
本文以Qwen3-32B模型为例,演示如何在ACK中部署SGLang PD分离推理引擎的模型推理服务。
背景知识
Qwen3-32B
Qwen3-32B 是通义千问系列最新一代的大型语言模型,基于328亿参数的密集模型架构,兼具卓越的推理能力与高效的对话性能。其最大特色在于支持思考模式与非思考模式的无缝切换。在复杂逻辑推理、数学计算和代码生成任务中表现出众,而在日常对话场景下也可高效响应。模型具备出色的指令遵循、多轮对话、角色扮演和创意写作能力,并在Agent任务中实现领先的工具调用表现。原生支持32K上下文,结合YaRN技术可扩展至131K。同时,支持100多种语言,具备强大的多语言理解与翻译能力,适用于全球化应用场景。有关更多详细信息,请参阅博客、GitHub和文档。
SGLang
SGLang 是一个高性能的大型语言模型与多模态模型服务推理引擎,通过前后端协同设计,提升模型交互速度与控制能力。其后端支持 RadixAttention(前缀缓存)、零开销 CPU 调度、PD分离、Speculative decoding、连续批处理、PagedAttention、TP/DP/PP/EP并行、结构化输出、chunked prefill及多种量化技术(FP8/INT4/AWQ/GPTQ)和多LoRA批处理,显著提升推理效率。前端提供灵活编程接口,支持链式生成、高级提示、控制流、多模态输入、并行处理和外部交互,便于构建复杂应用。支持 Qwen、DeepSeek、Llama等生成模型,E5-Mistral等嵌入模型以及 Skywork 等奖励模型,易于扩展新模型。更多关于SGLang推理引擎的信息,请参见SGLang GitHub。
PD分离
Prefill/Decode分离架构,是当前主流的LLM推理优化技术,旨在解决推理过程中两个核心阶段的资源需求冲突问题。LLM的推理过程可分为两个阶段:
Prefill (提示词处理) 阶段:此阶段一次性处理用户输入的全部提示词(Prompt),并行计算所有输入Token的注意力,并生成初始的KV缓存。这个过程是计算密集型(Compute-Bound)的,需要强大的并行计算能力,但只在请求开始时执行一次。
Decode (解码生成) 阶段:此阶段是自回归过程,模型根据已有的KV缓存,逐个生成新的Token。每一步的计算量很小,但需要反复、快速地从显存中加载巨大的模型权重和KV缓存,因此是内存带宽密集型(Memory-Bound)的。
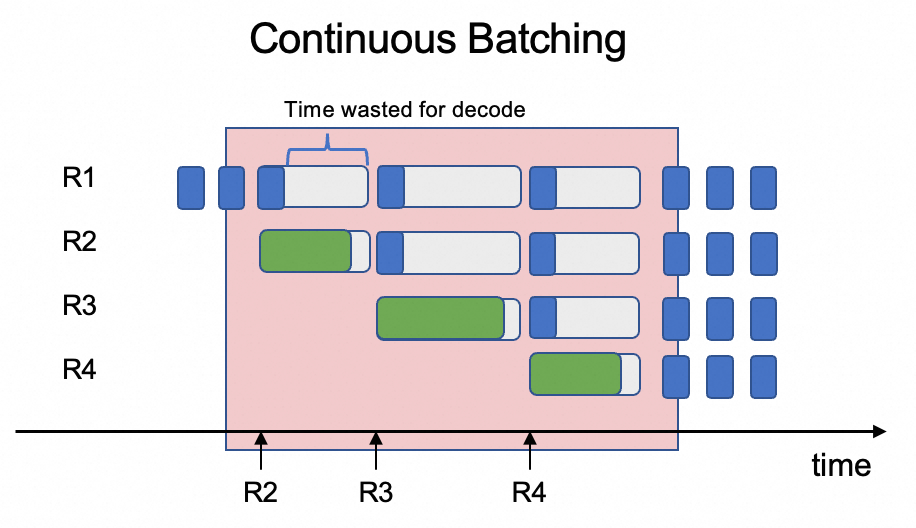
核心矛盾在于将这两种特性迥异的任务混合在同一GPU上调度,效率极低。推理引擎在处理多个用户请求时往往会采用连续批处理(Continuous Batching)的方式,将不同请求的Prefill阶段和Decode阶段放在一个批次里调度。由于Prefill阶段需处理完整提示词(计算复杂度高),而Decode阶段仅需生成单token(计算复杂度低),若在同一批次中调度,Decode阶段会因序列长度差异与资源竞争导致时延增加,进而增加系统整体延迟并降低吞吐量。
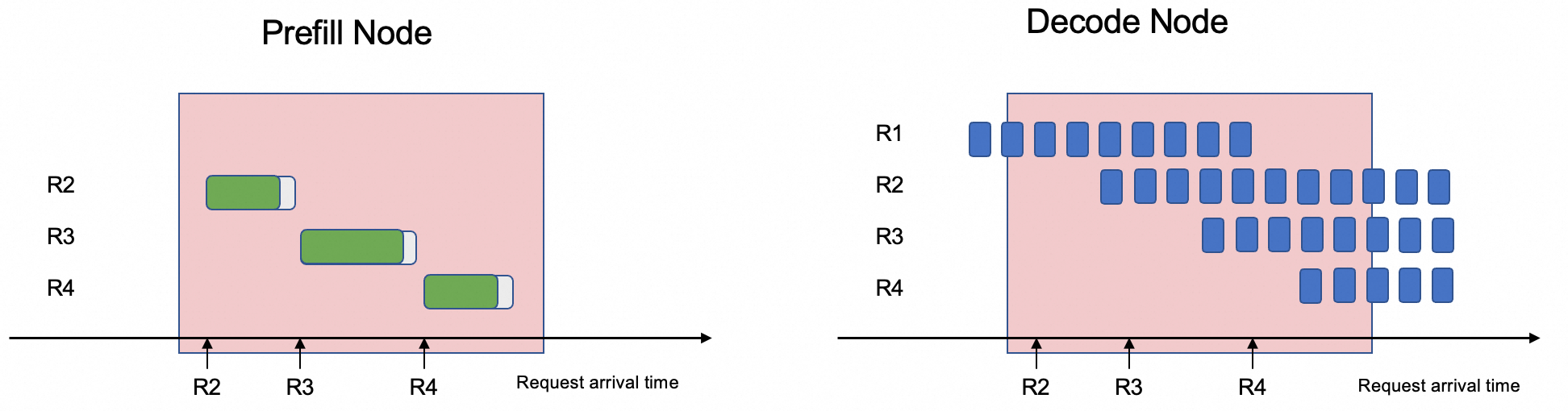
PD分离架构的解决方案就是将这两个阶段解耦,将Prefill和Decode阶段分开部署在不同GPU上。通过这种分离,系统可以针对Prefill和Decode不同特征进行优化,避免资源争抢,从而显著降低生成每个输出 token 的平均时间(TPOT),提升系统吞吐。
RoleBasedGroup
RoleBasedGroup(RBG)是阿里云容器服务团队设计的一种新的工作负载,为了解决PD分离架构在Kubernetes集群中大规模部署及运维的难题。该项目已开源,更多信息请查看RBG Github。
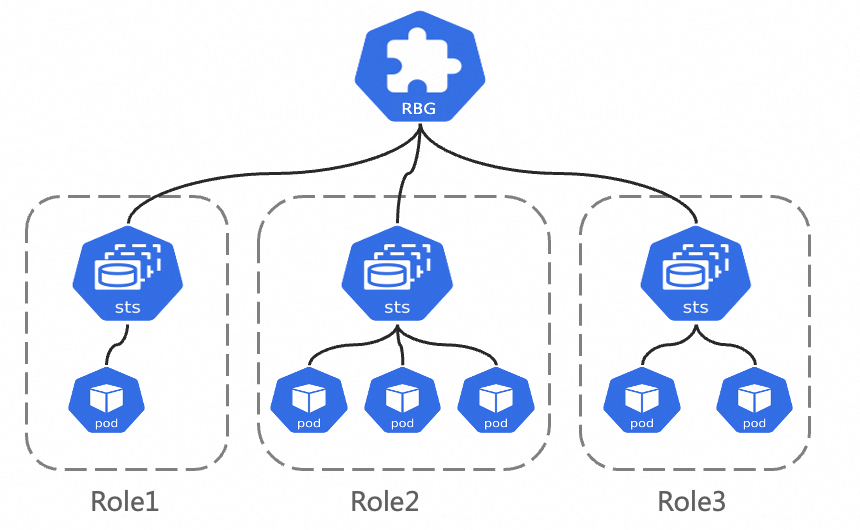
RBG API设计如下图所示,它由一组Role构成一个Group整体,每个Role可以基于StatefulSet/Deployment/LWS构建。其核心特性如下:
灵活的多角色定义:RBG支持定义任意数量任意名称的Role;支持定义Role间的依赖关系,可以按指定顺序启动Role;可以按照Role维度弹性扩缩容。
Runtime:具备Group内部的自动服务发现能力;支持多种重启策略;支持滚动更新;支持Gang调度。
前提条件
已创建ACK集群且集群版本为1.22及以上,并且已经为集群添加GPU节点。具体操作,请参见创建ACK托管集群和为集群添加GPU节点。
本文要求集群中GPU卡>=6, 单个GPU卡显存>=32GB。由于SGLang PD分离框架依赖GPU Direct RDMA(GDR)进行数据传输,所选择节点规格需支持弹性RDMA(eRDMA),推荐使用ecs.ebmgn8is.32xlarge规格,更多规格信息可参考弹性裸金属服务器规格。
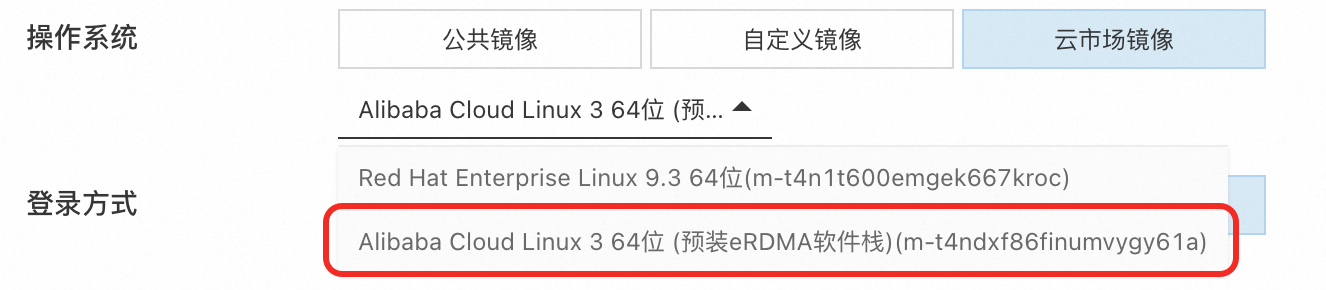
节点操作系统镜像选择:弹性RDMA的使用需要相关软件栈支持,因此在创建节点池时,推荐在操作系统-云市场镜像中选择Alibaba Cloud Linux 3 64位 (预装eRDMA软件栈)操作系统镜像。具体操作,请参见在ACK中添加eRDMA节点。
已安装ack eRDMA Controller组件,具体操作参见使用eRDMA加速容器网络,在集群中安装并配置ACK eRDMA Controller组件。
已安装ack-rbgs组件。组件安装步骤如下。
登录容器服务管理控制台,在左侧导航栏选择集群列表。单击目标集群名称,进入集群详情页面,使用Helm为目标集群安装ack-rbgs组件。您无需为组件配置应用名和命名空间,单击下一步后会出现一个请确认的弹框,单击是,即可使用默认的应用名(ack-rbgs)和命名空间(rbgs-system)。然后选择Chart 版本为最新版本,单击确定即可完成ack-rbgs组件的安装。
模型部署
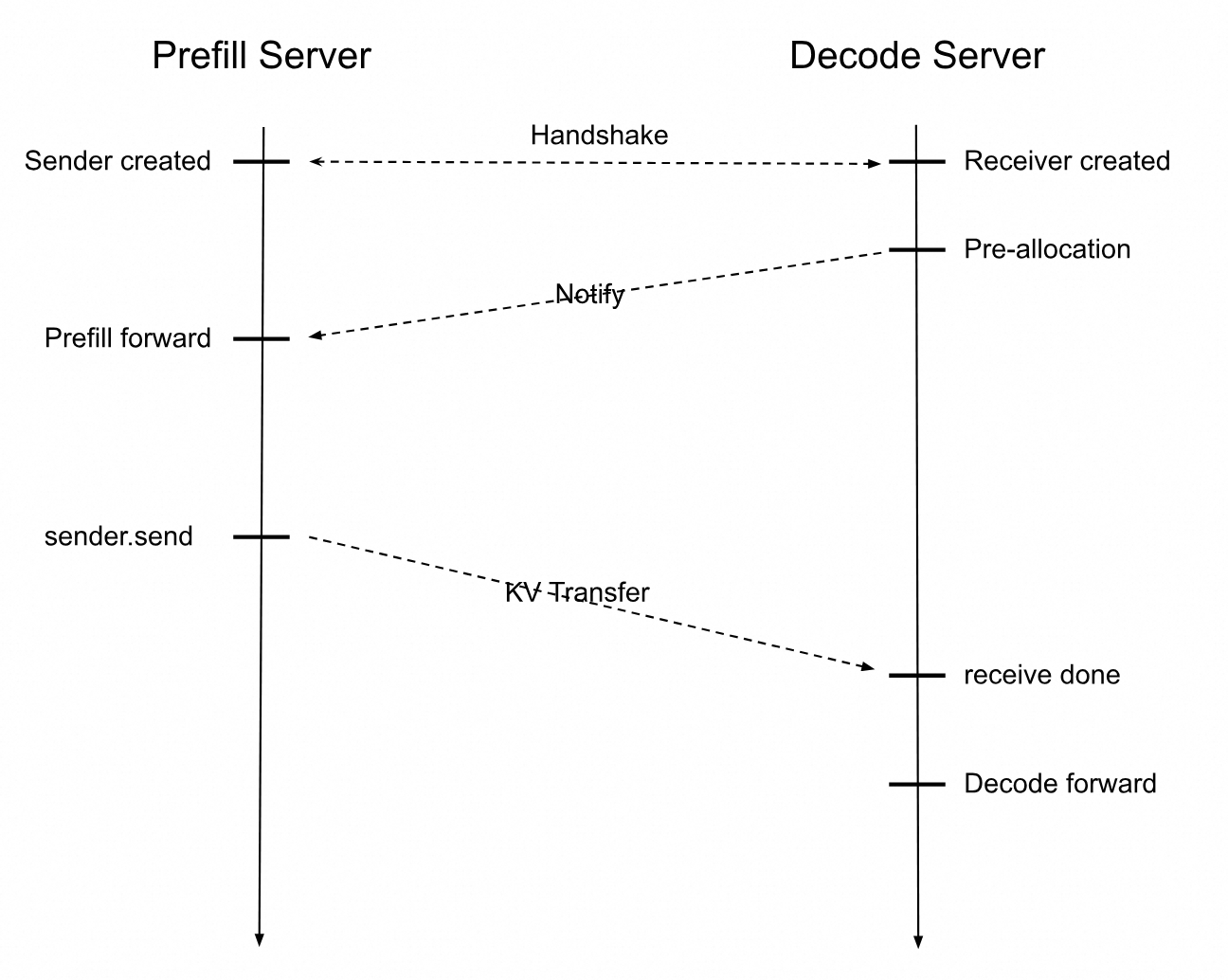
部署PD分离架构推理服务。SGLang Prefill Server和Decode Server交互时序图如下所示。
收到用户推理请求后,Prefill Server将会创建一个Sender对象而Decode Server会创建一个Receiver对象。
Prefill和Decode通过Handshake建立连接,Decode首先分配一块显存地址用于接收KVCache,Prefill Server完成计算后将KVCache传送给Decode Server,Decode Server收到KVCache后继续计算后续Token,直到完成用户的推理请求。
步骤一:准备Qwen3-32B模型文件
执行以下命令从ModelScope下载Qwen-32B模型。
请确认是否已安装git-lfs插件,如未安装可执行
yum install git-lfs或者apt-get install git-lfs安装。更多的安装方式,请参见安装git-lfs。git lfs install GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/Qwen/Qwen3-32B.git cd Qwen3-32B/ git lfs pull登录OSS控制台,查看并记录已创建的Bucket名称。如何创建Bucket,请参见创建存储空间。在OSS中创建目录,将模型上传至OSS。
关于ossutil工具的安装和使用方法,请参见安装ossutil。
ossutil mkdir oss://<your-bucket-name>/Qwen3-32B ossutil cp -r ./Qwen3-32B oss://<your-bucket-name>/Qwen3-32B创建PV和PVC。为目标集群配置名为
llm-model的存储卷PV和存储声明PVC。具体操作,请参见创建PV和PVC。控制台操作示例
创建PV。
登录容器服务管理控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在存储卷页面,单击右上角的创建。
在创建存储卷对话框中配置参数。
以下为示例PV的基本配置信息:
配置项
说明
存储卷类型
OSS
名称
llm-model
访问证书
配置用于访问OSS的AccessKey ID和AccessKey Secret。
Bucket ID
选择上一步所创建的OSS Bucket。
OSS Path
选择模型所在的路径,如
/Qwen3-32B。
创建PVC。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择。
在存储声明页面,单击右上角的创建。
在创建存储声明页面中,填写界面参数。
以下为示例PVC的基本配置信息:
配置项
说明
存储声明类型
OSS
名称
llm-model
分配模式
选择已有存储卷。
已有存储卷
单击选择已有存储卷链接,选择已创建的存储卷PV。
kubectl操作示例
创建
llm-model.yaml文件,该YAML文件包含Secret、静态卷PV、静态卷PVC等配置,示例YAML文件如下所示。apiVersion: v1 kind: Secret metadata: name: oss-secret stringData: akId: <your-oss-ak> # 配置用于访问OSS的AccessKey ID akSecret: <your-oss-sk> # 配置用于访问OSS的AccessKey Secret --- apiVersion: v1 kind: PersistentVolume metadata: name: llm-model labels: alicloud-pvname: llm-model spec: capacity: storage: 30Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: llm-model nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: <your-bucket-name> # bucket名称 url: <your-bucket-endpoint> # Endpoint信息,如oss-cn-hangzhou-internal.aliyuncs.com otherOpts: "-o umask=022 -o max_stat_cache_size=0 -o allow_other" path: <your-model-path> # 本示例中为/Qwen3-32B/ --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: llm-model spec: accessModes: - ReadOnlyMany resources: requests: storage: 30Gi selector: matchLabels: alicloud-pvname: llm-model创建Secret、创建静态卷PV、创建静态卷PVC。
kubectl create -f llm-model.yaml
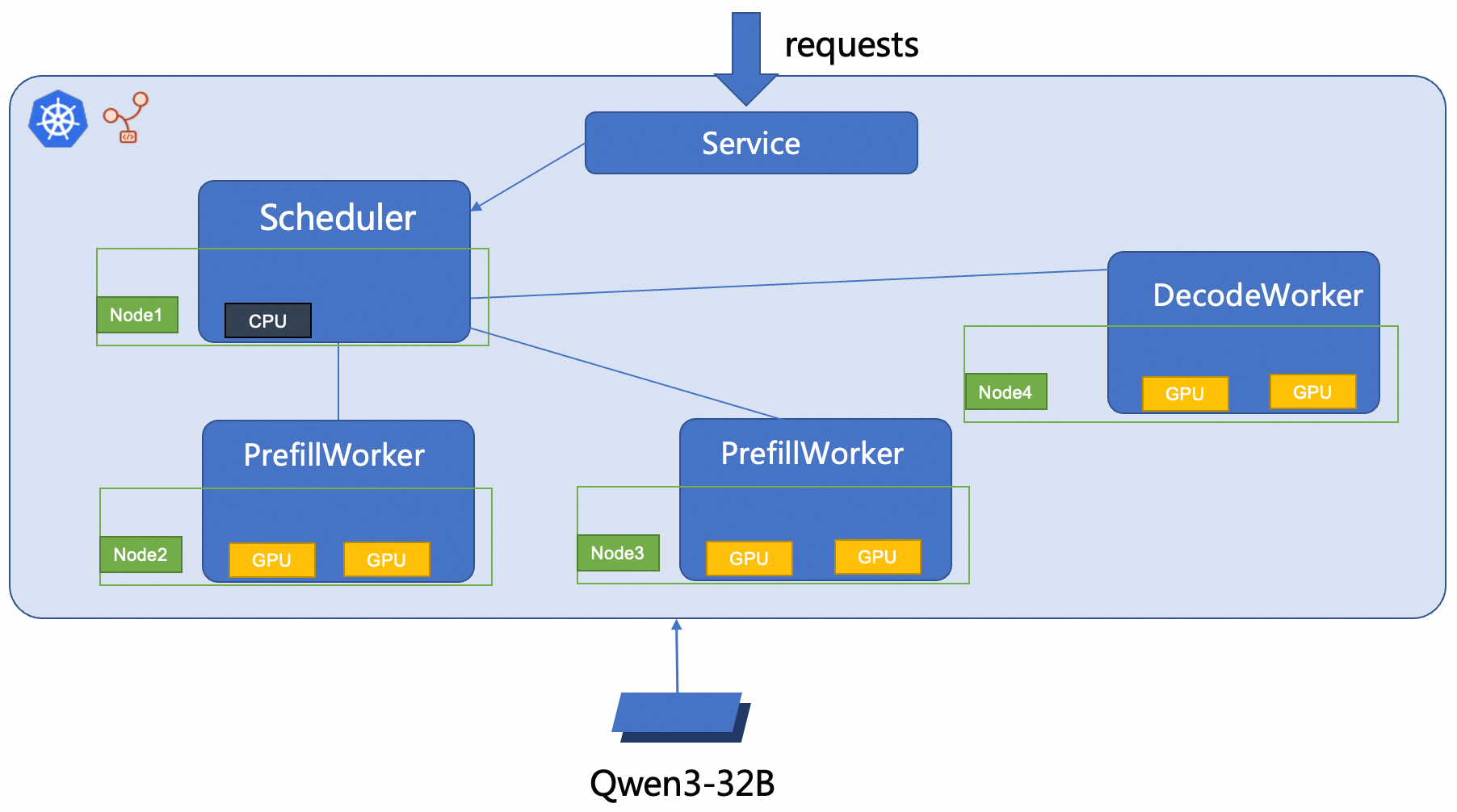
步骤二:部署SGLang PD分离架构的推理服务
本文使用RBG部署2P1D SGLang推理服务,部署架构图如下所示。
创建
sglang_pd.yaml文件。部署SGLang PD分离推理服务。
kubectl create -f sglang_pd.yaml
步骤三:验证推理服务
执行以下命令,在推理服务与本地环境之间建立端口转发。
重要kubectl port-forward建立的端口转发不具备生产级别的可靠性、安全性和扩展性,因此仅适用于开发和调试目的,不适合在生产环境使用。更多关于Kubernetes集群内生产可用的网络方案的信息,请参见Ingress管理。kubectl port-forward svc/sglang-pd 8000:8000预期输出:
Forwarding from 127.0.0.1:8000 -> 8000 Forwarding from [::1]:8000 -> 8000执行以下命令,向模型推理服务发送了一条示例的模型推理请求。
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "/models/Qwen3-32B", "messages": [{"role": "user", "content": "测试一下"}], "max_tokens": 30, "temperature": 0.7, "top_p": 0.9, "seed": 10}'预期输出:
{"id":"29f3fdac693540bfa7808fc1a8701758","object":"chat.completion","created":1753695366,"model":"/models/Qwen3-32B","choices":[{"index":0,"message":{"role":"assistant","content":"<think>\n好的,用户让我测试一下,我需要先确认他们的具体需求。可能他们想测试我的功能,比如回答问题、生成内容","reasoning_content":null,"tool_calls":null},"logprobs":null,"finish_reason":"length","matched_stop":null}],"usage":{"prompt_tokens":10,"total_tokens":40,"completion_tokens":30,"prompt_tokens_details":null}}输出结果表明模型可以根据给定的输入(在这个例子中是一条测试消息)生成相应的回复。
相关文档
为LLM推理服务配置Prometheus Dashboard监控
在生产环境中,LLM推理服务的可观测性是系统稳定性的核心保障,开源推理引擎通过集成Prometheus Dashboard实现故障的主动发现与精准定位。
LLM 模型通常包含超过10GB的权重文件,从存储服务(如 OSS、NAS 等)拉取这些大文件时,容易因长时间延迟和冷启动问题影响性能。Fluid 通过在 Kubernetes 集群节点上构建分布式文件缓存系统,整合多个节点的存储与带宽资源;同时,它从应用程序端优化模型文件的读取机制,从而显著加速模型加载过程。
配置ACK Gateway with Inference Extension网关实现智能路由
ACK Gateway with Inference Extension 是基于 Kubernetes 社区 Gateway API 及其 Inference Extension 规范构建的增强型组件,支持 Kubernetes 四层和七层路由服务,同时针对生成式 AI 推理场景提供了一系列优化能力。该组件能够简化 AI 推理服务的管理流程,并提升多推理服务工作负载间的负载均衡性能。其关键特性包括:
模型感知的推理负载均衡:提供优化的负载均衡策略,确保推理请求高效分发。
基于 OpenAI API 规范的模型路由:根据模型名称对推理请求进行智能路由,支持对同一基础模型的不同 LoRA 模型进行流量灰度管理。
模型关键性优先级配置:通过为不同模型设置关键性等级,实现请求的差异化优先级处理,确保高优先级模型的服务质量。