
NVIDIA GPU上存在一些硬件计数器,这些计数器可以用来收集一些设备级别的性能指标,例如GPU利用率、内存使用情况等。借助NVIDIA提供的NVML(NVIDIA Management Library)库或DCGM(Data Center GPU Manager)工具能够查询这些硬件层提供的指标。本文介绍硬件层Profiling的优缺点,以及运维人员和开发人员利用DCGM实现GPU性能分析的使用场景。
优势与局限性
在硬件层面进行性能分析的优势与局限性如下所示:
对比项 | 说明 |
优势 |
|
局限性 |
|
用户角色
集群管理员和开发人员在利用DCGM实现性能分析时,关注点和适用场景有所不同。
角色类型 | 说明 |
集群管理员 | 作为公司的Kubernetes集群管理员,您可能需要了解公司各个部门使用GPU资源的习性,从而更好地理解并优化整个集群中GPU资源的分配和使用情况,以提高集群的整体效率和服务质量。具体使用场景,请参见: |
开发人员 | 作为AI应用开发人员,您可能会关注硬件层面上的Profiling指标以做出最佳实践决策。通过了解业务的GPU使用情况,以便进行容量规划和任务调度。具体使用场景,请参见: |
前提条件
已创建托管GPU集群或专有GPU集群。具体操作,请参见创建GPU集群。
ACK集群支持的GPU机型,请参见ACK支持的GPU实例规格族。
使用场景
场景一:分析集群是否高效地使用GPU
某些场景下,GPU利用率高并不代表应用充分利用了GPU资源。在分析GPU性能时,不仅需要观察CPU利用率,还要结合其他关键指标,才能全面评估应用程序是否真正有效地利用了GPU资源。
以下将以一个简单的CUDA程序示例说明GPU利用率高并不代表高效的利用了GPU资源。
创建并拷贝以下内容到cuda-sample.yaml文件中,用于创建Pod。
apiVersion: v1 kind: Pod metadata: name: cuda-sample spec: containers: - name: cuda image: nvidia/cuda:12.1.0-devel-ubuntu22.04 command: - sleep - 1d resources: limits: nvidia.com/gpu: 1执行以下命令,创建Pod。
kubectl apply -f cuda-sample.yaml当Pod处于Running状态后,使用
kubectl exec -ti cuda-sample bash命令进入Pod中,然后将下方代码保存到名为Test_GPU_Utilization.cu的文件中。以下C++代码是CUDA编程语言的一个简单示例,用于在NVIDIA GPU上执行一个简单的空循环操作,模拟GPU线程等待一段时间的行为。
# include <stdio.h> # include <unistd.h> # include <stdlib.h> const long long tdelay=100000000000000LL; // 核函数定义,这个核函数所干的事有点类似于使这个GPU线程一直sleep状态。 __global__ void dkern(){ long long start = clock64(); long long targetClock = start+tdelay; while(clock64() < targetClock); } int main(int argc, char *argv[]){ dkern<<<1,1>>>(); // 调用核函数启动1个线程块,这个线程块包含1个线程。 cudaDeviceSynchronize(); return 0; }使用nvcc编译器编译代码,生成可执行文件Test_GPU_Utilization。
nvcc -o Test_GPU_Utilization Test_GPU_Utilization.cu如果编译过程中有错误,会输出相关错误信息。
执行以下命令,直接运行生成的可执行文件。
./Test_GPU_Utilization另起一个终端,进入名为cuda-sample的Pod中,执行以下命令,查看GPU的利用情况。
nvidia-smi预期输出:
Wed Mar 27 15:08:29 2024 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 470.161.03 Driver Version: 470.161.03 CUDA Version: 11.4 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00000000:00:07.0 Off | 0 | | N/A 44C P0 39W / 70W | 100MiB / 15109MiB | 100% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 108695 C ./Test_GPU_Utilization 97MiB | +-----------------------------------------------------------------------------+从NVIDIA-SMI输出信息来看,GPU占用了大约97 MiB的内存,且GPU利用率显示为100%,这意味着这块GPU正全力运行该程序。
但实际上通过登录容器服务管理控制台查看监控大盘,发现FP32 Pipe Active、FP64 Pipe Active、Tensor Core Pipe Active这些相关指标数据,可以了解到CUDA Core和Tensor Core基本没有使用。
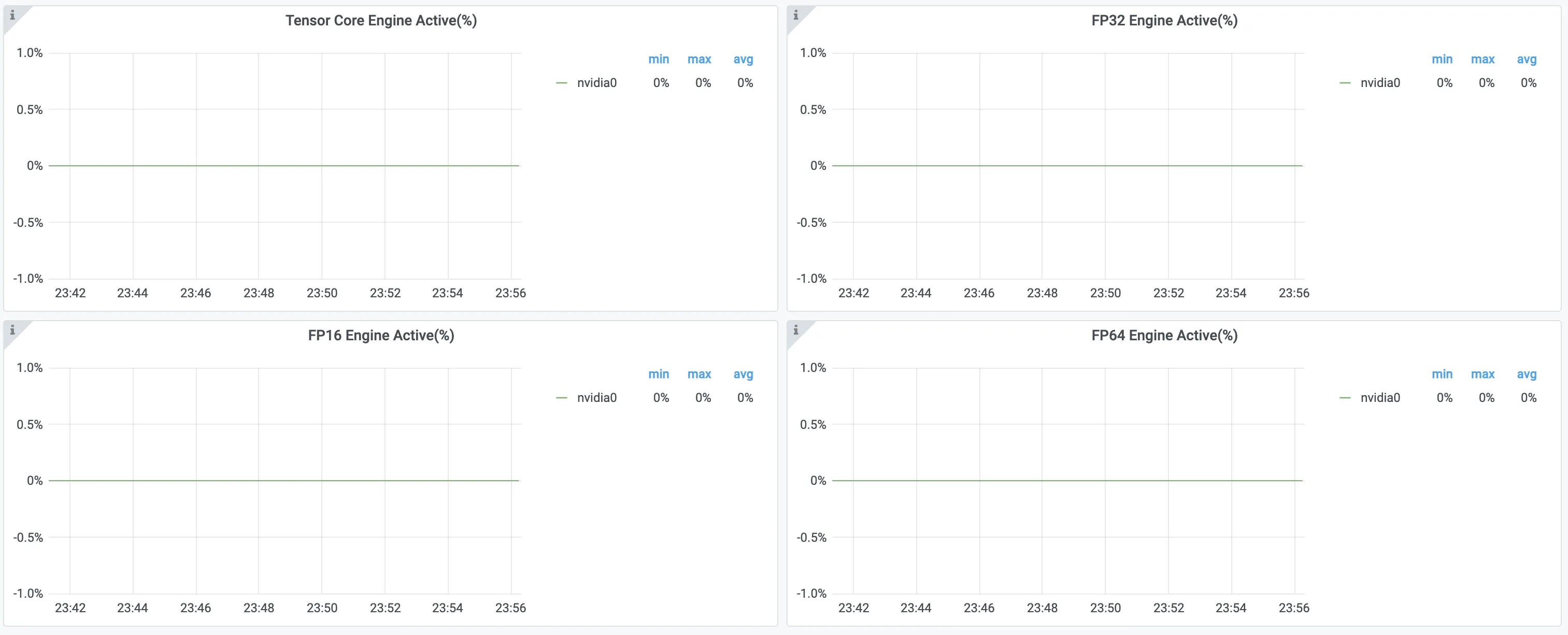
综上所述,即使使用命令查看GPU的利用率为100%,也应该再利用CUDA Core和Tensor Core相关指标查看其具体使用GPU的情况。关于如何查看GPU监控大盘,请参见监控集群GPU资源最佳实践。
场景二:了解各个部门常用的GPU资源
作为Kubernetes集群管理员,面对集群中包含V100、T4和A10等多种GPU类型的混合部署情况(即:集群中某些节点存在V100 GPU,某些节点存在T4 GPU等),您需要对资源分配进行精细化管理以最大程度地利用有限且宝贵的GPU资源。
例如,如果部门A的应用主要依赖于FP32(单精度浮点数)计算能力,部门B的应用需要用到bf16(半精度浮点数)和int4(4位整数)等数据类型。
V100、T4和A10等多种GPU类型均支持FP32计算能力,但bf16、int4等数据类型在V100、T4卡型不支持。
如下图所示,通过硬件层Profiling监控可以看到部门A的应用基本使用的CUDA Core为FP32。
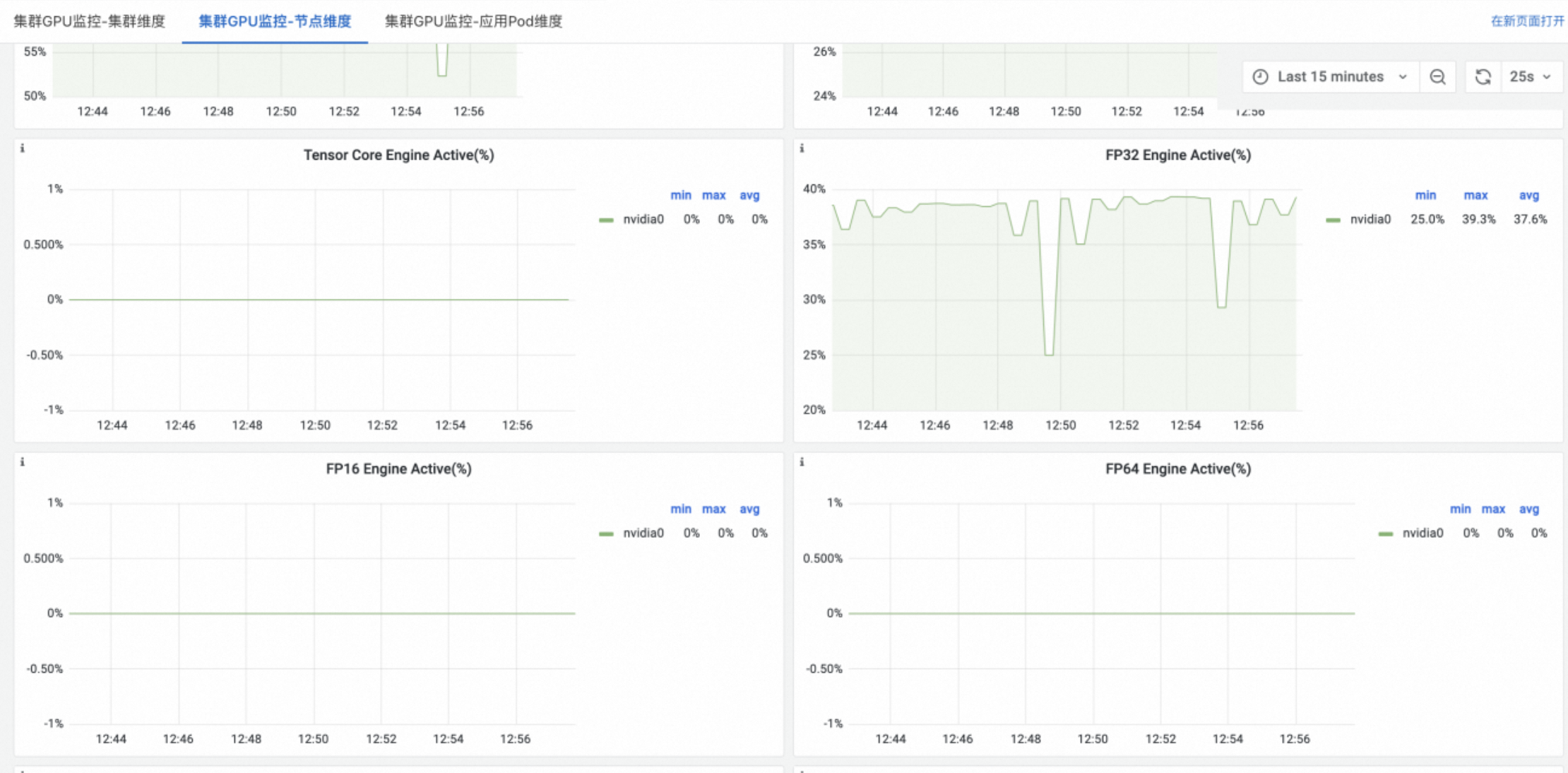
针对以上这种情况,如果不加区分地将部门A的应用部署在A10等更适合部门B应用的GPU节点上,一旦部门A的应用占用过多的A10等卡,有可能造成部门B的应用无法找到合适的GPU资源而无法运行。
综上所述,部门A的应用应该优先考虑部署到V100或T4节点上,这样就可以释放出A10等更高级别的GPU用于满足部门B对特定硬件加速功能的需求。
场景三:评估训练任务中如何设置Batch Size参数的大小
在深度学习训练任务中,Batch Size(批量大小)的大小是一个超参数,设置Batch Size的大小不仅需要考虑其对训练模型的影响,同时需要考虑GPU硬件资源的能力。
Batch Size设置过小,容易造成GPU饥饿,即GPU资源未充分利用。
Batch Size设置过大,容易造成大量数据在GPU上都处于等待状态,性能反而有可能下降。
为了避免出现以上问题,可以先准备小批量数据(不需要太多,训练任务能够运行5~10分钟即可),然后将这个训练任务启动多个副本,每个副本除了Batch Size大小不同以外,其他配置完全相同。然后通过硬件层面的Profiling指标寻找合适的Batch Size。具体操作步骤如下所示:
执行以下命令,运行名为main.py的Python脚本。
以PyTorch Examples中的word_language_model为例,训练Transformer模型。
python main.py --cuda --epochs 500 --batch_size 16 --model Transformer --lr 5以上命令的参数说明如下:
--cuda:表明使用GPU进行加速计算。--epochs 500:设置训练轮数为500轮,可以有足够长的时间观察到Profiling指标。--batch_size:用于设置训练任务每批包含的样本数大小。--model Transformer:使用的模型架构为Transformer。--lr 5:学习率为5,即模型参数更新的速度。
登录容器服务管理控制台可以查看GPU监控大盘数据和指标。
关于如何查看GPU的监控大盘,请参见监控集群GPU资源最佳实践。
将Batch Size大小分别设置为8、32、64、128、256、512(上一步已设置为16),统计五分钟内相关指标的平均值。
以下表格中,SM Active、SM Occupancy和FP32 Pipe Active对应的DCGM指标分别为DCGM_FI_PROF_SM_ACTIVE、DCGM_FI_PROF_SM_OCCUPANCY和DCGM_FI_PROF_PIPE_FP32_ACTIVE。关于DCGM指标的详细信息,请参见监控指标说明。
BatchSize
8
16
32
64
128
256
512
SM Active(%)
35.8
53.2
66.6
77.5
81.5
86.9
88.4
SM Occupancy(%)
18.2
25.1
32.1
38.8
43.7
46.9
48.1
FP32 Pipe Active(%)
15.6
27.7
37.6
45.1
49.3
54.7
55.7
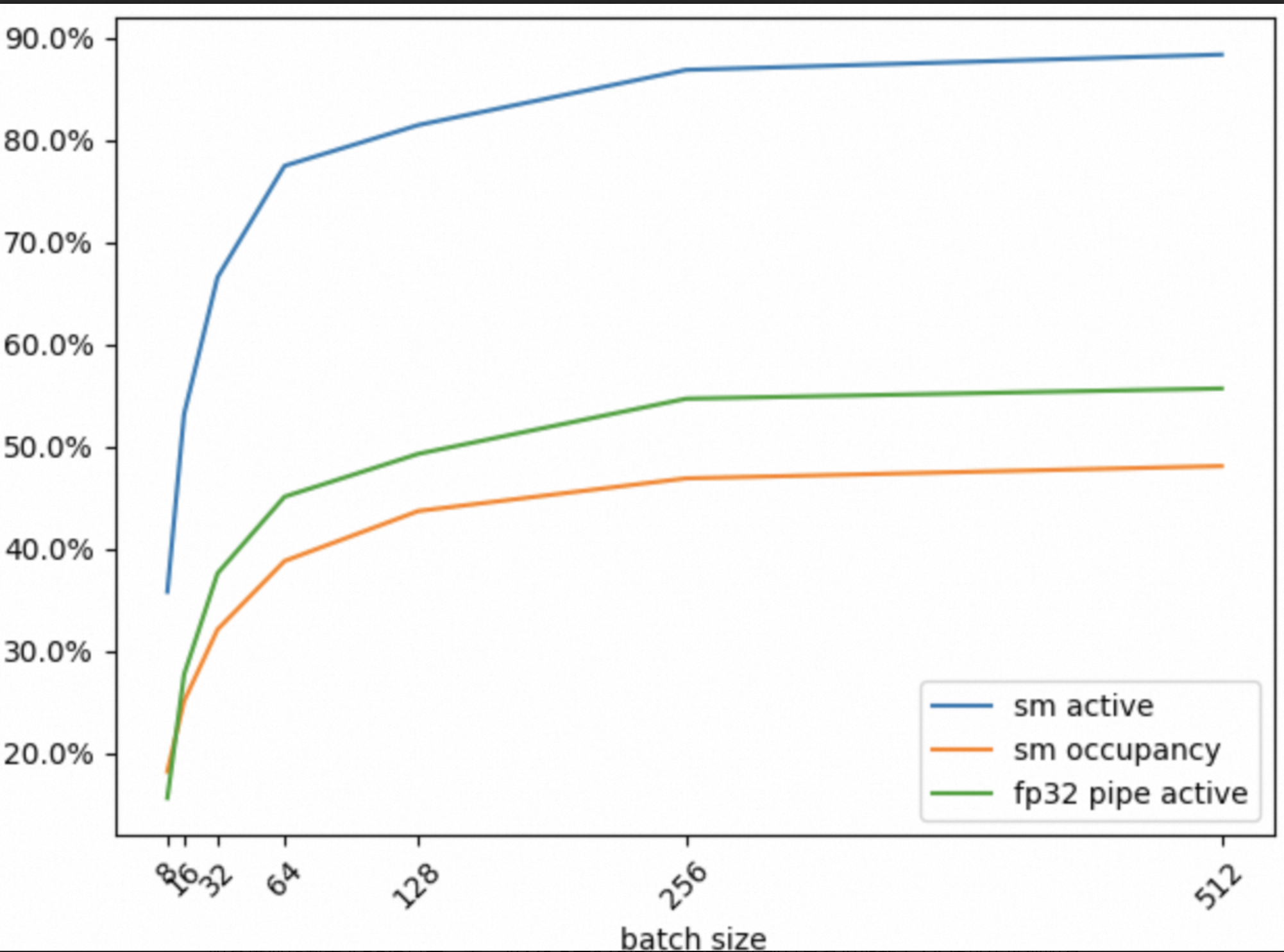
如下所示,将以上表格的数据汇总成折线图:
得出如下结论:
Batch Size从8到64,SM Active、SM Occupancy和FP32 Pipe active三个指标值都显著提升,也就是说增大Batch Size能够显著提升GPU资源的利用率。
Batch Size从64到256,SM Active、SM Occupancy和FP32 Pipe active三个指标值有提升,但增速放缓。
Batch Size从256到512,SM Active、SM Occupancy和FP32 Pipe active三个指标值几乎没有什么提升。
对于这个训练任务,如果仅从GPU资源高效利用的角度来看,Batch Size大小设置为64~256比较合适。
场景四:评估一张共享GPU卡可以运行多少个AI推理服务
对于推理服务而言,其使用GPU资源一般比较低效,如果将整张GPU卡分配给该推理服务,则会造成GPU资源浪费。这时可以考虑共享GPU方案,即在一张GPU上部署多个推理服务,增大GPU卡的资源使用密度。但是一张GPU卡部署多少个推理服务又是需要考量的问题。
从GPU资源使用的角度看,有以下两个问题需要考虑:
推理服务模型加载需要消耗GPU显存,所以该推理服务对于GPU显存的使用有一个最小值。例如,某个推理服务模型加载需要5 GiB显存,而一张A10卡有24 GiB显存左右,也就是最多仅能放下4个这样的推理服务。
在业务高峰期,单张GPU卡上多个推理服务都承载着高并发请求,需要评估是否会存在因为GPU上计算资源不足导致某些推理请求在GPU上处于等待状态,进而导致服务时延变长。
对于第一个问题,在一张卡上部署推理服务以后,通过nvidia-smi工具或GPU监控大盘可以很简单地获取到该推理服务模型加载使用的显存。
对于第二个问题,可以借助Profiling指标做一个评估。如下所示:
使用Arena向ACK集群提交一个bloom-tgi推理服务。
如果未安装Arena,请配置Arena客户端。具体操作,请参见配置Arena客户端。
arena serve custom \ --name=bloom-tgi-inference \ --gpumemory=6 \ --version=alpha \ --replicas=1 \ --restful-port=8080 \ --image=ai-tool-registry.cn-beijing.cr.aliyuncs.com/kube-ai/bloom-tgi:v0.1.0 \ "text-generation-launcher --disable-custom-kernels --model-id /model/bloom-560m --num-shard 1 -p 8080"使用压测工具Hey压测该推理服务。
说明Hey压测工具的详细介绍,请参见Hey。
hey \ -z 500000s \ -c 120 \ -m POST \ -H "Content-Type: application/json" \ -D ./bloom-tgi.json \ "http://bloom-tgi-inference-alpha:8080/generate"登录容器服务管理控制台可以查看GPU监控大盘指标数据。
关于如何查看GPU的监控大盘,请参见监控集群GPU资源最佳实践。
将示例的推理服务个数由1个增加到5个。
下面是在单张V100上,部署示例的推理服务个数由1个增加到5个,同时使用上一步的hey命令对每个服务做压测,得到各个Profiling指标的平均值(10分钟)如下:
推理服务个数
1
2
3
4
5
GPU Utilization(%)
18
74
94
98.0
100
SM Active(%)
5.87
11.3
16.0
18.6
20.6
SM Occupancy(%)
1.15
2.24
3.19
3.66
4.07
Tensor Core(%)
1.39
1.92
2.65
3.36
3.47
FP32 Core(%)
0.532
0.823
1.13
1.33
1.47
FP16(%)
0.0482
0.0736
0.0986
0.12
0.125
当单张GPU卡部署该推理服务由1到5时,GPU Utilization有很大的提升,接近100%,至少从表面看,这张卡的GPU资源使用情况很高。
当单张GPU卡部署该推理服务由1到5时,SM Active有很大的提升,达到20%左右,但这还不够,这个值一般要达到80%才算高效利用GPU资源。
当单张GPU卡部署该推理服务由1到5时,SM Occupancy、FP32 Pipe Active、FP16 Pipe Active、Tensor Pipe Active有提升,但是不太明显,使用率基本低于5%
综上所述,即使当前GPU卡部署5个这样的示例推理服务,但是对GPU计算资源的使用情况远没有达到其最大值,所以从GPU资源使用角度看,部署5个服务完全可行。
场景五:评估是否可以在共享的GPU上开启MPS能力
从本文的场景四中可以看到,一张V100卡上即使部署5个推理服务,在高并发请求情况下,FP32 Pipe Active、FP16 Pipe Active、Tensor Pipe Active等利用率仍然非常低(不超过5%),为了进一步提升GPU资源利用率,您可以评估是否可以在这张GPU卡上开启MPS(Multi-Process Service)能力。
借助Profiling性能指标能够评估使用MPS前和MPS后的效果,例如,先在节点上开启GPU卡的MPS能力,然后再重新部署一下这些推理服务,利用Hey压测工具,观察SM Occupancy、FP32 Pipe Active、FP16 Pipe Active、Tensor Pipe Active等指标参数就可以作出评估。
场景六:评估GPU的基本性能
在评估GPU基本性能时,您可以先借助硬件层的Profiling能力对应用做初步的性能评估,如果发现应用对GPU的利用率低,再借助例如Nsight System和Nsight Compute等专业的GPU Profiling工具对应用做深度分析和优化。
相关文档
如需更精细化地使用GPU的显存和算力资源,请参见通过共享GPU调度实现算力分配。
如需了解GPU各个监控面板(Panel)的含义,请参见监控面板说明。
关于GPU监控指标的详细信息,请参见监控指标说明。