
在深度学习中,一般会使用Nsight Systems和Nsight Compute工具对AI应用进行性能分析与优化。本文演示如何使用Nsight Systems对AI应用进行性能分析与优化。
AI性能分析优化流程
NVIDIA提供了一些适用于CUDA层面的Profiling工具,其中最重要的是Nsight产品族的性能分析工具Nsight Systems、Nsight Compute和Nsight Graphics。
在深度学习中,一般会使用Nsight Systems和Nsight Compute完成性能分析与优化,基本不会用到Nsight Graphics。

在整个性能优化周期中,通常会先使用Nsight Systems获取全局视角,接着借助Nsight Compute深入探究特定问题,优化完成后返回Nsight Systems重新评估整体效果,以此迭代直到达到理想的性能水平。
例如,使用Nsight Systems和Nsight Compute对AI应用实现性能分析与优化的流程为:
先利用Nsight Systems观察到某个CUDA Kernel具体运行时间,分析一下程序。
如果发现某个Kernel运行时间过长,可以使用Nsight Compute对这个CUDA Kernel做进一步的性能分析并进行优化。
CUDA Kernel如果优化完成,可以再次使用Nsight Systems对程序做Profiling,如此反复,直到整个程序的性能优化达到预期结果。
Nsight Systems的优势与局限性
优势
跨平台可视化:
可以实时捕获并可视化整个系统的活动,包括但不限于CPU、GPU、网络接口控制器(NIC)、存储以及其他加速器设备的执行情况和资源利用状况。这有助于开发者直观地理解不同硬件组件之间的交互和依赖关系。
深度硬件洞察:
提供Device级别的Profiling指标,能够深入揭示GPU工作负载的细节。例如:
显示GPU的利用率,识别是否存在空闲时段或过载情况。
分析Kernel的调度和执行,包括Grid维度设置是否合理以及Stream并发是否充分利用了GPU资源。
检测单个流多核处理器(Streaming Multiprocessor,SM)的占用情况,以及Warp调度的效率。
确认应用是否有效地利用了Tensor Cores这类专门针对机器学习和深度学习任务设计的硬件单元。
计算GPU指令执行率,用于评估性能瓶颈和潜在优化空间。
自动优化提示:
提供Expert Systems Analysis功能。如果发现程序存在潜在可优化的点,可以给出优化建议。
局限性
修改启动命令影响程序性能:
进行Profiling时需要通过其提供的命令行工具(例如
nsys profile)来启动目标应用程序,但此操作可能会增加启动时间、改变进程环境等,从而对原始应用的性能产生一定影响。
不具备连续Profiling能力:
在长时间连续运行的应用中,尤其是当GPU使用是间歇性的(例如在线推理服务),Nsight Systems收集的数据量可能会非常庞大,这可能导致结果难以读取和分析。
环境准备
本次示例使用的GPU卡型为V100-SXM2-32GB,并使用NVIDIA官方的PyTorch Docker镜像(nvcr.io/nvidia/pytorch:24.03-py3)运行代码。
由于NVIDIA官方提供的PyTorch镜像已经预安装了Nsight Systems,所以无需重复安装。
创建具备GPU节点的集群,并为集群开启GPU监控。具体操作,请参见为集群添加GPU节点、为集群开启GPU监控。
ACK集群支持的GPU机型,请参见ACK支持的GPU实例规格族。
拉起PyTorch环境。
利用Arena拉起PyTorch环境
安装最新版Arena。具体操作,请参见配置Arena客户端。
执行以下命令,修改values.yaml文件。
vi ~/charts/pytorchjob/values.yaml打开文件后,将
shmSize和privileged的参数值修改为如下值:shmSize: 20Gi # 通过shmSize参数指定共享内存的大小。 privileged: true # 因为要使用pytorch Profiler,建议容器使用特权模式,即privileged=true。执行以下命令,拉起PyTorch环境。
使用Arena工具向ACK集群提交一个简单的PyTorch作业请求。作业本身并不执行任何实际的深度学习训练任务,而是通过执行
sleep 10d命令来模拟一个持续运行的进程,便于测试和验证作业提交流程。arena submit pytorch \ --name=workspace \ --gpus=1 \ --image=nvcr.io/nvidia/pytorch:24.03-py3 \ "sleep 10d"预期输出:
pytorchjob.kubeflow.org/workspace created INFO[0005] The Job workspace has been submitted successfully INFO[0005] You can run `arena get workspace --type pytorchjob -n default` to check the job status输出结果显示PyTorch作业已成功创建。
执行以下命令,查看作业是否已经处于
Running状态。arena get workspace当作业处于
Running状态后,执行以下命令进入PyTorch容器,即可进行Profiling。arena attach workspace预期输出:
Hello! Arena attach the container pytorch of instance workspace-master-0可在PyTorch容器中检查Nsight System是否安装。
nsys profile --help
利用kubectl拉起PyTorch环境
复制并粘贴以下内容到pytorch-workspace.yaml文件中,用于创建一个Deployment。
apiVersion: apps/v1 kind: Deployment metadata: name: pytorch-workspace spec: selector: matchLabels: app: pytorch-workspace replicas: 1 template: metadata: labels: app: pytorch-workspace spec: hostIPC: true hostPID: true containers: - name: pytorch-workspace image: nvcr.io/nvidia/pytorch:24.03-py3 command: - sleep - 10d resources: limits: nvidia.com/gpu: 1 securityContext: privileged: true volumeMounts: - mountPath: /dev/shm name: dshm volumes: - emptyDir: medium: Memory name: dshm执行以下命令,创建Deployment资源。
kubectl apply -f pytorch-workspace.yaml当Pod处于
Running状态后,使用以下命令进入PyTorch容器内部。kubectl exec -it pytorch-workspace-xxxxx -- /bin/sh
训练场景
步骤一:创建示例模型
当搭建完一个深度学习网络,您可以使用NVIDIA Nsight Systems工具进行基准性能分析,观察哪些地方可以做优化。本文以TensorBoard-plugin tutorial中的示例模型为例,演示如何利用NVIDIA Nsight Systems工具寻找模型优化的机会。操作步骤如下所示。
在PyTorch容器内部,创建并拷贝以下内容到main.py文件中。
main.py文件中包含了您想要Nsight Systems分析的Python脚本逻辑。
import nvtx # 引入nvtx包,便于在nsight system中观察各个函数的逻辑关系。 import torch import torch.nn import torch.optim import torch.profiler import torch.utils.data import torchvision.datasets import torchvision.models import torchvision.transforms as T transform = T.Compose([ T.Resize(224), T.ToTensor(), T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) train_set = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) train_loader = torch.utils.data.DataLoader(train_set, batch_size=32, shuffle=True) device = torch.device("cuda:0") model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device) criterion = torch.nn.CrossEntropyLoss().cuda(device) optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9) model.train() def train(data, batch_idx): # 数据传输 nvtx.push_range("copy data " + str(batch_idx), color="rapids") inputs, labels = data[0].to(device=device), data[1].to(device=device) nvtx.pop_range() # 前向传播 nvtx.push_range("forward " + str(batch_idx), color="yellow") outputs = model(inputs) loss = criterion(outputs, labels) nvtx.pop_range() # 后向传播 nvtx.push_range("backward " + str(batch_idx), color="green") optimizer.zero_grad() loss.backward() optimizer.step() nvtx.pop_range() # 由于enumerate(train_loader)无法通过插入nvtx统计数据加载时间,将for循环代码替换为如下等价代码。 dl = iter(train_loader) batch_idx = 0 while True: try: # 统计最后3个batch总共持续的时间。 if batch_idx == 5: tet = nvtx.start_range(message="Total Elapsed Time(3 batchs)", color="orange") # 只观察前面8个batch,在这8个batch中前面5个用于wait和warmup,目标观察后面3个 if batch_idx >= 8: nvtx.end_range(tet) break # 数据加载。 nvtx.push_range("__next__ " + str(batch_idx), color="orange") batch_data = next(dl) nvtx.pop_range() # batch处理,包括数据传输和GPU计算 nvtx.push_range("batch " + str(batch_idx), color="cyan") train(batch_data, batch_idx) nvtx.pop_range() batch_idx += 1 except StopIteration: nvtx.pop_range() break在PyTorch容器内部,执行以下命令,会在当前目录下生成名为baseline.nsys-rep的文件。
nsys profile \ -w true \ --cuda-memory-usage=true \ --python-backtrace=cuda \ -s cpu \ -f true \ -x true \ -o baseline \ python ./main.py预期输出:
Files already downloaded and verified Generating '/tmp/nsys-report-6673.qdstrm' [1/1] [========================100%] baseline.nsys-rep Generated: /root/baseline.nsys-rep将baseline.nsys-rep文件导入Nsight System UI中,即可对模型进行分析。如下为初次打开的效果图:
说明如果您未安装Nsight Systems,请登录NVIDIA Developer官方网站,根据系统环境选择安装合适的Nsight Systems。

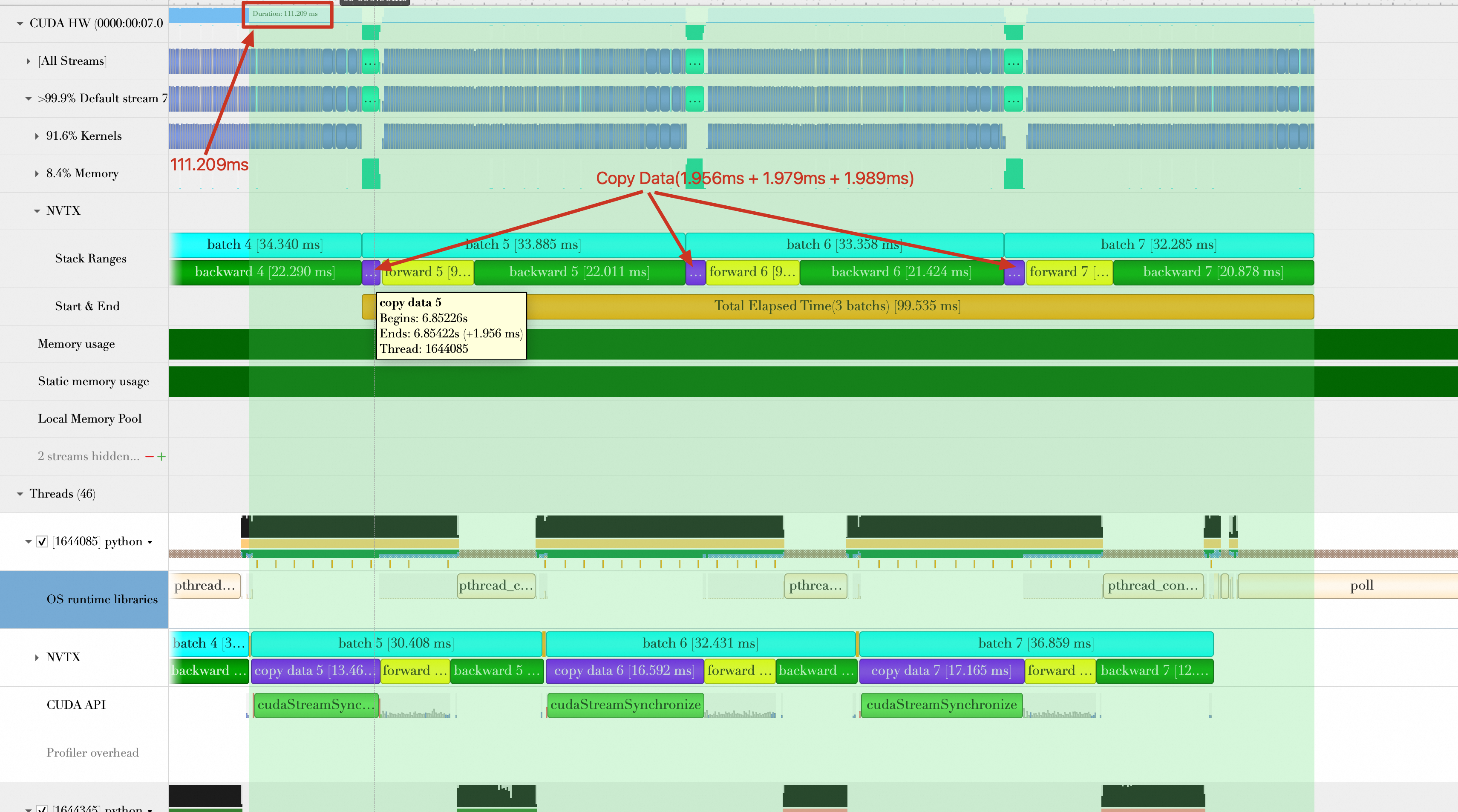
本文仅参考最后3个Batch(前3个Batch可能会受到初始化和预热效应的影响,性能评估不准确)。如下所示,放大最后3个Batch的位置。

图中有2个NVTX记录Batch时间,一个是在CUDA Stream(Default Stream)中(图中标号为1),一个是在Python线程中(图中标号为2),两者统计的Batch时间(包括
copy data、forward、backward)有很大差别。因此如果调用CUDA API并在GPU上运行核函数,此时应以在CUDA Stream中的NVTX为准(也就是标号1的数据),这是因为Batch传输和GPU计算对于CPU来说是异步的,Python线程中统计的可能不太准确。Batch数据加载和Batch计算(包括将Batch传输到GPU)是重叠的,从上图中可以看到,当进行Batch 6的加载操作时,GPU端仍然在计算Batch 5,所以在后续计算3个Batch的总持续时间时,重叠部分不计算时间。
对Baseline各个阶段的持续时间统计如下:
各阶段持续时间
耗时(单位:ms)
平均数据加载时间(图中标记:__next__)
(37.276 + 35.794 + 35.790) / 3 = 36.287
平均数据传输时间(图中折叠未显示出)
(4.39 + 4.363 + 4.317) / 3 = 4.357
平均Batch处理时间(包含数据传输、forward、backward)
(38.738 + 37.78 + 37.754) / 3 = 38.091
3个Batch总的持续时间(如下图所示,从第5个Batch数据加载到第7个Batch计算完成)
176.878 ms
平均每秒处理样本数(单位:samples/s)
32(batch size) * 3 / (176.878 / 1000) = 542.746

步骤二:优化和分析模型
模型优化流程
对于一个单机的深度学习训练任务,主要分为如下几个阶段:
数据加载(Data Loading):通常情况下,把数据从Disk(或者其他网络存储系统)加载到主机内存,并对数据做预处理操作(例如,去除噪声值),笼统地称为数据加载阶段。
数据传输(Data Transmission):将数据从主机内存传输到GPU内存。
训练(Training):GPU计算单元(CUDA Core、Tensor Core)利用这些数据做训练操作。

以下将对每部分做一些案例介绍。
优化方向1:缩短数据加载(Data Loading)时间
对于一个训练任务而言,缩短数据加载时间对整个训练任务有很大的帮助,如果数据加载时间大于GPU训练的时间,就有可能造成GPU空闲(等待数据加载)。
如下图所示,在Baseline(不包含任何优化措施)中,Batch与Batch计算之间存在很大的空隙,引起这些空隙的根因在于Batch数据加载时间比较长,GPU需要长时间等待数据加载完成才能处理这个Batch的数据,所以数据加载成为整个训练任务的瓶颈。

PyTorch的DataLoader支持多个Worker(Multi-process)同时工作,加载某一个Mini Batch的数据。修改main.py文件中的train_loader参数,尝试设置8个Worker加载数据。
train_loader = torch.utils.data.DataLoader(train_set,num_workers=8, batch_size=32, shuffle=True)重新运行,可以看到Batch与Batch之间已经没有空隙,同时数据加载时间大大缩小,三个Batch加载平均消耗时间为:(2.879 ms + 104.995 us + 180.066 us) / 3 = 1.055 ms。同时,每秒处理样本数(samples/s)为:32 * 3 / (120.328 / 1000) = 797.819(注意数据加载时间已经隐藏在GPU计算中,所以忽略),性能相比Baseline提升(797.819 - 542.746) / 542.746 * 100% = 47.00%。

优化方向2:缩短数据传输(Data Transmission)时间
在设置8个Worker的基础上,可以继续寻找示例模型训练中可优化的点。在上述的分析中,可以看到数据传输平均时间为4.357 ms,尝试开启Pin Memory来缩短数据传输时间。
在PyTorch中,支持将加载的数据直接存放在Pin Memory中。如下所示,修改main.py文件中的train_loader参数,开启Pin Memory。
train_loader = torch.utils.data.DataLoader(train_set,num_workers=8, batch_size=32,pin_memory=True, shuffle=True)重新运行代码,可以看到数据传输的平均时间为:(1.956 + 1.979 + 1.989)/ 3 = 1.975 ms,相比Baseline时间缩短4.357 ms - 1.975 ms = 2.382 ms。总的持续时间缩短为99.535 ms,平均每秒处理样本数(samples/s)为:
32 * 3 /(99.535 / 1000) = 964.485,性能提升(964.485 - 797.819)/ 797.819 * 100% = 20.89%
优化方向3:数据加载和数据计算完全重叠
在缩短数据传输时间的基础上,继续寻找优化的机会。分析开启Pin Memory的Timeline发现,虽然Batch加载和Batch计算(包括Batch传输)有重叠效果,但是Batch加载却只能重叠一个Batch计算,如下图,Batch5的加载与Batch4的计算重叠,Batch6的加载与Batch5的计算重叠,Batch7的加载与Batch6的计算重叠。并没有出现例如加载Batch6、Batch7与Batch5计算重叠的情况。同时,在Timeline中发现,在数据加载操作的后面,都会出现一次cudaStreamSynchronize,强制CPU与GPU做一次同步操作,然而每次计算Batch时并不需要这个同步操作。

这个同步操作是由如下的这行代码引入的:
inputs, labels = data[0].to(device=device), data[1].to(device=device)to函数默认行为是:每次将数据从Host端传输到GPU端后,会执行cudaStreamSynchronize进行同步。然而,to函数亦支持非阻塞模式(异步操作),通过添加参数non_blocking=True来实现:
inputs, labels = data[0].to(device=device,non_blocking=True), data[1].to(device=device,non_blocking=True)采用非阻塞模式后(异步操作),数据传输至GPU的操作被安排至CUDA流队列末尾而不会阻碍CPU,即CPU可继续执行后续任务,无需等待数据传输完成。
修改代码后,重新运行,结果显示如下。

从上面的图中可以看出:
GPU真正在计算Batch3时,CPU端Batch5、Batch6、Batch7数据加载已经完成(也就是CPU早早完成自己的任务),真正做到Batch加载与Batch计算完全重叠。
Batch5、Batch6、Batch7的加载已经完全隐藏在了Batch2、Batch3、Batch4的计算中,它们的加载时间可以忽略不计。
每秒样本处理数(samples/s)为:32 × 3 / (94.164 / 1000) = 1019.498。相比上一步的优化2,性能提升(1019.498 - 964.485)/ 964.485 × 100% = 5.7%。
优化方向4:自动混合精度
前面已经优化了数据加载、数据传输。本次将聚焦寻找一些降低GPU计算Batch时间的方法。
PyTorch支持在训练的时候开启混合精度计算( Automatic Mixed Precision (AMP)),在AMP模式下,GPU上部分Tensor自动转换为低精度的16位浮点数,并在GPU张量核心上运行,以此降低显存使用量和缩短计算时间。
修改下面的代码开启AMP模式。在生产环境中,AMP的完整实现可能需要梯度缩放,下方代码演示中没有包括这一点,请参考相关文档正确使用AMP。
# train step
def train(data):
# 省略其他代码
# 开启amp
with torch.autocast(device_type='cuda', dtype=torch.float16):
outputs = model(inputs)
loss = criterion(outputs, labels)
# 省略其他代码 开启AMP的结果如下。Batch计算时间缩短为58.938 ms,平均每秒处理的样本数为:32 × 3 / (58.938 /1000) = 1628.83,性能提升(1628.83 - 1019.498)/ 1019.498 × 100% = 59.77%。

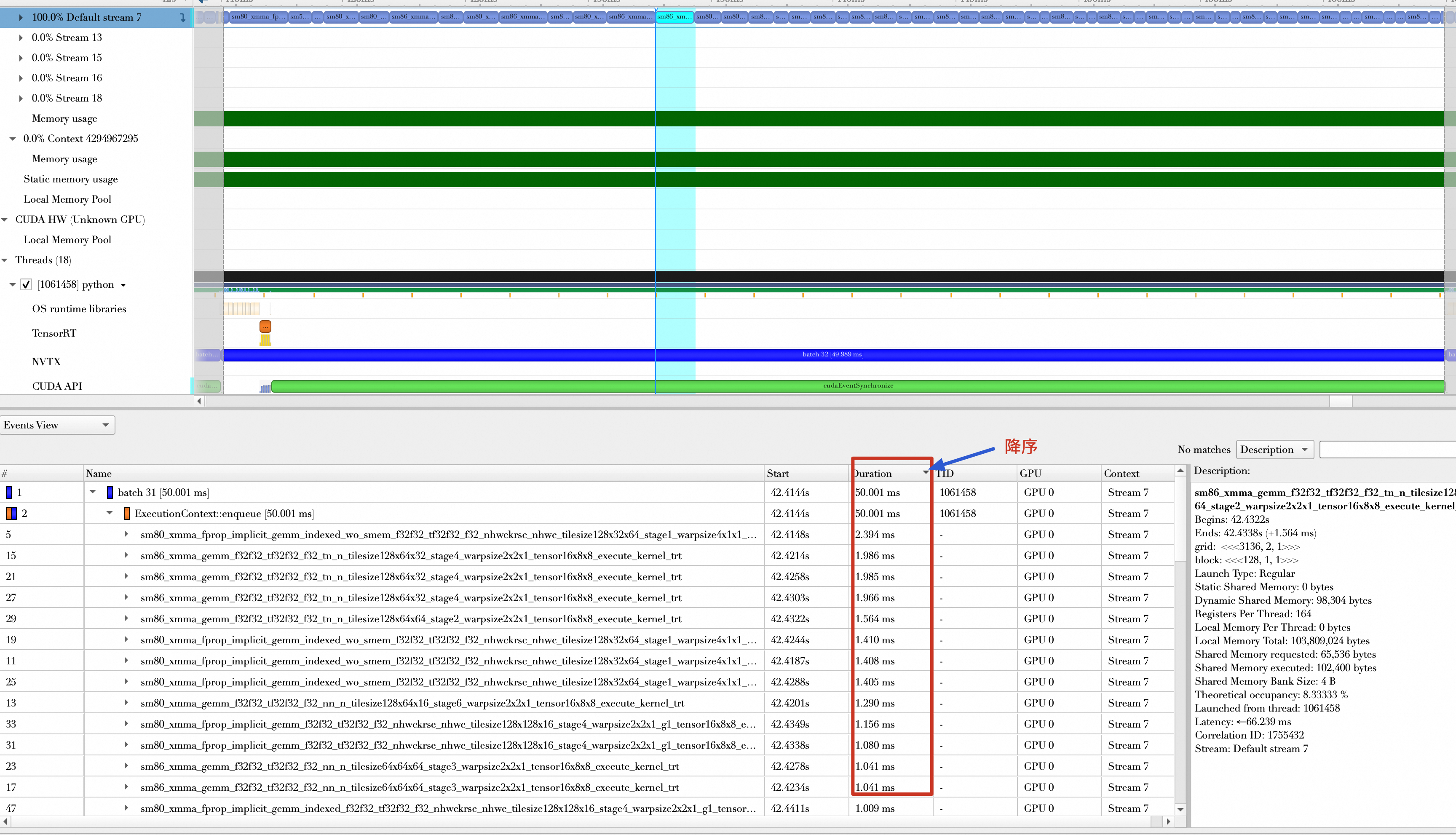
进入一个Batch的forward和Backward,观察其Kernel函数的组成,发现开启AMP之前,操作的数据类型基本都是float32,并且将Kernel函数执行时间按降序排列,执行时间靠前的如下所示,从300μs到1ms不等。
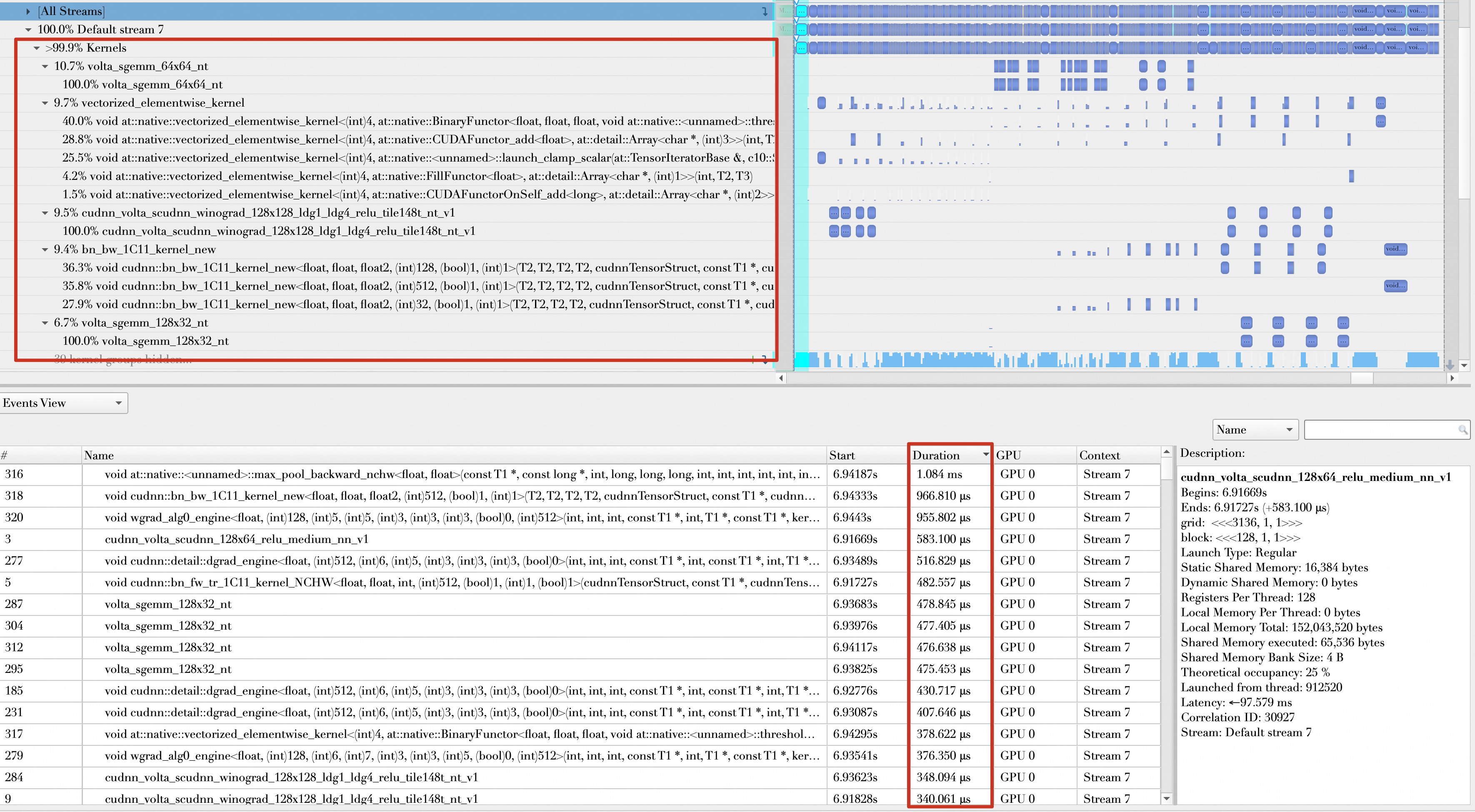
开启AMP以后,大多数操作的数据类型都是float16,且执行时间靠前的Kernel基本都在100μs到300μs之间。

优化方向5:增大Batch Size
增大Batch Size也能够提升每秒处理样本数,但是增大Batch Size需要考虑显存的使用情况(显存是否够用)和大Batch Size对Loss值的影响。
修改如下代码,尝试将Batch Size从32调整至512。
train_loader = torch.utils.data.DataLoader(train_set,num_workers=8, batch_size=512,pin_memory=True, shuffle=True)运行代码,结果如下。总的持续时间为:697.666 ms,平均每秒处理样本数(samples/s)为:512 × 3 /(697.666 / 1000)= 2201.627。性能提升(2201.627 - 1628.83)/ 1628.83 × 100% = 35.17%。

优化方向6:模型编译
默认情况下,PyTorch采用的是即时编译,您可以借助PyTorch的编译API将模型编译成图模式(Graph Mode)。
修改如下代码:
model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)
model = torch.compile(model)运行代码,结果显示如下。总的持续时间为:567.971 ms,平均每秒处理的样本数为:512 × 3 /(567.971 / 1000)= 2704.36,性能提升(2704.36 - 2201.627)/ 2201.627 × 100% = 22.83%。
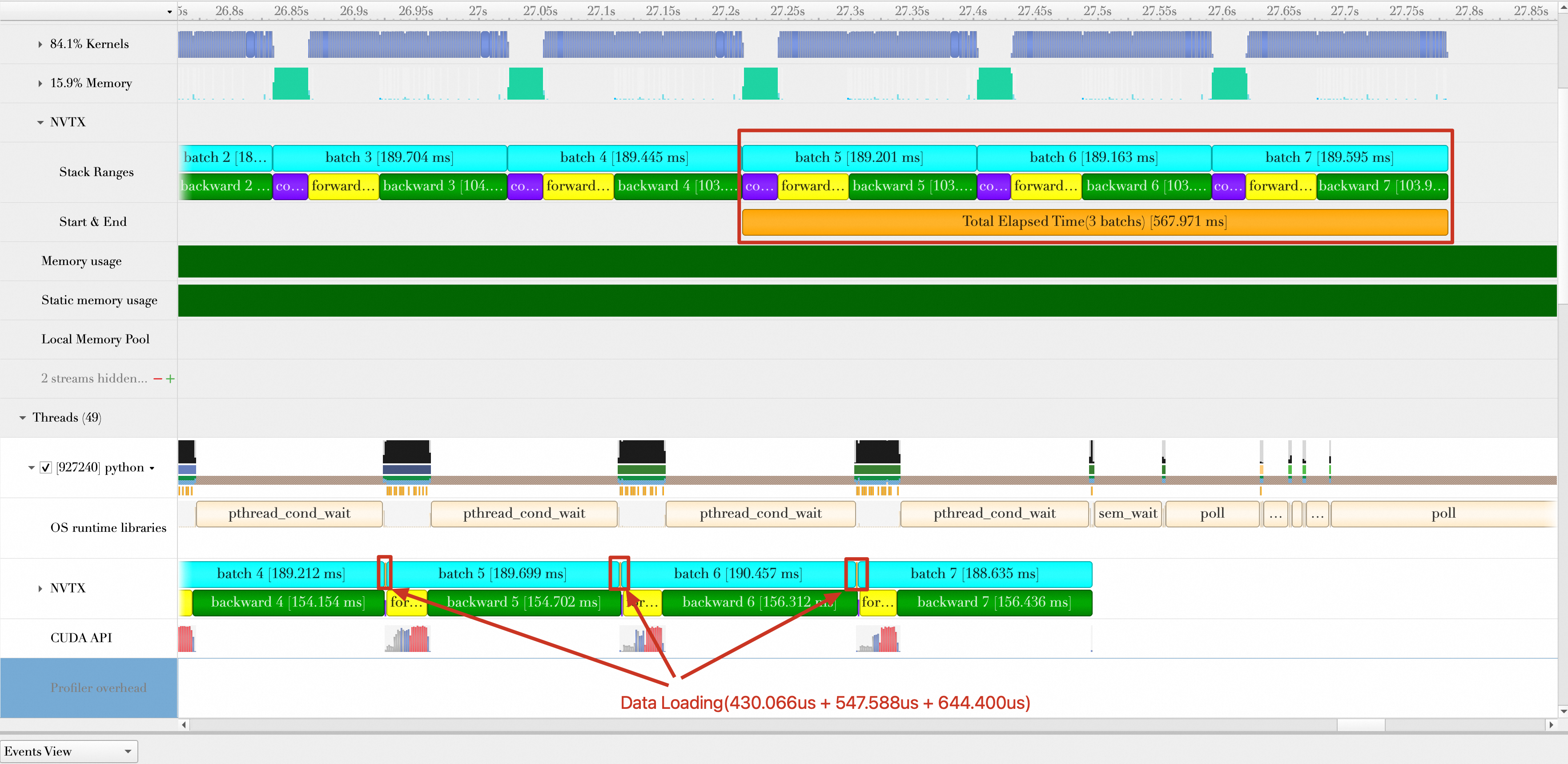
需要注意的是,模型编译这个优化选项在小Batch场景下不一定有效果。
优化方向7:Batch传输与Batch计算重叠
由于Batch传输和Batch计算是串行执行的,即Batch传输完成,才能执行Batch计算。而Batch传输时,GPU是处于空闲状态;当Batch Size变大时,Batch传输时间相比Batch计算已不可忽略的。

按照一般的思维,要计算Batch,只有当Batch传输到GPU后,才能开始计算,如果传输没有完成就开始计算,结果就不是正确的。如果以流水线思维思考,假设Batch计算的时间比Batch传输的时间长,那么如果GPU在计算第一个Batch的同时,第二个Batch也开始传输,等GPU计算第二个Batch的同时,第三个Batch传输也在进行,那么就将Batch传输的时间隐藏在Batch的计算中了。
在单个Stream中无法完成上述的重叠操作,不过PyTorch允许创建多个Stream,除了默认的Stream外,可以额外创建一个Stream。完整代码如下:
import nvtx # 引入nvtx包
import torch
import torch.nn
import torch.optim
import torch.profiler
import torch.utils.data
import torchvision.datasets
import torchvision.models
import torchvision.transforms as T
transform = T.Compose([
T.Resize(224),
T.ToTensor(),
T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_set = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, num_workers=8, batch_size=512, pin_memory=True, shuffle=True)
device = torch.device("cuda:0")
model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)
model = torch.compile(model)
criterion = torch.nn.CrossEntropyLoss().cuda(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
def train(model, device, train_loader, optimizer, criterion):
model.train()
dl = iter(train_loader)
transfered_data = []
# 创建一个新的stream
s = torch.cuda.Stream()
def prepare_batch(batch_idx):
nvtx.push_range("__next__ " + str(batch_idx), color="orange")
(inputs, labels) = next(dl)
# 传输数据在新的stream中进行
nvtx.pop_range()
nvtx.push_range("cpy " + str(batch_idx), color="rapids")
with torch.cuda.stream(s):
inputs, labels = inputs.to(device=device, non_blocking=True), labels.to(device=device, non_blocking=True)
nvtx.pop_range()
return (inputs, labels)
def batch_compute(batch_idx, data):
nvtx.push_range("batch " + str(batch_idx), color="cyan")
nvtx.push_range("forward " + str(batch_idx), color="yellow")
with torch.autocast(device_type='cuda', dtype=torch.float16):
outputs = model(data[0])
loss = criterion(outputs, data[1])
nvtx.pop_range()
nvtx.push_range("backward " + str(batch_idx), color="green")
optimizer.zero_grad()
loss.backward()
optimizer.step()
nvtx.pop_range()
torch.cuda.current_stream().wait_stream(s)
nvtx.pop_range()
batch_idx = 0
tet = None
while True:
try:
if batch_idx == 6:
tet = nvtx.start_range(message="Total Elapsed Time(3 batchs)", color="orange")
if batch_idx >= 8:
break
data = prepare_batch(batch_idx)
transfered_data.append(data)
# 当batch_idx为0时,不执行计算操作
# 每一个循环都需要让默认的stream等待新创建的stream传输数据完成,确保下一轮
# Batch计算所需数据能够准备完成。
if batch_idx > 0:
batch_compute(batch_idx - 1, transfered_data[batch_idx - 1])
else:
torch.cuda.current_stream().wait_stream(s)
batch_idx += 1
except StopIteration:
nvtx.pop_range()
break
batch_compute(batch_idx - 1, transfered_data[batch_idx - 1])
nvtx.end_range(tet)
train(model, device, train_loader, optimizer, criterion)
运行代码,结果展示如下。图中展示了Batch2到Batch7的传输操作隐藏在了Batch1到Batch4的计算中(Batch0和Batch1的传输未展示,页面有限)。同时可以确认的是,每个Batch在计算之前,其数据都已经传输完成。例如,Batch4计算时,Batch4的传输已经隐藏在Batch2的计算中。因此,可以确保计算结果的正确性。

总的持续时间为484.016 ms,平均每秒处理样本数为:512 × 3 ÷ (484.016 ÷ 1000) = 3173.449,性能提升(3173.449 - 2704.36)÷ 2704.36 × 100% = 17.35%。
需要注意的是,虽然将数据传输隐藏在数据计算中,但是会额外增加GPU内存的使用,以上面为例,当计算Batch5时,所有的Batch都驻留在了GPU内存中。
总结
对各个优化项性能提升做一个总结。
阶段 | 平均每秒处理样本数(samples/s) | 性能相比前一个优化项提升百分比 |
未优化:Baseline | 542.746 | - |
优化1:Data Loader worker设置为8 | 797.819 | 47.00% |
优化2:开启Pin Memory | 964.485 | 20.89% |
优化3:数据加载与Batch计算完全重叠 | 1019.498 | 5.7% |
优化4:自动混合精度 | 1628.83 | 59.77% |
优化5:增大Batch Size | 2201.627 | 35.17% |
优化6:模型编译 | 2704.36 | 22.83% |
优化7:Batch传输与Batch计算重叠 | 3173.449 | 17.35% |
推理场景
目前,有很多推理框架都支持对模型的优化,本节以TensorRT中优化ResNet-50为例,演示如何在推理场景中使用Nsight Systems进行性能分析。
步骤一:创建示例模型
在PyTorch容器内部,创建并拷贝以下内容到main.py文件中。
main.py文件中集成了PyTorch模型与TensorRT以加速推理过程,同时提供了基本的模型加载、预测和性能评估功能。
对于这个脚本,有一点需要注意,加载模型路径为当前路径下的model/vision-v0.10.0。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import argparse
import torch
import torchvision
from PIL import Image
import matplotlib.pyplot as plt
import json
from torchvision import models as M
from torchvision import transforms
import numpy as np
import time
import torch.backends.cudnn as cudnn
import torch_tensorrt
import nvtx
cudnn.benchmark = True
def load_model():
torch.hub._validate_not_a_forked_repo=lambda a,b,c: True
weights=M.ResNet50_Weights.IMAGENET1K_V1
#resnet50_model = torch.hub.load('pytorch/vision:v0.10.0', 'resnet50',force_reload=True,skip_validation=True, weights=weights)
resnet50_model = torch.hub.load('model/vision-v0.10.0', 'resnet50',source='local', weights=weights)
resnet50_model.load_state_dict(torch.load('./resnet50-0676ba61.pth'))
return resnet50_model
def rn50_preprocess():
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
return preprocess
def load_labels():
# loading labels
with open("./data/imagenet_class_index.json") as json_file:
d = json.load(json_file)
# decode the results into ([predicted class, description], probability)
def predict(img_path, model,labels):
model.eval()
img = Image.open(img_path)
preprocess = rn50_preprocess()
input_tensor = preprocess(img)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Tensor of shape 1000, with confidence scores over Imagenet's 1000 classes
sm_output = torch.nn.functional.softmax(output[0], dim=0)
ind = torch.argmax(sm_output)
return labels[str(ind.item())], sm_output[ind] #([predicted class, description], probability)
def benchmark(model, input_shape=(1024, 1, 224, 224), dtype='fp32', nwarmup=50, nruns=10000):
model.eval()
input_data = torch.randn(input_shape)
input_data = input_data.to("cuda")
if dtype=='fp16':
input_data = input_data.half()
print("Warm up ...")
with torch.no_grad():
for _ in range(nwarmup):
features = model(input_data)
torch.cuda.synchronize()
print("Start timing ...")
timings = []
e = torch.cuda.Event(enable_timing=False)
with torch.no_grad():
for i in range(1, nruns+1):
start_time = time.time()
nvtx.push_range("batch " + str(i),"blue")
e.record()
features = model(input_data)
e.synchronize()
nvtx.pop_range()
end_time = time.time()
timings.append(end_time - start_time)
if i%10==0:
print('Iteration %d/%d, ave batch time %.2f ms'%(i, nruns, np.mean(timings)*1000))
print("Input shape:", input_data.size())
print("Output features size:", features.size())
print('Average batch time: %.2f ms'%(np.mean(timings)*1000))
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch RESNET Example')
parser.add_argument('--enable-tensorrt', action='store_true', default=False,
help='Enable tensorrt to optimize model')
parser.add_argument('--precision', type=str, default='fp32', metavar='N',
help='specify the precision when tensorrt is enabled,value in [fp32,fp16] (default: fp32)')
args = parser.parse_args()
model = load_model()
model = model.eval().to("cuda")
optimized_model = model
dtype = "fp32"
if args.enable_tensorrt:
if args.precision == "fp32":
optimized_model = torch_tensorrt.compile(
model, inputs = [torch_tensorrt.Input((128, 3, 224, 224), dtype=torch.float32)],
enabled_precisions = torch.float32, # Run with FP32
workspace_size = 1 << 22,
)
elif args.precision == "fp16":
optimized_model = torch_tensorrt.compile(
model, inputs = [torch_tensorrt.Input((128, 3, 224, 224), dtype=torch.half)],
enabled_precisions = {torch.half}, # Run with FP16
workspace_size = 1 << 22
)
dtype = "fp16"
benchmark(optimized_model, input_shape=(128, 3, 224, 224),dtype=dtype, nruns=100)
if __name__ == '__main__':
main()步骤二:生成Profiling报告
分别生成以下三种场景的Profiling报告,然后通过生成的Nsight Systems报告文件比较模型优化效果。
未对模型做任何优化 | 使用TensorRT对模型做优化,没有开启量化操作 | 使用TensorRT对模型做优化,同时开启量化操作 |
执行以下命令,生成Nsight Systems报告文件。 | 使用TensorRT对模型做优化,但是没有开启量化操作,也就是说模型的权重和激活函数的精度仍然使用FP32。 执行以下命令,生成Nsight Systems报告文件。 | 使用TensorRT对模型做优化,同时开启量化操作,也就是模型的权重和激活函数的精度使用FP16。 执行以下命令,生成Nsight Systems报告文件。 |
上述三个命令运行完成后,会在当前目录分别生成三个Nsight Systems报告文件:
resnet-50-none-tensorrt.nsys-rep
resnet-50-tensorrt-fp32.nsys-rep
resnet-50-tensorrt-fp16.nsys-rep将这三个文件导入Nsight System UI中,就可以开始Profiling了。
步骤三:查看Profiling报告
查看和分析Profiling报告前,需要明确TensorRT做了哪些优化工作,从TensorRT的官方文档可以了解到TensorRT具备如下能力:
层间融合或张量融合(Layer & Tensor Fusion):一次推理过程中,需要在GPU上启动许多的核函数(Kernel),这些核函数运行时间基本都很短,但是启动每一个Kernel也需要花费很多时间,如果有大量的Kernel需要完成计算,那么可能导致大量的时间都花在了启动核函数(Launch Kernel)上,为了解决这个问题,可以将多个核函数融合成一个。
数据精度校准(Weight &Activation Precision Calibration):大部分深度学习框架在训练神经网络时网络中的张量(Tensor)都是32位浮点数的精度(FP32),TensorRT能够自动将某些张量的FP32精度数值转化为FP16、INT8,以此减少GPU内存使用和计算时间,同时最小化性能损失。
Kernel Auto-Tuning:启动核函数时,能够自动计算每个Grid、Block的尺寸,最大化GPU SM占用率。
Dynamic Tensor Memory:在每个Tensor的使用期间,TensorRT会为其指定显存,避免显存重复申请,减少内存占用并提高重复使用效率。
Multi-Stream Execution:启动多个CUDA Stream来并发执行任务。
接下来就从Nsight System UI中观察TensorRT支持的这些能力。
层间融合或张量融合(Layer & Tensor Fusion)
现在看看执行每个Batch计算时,启动了多少次核函数。
未对模型做任何优化 | 使用TensorRT对模型做优化,没有开启量化操作 | 使用TensorRT对模型做优化,同时开启量化操作 |
|
|
|
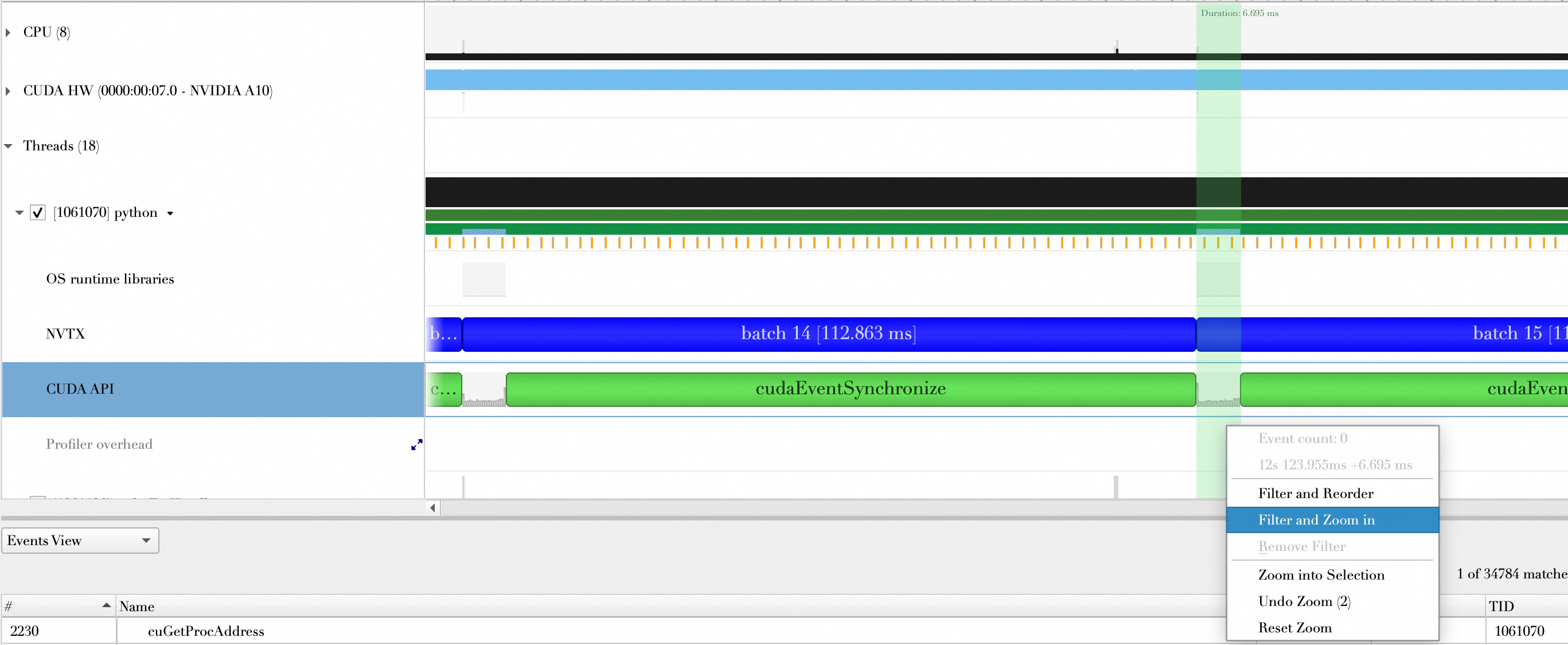

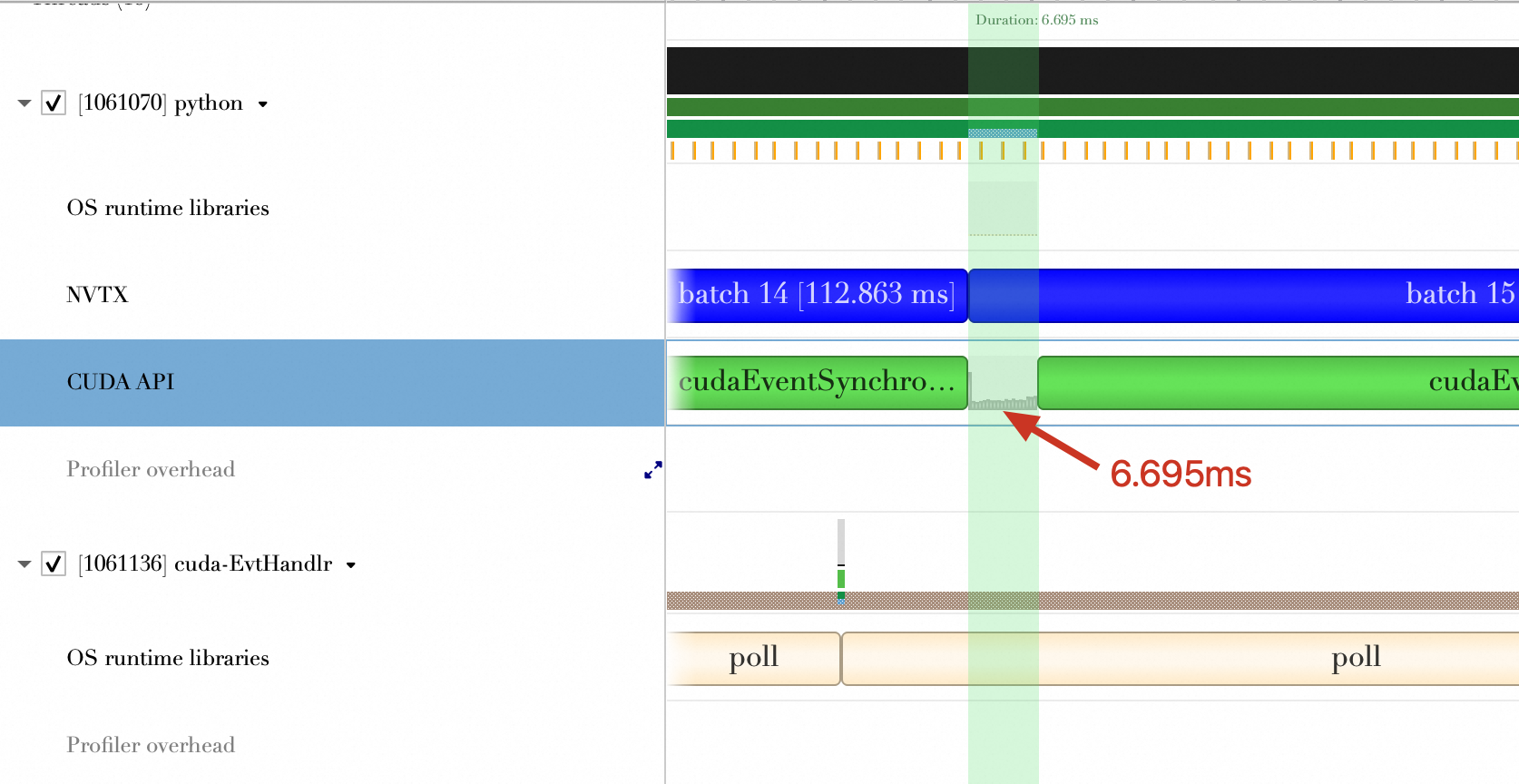

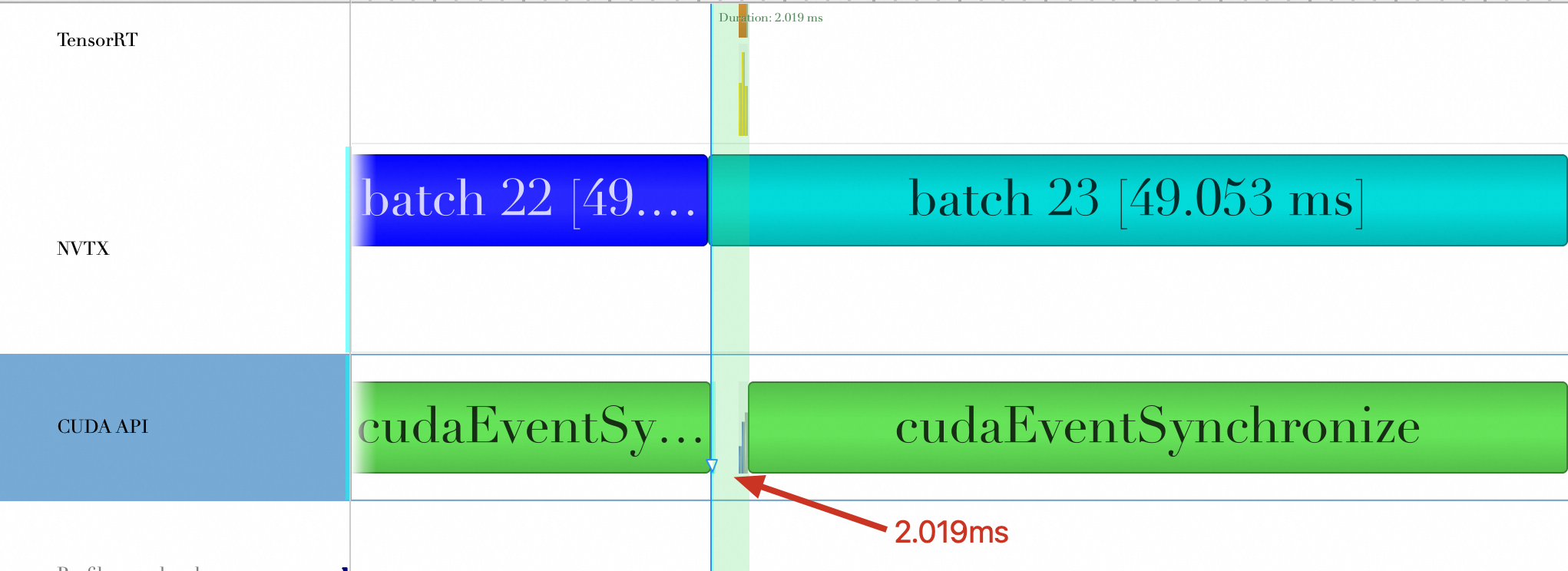


结论
对比项 | 未使用TensorRT | 使用TensorRT(未开启量化) | 使用TensorRT(开启量化) |
一次Batch计算Kernel Launch次数 | 233 | 57 | 59 |
一次Batch计算Kernel Launch和CUDA API调用花费时间(ms) | 6.695 ms | 2.019 ms | 2.405 ms |
开启量化的情况下,CUDA Kernel执行时间有可能变长,这是因为存在数据类型转换操作。
所以,TensorRT进行层间融合或张量融合后,缩短了Kernel Launch次数以及Kernel Launch和CUDA API调用所花费时间。
数据精度校准(量化)
接下来利用Nsight System UI对比量化前和量化后效果。
未对模型做任何优化 | 使用TensorRT对模型做优化,没有开启量化操作 | 使用TensorRT对模型做优化,同时开启量化操作 |
|
|
|
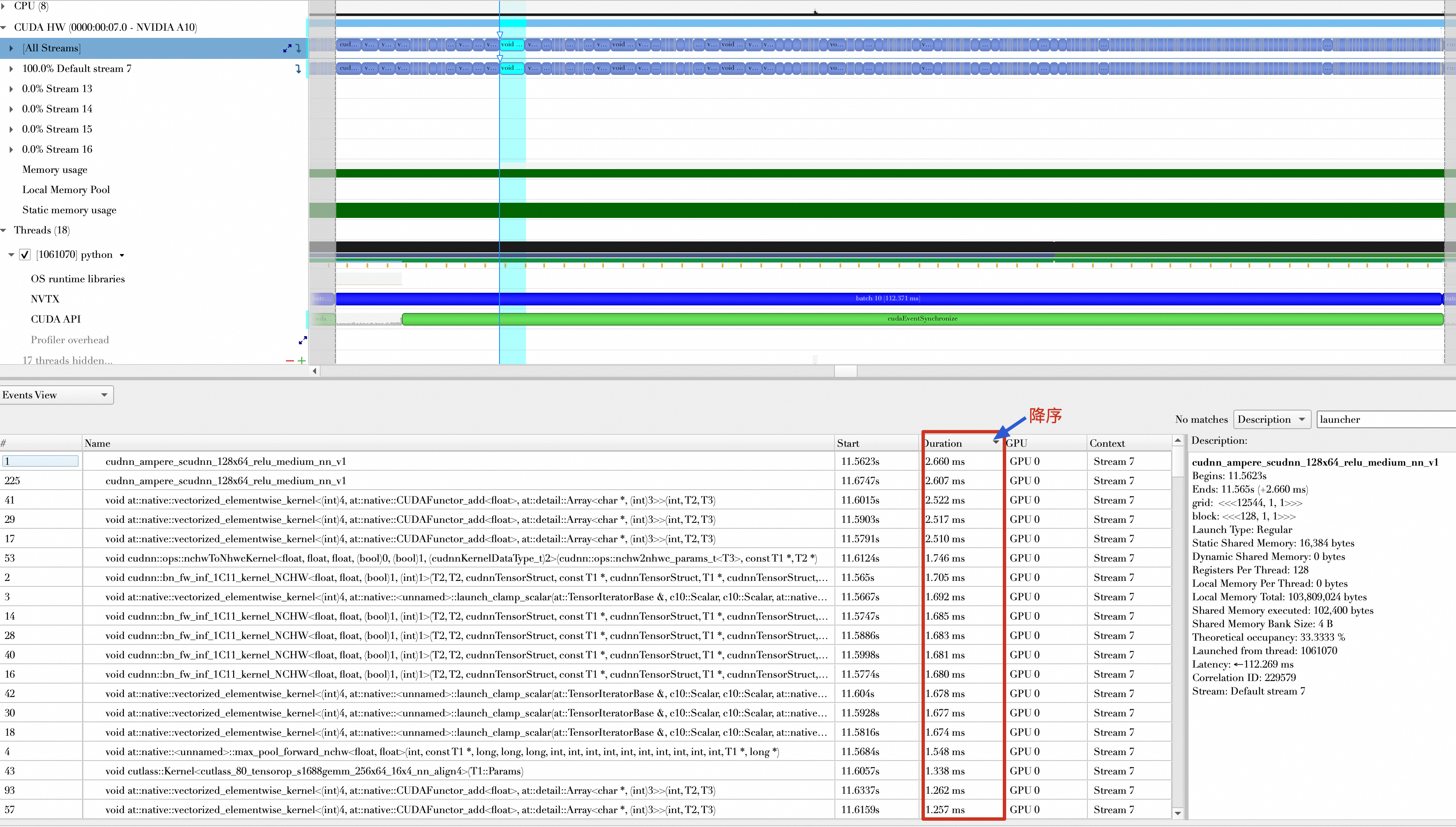


结论
对比项 | 未对模型做优化 | 使用TensorRT(未开启量化) | 使用TensorRT(开启量化) |
运行时长Top15函数平均耗时 | 1.98 ms | 1.51 ms | 772.76 us |
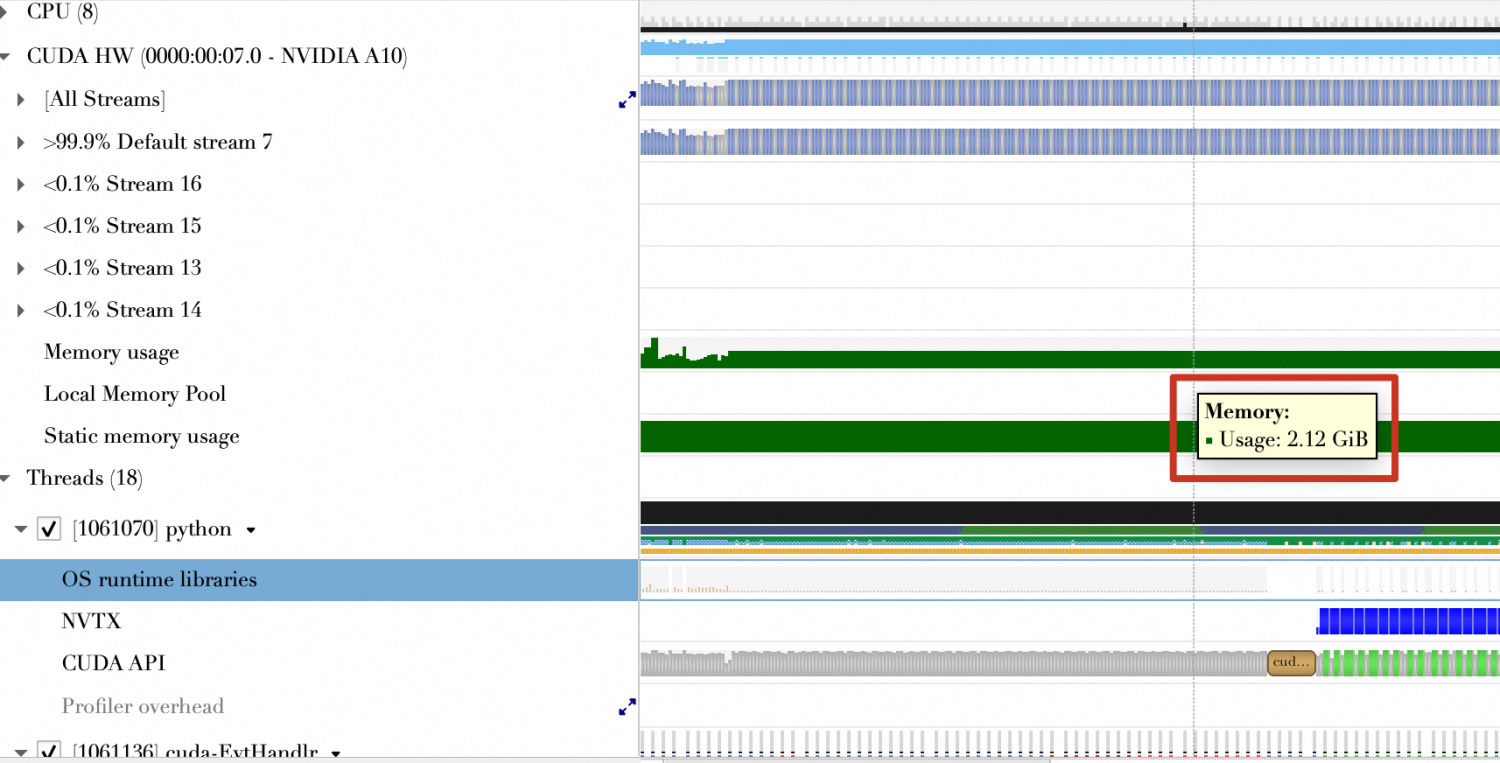
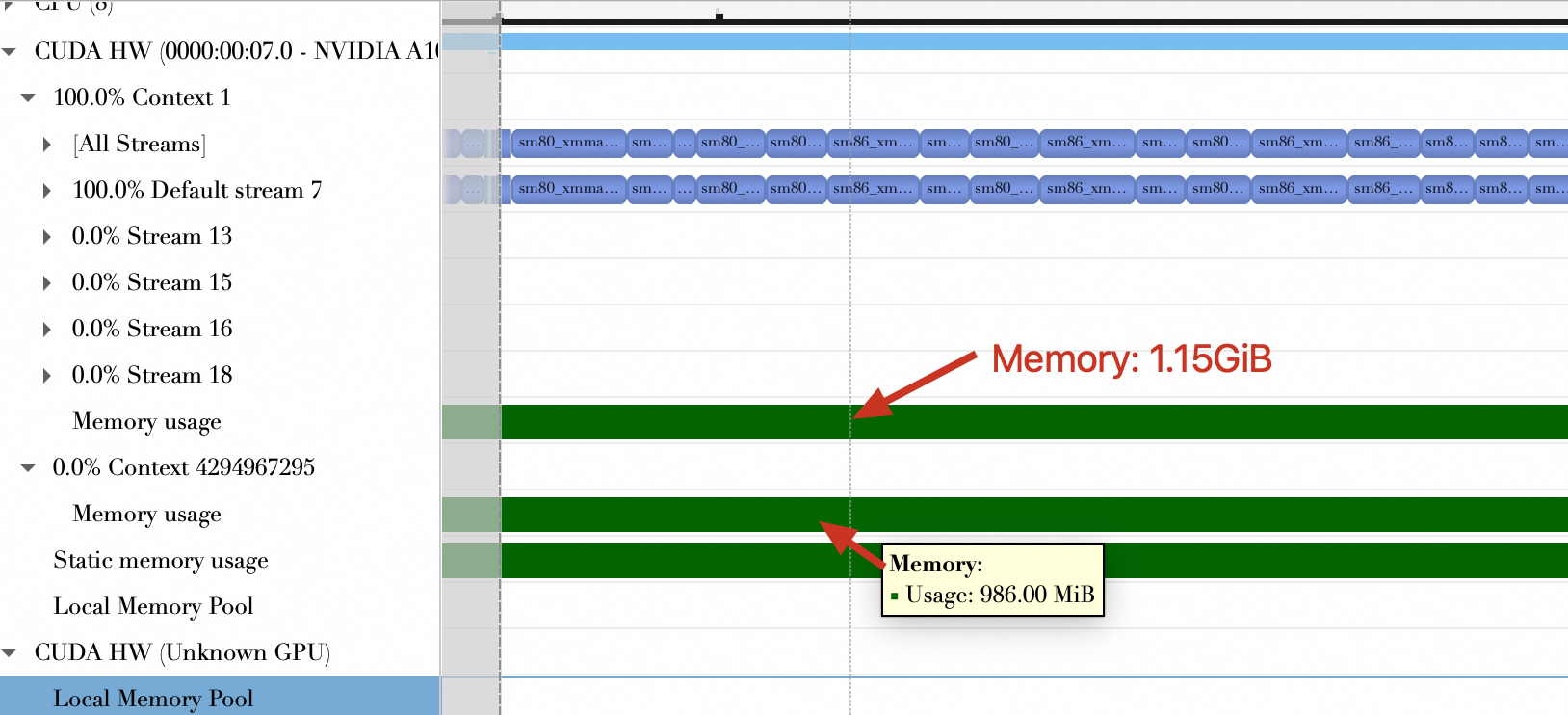
内存使用(GiB) | 2.12 GiB | 2.13 GiB | 1.65 GiB |
可以看到,量化后的核函数计算时间缩短,使用的GPU内存更少。
Dynamic Tensor Memory
未对模型做任何优化 | 使用TensorRT对模型做优化,没有开启量化操作 | 使用TensorRT对模型做优化,同时开启量化操作 |
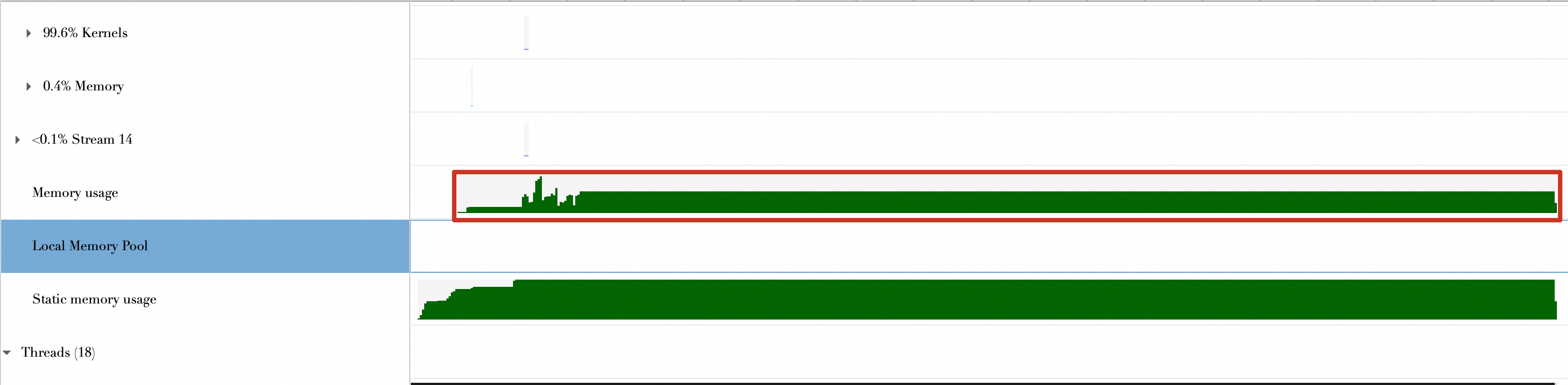
程序整个运行期间的内存使用情况如下,可以看到,程序整个生命周期里,内存的申请基本没有变化。
| 程序整个运行期间的内存使用情况如下,可以看到,程序整个生命周期里,内存的申请呈现阶梯状,说明是动态按需申请。
| - |

Multi-Stream Execution
未对模型做任何优化 | 使用TensorRT对模型做优化,没有开启量化操作 | 使用TensorRT对模型做优化,同时开启量化操作 |
从下面的图中可以看到,使用了5个CUDA Stream。
| 从下面的图可以看到,使用了5个CUDA Streams。
| 从下面的图可以看到,使用了7个CUDA Streams。
|



结论
TensorRT能够支持动态多Stream创建,但是目前不清楚是否只有在开启量化的情况下才支持动态多Stream创建。
迁移场景
目前PyTorch、TensorFlow本身支持感知运行环境,一个应用(不管是推理服务还是训练任务),不做任何更改,就能直接从CPU迁移到GPU上运行,如果有GPU就用GPU计算、没有GPU就用CPU计算。但在实际的场景经常会碰到业务从CPU迁移到GPU上运行,为什么执行速度还是很慢?
这是由于代码开发时并未预见到需要将更多计算任务分配给GPU,导致该应用程序在从CPU迁移至GPU运行后,GPU利用率偏低,大部分计算任务仍旧依赖于CPU,使得GPU大部分时间处于闲置状态。
所以在迁移场景中,最佳实践是利用Nsight Systems和Nsight Compute对应用做Profiling,观察是否存在可优化的地方,优化完成后再在新的环境下运行。
FAQ
问题1:缩短数据传输(Data Transmission)时间,为什么建议使用Pin Memory?
默认情况下,分配的主机内存是可分页的(Pageable),也就是说,受页面错误(Page Fault)操作的影响,这些操作会根据操作系统指示将主机虚拟内存中的数据移动到不同的物理位置。
GPU无法安全地访问可分页主机内存中的数据,因为它无法控制主机操作系统何时选择移动该数据。在将数据从可分页的主机(Host)内存传输到设备(Device)内存时,CUDA驱动首先分配临时锁定(Page-Locked)的页面(或者称为固定主机内存,Pinned Memory),将源数据从可分页内存传输到Pinned Memory。然后从Pinned Memory中传输数据到Device Memory中。如果直接使用Pinned Memory,就减少了数据从Pageable Memory到Pinned Memory的复制,节约了时间。
问题2:Batch加载与Batch计算重叠是怎么做到的?
首先要理解的是,CUDA体系中引入了一种称为Stream的构造,它工作原理近似于先进先出(FIFO)队列,但与之不同的是,此队列处理的对象是CUDA操作序列。所谓CUDA操作,涵盖了如将数据从主机内存传输至GPU内存的任务,GPU上函数的触发执行,或是反向的数据迁移等。这些操作严格按照它们进入Stream的顺序执行,确立了清晰的执行时序。
进而,CUDA操作与CPU进程的交互可被划分为同步与异步两大类,其区别如下:
同步操作:这如同CPU进程在操作前设立的一道“关卡”。一旦遭遇同步操作,CPU进程便暂停脚步,直至该操作圆满结束。换言之,CPU不仅将此操作安置于Stream队列末尾,并且暂时封锁队列入口,静候该操作执行完毕才重新开放。因此,同步操作的耗时受队列中待处理任务数量的影响,时长可变,不确定性大。
异步操作:与之相对,异步操作显得更为流畅。CPU进程在“投放”此操作入Stream队列后,即刻抽身继续其他任务,无需驻足等待。这意味着操作的加入不构成CPU进程的直接等待点。
最后,提及PyTorch实践中的一个重要细节:针对CUDA操作,默认配置下PyTorch会自动创建并使用一个Stream,即所谓的默认Stream,作为操作执行的默认通道,这是您进行GPU加速计算时不可忽视的环境设定。