在生产环境中LLM推理服务的可观测性是至关重要的,可以监控LLM推理服务、推理服务Pod及相关GPU的性能指标,有效发现性能瓶颈,帮助定位故障。本文介绍如何为LLM推理服务配置监控。
前提条件
已为ACK开启阿里云Prometheus监控。具体操作,请参考使用阿里云Prometheus监控。
计费说明
LLM推理服务将监控数据接入阿里云Prometheus监控功能后,相关组件会自动将监控指标发送至阿里云Prometheus服务,这些指标将被视为自定义指标。
使用自定义指标会产生额外的费用。这些费用将根据您的集群规模、应用数量和数据量等因素产生变动,您可以通过用量查询,监控和管理您的资源使用情况。
步骤一:接入LLM推理服务监控大盘
登录ARMS控制台。
在左侧导航栏单击接入中心,然后在人工智能区域单击云原生AI套件-LLM推理服务卡片。
在云原生AI套件-LLM推理服务页面的选择容器服务集群区域,选择目标集群。
若显示已经安装该组件,则无需再重复安装。
在配置信息区域配置参数,然后单击确定,完成组件接入。
配置项
说明
接入名称
当前LLM推理服务监控唯一名称。非必填,可留空。
命名空间
当前LLM推理服务监控仅采集哪些命名空间下的指标。非必填,留空时表示采集所有命名空间下满足条件。
Pod 端口名
LLM推理服务Pod上标识的端口名,将尝试从该端口上采集推理服务监控指标。默认值为"http"。
指标采集路径
LLM推理服务Pod暴露Prometheus格式指标的HTTP服务路径。默认值为“/metrics”。
metrics采集间隔
监控数据采集时间间隔(秒)。
已接入的组件可在ARMS控制台的接入管理页面查看。
接入中心的更多信息,请参见接入指南。
步骤二:部署推理服务并开启指标采集
在需要采集指标的LLM推理服务Pod上增加以下标签,将该推理服务Pod加入到ARMS指标采集目标列表中:
...
spec:
template:
metadata:
labels:
alibabacloud.com/inference-workload: <workload_name>
alibabacloud.com/inference-backend: <backend>变量 | 用途 | 说明 |
<workload_name> | 用于唯一标识一个命名空间下的一个推理服务。 | 推荐选择部署推理服务时使用的工作负载(例如:StatefulSet、LeaderWorkerSet、RoleBasedGroup)的名字作为<workload_name>。当Pod包含 |
<backend> | 用于标识推理引擎。 | 需要根据实际使用的推理引擎填写。目前该字段支持的值包括:
|
上述示例仅展示了为LLM推理服务Pod开启指标采集时的部分代码片段,如果需要了解如何部署不同的LLM推理服务的完整示例,请参见:
步骤三:查看推理服务监控大盘
登录容器服务管理控制台,在左侧导航栏单击集群。
在集群列表页面,单击已接入云原生AI套件-LLM推理服务组件的ACK集群或ACS集群,然后在左侧导航栏,选择运维管理 > Prometheus 监控。
在Prometheus监控页面,选择其他 > LLM Inference Dashboard,查看LLM推理服务监控大盘的详情数据。在LLM推理服务监控大盘中,您可以查看有关集群中运行的LLM推理服务的详情数据。
调整监控大盘的变量,可以选择需要查看的LLM推理服务的命名空间(
namespace)、负载名称(workload_name)和该推理服务使用的模型名称(model_name)。如果需要了解大盘中各个Panel的含义,请参考监控面板说明。
监控指标说明
LLM推理服务采集的指标主要包括:
监控面板说明
LLM推理服务监控大盘假设用户使用一个Kubernetes工作负载(workload)部署一个推理服务,一个推理服务中包含多个推理服务实例(一个实例可能由一个Pod或多个Pod构成),一个推理服务实例同时可对外提供一个模型或多个模型(例如:基于基础模型+Lora的组合模型)的LLM推理能力。
因此,如果需要对某个推理服务上特定模型的推理表现进行监控,需要选择推理服务所在的命名空间(namespace),接着选择工作负载名字(workload_name),最后选择模型名(model_name)。选择完成后,监控大盘数据将会自动更新,展示指定时间段内推理服务的性能指标。
LLM推理服务监控大盘包含3个Panel组:
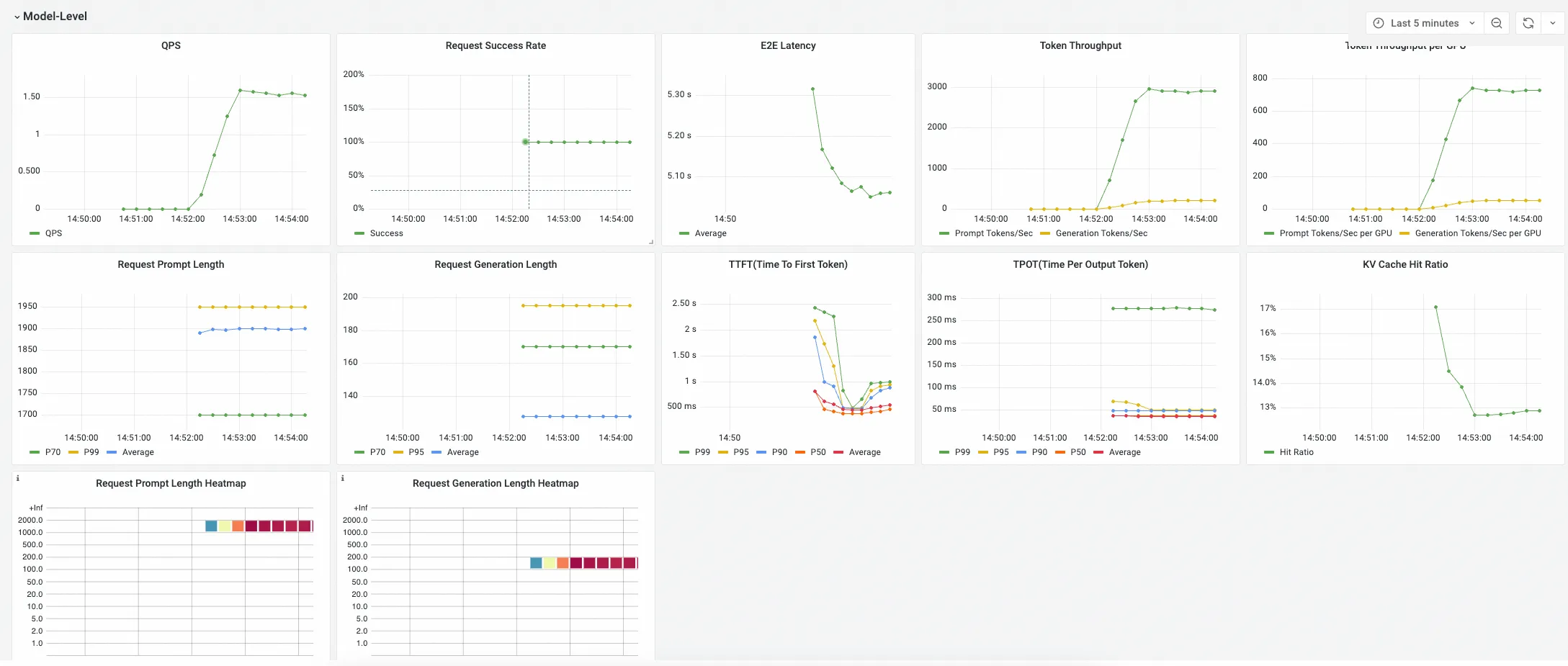
Model-Level Panel
该组下Panel展示某个模型对应的推理服务聚合指标,这些指标用于从整体上判断一个推理服务的性能是否满足业务预期。
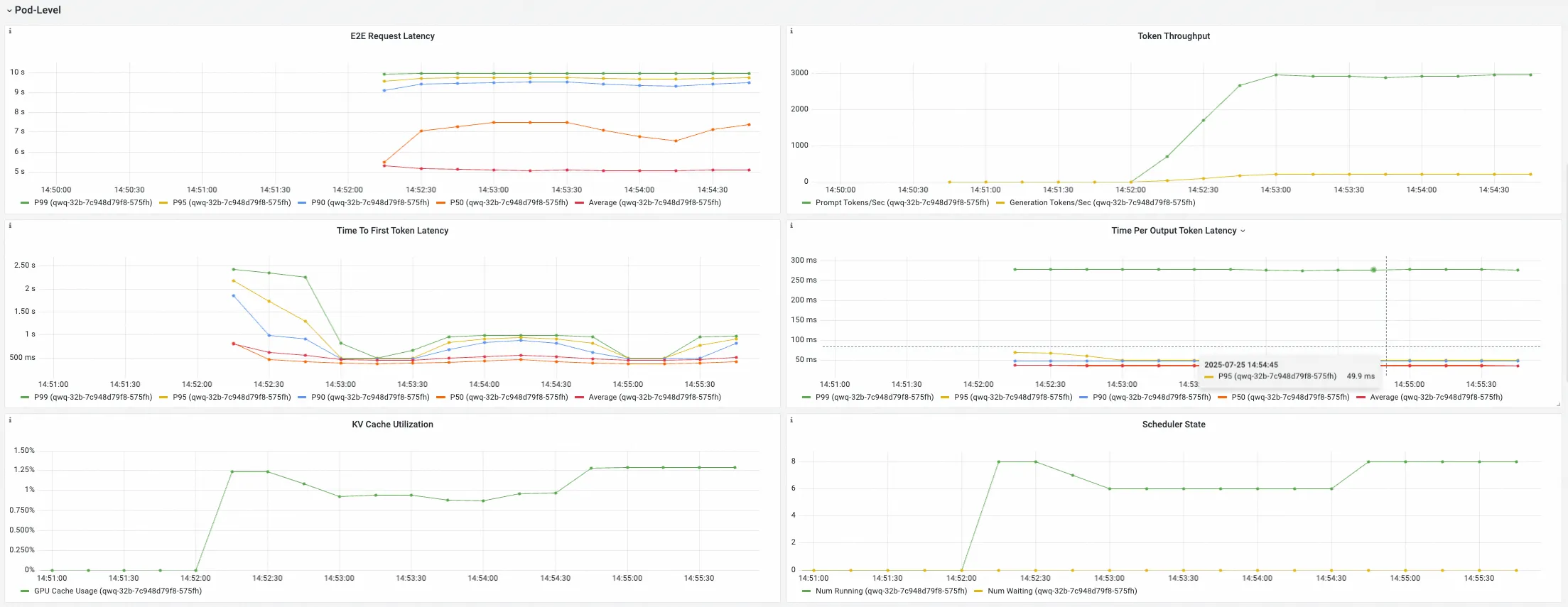
Pod-Level Pane
该组下Panel展示选择的推理服务下各个Pod的推理服务指标,这些指标用于细化了解不同推理服务实例的负载均衡情况。
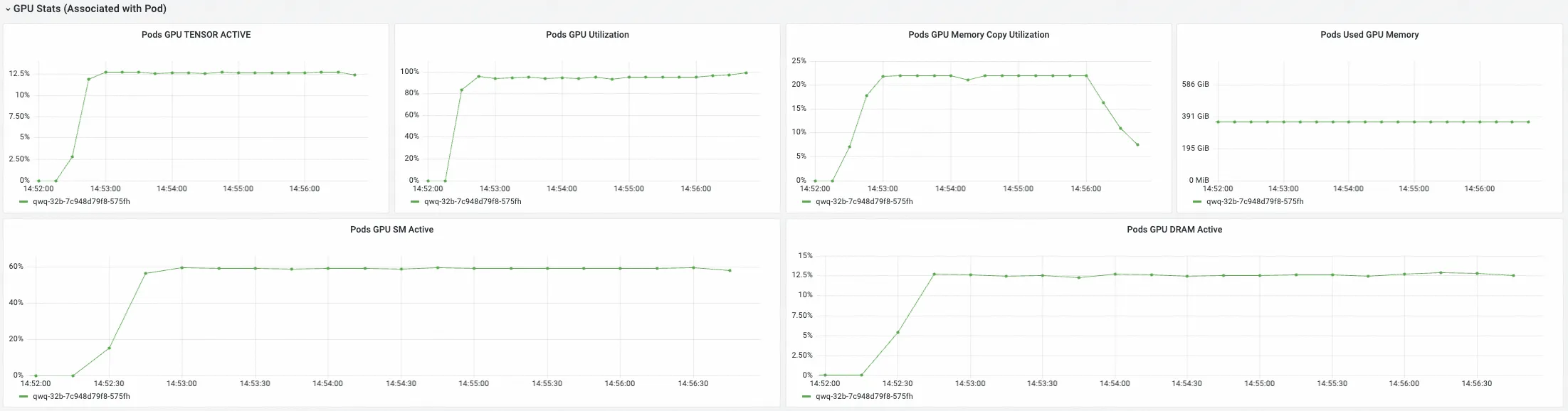
GPU Stats (Associated with Pod)
该组下Panel展示选择的推理服务下各个Pod的GPU指标,这些指标用于了解各个推理服务Pod对GPU资源的使用情况。