,单击监控概览,然后单击集群监控概览页签,进入集群监控大盘。
集群监控大盘中的存储资源监控界面以及相关指标介绍如下:


指标名称 | 说明 |
PVC Overview | 集群中已挂载的存储卷的概要信息,包括对应的存储卷声明的名称、存储卷名称、存储类型、所属命名空间、集群中挂载了该存储卷的节点数量、总空间、空间使用量、空间使用率。 |
Container File System Usage(Top 10) | 容器RootFS空间使用量最高的前10个容器。 |
Container File System Inode Usage(Top 10) | 容器RootFS中inode使用量最高的前10个容器。 |
节点存储监控大盘
在Prometheus 监控页面,单击节点监控,然后单击集群节点监控详情页签,进入节点监控大盘。
节点监控大盘中的存储资源监控包含磁盘监控和PVC使用监控,相关界面以及指标介绍如下:
磁盘监控
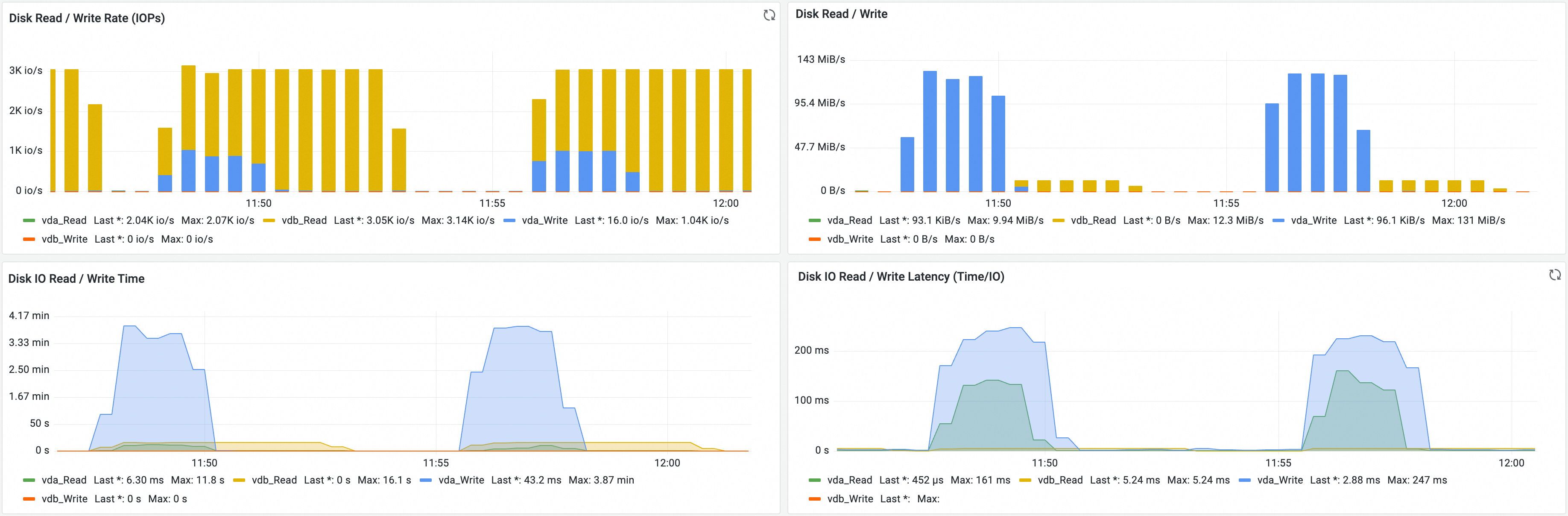
指标名称 | 说明 |
Disk Read / Write Rate (IOPs) | 磁盘每秒读写次数。 |
Disk Read / Write | 磁盘每秒读写速率。 |
Disk IO Read / Write Time | 磁盘每秒读写用时。 |
Disk IO Read / Write Latency (Time/IO) | 磁盘每秒读写时延。 |
PVC监控
该节点上已挂载的PVC的概览信息以及各PVC的实时读写速率。
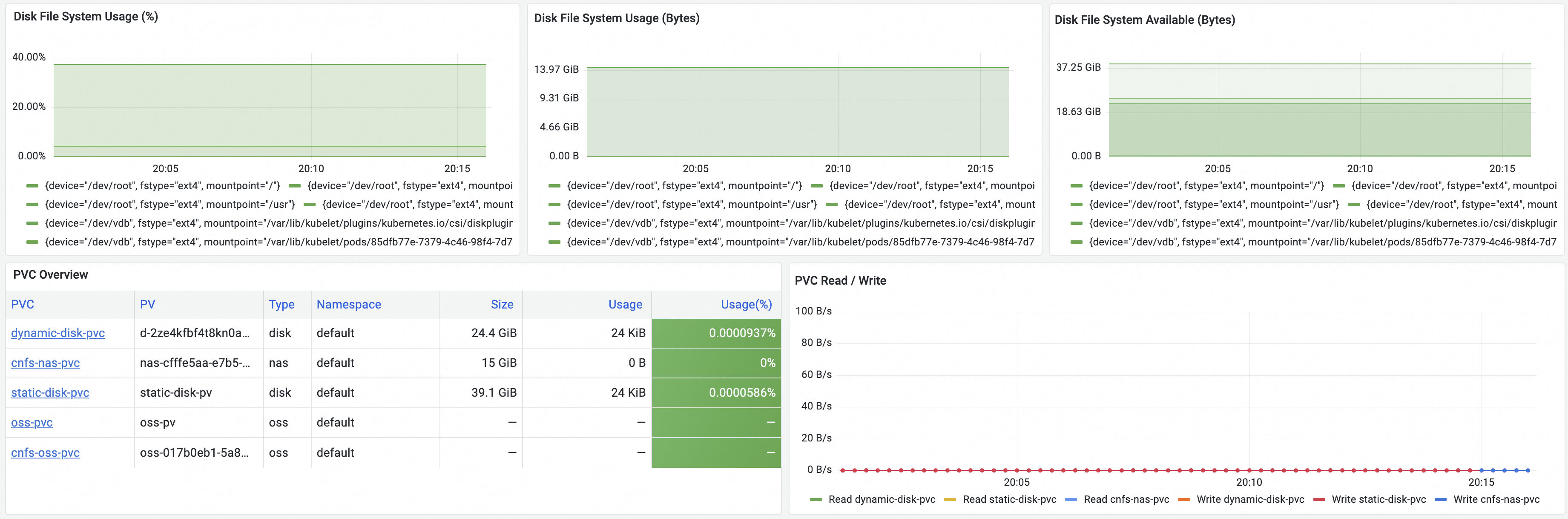
指标名称 | 说明 |
Disk File System Usage (%) | 磁盘空间使用率。 |
Disk File System Usage (Bytes) | 磁盘空间使用量。 |
Disk File System Available (Bytes) | 磁盘空间可用量。 |
PVC Overview | 节点已挂载的各存储卷的概要信息,包括对应存储卷声明的名称、存储卷名称、存储类型、所属命名空间、集群中挂载了该存储卷的节点数量、总空间、空间使用量、空间使用率。 |
PVC Read / Write | 各存储卷的实时读写速率。 |
Pod存储监控大盘
在Prometheus 监控页面,单击应用监控,然后单击集群Pod监控页签,进入Pod监控大盘。
Pod监控大盘中集群内部RootFS和Ephemeral Storage存储资源监控界面及各指标介绍如下:
RootFS监控
若您的集群为1.24及以上版本,以下指标依赖于csi-plugin组件。CSI组件需为v1.28.3-eb95171-aliyun及以上版本,否则会缺少Pod维度的指标信息。组件发布记录请参见csi-plugin,如需升级,请参见升级csi-plugin和csi-provisioner。
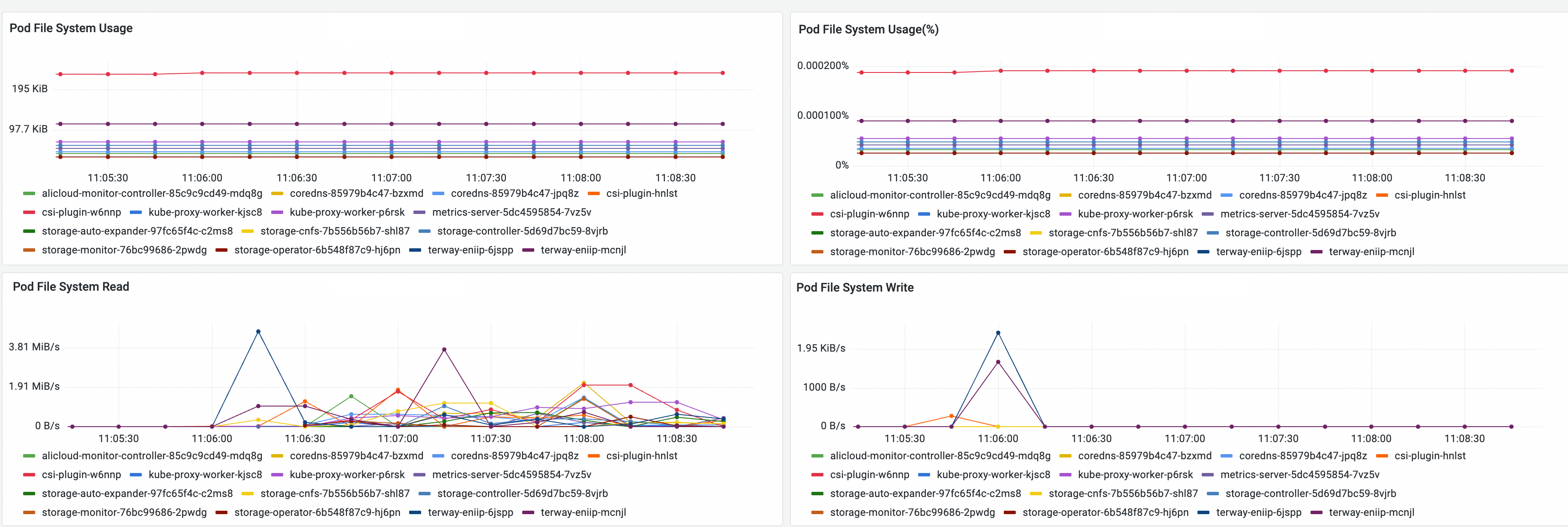
指标名称 | 说明 |
Pod File System Usage | Pod的RootFS空间使用量。 |
Pod File System Usage(%) | Pod的RootFS空间使用率。 |
Pod File System Read | Pod的RootFS实时读取速率。 |
Pod File System Write | Pod的RootFS实时写入速率。 |
Ephemeral Storage监控
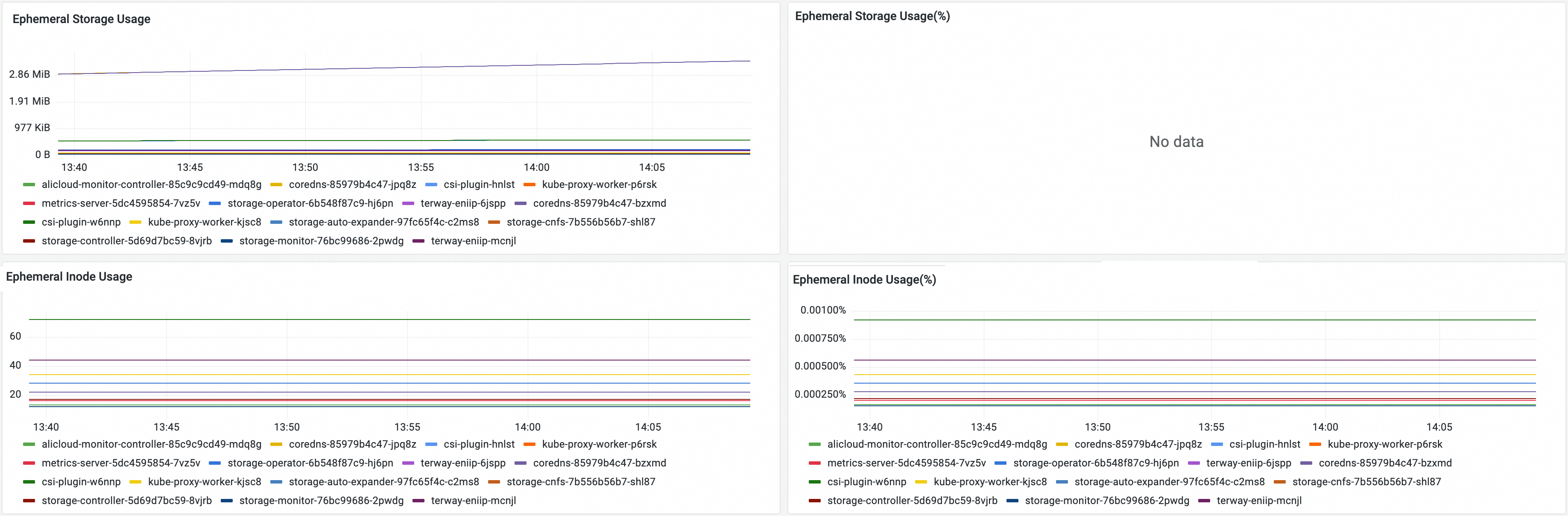
指标名称 | 说明 |
Ephemeral Storage Usage | Pod的Ephemeral Storage空间使用量。 |
Ephemeral Storage Usage(%) | Pod的Ephemeral Storage空间使用率。 说明 仅当设置了 |
Ephemeral Inode Usage | Pod的Ephemeral Storage inode使用量。 |
Ephemeral Storage Inode Usage(%) | Pod的Ephemeral Storage inode使用率。 |
存储卷监控大盘
如果您在集群中为Pod挂载了云盘、NAS、OSS等存储卷,您可以通过以下方式查看各存储卷的使用情况。
云盘存储卷监控
在Prometheus 监控页面,单击存储监控,然后单击CSI Disk页签,进入云盘存储卷监控大盘,可以查看云盘的PVC信息,所挂载的节点、云盘使用情况等信息。
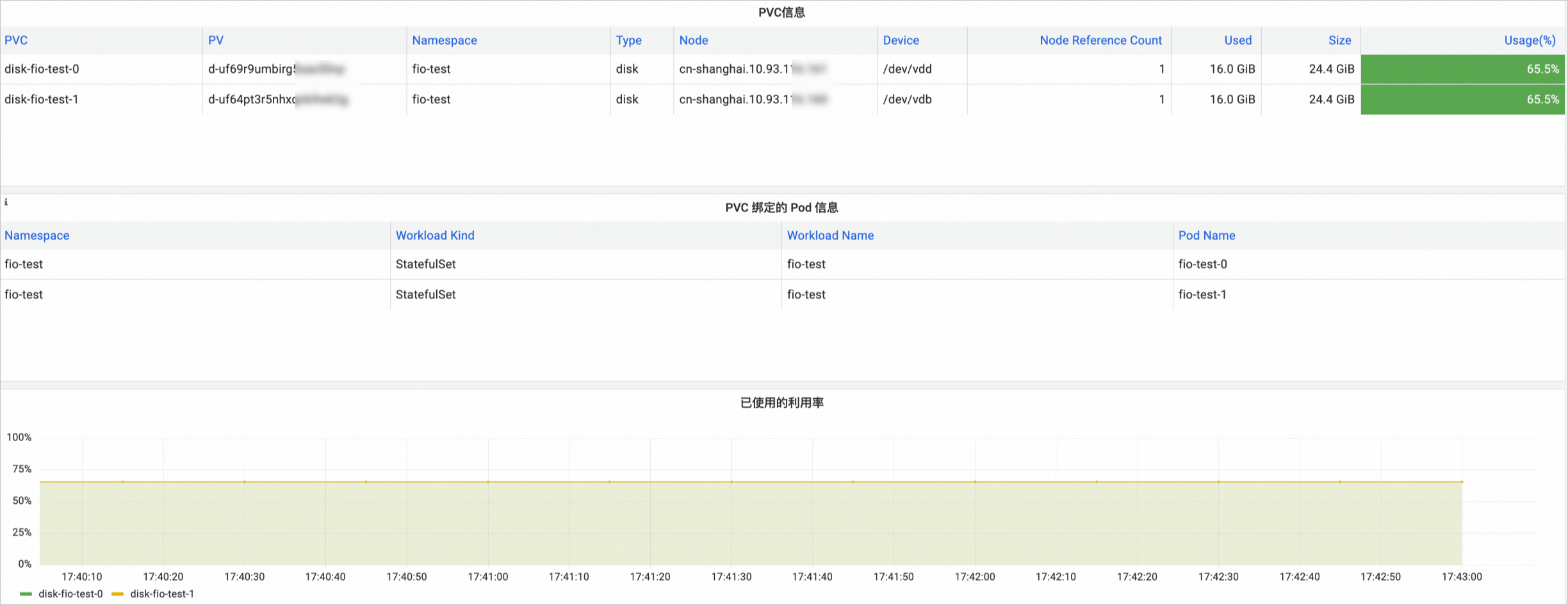
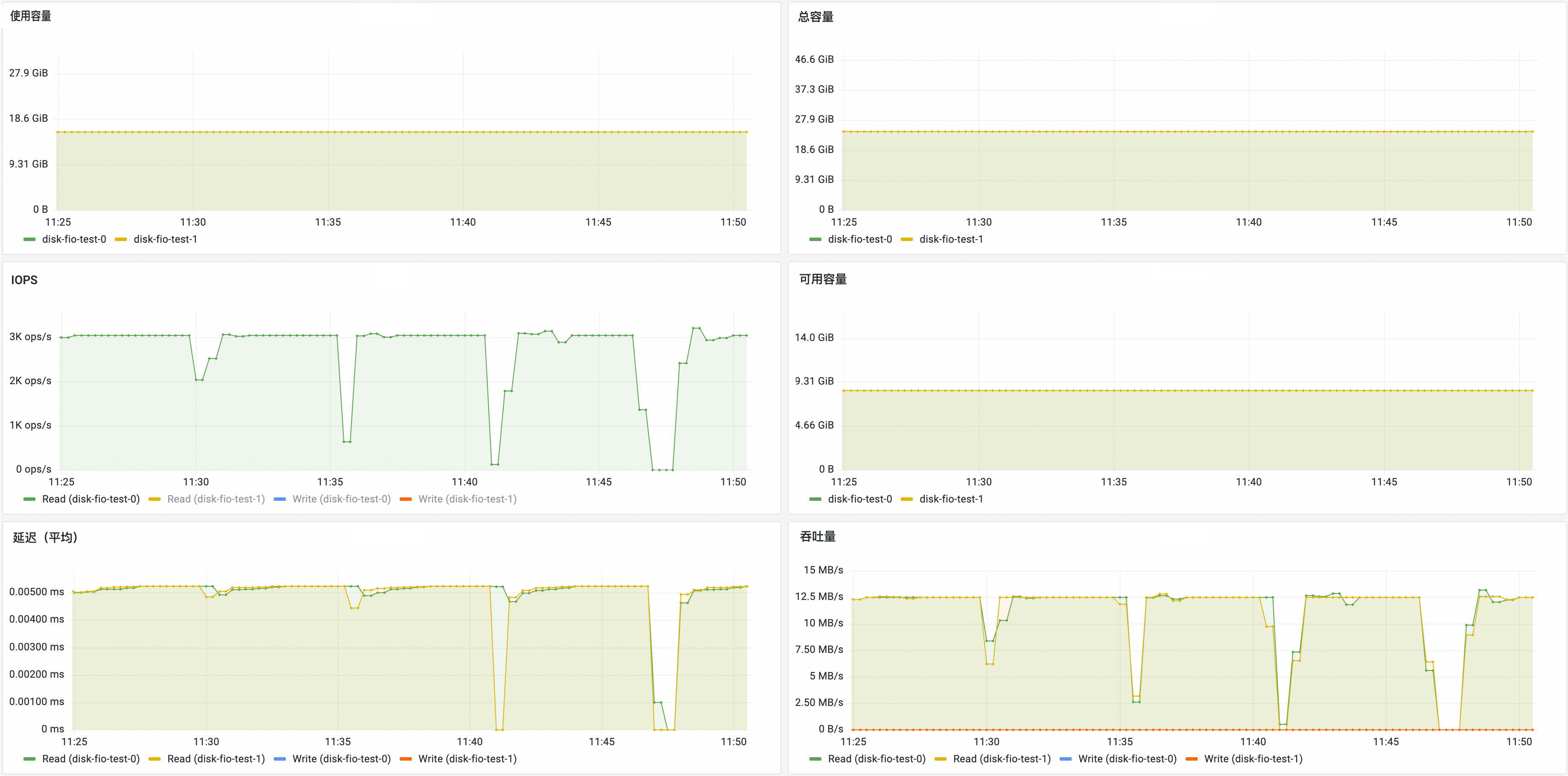
NAS存储卷监控
在Prometheus 监控页面,单击存储监控,然后单击CSI NAS页签,进入NAS存储卷监控大盘,可以查看NAS的PVC信息,所挂载的节点、NAS使用情况等信息。
只有通过CNFS使用的NAS存储卷才有已使用的利用率、总容量、使用容量、可用容量四个指标的数据。
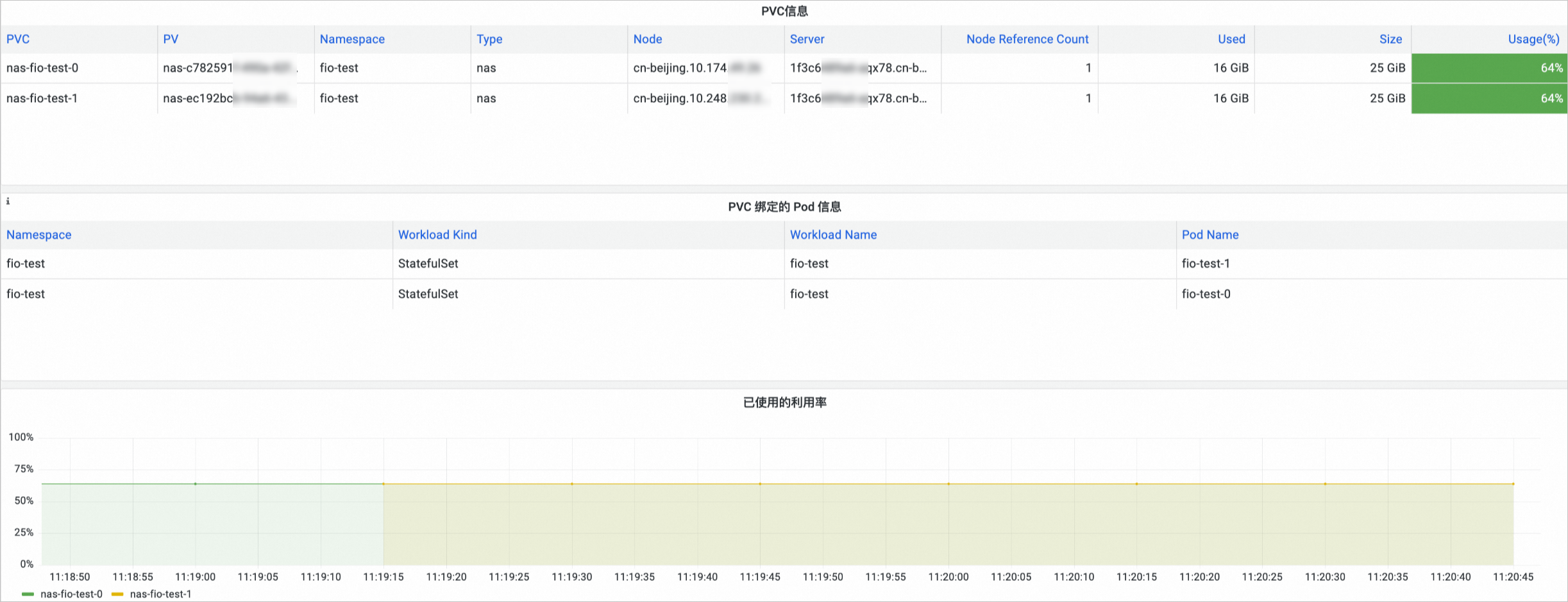
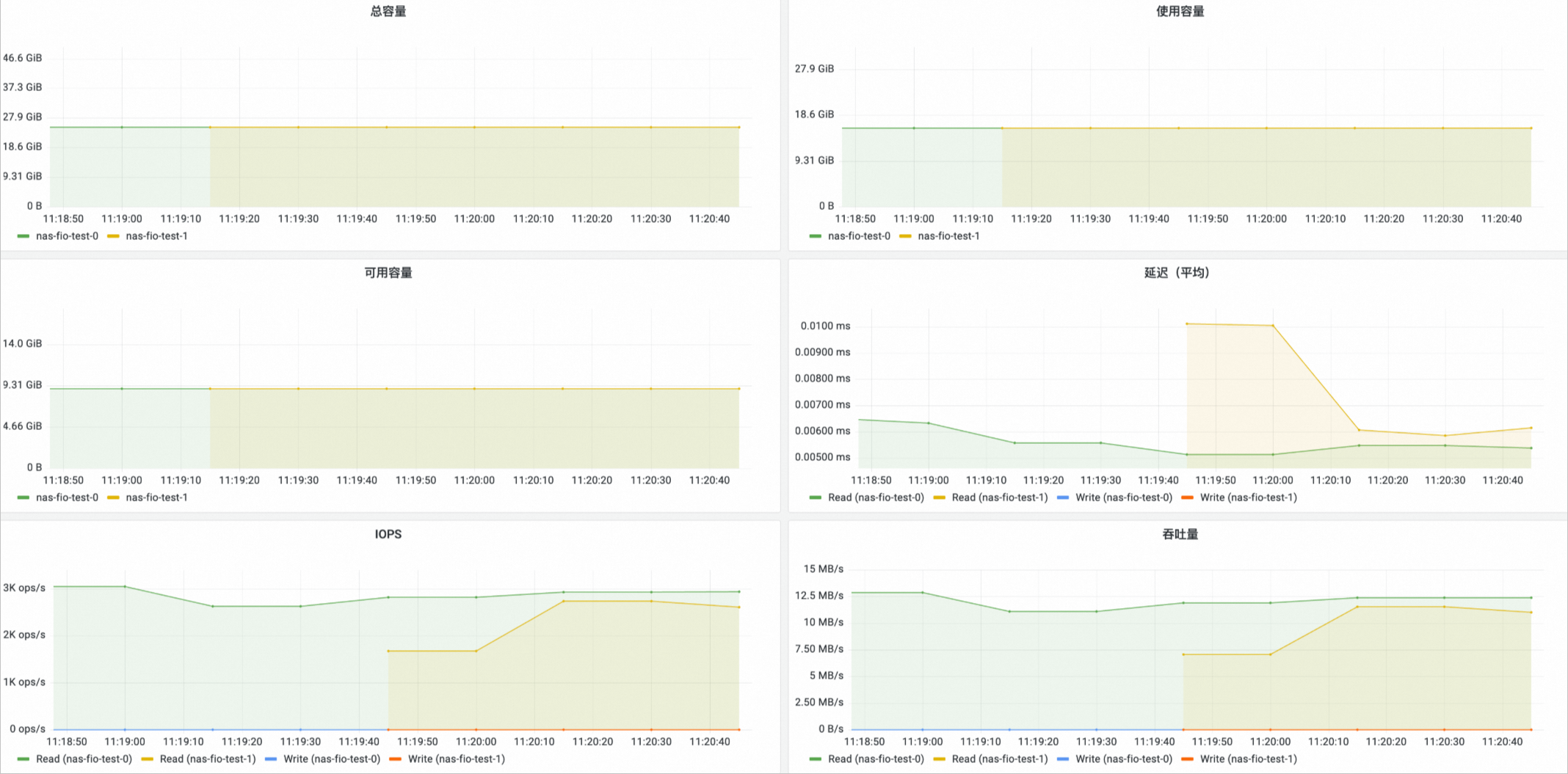
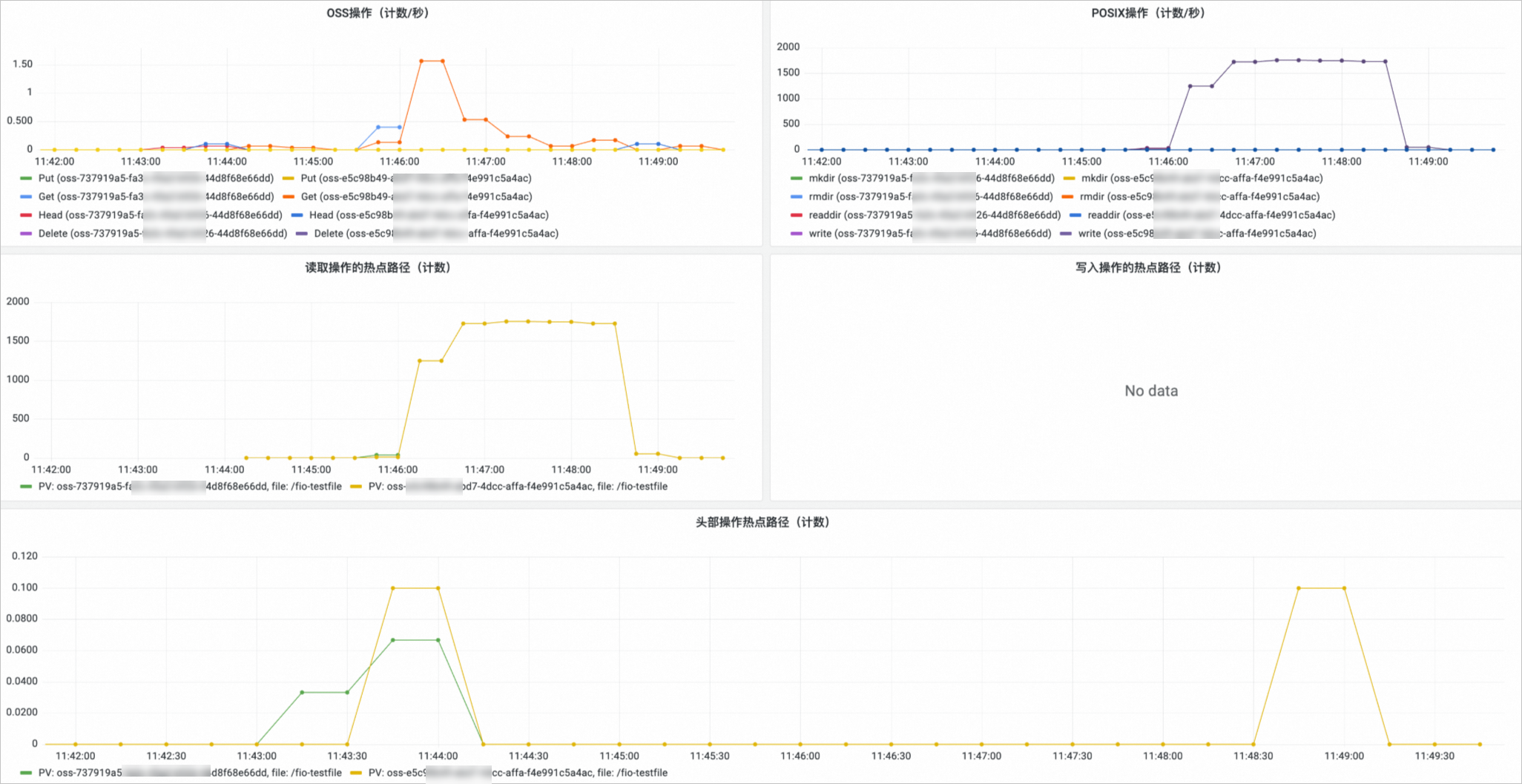
OSS存储卷监控
在Prometheus 监控页面,单击存储监控,然后单击CSI OSS页签,进入OSS存储卷监控大盘,可以查看OSS的PVC信息,所挂载的节点、OSS使用情况等信息。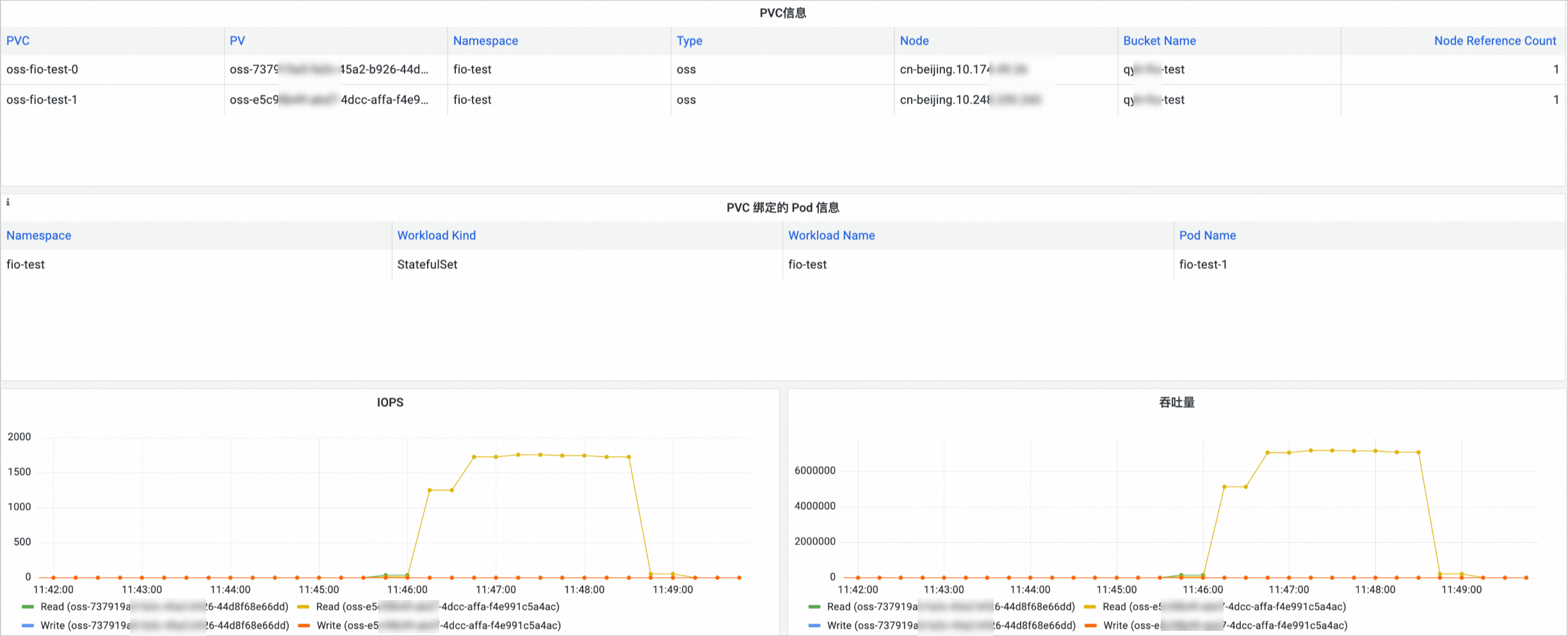
相关文档
容器存储监控采集的指标,请参见存储监控指标说明。
如需扩容存储卷,请参见扩容云盘存储卷、扩容NAS动态存储卷容量、使用CNFS自动扩容NAS存储卷。